Section1 強化学習
強化学習とは
長期的に報酬を最大化できるように環境の中で行動を選択できるエージェントを作ることを目標とする機械学習の一分野
→ 行動の結果として与えられる利益(報酬)を基に、行動を決定する原理を改善していく仕組み
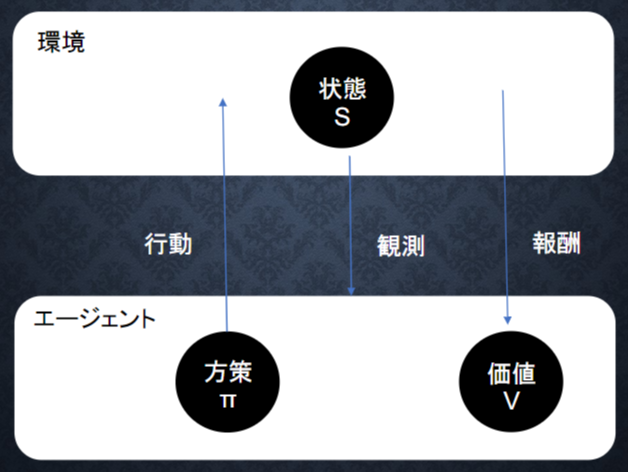
エージェント:主人公
エージェントが方針に基づいて行動しそれに見合う環境から報酬がもらえる
報酬が最大になるように方針を訓練していくイメージ
強化学習の応用例
マーケティングの場合
エージェント:プロフィールと購入履歴に基づいて、キャンペーンメールを送る顧客を決めるソフトウェアである。行動:顧客ごとに送信、非送信のふたつの行動を選ぶことになる。報酬:キャンペーンのコストという負の報酬とキャンペーンで生み出されると推測される売上という正の報酬を受ける
探索と利用のトレードオフ
利用が足りない状態⇔探索が足りない状態がトレードオフの関係
強化学習ではこれをうまく調整していく
探索が足りない状態
過去のデータでベストとされる行動のみを常にとり続ければ、他のさらにベストな行動を見つけることはできない
利用が足りない状態
未知の行動のみを常にとり続ければ、過去の経験が活かせない
強化学習の差分
強化学習と通常の教師あり、教師なし学習との違い
目標が違う ・教師なし、あり学習では、データに含まれるパターンを見つけ出す およびそのデータから予測することが目標
強化学習では、優れた方策を見つけることが目標
価値関数
価値を表す関数としては、状態価値関数と行動価値関数の2種類がある
状態価値関数
価値を決める際環境の状態の価値に注目する場合
環境の状態が良ければ価値が上がる
エージェントの行動は関係ない
V^{\pi}(s)
行動価値関数
価値を決める際環境の状態と価値を組み合わせた価値に注目する場合
エージェントがある状態で行動したときの価値
Q^{\pi}(s,a)
方策関数
ある環境の状態においてどのような行動をとるのか確率を与える関数
\pi(s)=a
方策勾配法
方策をモデルにすることで最適化する手法
\theta^{(t+1)}=\theta^{(t)}+\epsilon\nabla J(\theta)
\nabla_{\theta}J(\theta)=\mathbb{E}_{\pi_{\theta}}[(\nabla_{\theta}log\pi_{\theta}(a|s)Q^{\pi}(s,a))]
$t$:時間
$\theta$:重み
$\epsilon$:学習率
$J$:誤差関数
Section2 Alpha Go
AlphaGo LeeとAlphaGo Zero二種類ある
AlphaGo Lee
ValueNetとPolicyNetのCNNを利用している
