Ingestlyを使って分析まではリアルタイム化・高度化ができているのですが、データを真に利用するという意味では施策をトリガーできていなかったので、まだまだという感じでした。
また、データはクライアント側でほとんど作成しており、ビーコンに乗る情報に冗長な点が多い感じも受けます。
この2点を解決できるのが「Enrichment Pipeline」的な処理の仕組みで、ストリームデータに逐次処理を行うようなイメージです。そして、それを実現するにはメッセージングサービスあるいはキューサービスを利用しつつ、publish/subscribe の仕組みを動かすことが基本的な設計パターンになります。
IngestlyはFastlyのLogging機能を使っているので、FastlyがCloud Pub/Subに対応してくれたらな… と願っていました。
(AWSのKafka、MSKを使う手もありますが、GCPのCloud Pub/Subの方が最低料金が低いように思います)
こういうことがしたかった
Ingestly始まって以来構想していたこと…
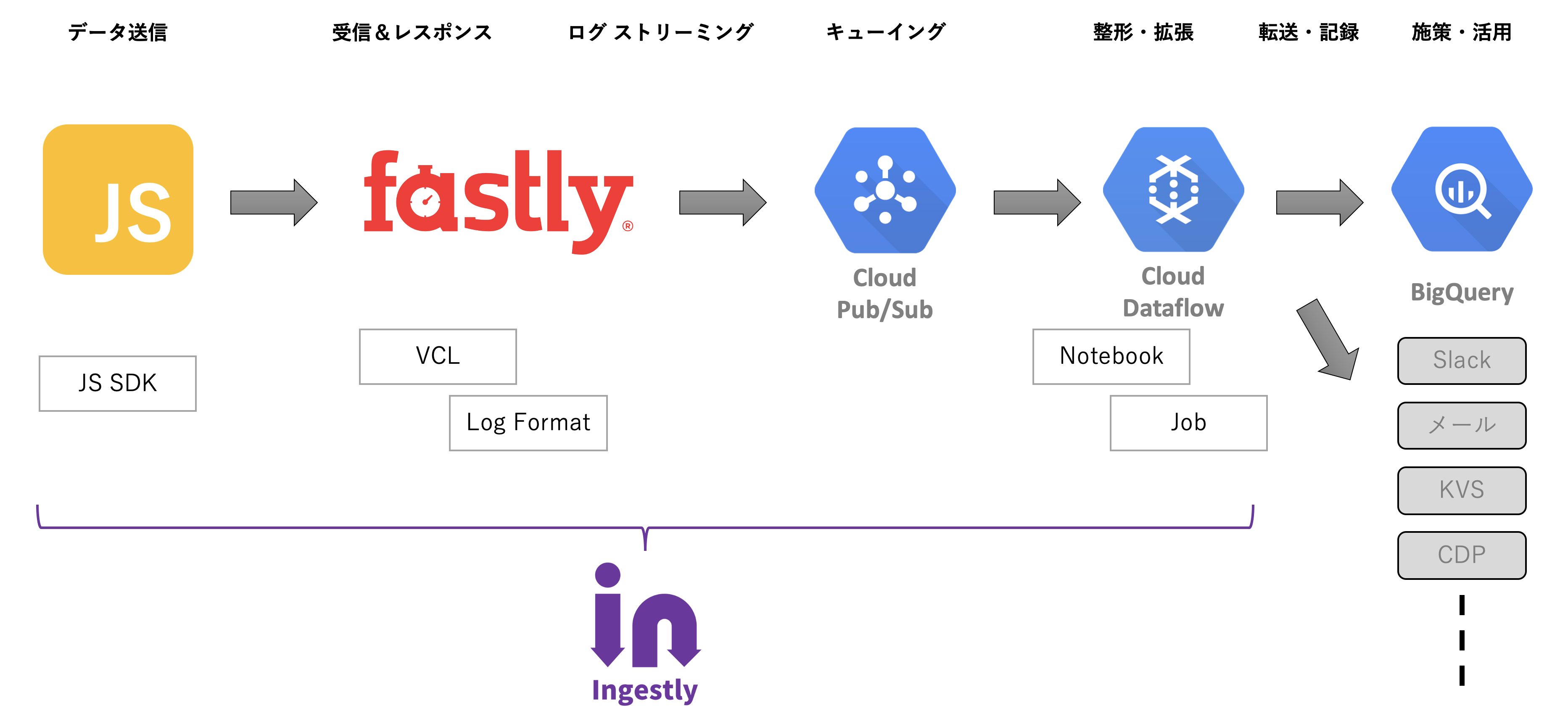
これができると、エンジニアリングリソースが豊富なエンタープライズ企業が内製しているようなデータ処理基盤を、エンジニアリングスキルやインフラ保守の手間をかけずに実現できます。
FastlyがGoogle Cloud Pub/Subへのログストリーミングに対応する
Ingestlyプロジェクトの大前提であるFastlyがついに、GCPのGoogle Cloud Pub/Subにログをストリーミングできるようになるそうです!
