はじめに
Elastic社公式ツールであるCuratorを用いて、Index管理運用を実施している中でForce Mergeに掛かった時間やCPU負荷、ディスク使用率の変化など、参考としてまとめてみました。
利用環境
| product | version |
|---|---|
| Curator | 5.6.0 |
| Elasticsearch | 6.6.0 |
| OS(EC2) | Amazon Linux2 |
| AMI ID | ami-04677bdaa3c2b6e24 |
| ※CuratorおよびElasticsearchは現行最新版を利用しています。 | |
| ※AWSリージョンはシンガポール(ap-southeast-1)を利用しています。 |
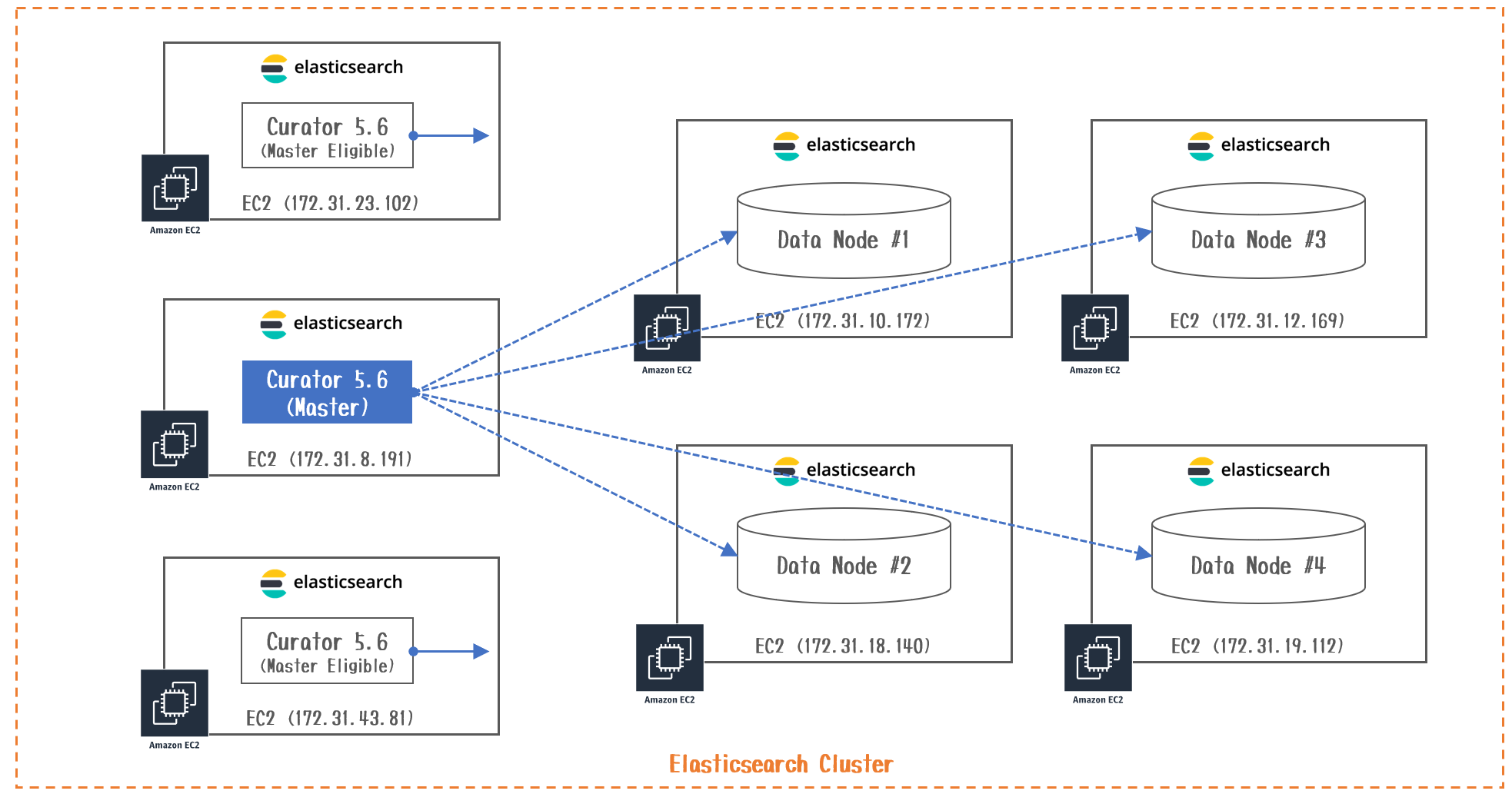
構成図
| NodeType | EC2 InstanceType |
|---|---|
| Master | r5.large |
| Data(#1、#2) | i3.2xlarge |
| Data(#3、#4) | i3.large |
 |
[root@ip-172-31-10-172 ~]# cat /proc/cpuinfo | grep "cpu MHz"
cpu MHz : 2706.182
cpu MHz : 2705.794
cpu MHz : 2714.690
cpu MHz : 2701.995
cpu MHz : 2700.612
cpu MHz : 2720.834
cpu MHz : 2702.359
cpu MHz : 2707.756
[root@ip-172-31-12-169 ~]# cat /proc/cpuinfo | grep "cpu MHz"
cpu MHz : 2484.403
cpu MHz : 2279.959
実施したこと
X-Pack Security機能であるAudit Logで生成される.security_audit_log-YYYY.mm.ddを対象にForce Mergeを実施しました。
Index数は10個、各Indexの容量はPrimaryShardが1.2~1.3GB、ReplicaShardを含めると2.4~2.6GBとなります。(合計:25GB程度)
GET /_cat/indices/.security_audit_log-2019.02.*?v&s=index
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .security_audit_log-2019.02.13 usr5646hSfyMlAKVGx3BOA 5 1 14666469 0 2.5gb 1.2gb