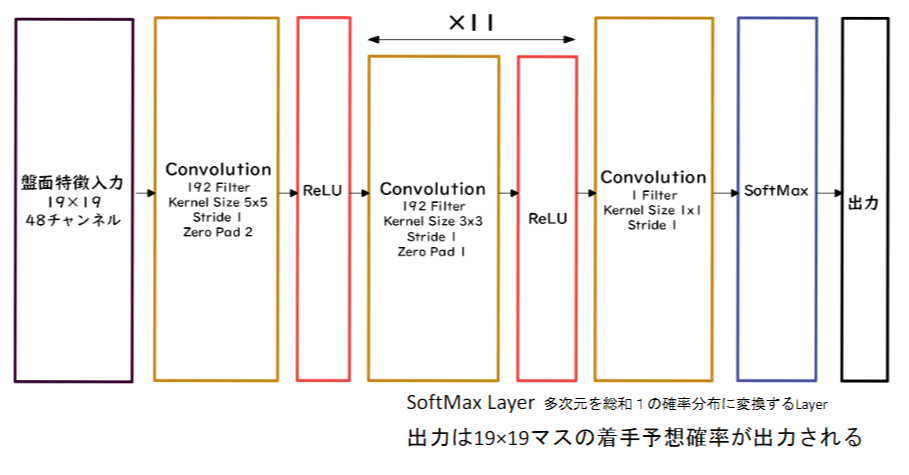
PolicyNet(方策関数)
19x19の2次元データを利用
48チャンネル持っている
19x19の着手予想確率得られる
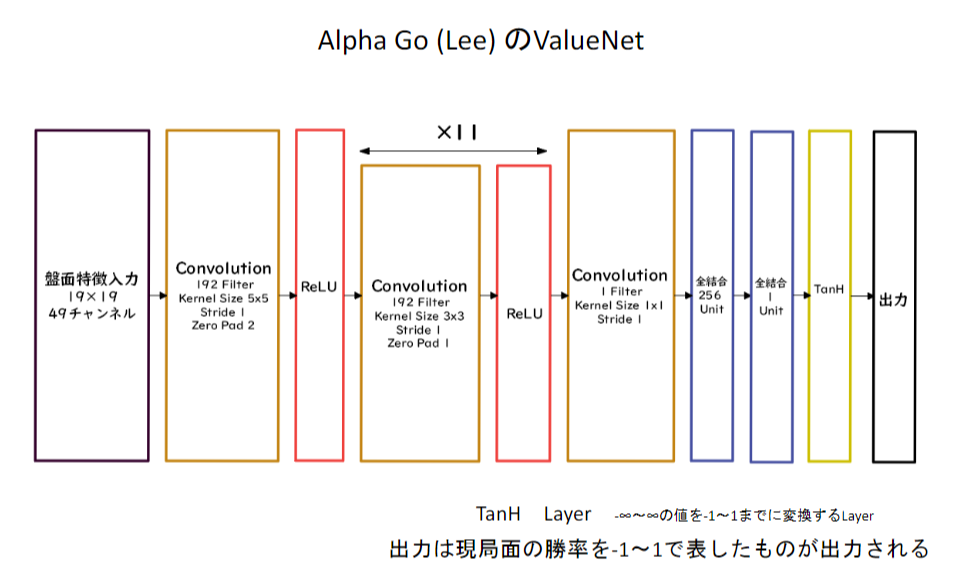
ValueNet(価値関数)
19x19の2次元データを利用
49チャンネル持っている(手番が追加)
勝率を-1~1の範囲で得られる
勝つか負けるかの出力であるためFlattenを挟んである
Alpha Go Leeの学習ステップ
1.教師あり学習でRollOutPolicyとPolicyNetの学習
2.強化学習でPolicyNetの学習
3.強化学習でValueNetの学習
RollOutPolicy
NNではなく線形の方策関数
探索中に高速に着手確率を出すために使用される。
モンテカルロ木探索
コンピューター囲碁ソフトで現在もっとも有効とされている探索法
AlphaGo Zero
AlphaGo LeeとAlphaGo Zeroの違い
1.教師あり学習を一切行わず、強化学習のみで作成
2.特徴入力からヒューリスティックな要素を排除し、石の配置のみにした
3.PolicyNetとValueNetを1つのネットワークに統合した
4.Residual Net(後述)を導入した5、モンテカルロ木探索からRollOutシミュレーションをなくした
PolicyValueNet
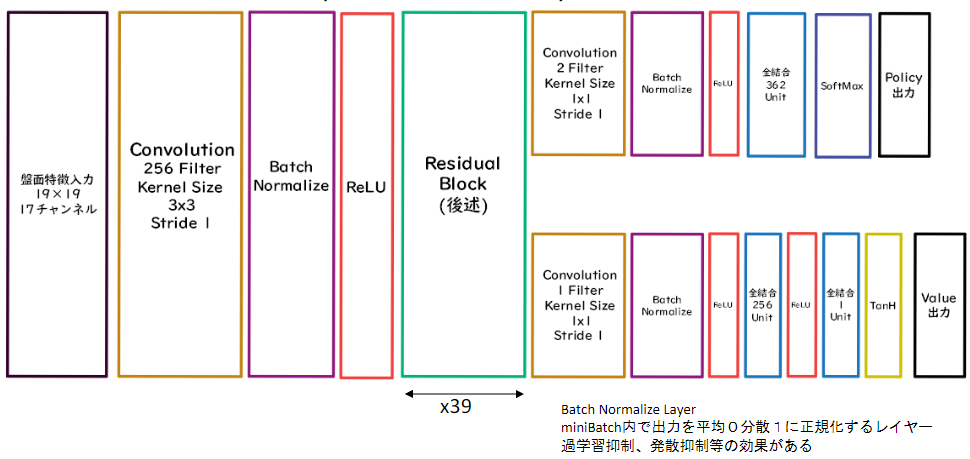
PolicyNetとValueNetが統合し、それぞれ方策関数と価値観数の出力が得たいため途中で枝分かれした構造のNNとなる。
Residual Block
ネットワークにショートカットを作る
ネットワークの深さを抑える
勾配消失問題が起きにくくなる
基本構造はConvolution→BatchNorm→ReLU→Convolution→BatchNorm→Add→ReLU
アンサンブル効果
PreActivation
Residual Blockの並びをBatchNor→ReLU→Convolution→BatchNorm→ReLU→Convolution→Addにして性能向上
wideResNet
Convolutionのフィルタをk倍にしたResNet。
フィルタを増やすことで層が浅くても深い層のものと同等以上の性能を発揮
PyramidNet
各層でフィルタ数を増やしていくResNet
aection3 軽量化・高速化技術
どうやってモデルを高速に学習するか
どうやって高性能ではないコンピューターでモデル動かすか
分散深層学習
- 深層学習は多くのデータを使用したり、パラメータ調整のために多くの時間を使用したりするため、高速な計算が求められる
