Fastlyがログの宛先としてGoogle Cloud Pub/Subに対応(2020年4月19日時点ではLimited Available)するということで、Ingestlyで計測したログをリアルタイムに扱う実験をして記事にしました → FastlyからCloud Pub/Subにログを直送してDataflowで扱うと幸せになれるというお話
今回はIngestlyのログをリアルタイムに加工して、その結果をBigQueryに書き込む処理をDataflowのジョブとして登録してみます。
具体的には、以下の処理を実現してみます。

準備
前提
- 既にCloud Pub/Subにトピックが作成済みである(例:
ingestly) - 既にFastlyのLoggingで 上記Pub/Sub トピックへのログ送信が構成済みである(かつログにUser-Agentが含まれる)
以下のリソースを作成する
Cloud Storageに今回作成するDataflowジョブ用のバケットを作成する(例: ingestly-files )

上記バケットの中に2つのフォルダ temp と staging を作成する

Cloud Pub/Subに、既存のトピックに対応するサブスクリプションを作成する(例: dataflow )

Dataflowで作業環境としてノートブックインスタンスを作成する(例: ingestly )

BigQueryに宛先となるテーブルを作成する。
テーブルスキーマはIngestly-Dataflowリポジトリのこちらのファイルを使う。
timestamp フィールドでパーティションするのを忘れずに。

Notebookでの作業
今回は一時的な作業環境として使いやすいため、Dataflow内のNotebookを利用します。
もちろんローカルのJupyterのように、Dataflowの外でも同じ作業はできますが、モジュールや認証周りの整備が必要です。
インスタンスが起動したら、Jupyterに入ります。

必要なモジュールをインストールする
メニューで「File」→「New」→「Terminal」を開きます。
開いたターミナルで以下のコマンドを実行し、作業場所を移動&今回必要なモジュールをインストールします。
cd /root/notebook/workspace
pip install google-cloud-pubsub
pip install apache-beam
pip install apache-beam[gcp]
pip install PyYAML ua-parser user-agents

必要なファイルを作成する
メニューで「File」→「New」→「Text File」を開くと新規テキストファイルが作成できるので、2ファイルを作成します。
(作成直後は untitled.txt というファイル名なので、右クリックしてRenameします)
1つはingestly_enrichment.pyで、ジョブを構築する本体のPythonファイルです。
もう一つがrequirements.txtで、外部モジュールをDataflowのジョブで扱う場合に必要になるものです。
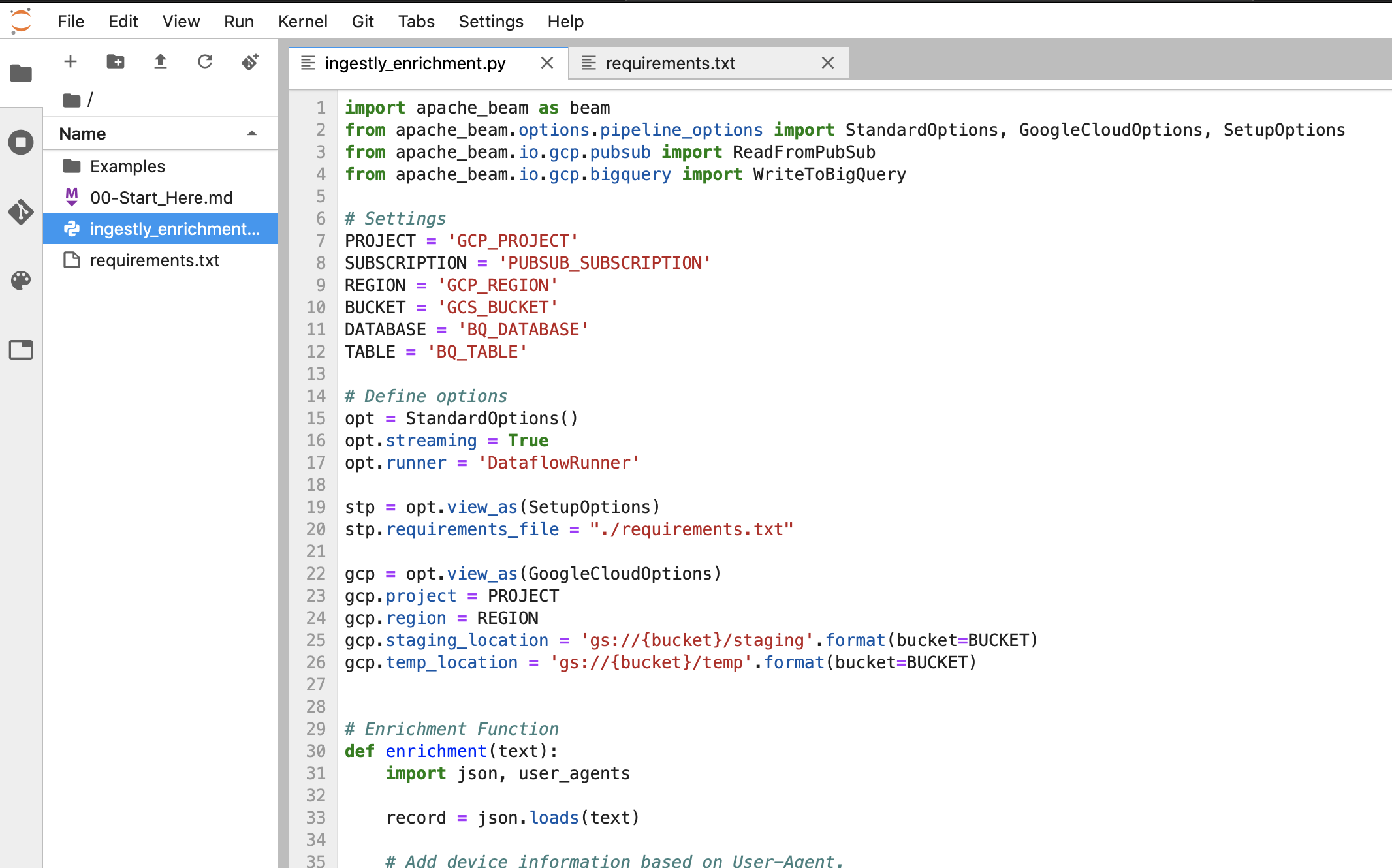
変数に必要情報をセットする
ingestly_enrichment.py の前半に以下の様な行があるので、それぞれ値を設定します。
# Settings
PROJECT = 'GCP_PROJECT'
SUBSCRIPTION = 'PUBSUB_SUBSCRIPTION'
REGION = 'GCP_REGION'
BUCKET = 'GCS_BUCKET'
DATABASE = 'BQ_DATABASE'
TABLE = 'BQ_TABLE'
| 変数 | 意味 | 例 |
|---|---|---|
| PROJECT | GCPのプロジェクト | ingestly-prod |
| SUBSCRIPTION | Cloud Pub/Subで作成したサブスクリプション | dataflow |
| REGION | GCPのリージョン | asia-northeast1 |
| BUCKET | Dataflow関連のファイルを保管するGCSバケット | ingestly-files |
| DATABASE | データ格納先のBigQueryデータベース | ingestly |
| TABLE | データ格納先のBigQueryテーブル | log_enriched |
設定が済むとこのようになります。

