PostgreSQL 12.4文書ノート
※まとめノートです。自分の視点で書いたコードがたまに混ざっております。ライセンスは下部に記載しております。
途中です。
第8章 データ型
8.1. 数値データ型
8.1.1. 整数データ型
8.1.2. 任意の精度を持つ数
8.1.3. 浮動小数点データ型
numeric型
非常に大きな桁数で数値を格納できます。
通貨金額やその他正確性が求められる数量を保存する時は特にこの型
計算が非常に遅い
drop table if exists numeric_table;
CREATE table numeric_table
(
num numeric(10,5) DEFAULT 0, -- 有効数字10桁、少数の位取りが5
num2 numeric(10,9) DEFAULT 0 -- 有効数字10桁、少数の位取りが9
);
INSERT into numeric_table (num,num2) VALUES(10000.00000,null);
INSERT into numeric_table (num,num2) VALUES(DEFAULT,1.000000000);
INSERT into numeric_table (num,num2) VALUES(DEFAULT,1.0);
INSERT into numeric_table (num,num2) VALUES(DEFAULT,1.00000987);
select * from numeric_table;
- numeric列の数値の最大位取りを超えているので、システムが指定された少数部の桁まで値を丸めている
INSERT into numeric_table (num,num2) VALUES(DEFAULT,1.000000000000);