- 複数の計算資源(ワーカー)を使用し、並列的にニューラルネットを構成することで、効率の良い学習を行いたい
- データ並列化、モデル並列化、GPUによる高速技術は不可欠である
データ並列
- 親モデルを各ワーカー(コンピューターなど)に子モデルとしてコピー
- データを分割し、各ワーカーごとに計算させる
コンピューター自体やGPUやTPUなどを増やし計算を分散し学習を高速にする
データ並列化は各モデルのパラメータの合わせ方で、同期型か非同期型か決まる
同期型
同期型のパラメータ更新の流れ。各ワーカーが計算が終わるのを待ち、全ワーカーの勾配が出たところで勾配の平均を計算し、親モデルのパラメータを更新する。
非同期型
各ワーカーはお互いの計算を待たず、各子モデルごとに更新を行う。学習が終わった子モデルはパラメータサーバにPushされる。新たに学習を始める時は、パラメータサーバからPopしたモデルに対して学習していく
同期・非同期の比較
- 処理のスピードは、お互いのワーカーの計算を待たない非同期型の方が早い
- 非同期型は最新のモデルのパラメータを利用できないので、学習が不安定になりやすい
-> Stale Gradient Problem - 現在は同期型の方が精度が良いことが多いので、主流となっている。
モデル並列
- 親モデルを各ワーカーに分割し、それぞれのモデルを学習させる。全てのデータで学習が終わった後で、一つのモデルに復元
- モデルが大きい時はモデル並列化を、データが大きい時はデータ並列化をすると良い
モデルのパラメータが多い場合ほど、効率化も向上する
GPUによる高速化
GPGPU (General-purpose on GPU)
元々の使用目的であるグラフィック以外の用途で使用されるGPUの総称
CPU
高性能なコアが少数
複雑で連続的な処理が得意
GPU
比較的低性能なコアが多数
簡単な並列処理が得意
ニューラルネットの学習は単純な行列演算が多いので、高速化が可能
GPGPUの開発環境
CUDA
GPU上で並列コンピューティングを行うためのプラットフォーム
NVIDIA社が開発しているGPUのみで使用可能
Deep Learning用に提供されているので、使いやすい
OpenCL
オープンな並列コンピューティングのプラットフォーム
NVIDIA社以外の会社(Intel, AMD, ARMなど)のGPUからでも使用可能
Deep Learning用の計算に特化しているわけではない
軽量化
- 量子化
- 蒸留
- プルーニング
量子化はよく使用されている
量子化
ネットワークが大きくなると大量のパラメータが必要なり学習や推論に多くのメモリと演算処理が必要
→通常のパラメータの64 bit 浮動小数点を32 bit など下位の精度に落とすことでメモリと演算処理の削減を行う
数十億個のパラメータがあると重みを記憶するために多くのメモリが必要