FastlyのLoggingはBigQueryをはじめ様々な宛先にログを渡せるのですが、どちらかというとインフラのアクセスログを扱うようなサービスが多い印象でした。Ingestlyはデジタルマーケティングにおけるリアルタイムデータの収集・活用の起点となることを目指しているので、ストリームデータ処理に不可欠なキューイングやメッセージング的な宛先にログを渡せたらな…と考え、昨年からCloud Pub/Subへの対応をお願いしていました。
そして、2020年4月…現時点ではLA(Limited Available)としてCloud Pub/SubをLoggingの宛先に指定できるようになり、私の環境で有効化してもらいました。

インフラのログ的にLoggingを使っていると、Cloud Pub/Subへの対応は興奮するほどのベネフィットではないかもしれません。しかし、デジタルマーケティングやアクショナブルなデータをリアルタイムに扱う上では、Cloud Pub/Subへの対応は劇的な改善です。ログをDBに入れてしまうと、基本的にはクエリーして取り出さなければならないので、バッチ処理ベースで重い処理を繰り返しますが、マーケティング的にはデータの賞味期限が切れていく… Cloud Pub/Subでは一件一件のログを常に処理し続けることができるので、ログが到着した瞬間に必要な処理を行う、プッシュ型のデータ処理が可能になります。
しかも、GCPなのでApache BeamベースのDataflowから扱えてしまうのです。つまり、リアルタイムデータを扱う上で気になるインフラのスケーリングやスパイク耐性という点で、FastlyとGoogleが前段を全て巻き取ってくれるので、運用管理の工数がほとんどかからずに、エンタープライズ級のリアルタイムデータ処理が実現できてしまいます。
DataflowはJava、Go、そしてPythonで処理を書くことができ、PythonであればDataflowに組み込まれたJupyter Notebookが利用できます。どうしてもデータ処理基盤を作ろうとすると高度なエンジニアリングが必要な印象がありますが、データ界隈で多用されるJupyterでできてしまうのが便利だなと感じます。