select * from numeric_table;
-- numeric列の数値の最大制度を超えているので、numericフィールドのオーバーフローとでてエラーになる
-- 有効数字から小数の位取りを引いた数値を超える桁数の数値を挿入しようとするとエラー
-- INSERT into numeric_table (num,num2) VALUES(100000.0,null);
-- select * from numeric_table;
-- - 小数点の位取りの扱われ方を見る
SELECT
num+num2 --小数点の位取り5と9の足算の結果は9の位取りで扱われるっぽい
from numeric_table;
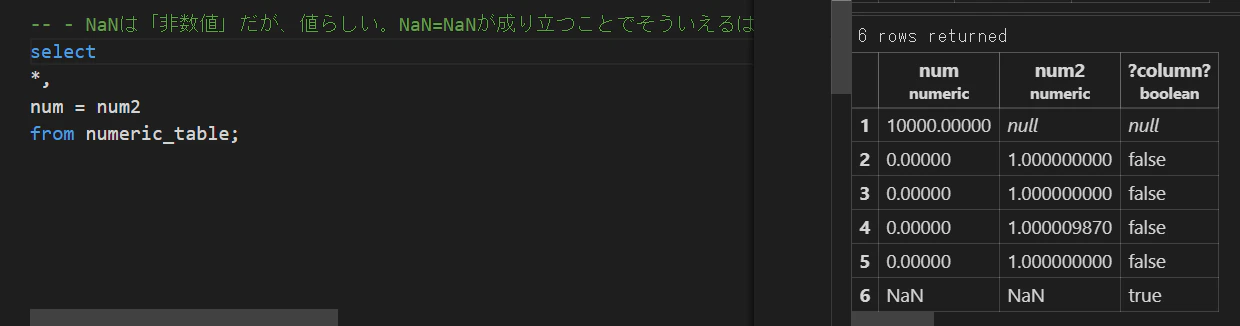
-- - NaNの挙動を見る
INSERT into numeric_table (num,num2) VALUES('NaN','NaN');
-- 二重引用符だとエラー
-- INSERT into numeric_table (num,num2) VALUES("NaN","NaN");
select * from numeric_table;
-- - null>NaN>数値の順に大きいという風に扱われる
select * from numeric_table order by num2;
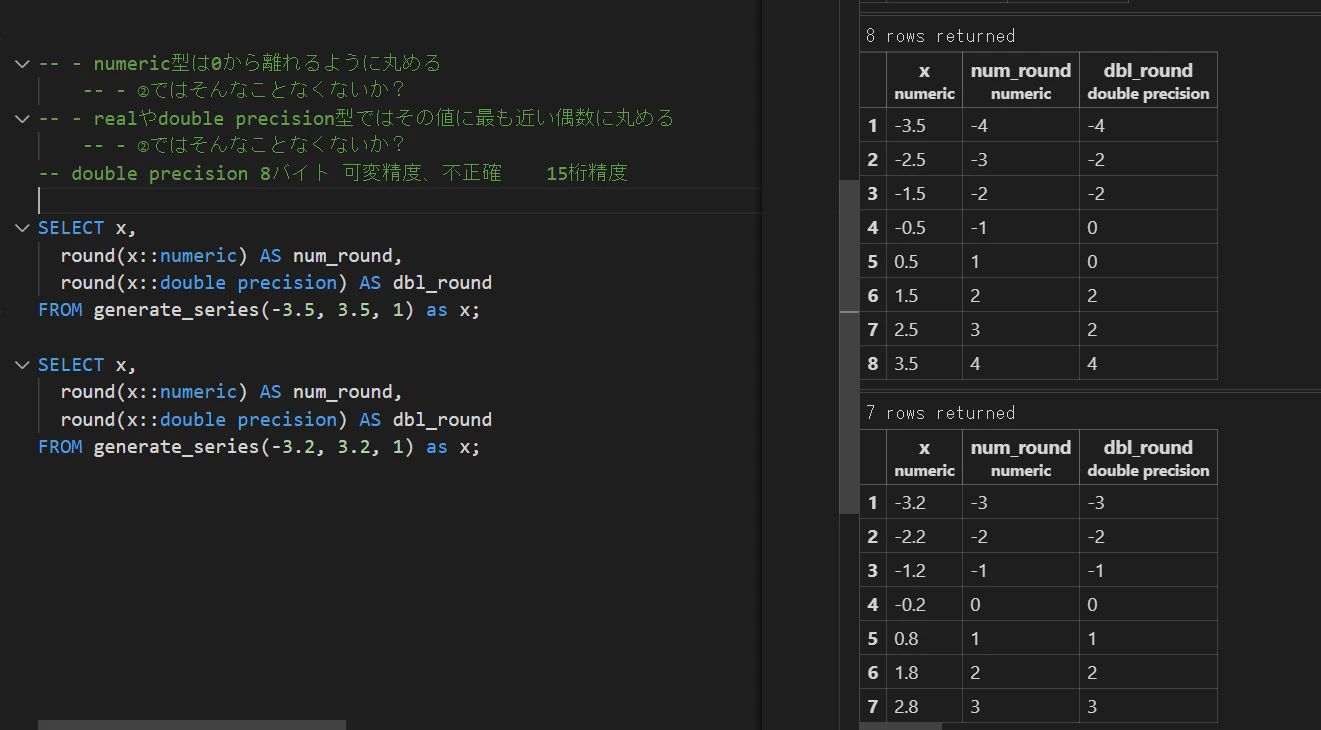
- numeric型は0から離れるように丸める
- ②ではそんなことなくないか?
- realやdouble precision型ではその値に最も近い偶数に丸める
- ②ではそんなことなくないか?