パラメータ一つの情報の精度を落とし記憶する情報量を減らしていく
倍精度演算(64 bit)と単精度演算(32 bit)は演算性能が大きく違うため、量子化により精度を落とすことによりより多くの計算をすることができる。
16bitが無難
メリット
計算の高速化
省メモリ化
デメリット
精度の低下
蒸留
精度の高いモデルはニューロンの規模が大きなモデルとなっていてそのため、推論に多くのメモリと演算処理が必要
→規模の大きなモデルの知識を使い軽量なモデルの作成を行う
モデルの簡約化
学習済みの精度の高いモデルの知識を軽量なモデルに継承させる
メリット
蒸留によって少ない学習回数でより精度の良いモデルを作成することができる
プルーニング
ネットワークが大きくなると大量のパラメータがすべてのニューロンが計算の精度に関係しているわけではない
→モデルの精度に寄与が少ないニューロンを削除することでモデルの軽量化・高速化する
ニューロン数と精度
精度にどのくらい寄与しているかの閾値を決めニューロン削除するものをきめる
閾値が高くすることによりニューロン数が減少し精度が減少する
Section4 応用技術
実際に使用させてるモデルを紹介
※
横幅:$H$
縦幅:$W$
チャンネル:$C$
フィルタ数:$M$
一般的な畳み込みレイヤー
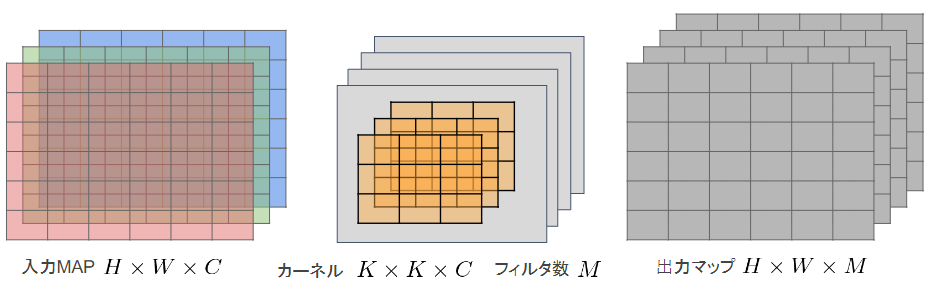
- 入力マップ(チャンネル数):$H\times W\times C$
- 畳み込みカーネルサイズ:$K\times K\times C$
- 出力チャンネル数:$M$
全出力の計算量:$H\times W\times K\times K\times C\times M$
一般な畳込みレイヤーは計算量は多い
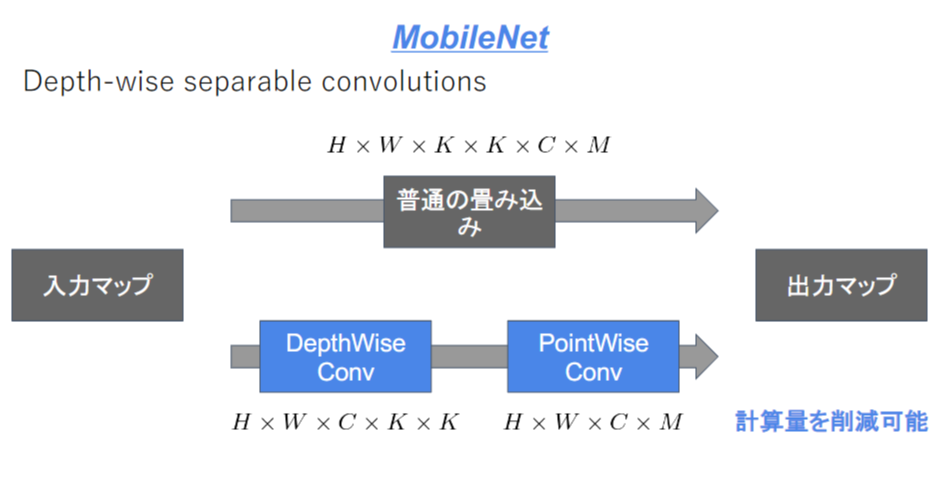
MobileNet
画像認識モデルの軽量化版
Depthwise ConvolutionとPointwise Convolutionの組み合わせで軽量化を実現
Depthwise Convolution
入力マップのチャネルごとに畳み込みを実施
出力マップをそれらと結合
通常の畳み込みカーネルは全ての層にかかっていることを考えると計算量が大幅に削減可能
各層ごとの畳み込みなので層間の関係性は全く考慮されない。通常はPW畳み込みとセットで使うことで解決
フィルタの数(M)分計算量が削減
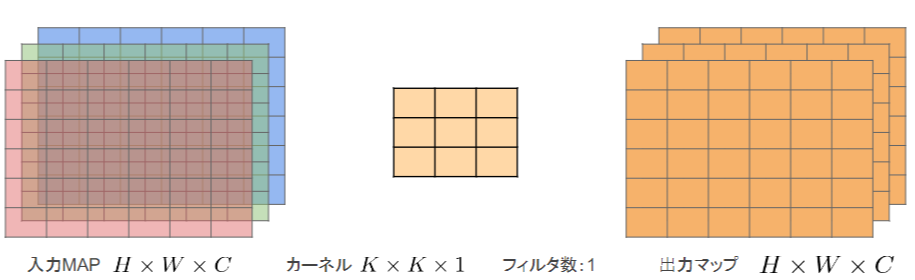
全出力の計算量:$H\times W\times C\times K\times K$
(一般的な全出力の計算量:$H\times W\times K\times K\times C\times M$)
Pointwise Convolution