green open .security_audit_log-2019.02.14 Km_vV0QKQt66vaRiu1as3g 5 1 14715845 0 2.6gb 1.3gb
green open .security_audit_log-2019.02.15 BB3CAsLIRNKijYPN_rYUJw 5 1 14520943 0 2.5gb 1.2gb
green open .security_audit_log-2019.02.16 FwOIcjsER36YCUjf6j5tVA 5 1 14304829 0 2.4gb 1.2gb
green open .security_audit_log-2019.02.17 _Qe70E9QQveb5zsLuEWTcQ 5 1 14400868 0 2.5gb 1.2gb
green open .security_audit_log-2019.02.18 MmbNYSbZSouMZ9McL_y1TA 5 1 14680582 0 2.6gb 1.3gb
green open .security_audit_log-2019.02.19 6MguHQ52QyehEWAdT7fvmQ 5 1 14655887 0 2.6gb 1.3gb
green open .security_audit_log-2019.02.20 0cFIhhEwSfuqP14X8wodUQ 5 1 14632516 0 2.5gb 1.2gb
green open .security_audit_log-2019.02.21 ZoLV2-7CS72NSlhc-h9zKQ 5 1 14640680 0 2.5gb 1.2gb
green open .security_audit_log-2019.02.22 pZviMg5rQGSAgu_5Znuv4w 5 1 14635903 0 2.5gb 1.2gb
Force Mergeとは
- Elasticsearchは、Indexをshardと呼ばれる単位で各Data Nodeに分散配置させることで負荷をスケールアウトさせるアーキテクチャになります。
- ShardにはDocummentが格納されていますが、Segmentという単位でデータを保持しています。このSegmentは大きい1つのSegmentに格納されている方が効率的にデータを管理することができ、検索性能に寄与するはずです。(ログ分析では、あまり検索性能に寄与している感じはしないですが...)