- double precision 8バイト 可変精度、不正確 15桁精度
SELECT x,
round(x::numeric) AS num_round,
round(x::double precision) AS dbl_round
FROM generate_series(-3.5, 3.5, 1) as x;
SELECT x,
round(x::numeric) AS num_round,
round(x::double precision) AS dbl_round
FROM generate_series(-3.2, 3.2, 1) as x;
-
realとdouble precision可変精度、不正確なので使いづらいだろう
-
NaNは「非数値」だが、値らしい。NaN=NaNが成り立つ。
select
*,
num = num2
from numeric_table;
8.1.4. 連番型
drop TABLE if EXISTS tablename;
DROP SEQUENCE if EXISTS tablename_colname_seq;
CREATE SEQUENCE tablename_colname_seq AS integer;
CREATE TABLE tablename (
colname integer NOT NULL DEFAULT nextval('tablename_colname_seq'),
col integer NOT NULL
);
ALTER SEQUENCE tablename_colname_seq OWNED BY tablename.colname;
insert into tablename (colname,col) VALUES(DEFAULT,100);
insert into tablename (colname,col) VALUES(DEFAULT,100);
insert into tablename (colname,col) VALUES(DEFAULT,100);
insert into tablename (colname,col) VALUES(DEFAULT,100);
insert into tablename (colname,col) VALUES(DEFAULT,100);
SELECT * from tablename;
drop TABLE if EXISTS tablename2;
CREATE TABLE tablename2 (
colname SERIAL UNIQUE,
colname2 bigserial UNIQUE,
col integer NOT NULL
);
insert into tablename2 (colname,col) VALUES(DEFAULT,100);
insert into tablename2 (colname,col) VALUES(DEFAULT,100);
insert into tablename2 (colname,col) VALUES(DEFAULT,100);
insert into tablename2 (colname,col) VALUES(DEFAULT,100);
insert into tablename2 (colname,col) VALUES(DEFAULT,100);
SELECT * from tablename2;
8.2. 通貨型
8.3. 文字型
8.4. バイナリ列データ型
8.4.1. byteaのhex書式
8.4.2. byteaのエスケープ書式
8.5. 日付/時刻データ型
8.5.1. 日付/時刻の入力
8.5.2. 日付/時刻の出力
8.5.3. 時間帯
8.5.4. 時間間隔の入力
8.5.5. 時間間隔の出力
8.6. 論理値データ型
8.7. 列挙型
8.7.1. 列挙型の宣言
8.7.2. 順序
8.7.3. 型の安全性
8.7.4. 実装の詳細
8.8. 幾何データ型
8.8.1. 座標点
8.8.2. 直線
8.8.3. 線分
8.8.4. 矩形
8.8.5. 経路
8.8.6. 多角形(ポリゴン)
8.8.7. 円
8.9. ネットワークアドレス型
8.9.1. inet
8.9.2. cidr
8.9.3. inetとcidrデータ型の違い
8.9.4. macaddr
8.9.5. macaddr8
8.10. ビット列データ型
8.11. テキスト検索に関する型
8.11.1. tsvector
8.11.2. tsquery
8.12. UUID型
8.13. XML型
8.13.1. XML値の作成
8.13.2. 符号化方式の取扱い
8.13.3. XML値へのアクセス
8.14. JSONデータ型
8.14.1. JSONの入出力構文
8.14.2. JSONドキュメントの設計
8.14.3. jsonb型用包含演算子と存在演算子
8.14.4. jsonb インデックス
8.14.5. 変換
8.14.6. jsonpath型
8.15. 配列
8.15.1. 配列型の宣言
PostgreSQLではテーブルの列を可変長多次元配列として定義できる。 あらゆる組み込み型あるいはユーザ定義の基本型、列挙型、複合型、範囲型そしてドメインの配列も作成可能
例
text型文字列(name)、従業員の四半期の給与を保存するinteger型の一次元配列(pay_by_quarter)、そして従業員の週間スケジュールを保存するtext型の二次元配列(schedule)の列を持つsal_empという名前のテーブル
drop TABLE sal_emp;
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[],
schedule text[][]
);
INSERT INTO sal_emp values('itiro', '{100}', '{"mtg","office"}');
INSERT INTO sal_emp values('ziro', '{100}', '{"mtg","office"}');
INSERT INTO sal_emp values('nullro', '{null}', '{"mtg","office"}');
INSERT INTO sal_emp values('nullziro', '{null}', '{"office",null}');
INSERT INTO sal_emp values('nullsaburo', '{null}', '{"mtg","null"}');
-- INSERT INTO sal_emp values('nullshiro', '{"null"}', '{"mtg","null"}');
INSERT INTO sal_emp values('nullgoro', '{null}', '{"mtg",mtg}');
SELECT
*,
schedule[1] as 列1,
schedule[2] as 列2,
name || schedule[2] as concat
from sal_emp;

- nullsaburoの結果から配列にいれるはずのnullを二重引用符で囲んでしまうとNULLではなく文字列定数"NULL"と扱われてしまう。したがってコメントアウトしたnullshiroはintegerに文字列定数"null"を挿入する動作になり当然エラー
「NULL」という文字列値を指定したければ、二重引用符でくくって記載しなければなりません。
- 書いてあった。
この種の配列定数は実際4.1.2.7で説明されている一般型定数の特別の場合に過ぎません。 この定数は元々文字列として扱われていて配列入力ルーチンに渡されます。
- 上記の理由でnullgoroの行は二重引用符で囲まないmtg配列要素の入力をデフォで"mtg"として配列入力ルーチンが処理しているから動作するのかな?