1 x 1 convとも呼ばれる
入力マップのポイントごとに畳み込みを実施
出力マップ(チャネル数)はフィルタ数分だけ作成可能(任意のサイズが指定可能)
$K \times K$分の計算量が削減
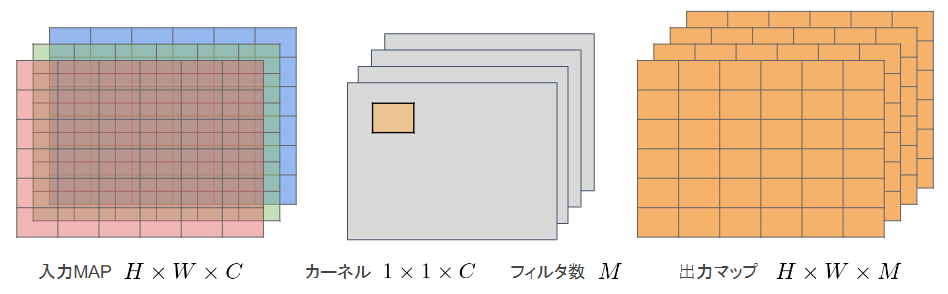
全出力の計算量:$H\times W\times C\times M$
(一般的な全出力の計算量:$H\times W\times K\times K\times C\times M$)
まとめ
一般的な畳み込み計算をDepthwise Convolutionの出力をPointwise Convolutionに分けて計算を行うことによって計算を量を削減している
DenseNet
画像認識のネットワーク
NNでは層が深くなるにつれて、学習が難しくなるという問題があったが
ResNetなどのCNNアーキテクチャでは前方の層から後方の層へアイデンティティ接続を介してパスを作ることで問題を対処した。DenseBlockと呼ばれるモジュールを用いた、DenseNetもそのようなアーキテクチャの一つである
初期の畳み込み→Denseブロック→変換レイヤー→判別レイヤー

DenseBlock
出力層の前の層の竜力を足し合わせる
次第にチャンネル増える構造になっている
具体的にはBatch正規化→Relu関数による変換→畳み込み層による処理
前スライドで計算した出力に入力特徴マップを足し合わせる
入力特徴マップのチャンネル数が$l \times k$だった場合、出力は$(l+1) \times k$となる
第l層の出力をとすると
$$
x_1 = H_1([x_0,x_1,x_2, \dots ,x_{l-1}])
$$
一層通過するごとにkチャンネルづつ増える場合kをネットワークの「growth rate」と呼ぶ
Transition Layer
CNNでは中間層でチャネルサイズを変更する(DenseBlockの入力前のサイズ戻すなど)
特徴マップのサイズを変更し、ダウンサンプリングを行うため、Transition Layerと呼ばれる層でDence blockをつなぐ
DenseNetとResNetの違い
DenseBlockでは前方の各層からの出力全てが後方の層への入力として用いられ
RessidualBlockでは前1層の入力のみ後方の層へ入力
BatchNorm
レイヤー間を流れるデータの分布を、ミニバッチ単位で平均が0・分散が1になるように正規化
$H \times W \times C$のsampleがN個あった場合に、N個の___同一チャネル___が正規化の単位(色で単位で)
Batch Normalizationはニューラルネットワークにおいて学習時間の短縮や初期値への依存低減、過学習の抑制など効果がある