なぜCloud Pub/Subが嬉しいのか
同じコンセプトの基盤を作るのは2回目で、前回は4年前にいた会社で内製したときでした。
当時リアルタイムデータ基盤を作ったときに重要視していたこととして、
- サービス利用者とのコミュニケーションを円滑にする、データの賞味期限を切らさず活かす → リアルタイム
- 人間の時間が最も高額なリソースである → 省力化・複雑さの排除・工数削減
- 同じ処理を何度もしない → Pre-JOIN、Enrichment Pipelineで事前処理
- アクショナブル → 人が介在しなくても施策を動かせる
- 安い、速い、スパイク耐性&自動復旧 をバランス
といった思想がありました。
データを集めて記録するだけではなく、マーケティングをはじめとするデータの出口としっかり繋がることで、データ利用が業務フローに「上乗せ・add-on」ではなく「浸透・Penetration」するための要件でした。
Ingestlyに取り組んだ動機も、これをエンジニアに恵まれた企業やエンタープライズ規模の組織だけにできることではなく、個人事業主〜中小企業でも取り組めるようにするというものでした。
これを実現するためには、DBに記録する前段で任意の処理を挟む余地が必要です。スパイク耐性や省力化を考えると、Fastlyのインフラと、キューイングあるいはメッセージングの仕組みをはさみ確実にデータを受け取りつつバッファリングできればいいのです。
そして、任意の処理を挟むことで、データを逐次処理して以下の様にDBへの記録以外の処理を発火させることができるのです。
- User-Agentからデバイス判定をしたり、URLをパースしてDBで扱いやすいよう別フィールド化する(加工、整形、あるいはEnrichment Pipeline)
- マスターテーブルやKVSを参照してレコードに豊富なコンテキストを付与する