8.15.2. 配列の値の入力
8.15.3. 配列へのアクセス
drop TABLE sal_emp2;
CREATE TABLE sal_emp2 (
name text,
pay_by_quarter integer[],
schedule text[][]
);
INSERT INTO sal_emp2
VALUES ('Bill',
'{10000, 10000, 10000, 10000}',
'{{"meeting", "lunch"}, {"training", "presentation"}}');
INSERT INTO sal_emp2
VALUES ('Carol',
'{20000, 25000, 25000, 25000}',
'{{"breakfast", "consulting"}, {"meeting", "lunch"}}');
SELECT * FROM sal_emp2;
- numpyに触れてきたのでARRAY生成子構文の方が少しだけ直観的。
- array生成子構文の中で10000+100のようなちょっとした計算もできる。
INSERT INTO sal_emp2
VALUES ('Bill',
ARRAY[10000, 10000, 10000+100, 10000],
ARRAY[['meeting', 'lunch'], ['training', 'presentation']]);
INSERT INTO sal_emp2
VALUES ('Carol',
ARRAY[20000, 25000, 25000, 25000],
ARRAY[['breakfast', 'consulting'], ['meeting', 'lunch']]);
- 配列の要素は1始まり
SELECT name FROM sal_emp2 WHERE pay_by_quarter[1] <> pay_by_quarter[2];
SELECT name, pay_by_quarter[3] FROM sal_emp2;
- vscode エディタだと'{{"meeting", "lunch"}, {"training", "presentation"}}'からmeeting,training
- のように切り出されるので配列の構造が不明確←配列の構造は後述の関数で確認できた
SELECT schedule[1:2][1:1] FROM sal_emp2 WHERE name = 'Bill';
切り出しのない場合と混乱を避けるため、すべての次元に対し切り出し構文を使用することが最善です。 例えば、[2][1:1]ではなく、[1:2][1:1]のようにします。
- これは守ろう
切り出し指定子のlower-bound、upper-boundは省略可能です。省略された上限または下限は、配列の添字の上限または下限で置き換えられます。
- numpyと同じ
SELECT schedule[:2][2:] FROM sal_emp2 WHERE name = 'Bill';
SELECT schedule[:][1:1] FROM sal_emp2 WHERE name = 'Bill';
配列の範囲を超える添字の場合もNULLが返されます(この場合はエラーになりません)。
- 例えば、scheduleが現在[1:3][1:2]次元であれば、schedule[3][3]の参照はNULLとなります。 同様にして、添字として間違った値を指定して配列を参照した場合もエラーではなく、NULLが返されます。
SELECT *,
pay_by_quarter[1:2] as 上半期,
pay_by_quarter[1:6] as nullになるか?, -- 後ろの2つは空の配列?
pay_by_quarter[6] as nullになるか?2 -- こちらはダイレクトに範囲外の要素を指定したのでNullになる
-- array[pay_by_quarter[1:3]] + array[pay_by_quarter[1:3]]
-- ERROR: 演算子が存在しません: integer[] + integer[]
-- 配列同士の演算はできないのか?