- 通常、Merge処理はリソースの状態などに応じて自動的に実行されますが、Force MergeはElasticsearchのリソースを考慮せずに強制的にMerge処理を実行することを指します。CPU使用率やディスク容量などを考慮し、サービス影響を避ける必要があります。
- またMerge処理はSegmentの統合処理になるため、Merge後のSnapshot取得は全てのデータが差分となり、バックアップ対象になってしまうことも意識しておく必要があります。
- Merge後のSegment数はなるべく1個にするのが検索性能的に良いですが、必ず1個に収まるわけではありません。1個のSegmentの最大サイズを超える場合があります。
【参考】
・Forcemerge
・Indices API Force Merge
・Document changes to forcemerge as a breaking change for 6.5
・Remove max_num_segments from _forcemerge
実施してみた
- CuratorのForce Merge用のActionファイルは以下の通りです。
actions:
# Force Mergeを実行する
1:
action: forcemerge
description: >-
options:
max_num_segments: 2
timeout_override: 21600
filters:
- filtertype: pattern
kind: prefix
value: .security_audit_log-
exclude: False
- filtertype: age
source: name
direction: older
timestring: '%Y.%m.%d'
unit: days
unit_count: 1
※1日前よりも古いIndexを対象にshardあたり最大2つのSegmentにMerge
- 以下のcuratorコマンドでForce Mergerを実施します。
[root@ip-172-31-8-191]# curator --config /root/.curator/curator.yml /opt/elasticsearch-curator/action_file/force_
merge_action.yml
- 2:32:53~2:38:48の約6分間で終了しています。
[root@ip-172-31-8-191]# cat /var/log/curator/curator.log
2019-02-24 02:32:53,400 INFO Preparing Action ID: 1, "forcemerge"
2019-02-24 02:32:53,423 INFO Trying Action ID: 1, "forcemerge":
2019-02-24 02:32:53,498 INFO forceMerging selected indices
2019-02-24 02:32:53,498 INFO forceMerging index .security_audit_log-2019.02.17 to 2 segments per shard. Please wait...
2019-02-24 02:33:28,014 INFO forceMerging index .security_audit_log-2019.02.18 to 2 segments per shard. Please wait...
2019-02-24 02:34:04,969 INFO forceMerging index .security_audit_log-2019.02.15 to 2 segments per shard. Please wait...
2019-02-24 02:34:39,235 INFO forceMerging index .security_audit_log-2019.02.20 to 2 segments per shard. Please wait...
2019-02-24 02:35:15,450 INFO forceMerging index .security_audit_log-2019.02.13 to 2 segments per shard. Please wait...
2019-02-24 02:35:48,805 INFO forceMerging index .security_audit_log-2019.02.19 to 2 segments per shard. Please wait...
2019-02-24 02:36:23,123 INFO forceMerging index .security_audit_log-2019.02.22 to 2 segments per shard. Please wait...
2019-02-24 02:37:02,888 INFO forceMerging index .security_audit_log-2019.02.14 to 2 segments per shard. Please wait...
2019-02-24 02:37:37,271 INFO forceMerging index .security_audit_log-2019.02.21 to 2 segments per shard. Please wait...
2019-02-24 02:38:10,335 INFO forceMerging index .security_audit_log-2019.02.16 to 2 segments per shard. Please wait...
2019-02-24 02:38:48,265 INFO Action ID: 1, "forcemerge" completed.
2019-02-24 02:38:48,265 INFO Job completed.