- NPSのようなアンケート結果をJSで送出しSlackに通知する
- キャンペーンへの応募があったら30分後にメールを送るよう予約する
- 既読記事をユーザー毎にDynamo DBに記録し、デバイス横断で既読記事情報を扱う
- 本文の80%以上が読まれた記事のみをElasticsearchに記録しレコメン精度を上げる
- 複数のビーコンを配列として送り、Dataflowで分割して扱うことで計測のための通信のオーバーヘッドを削減する
- モデルをリアルタイムに適用し、イベントに対して何らかの予測を行う
- Fastlyが対応していないエンドポイントにログを渡す
- 訪問者の行動を元に、SSRをトリガーしてキャッシュさせるとか、キャッシュをパージする処理を複雑な条件で制御する
- Loggingで指定の宛先にうまくログが書き込めない場合の出バグにも使えそう
こんなことを、簡単な仕組みで、しかもデータ界隈でエンジニア人口が多めのPythonでできたら、多くの企業で製品開発やマーケティングのレベルアップに繋がるのでは、と考えています。
試してみた
ということで、まずは実際にCloud Pub/Sub → Dataflow(のJupyterノートブック)で動くところを確認します。
Cloud Pub/Sub
トピックを作成
まずはCloud Pub/Subのコンソールでトピックを作成する。
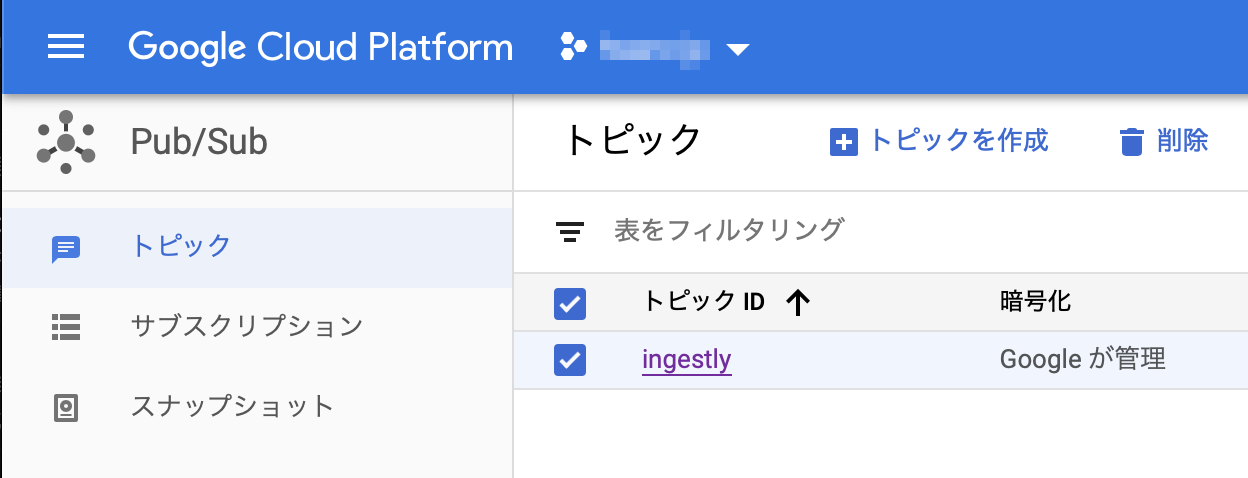
とはいっても名前を決めるだけ。
これがFastlyからログを受け取る口となる。
サブスクリプションを作成
同じくCloud Pub/Subのコンソールでサブスクリプションを作成する。
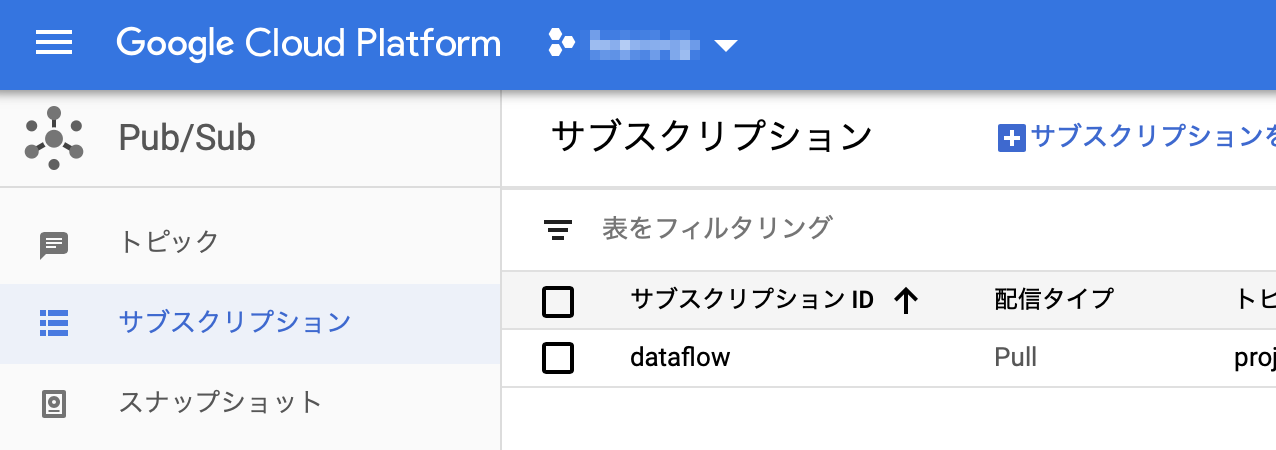
ストリームデータ処理に特化するのであればデータの保持期間は短くても良いかもしれない。
Pythonから操作する場合、トピックを指定することもできるがその場合は裏で自動的にサブスクリプションが作成されるため、試行錯誤していて消し忘れると課金に影響するので注意。