FROM sal_emp2;

配列の範囲を超える添字の場合もNULLが返されます(この場合はエラーになりません)
現在の配列範囲を完全に超えた部分配列を選択する場合では、部分配列式はNULLではなく空の(0次元)の配列を返します。 (これは切り出しなしの動作に一致せず、歴史的理由で行われるものです。)
要求された部分配列が配列の範囲に重なる場合、NULLを返さずに、警告なく重複部分だけに減少させます。
-
これも書いてあった。今回は要求された部分配列が配列の範囲に重なるので配列の存在する要素のみが返されているっぽい。
-
array_dims関数で任意の配列値の現在の次元を取りだせる。
drop TABLE sal_emp3;
CREATE TABLE sal_emp3 (
name text,
pay_by_quarter integer[],
schedule text[][][]
);
INSERT INTO sal_emp3
values('itiro', array[100], array[[['mtg','office','3番目の予定'],['mtg','office','3番目の予定']],[['mtg','office','3番目の予定'],['mtg','office','3番目の予定']],[['mtg','office','3番目の予定'],['mtg','office','3番目の予定']],[['mtg','office','3番目の予定'],['mtg','office','3番目の予定']]]);
INSERT INTO sal_emp3
values('ziro', array[100], array[[['mtg','office','3番目の予定'],['mtg','office','3番目の予定']],[['mtg','office','3番目の予定'],['mtg','office','3番目の予定']],[['mtg','office','3番目の予定'],['mtg','office','3番目の予定']],[['mtg','office','3番目の予定'],['mtg','office','3番目の予定']]]);
INSERT INTO sal_emp3
values('nullro', array[10], array[[['mtg','office','3番目の予定'],['mtg','office','3番目の予定']],[['mtg','office','3番目の予定'],['mtg','office','3番目の予定']],[['mtg','office','3番目の予定'],['mtg','office','3番目の予定']],[['mtg','office','3番目の予定'],['mtg','office','3番目の予定']]]);
SELECT
name,
array_dims(schedule),
array_upper(schedule, 1),
array_upper(schedule, 2),
array_upper(schedule, 3),
array_length(schedule, 1), -- 配列次元の長さを返すが、array_upperと同じなので使い分けるシチュエーションあるか?
array_length(schedule, 2), -- 配列次元の長さを返すが、array_upperと同じなので使い分けるシチュエーションあるか?
array_length(schedule, 3), -- 配列次元の長さを返すが、array_upperと同じなので使い分けるシチュエーションあるか?
cardinality(schedule) --cardinalityは配列の全次元に渡る要素の総数を返します。 実質的にunnestの呼び出しで生成される行の数です。
FROM sal_emp3;
-
array_dims関数はtext型で結果を返します。 人間が結果を見るためには便利ですが、プログラムにとって都合がよくありません。
-
次元はarray_upperとarray_lowerでも抽出することができ、それぞれ特定の配列の次元の上限と下限を返します。
-
array_upperの2番目の引数は次元
-
(4,2,3)のテンソルを格納できることも分かった。次元の順序はnumpyと同じ

8.15.4. 配列の変更
drop TABLE IF EXISTS sal_emp;
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[],
schedule text[][]
);
INSERT INTO sal_emp
VALUES ('Bill',
'{10000, 10000, 10000, 10000}',