Batch Normの問題点
Batch Sizeの影響をうけミニバッチのサイズを大きく取れない場合には、効果が薄くなってしまう
ハードウェアによってミニバッチ数を変更しなければならなく効果が実験しづらい
Batch Sizeが小さい条件下では、学習が収束しないことがあり、代わりにLayer Normalizationなどの正規化手法が使われることが多い
Layer Norm
N個のsampleのうち___一つに注目___。$H \times W \times C$の___全てのpixel___が正規化の単位(画像一枚単位で)
ミニバッチの数に依存しないBatch Normの問題点を解消
Instance Norm
各sampleの各チャンネルごとに正規化
コントレスト正規化に寄与・画像スタイル転送やテクスチャ合成タスクなどで利用
Wavenet
音声生成モデル→時系列データ
生の音声波形を生成する深層学習モデル
Pixel CNNを音声に応用したもの
時系列データに対して畳み込みを適用する
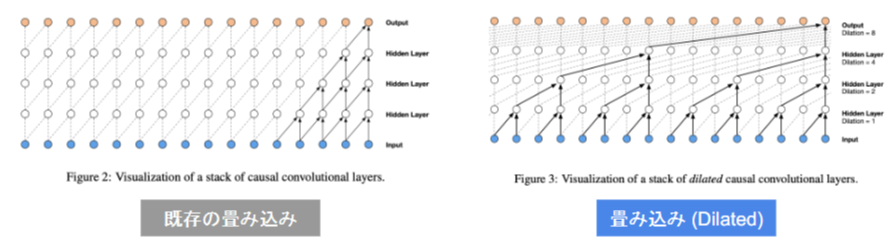
Dilated comvolution
- 層が深くなるにつれて畳み込むリンクを離す
- より広い情報を簡単に増やすことができる
Seq2seq
系列を入力として、系列を出力するもの
入力系列がEncode(内部状態に変換)され、内部状態からDecode(系列に変換)する
- 翻訳(英語→日本語)
- 音声認識(波形→テキスト)
- チャットボット(テキスト→テキスト)
言語モデル
単語の並びに確率を与えるもの
数式的には同時確立を事後確率に分解して表せる
例)
You say goodbye→0.092(自然)
You say good die→0.0000032(不自然)
RNN×言語モデル
文章は各単語が現れる際の同時確率は事後確率で分解できRNNで学習することによってある時点でほ次の単語を予測することできる
実装
Trancefomer
RNNを使用していない(必要なのはAttntionだけ)
英仏の3600万分の学習を8GPUで3.5日で完了(当時のほかのモデルよりはるかに少ない計算量)
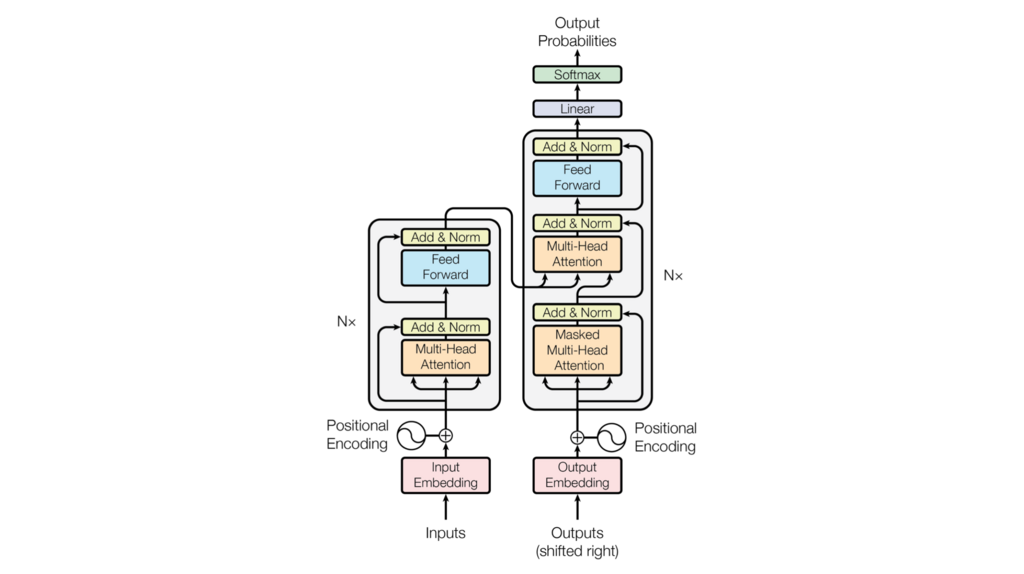
- 単語ベクトルに位置情報を追加
- 複数のヘッドでAttentionを計算
- 単語の位置ごとに独立処理する全結合
- 正則化し次元をまとめデコーダーへ
- 未来情報を見ないように入力され
- 入力された情報とエンコーダーの情報から予測をしていく
Encoder-Decoder
Encoder-Decoderモデルは文章の長さに弱い
- 翻訳元の文の内容を一つのベクトルで表現
- 文章が長くなると表現が足りなくなる
Attention