スクリプトを実行しジョブを登録する
Notebookのターミナルに戻り、以下のコマンドでスクリプトを実行するとDataflowにジョブが作成されます。
データの加工に使うモジュールを、 enrichment 関数の中でimportしている場合は問題ないのですが、
もしモジュールを先頭でimportしている場合は --save_main_session オプションを付ける必要があります。
python ingestly_enrichment.py --machine_type n1-standard-1 --job_name ingestly-enrichment

Dataflowの「ジョブ」ページでジョブを確認します。
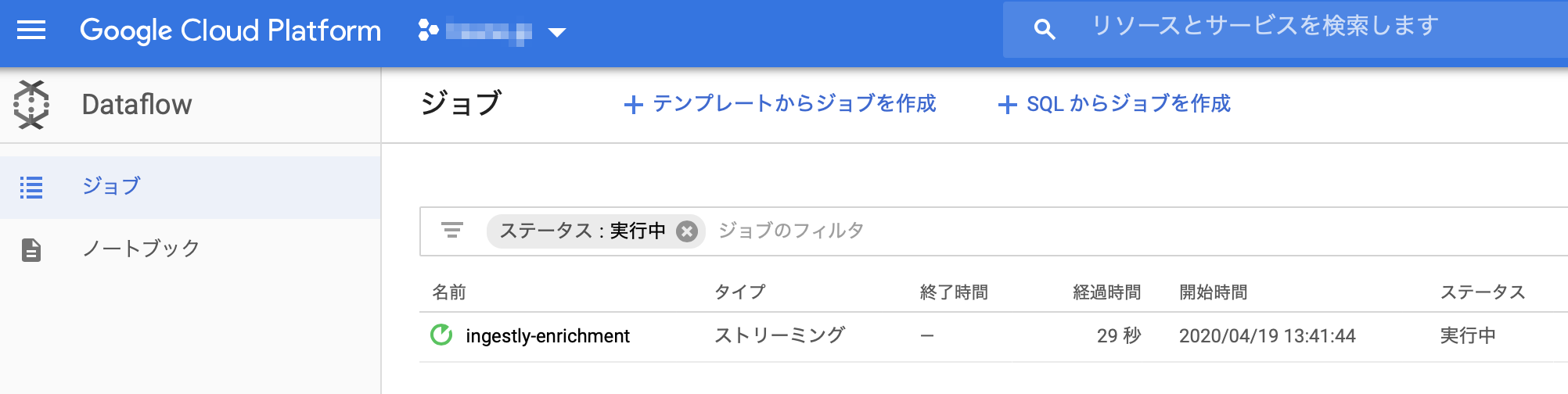
そして、処理の流れがこのように表現されているのが見えます。

結果を確認する
BigQueryのコンソールで以下の様なクエリーを実行すると…
SELECT
er_ua_device_brand,
er_ua_os_family,
er_ua_browser_family,
er_ua_browser_version_string,
COUNT(DISTINCT ingestly_id) as unique_browsers
FROM
ingestly.log_enriched
WHERE
timestamp > '2020-01-01'
GROUP BY
1,
2,
3,
4
今回作成したDataflowを使って、User-Agentから判定したデバイス/ブラウザ情報が確認できます。

まとめ
ということで、(ニア)リアルタイムなデータ拡張がほとんどコピー&ペーストで実現できました。
Pythonの処理を発展させることで外部APIの参照等も簡単に実現できるので、データを蓄積するだけではなくビジネスロジックを組み込んで独自のデータ拡張やデータ連携が構築できると思います。
注意
- この処理を1ヶ月動かすとGCPの費用が $100/月〜 かかります。
- 不要になったジョブや各種リソースは停止または削除しましょう。
- 最小構成の「n1-standard-1」を選択していますが、データ量に応じてマシンタイプやスケーリングの設定は調整しましょう。