'{{"meeting", "lunch"}, {"training", "presentation"}}');
INSERT INTO sal_emp
VALUES ('Carol',
'{20000, 25000, 25000, 25000}',
'{{"breakfast", "consulting"}, {"meeting", "lunch"}}');
- 値の置き換え
- 配列の値を全て置き換えることができます。
- もしくはARRAY演算構文を用いて次のように書きます。
- 配列の1つの要素を更新することも可能です。
- あるいは一部分の更新も可能です。
UPDATE sal_emp SET pay_by_quarter = '{25000,25000,27000,27000}'
WHERE name = 'Carol';
SELECT *
from sal_emp;
UPDATE sal_emp SET pay_by_quarter = ARRAY[25000,25000,27000,27000]
WHERE name = 'Carol';
SELECT *
from sal_emp;
UPDATE sal_emp SET pay_by_quarter[4] = 15000
WHERE name = 'Bill';
SELECT *
from sal_emp;
UPDATE sal_emp SET pay_by_quarter[1:2] = '{27000,27000}'
WHERE name = 'Carol';
SELECT *
from sal_emp;
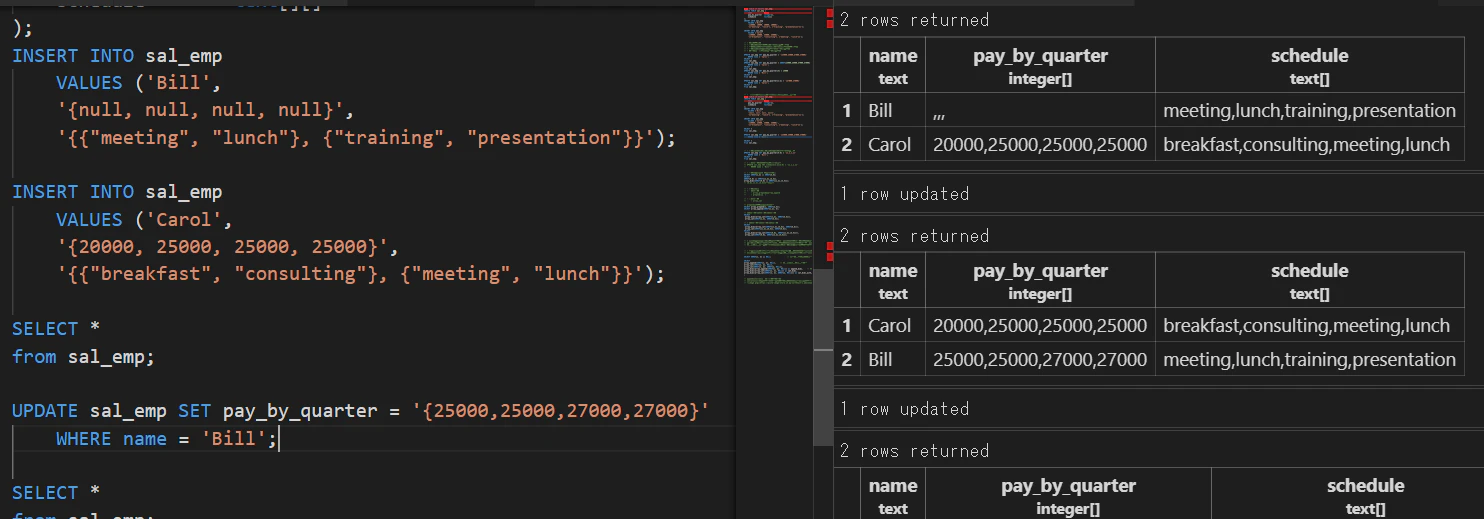
- 作り直してnullがある場合の変更の挙動を調べる
drop TABLE IF EXISTS sal_emp;
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[],
schedule text[][]
);
INSERT INTO sal_emp
VALUES ('Bill',
'{null, null, null, null}',
'{{"meeting", "lunch"}, {"training", "presentation"}}');
INSERT INTO sal_emp
VALUES ('Carol',
'{20000, 25000, 25000, 25000}',
'{{"breakfast", "consulting"}, {"meeting", "lunch"}}');
SELECT *
from sal_emp;
UPDATE sal_emp SET pay_by_quarter = '{25000,25000,27000,27000}'
WHERE name = 'Bill';
SELECT *
from sal_emp;
nullはもちろん置き換え可能↓
- 配列の拡張を存在しない要素に代入することで行う
UPDATE sal_emp SET pay_by_quarter[5:8] = '{1,1,1,1}'
WHERE name = 'Bill';
SELECT *
from sal_emp;
-- 多次元配列についてはエラーになる
UPDATE sal_emp SET schedule[1:2][2:8] = '{1,1,1,1}'
WHERE name = 'Bill';

- 配列要素の結合 連結演算子||
SELECT ARRAY[1,2] || ARRAY[3,4];
SELECT
ARRAY[5,6] || ARRAY[[1,2],[3,4]],
array_dims(ARRAY[5,6] || ARRAY[[1,2],[3,4]]);
-- [5,6],[1,2],[3,4]の形になる
-
配列の構築
-
一次元配列
- array_prepend、array_append
- prepend(付加)
-
多次元配列
- array_cat
-
prependは先頭、appendは末尾
SELECT array_prepend(1, ARRAY[2,3]);
SELECT array_append(ARRAY[1,2], 3);
- 1次元配列と1次元配列の結合=2次元配列
array_dims(array_cat(ARRAY[1,2], ARRAY[3,4])),
array_cat(ARRAY[1,2], ARRAY[3,4]);
- 2次元配列と1次元配列の結合=2次元配列
SELECT
array_dims(array_cat(ARRAY[[1,2],[3,4]], ARRAY[5,6])),
array_cat(ARRAY[[1,2],[3,4]], ARRAY[5,6]);