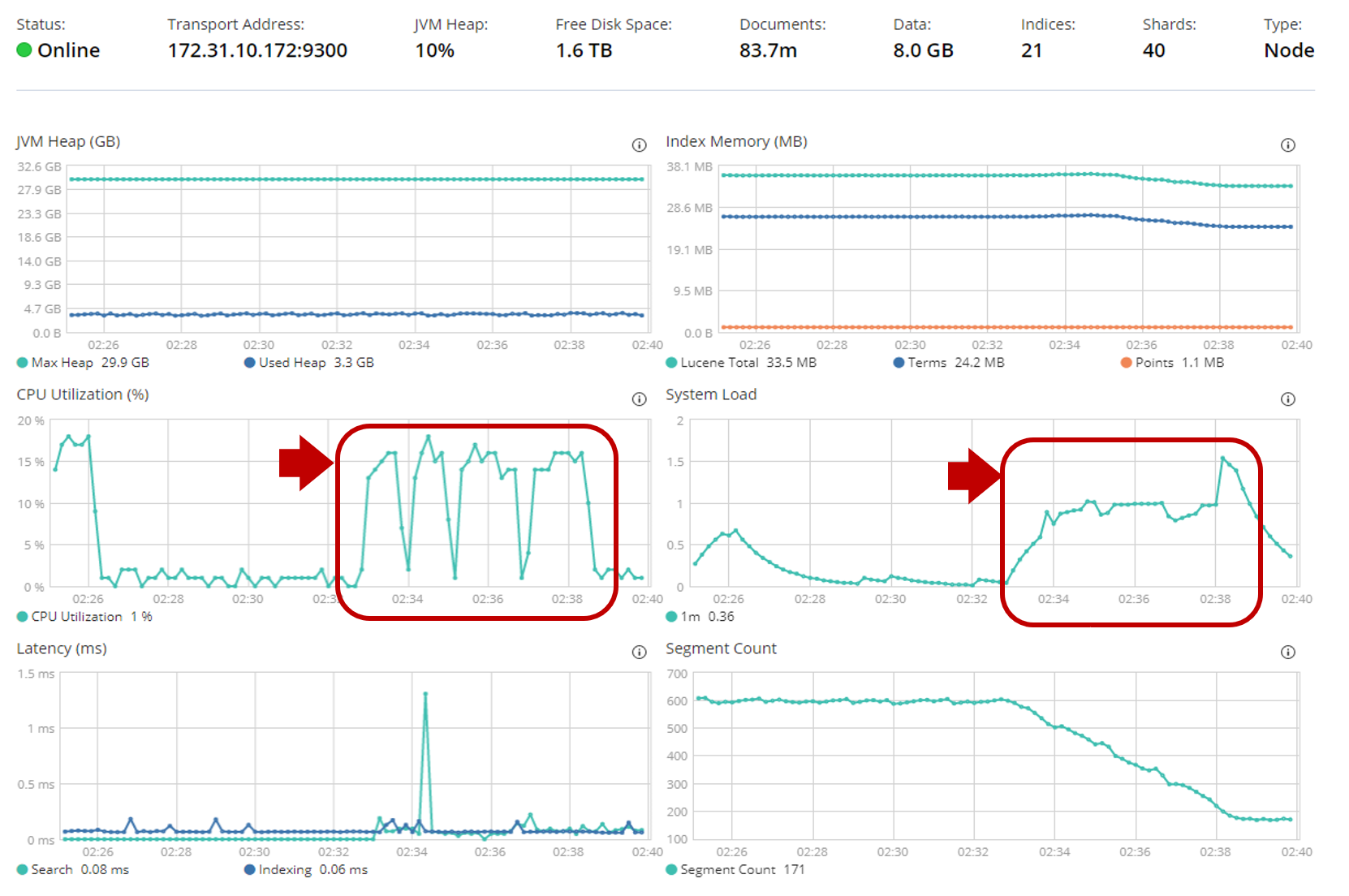
- i3.2xlarge(vCPU8コア)は該当時間中のCPU使用率が**15~20%**程度を推移しています。
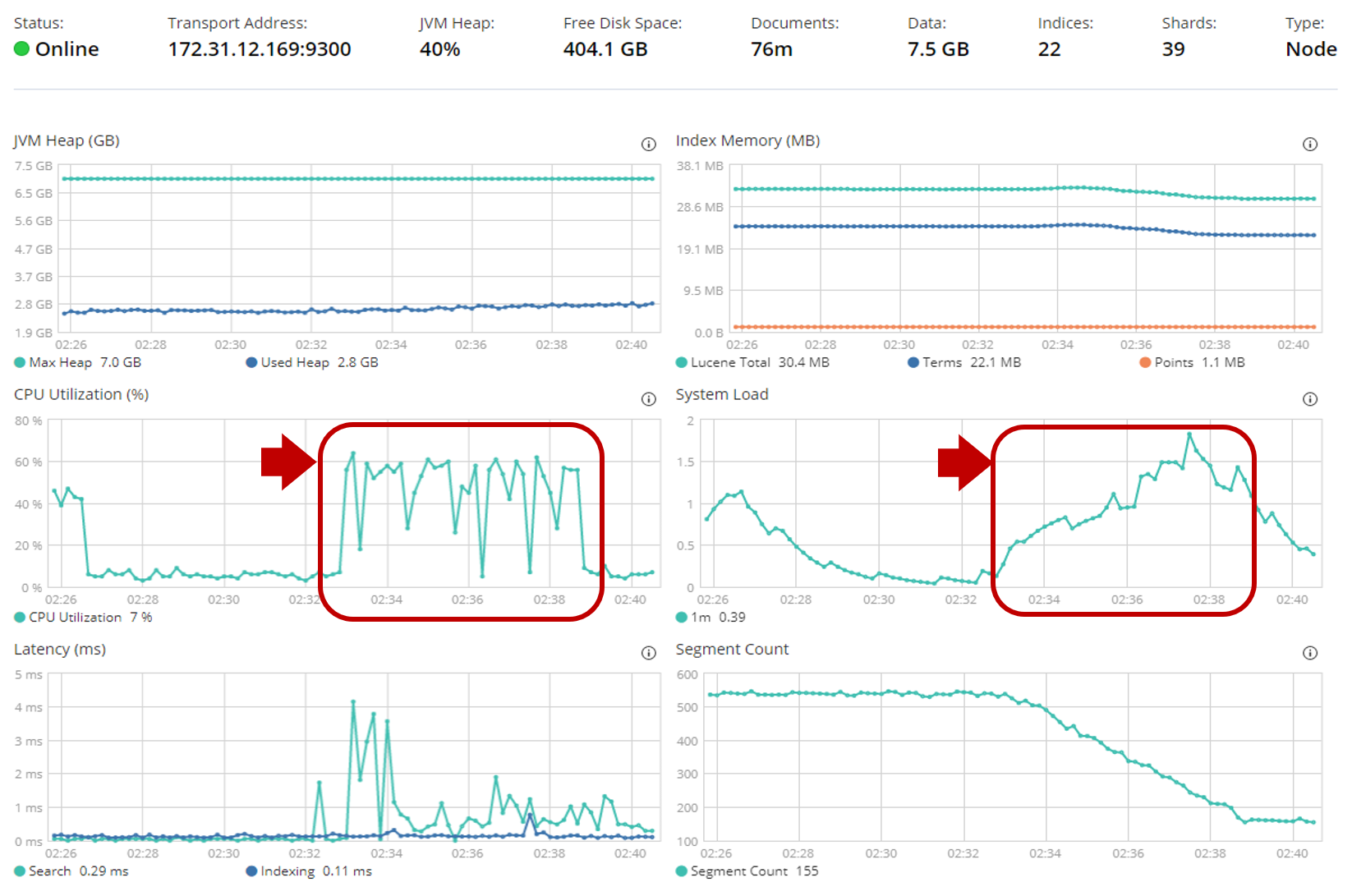
- i3.large(vCPU2コア)は該当時間中のCPU使用率が**60%**程度を推移しています。
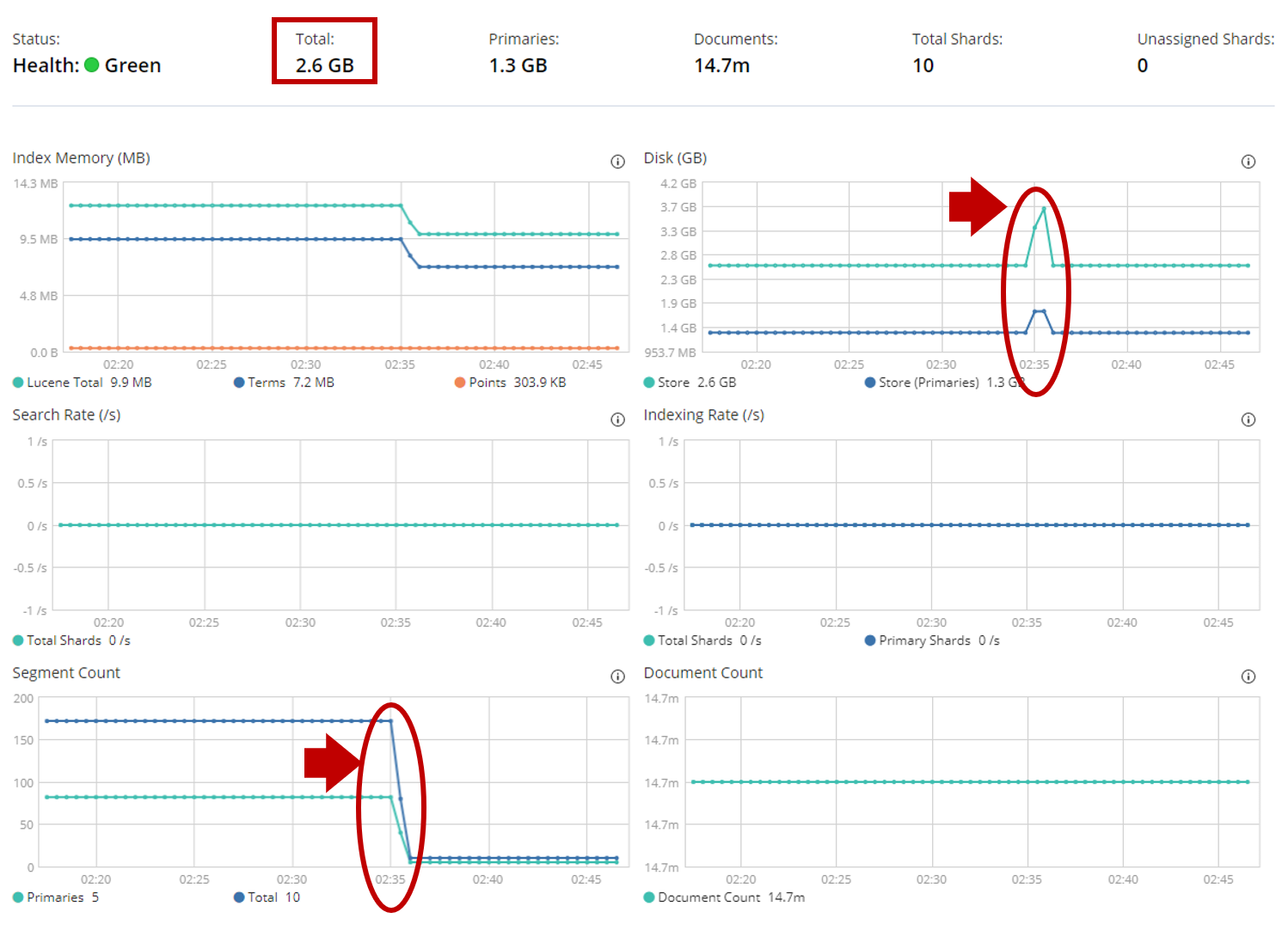
- 各Indexのディスク容量が一時的に約1GB増加し、Merge後に元に戻りました。
- Segment数も170個→10個に大幅削減が出来ました。(お掃除完了!)
まとめ
いかがでしたでしょうか。
2.6GBというサイズのIndexに対して、ディスク容量は1GB程増加していました。
2コアのインスタンスではCPU使用率が50%以上増加していました。
8コアのインスタンスはさすがに余裕がありましたが、それなりにパワーを使いますね。
本番環境において、IndexをPrimaryShard1個(20GB)=ReplicaShard1個(20GB)とした場合、今回の倍くらいの時間とマシンリソースが必要になるという目安を知ることが出来ました。
Force Mergeにより検索性能がどの程度向上するか試すのが楽しみですね^^
cronジョブの実施タイミングはIndex Backupと1時間も空けておけば十分そうですね。
crontab -u root -e
00 00 * * * curator --config /root/.curator/curator.yml /opt/elasticsearch-curator/action_file/force_merge_action.yml
00 01 * * * curator --config /root/.curator/curator.yml /opt/elasticsearch-curator/action_file/index_backup_ation.yml
00 06 * * * curator --config /root/.curator/curator.yml /opt/elasticsearch-curator/action_file/index_delete_ation.yml
30 06 * * * curator --config /root/.curator/curator.yml /opt/elasticsearch-curator/action_file/snapshot_delete_ation.yml
【参考】
・S3 Repository Pluginを使ってElasticsearchのIndexバックアップを取得してみた話