Fastly
Ingestlyを構成済みという前提で、新たに設定する部分としては…
CONFIGURE → Logging のページで「Google Cloud Pub/Sub」を追加する。
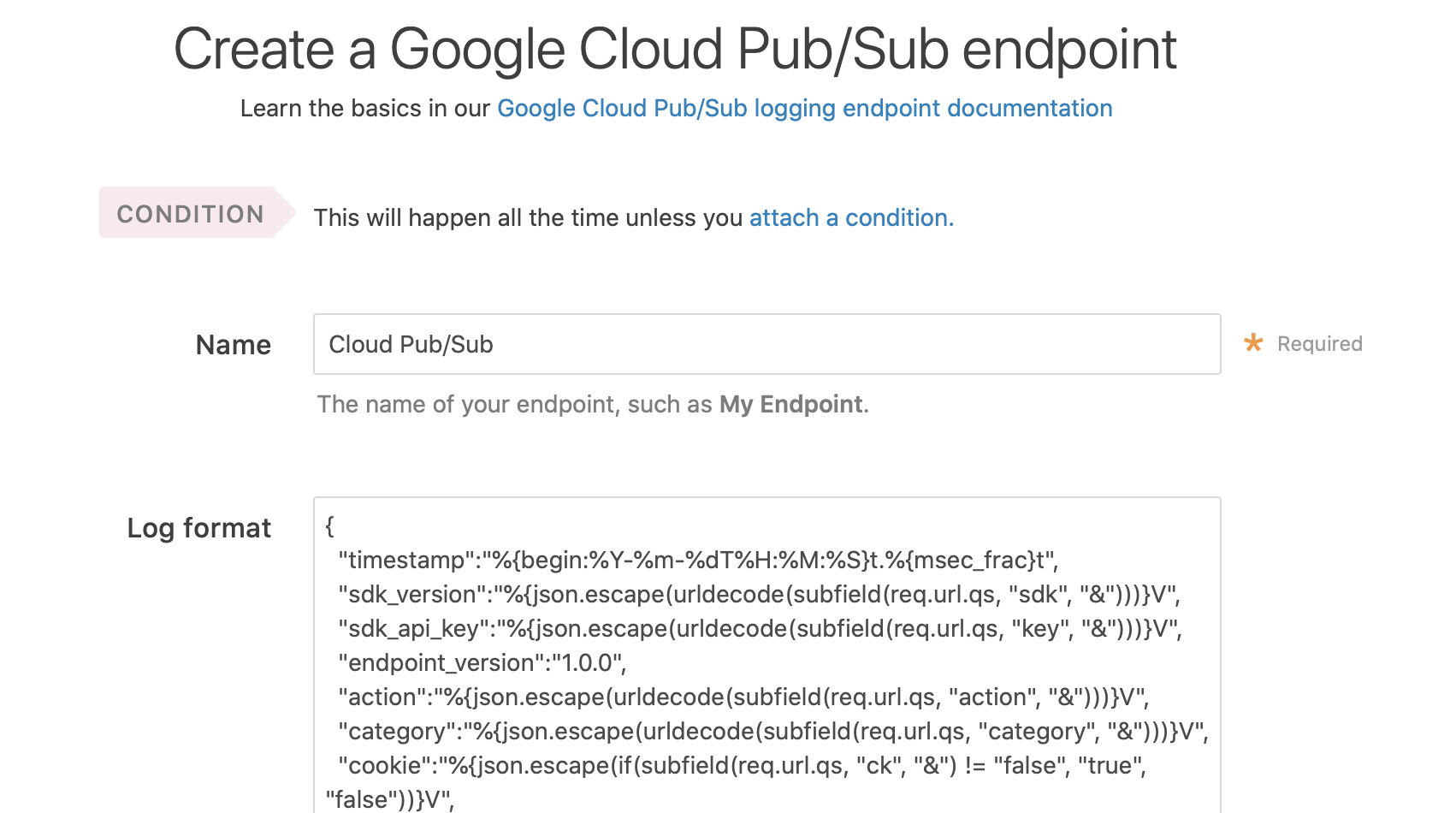
設定内容はIngestlyのBigQueryと全く同じで問題なかった。BigQuery用のログフォーマットをそのまま利用した。
Dataflow
今回はあくまでデータが到着すること、そしてリアルタイムにPythonで処理できることを検証するのでジョブやテンプレートの作成はしない。(後日公開予定)
Dataflowのコンソールで、「ノートブック」を開き、適当なサイズのインスタンスを作成する。
初期状態で選択されているマシンタイプが n1-standard-4 だけど、検証では n1-standard-1 に変更した。
「JUPYTERLABを開く」からノートブックを開き以下の様にPythonをちょこちょこっと書く。
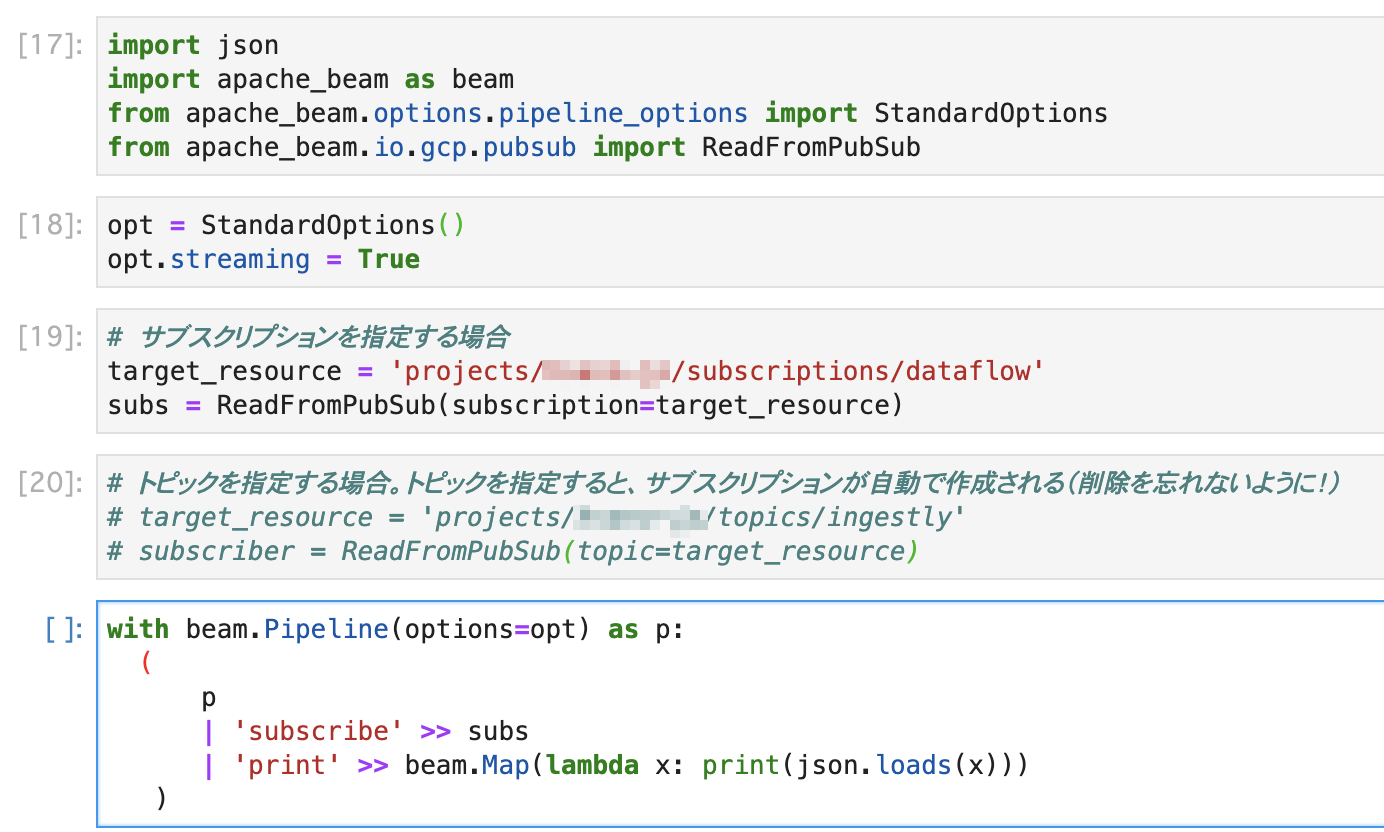
具体的には…
モジュールをインポートして…
import json
import apache_beam as beam
from apache_beam.options.pipeline_options import StandardOptions
from apache_beam.io.gcp.pubsub import ReadFromPubSub
オプションを指定…
opt = StandardOptions()
opt.streaming = True
連携するPub/Subリソースを指定して… ( target_resource を環境に合わせて指定すること )
# サブスクリプションを指定する場合
target_resource = 'projects/YOUR_PROJECT/subscriptions/dataflow'
subs = ReadFromPubSub(subscription=target_resource)