SELECT
array_dims(array_cat(ARRAY[5,6], ARRAY[[1,2],[3,4]])),
array_cat(ARRAY[5,6], ARRAY[[1,2],[3,4]]);
上の例では、パーサは連結演算子の一方の側に整数の配列を見つけ、もう一方の側に型の決まらない定数を見つけます。
パーサが定数の型を解決するのに使う発見的手法は、演算子のもう一方の入力と同じ型(この場合には整数の配列)だと仮定することです。 そのため、連結演算子はarray_appendではなく、array_catと推定されます。
これが誤った選択である場合には、定数を配列の要素の型にキャストすることで直せるかもしれません。ですが、array_appendを明示的に使うのが好ましい解決法であるかもしれません
- 型指定がないリテラルが片方に入るとpythonみたいに動的に型が決定されるがこれは好ましくない。
- 明示的にarray[]等でリテラルの型を指定したり、結合演算子よりも明示的に関数の構文を使用したほうがいいと解釈した。
SELECT
array_append(ARRAY[1, 2], NULL), -- これがやりたかった事かも
array_cat(ARRAY[1, 2], NULL),
array_cat(ARRAY[1, 2], ARRAY[1, NULL]),
array_dims(array_append(ARRAY[1, 2], NULL)) as append_dims, -- これがやりたかった事かも
array_dims(array_cat(ARRAY[1, 2], NULL)) as cat_dims,
array_dims(array_cat(ARRAY[1, 2], ARRAY[1, NULL])) as cat_dims_with_nullandinteger
;
- appendはnullの追加に対応している。
- concatはnullと結合すると何も結合していないことになる、が結合する配列に一つでもNullでない定数が入っていると、nullも結合される

8.15.5. 配列内の検索
drop TABLE IF EXISTS sal_emp;
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[],
schedule text[][]
);
INSERT INTO sal_emp
VALUES ('Bill',
'{10000, 12000, 500, 10000}',
'{{"meeting", "lunch"}, {"training", "presentation"}}');
INSERT INTO sal_emp
VALUES ('Carol',
'{20000, 25000, 25000, 25000}',
'{{"breakfast", "consulting"}, {"meeting", "lunch"}}');
- 最も愚直な方法
SELECT * FROM sal_emp;
SELECT * FROM sal_emp WHERE pay_by_quarter[1] = 10000 OR
pay_by_quarter[2] = 10000 OR
pay_by_quarter[3] = 10000 OR
pay_by_quarter[4] = 10000; - 最も愚直な方法を簡略化したもの
SELECT * FROM sal_emp WHERE 10000 = ANY (pay_by_quarter);
SELECT * FROM sal_emp WHERE 10000 = ALL (pay_by_quarter);
SELECT 10000 = ANY(pay_by_quarter) FROM sal_emp;
SELECT * FROM sal_emp WHERE pay_by_quarter && ARRAY[10000];
SELECT * FROM sal_emp WHERE pay_by_quarter && ARRAY[10000];
- 配列内の特定の値を検索
- 配列内で初めてその値が現れる添字
SELECT array_position(ARRAY['sun','mon','tue','wed','thu','fri','sat'], 'mon');
- 配列内でその値が現れる添字すべての配列
SELECT array_positions(ARRAY[1, 4, 3, 1, 3, 4, 2, 1], 1);
配列は集合ではありません。 特定の配列要素に検索をかけることはデータベース設計が誤っている可能性があります。
- 配列の要素とみなされるそれぞれの項目を行に持つ別のテーブルを使うことを検討してください。 この方が検索がより簡単になり要素数が大きくなっても規模的拡張性があります。
8.15.6. 配列の入出力構文
- インデックスは下記のように自由に設定できる。個人的には超紛らわしいと思う。
SELECT
'[1:1][-2:-1][3:5]={{{1,2,3},{4,5,6}}}'::int[]
AS f1;
SELECT
f1[1][-2][3] AS e1,
f1[1][-1][5] AS e2,
array_dims(f1)
FROM (SELECT '[1:1][-2:-1][3:5]={{{1,2,3},{4,5,6}}}'::int[] AS f1) AS ss;
8.16. 複合型
8.16.1. 複合型の宣言
8.16.2. 複合型の値の構成
8.16.3. 複合型へのアクセス
8.16.4. 複合型の変更
8.16.5. 問い合わせでの複合型の使用
8.16.6. 複合型の入出力構文
8.17. 範囲型
8.17.1. 組み込みの範囲型
8.17.2. 例
8.17.3. 閉じた境界と開いた境界
8.17.4. 無限の(境界のない)範囲
8.17.5. 範囲の入出力
8.17.6. 範囲の生成
8.17.7. 離散的な範囲型
8.17.8. 新しい範囲型の定義
8.17.9. インデックス
8.17.10. 範囲の制約
8.18. ドメイン型
8.19. オブジェクト識別子データ型
8.20. pg_lsn 型
8.21. 疑似データ型
ライセンス
法的告知
Copyright © 1996-2020 PostgreSQLはPostgreSQLグローバル開発チームが著作権を有します。
Copyright © 1994-1995 Postgres95はカリフォルニア大学評議員が著作権を有します。
N
Permission to use, copy, modify, and distribute this software and its documentation for any purpose, without fee, and without a written agreement is hereby granted, provided that the above copyright notice and this paragraph and the following two paragraphs appear in all copies. [訳注:日本語は参考程度と解釈してください。] 上記の著作権表示、および 本段落と続く2つの段落を全てのコピーに含めることを条件として、無料かつ 書面による許可なしに、このソフトウェアとドキュメントの使用、複製、改変、 頒布をどのような目的にでも許可します。
IN NO EVENT SHALL THE UNIVERSITY OF CALIFORNIA BE LIABLE TO ANY PARTY FOR DIRECT, INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, INCLUDING LOST PROFITS, ARISING OUT OF THE USE OF THIS SOFTWARE AND ITS DOCUMENTATION, EVEN IF THE UNIVERSITY OF CALIFORNIA HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. カリフォルニア大学は、いかなる当事者に対しても、利益の喪失を含む、 直接的、間接的、特別、偶然あるいは必然的にかかわらず生じた 損害について、たとえカリフォルニア大学がこれらの損害の可能性について 知らされていたとしても、一切の責任を負いません。
THE UNIVERSITY OF CALIFORNIA SPECIFICALLY DISCLAIMS ANY WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE SOFTWARE PROVIDED HEREUNDER IS ON AN 「AS-IS」 BASIS, AND THE UNIVERSITY OF CALIFORNIA HAS NO OBLIGATIONS TO PROVIDE MAINTENANCE, SUPPORT, UPDATES, ENHANCEMENTS, OR MODIFICATIONS. カリフォルニア大学は、商用目的における暗黙の保証と、特定目的での 適合性に関してはもとより、これらに限らず、いかなる保証もしません。 以下に用意されたソフトウェアは「そのまま」を基本原理とし、 カリフォルニア大学はそれを維持、支援、更新、改良あるいは修正する 義務を負いません。