# トピックを指定する場合。トピックを指定すると、サブスクリプションが自動で作成される(削除を忘れないように!)
# target_resource = 'projects/YOUR_PROJECT/topics/ingestly'
# subscriber = ReadFromPubSub(topic=target_resource)
受信を開始する
with beam.Pipeline(options=opt) as p:
(
p
| 'subscribe' >> subs
| 'print' >> beam.Map(lambda x: print(json.loads(x)))
)
この例のように単純にノートブックから実行する分にはApache BeamやGCP関連のモジュールのインストールはしなくても動作する。
Ingestlyで計測しているサイトにアクセスする

このように、ビーコンが到着すると順次JSONを処理できることが確認できた。
謝辞
Ingestlyプロジェクトを始めて1年が経ち、自分のコンセプトを実証するだけでなく、僅かではあるものの企業が利用するまでに至りました。数人のコントリビューターの手でエンドポイントもクライアントSDKも改良を重ねてきました。
データを受け取るエンドポイントとしてデザインの前提になっているFastlyには、バックエンドを必要とせずエッジ側で全ての処理を完結してくれる、スケーリングを気にせずメンテナンスフリーに使えるコンピューティング環境的な役割として、さらにオープンソースソフトウェアプロジェクトの支援者として多くの機会を創っていただいています。ありがとうございます!
この次は…
Dataflowでデータの整形、外部APIの呼び出し、他のDBへのデータ投入、についてジョブを作成して動かす部分を記事にする予定です。
参考にした記事
Python+Cloud DataflowのPubSubストリーミングをGoogle Colaboratory使って試す - YOMON8.NET