Encoder-Decoderの問題を解決する
翻訳先の単語を選択する際に、翻訳元の文中の単語の隠れ状態を利用
すべてを足すと1になるような重みを各隠れ層に分配していく
辞書オブジェクトの機能と同じような機能
souce Target Attention
受け取った情報に対して狙うべき情報が近いかどうかで注意するものを決める
Self Attention
自分の入力のみでどの情報に注意するかきめる
Trancefomer Encoder
Self Attentionによって文脈を考慮して各単語をエンコード
Position Wise Feed Forwrd Networks
各Attention層の出力を決定
位置情報を保持したまま出力を成形
線形変換をかける層
Scaled dot product attention
全単語に関するattentionをまとめて計算する
Multi Head attention
8個のScaled dot product attentionの出力を合わせる
合わせたものを線形変換する
それぞれの異なる情報を収集(アンサンブル学習みたいな)
Add
入出力の差分を学習させる
実装上は出力に入力を加算
学習・テストエラーの低減
Norm(Layder Norm)
学習の高速化
Position Encoding
単語の位置情報をエンコード
RNNではないので単語列の語順を情報を追加するため
実装
考察
TrancefomerとSeq2seq比べるとはるかにTrancefomerのほうが学習速度が高速で精度もよいことが分かった
物体認識
入力データは画像
広義の物体認識タスクは4つに分類される
| 名称 | 出力 | 位置 | インスタンスの区別 |
|---|---|---|---|
| 分類 | 画像に対し単一または複数のクラスラベル | 興味なし | 興味なし |
| 物体検知 | Bounding Box | 興味あり | 興味なし |
| 意味領域分割 | 各ピクセルに対し単一のクラスラベル | 興味あり | 興味なし |
| 個体領域分割 | 各ピクセルに対し単一のクラスラベル | 興味あり | 興味あり |
分類→物体検知→意味領域分割→個体領域分割の順で難しくなる
物体検知
どこに何がどんなコンフィデンスであるかを示すもの(Bounding Box)を予測する
データセット
| 名称 | クラス | Train+Val | Box数/画像 |
|---|---|---|---|
| VOC12 | 20 | 11,540 | 2.4 |
| ILSVRC17 | 200 | 476,668 | 1.1 |
| MS COCO18 | 80 | 123,287 | 7.3 |
| OICOD18 | 500 | 1,743,042 | 7.0 |
Box/画像が小さいとアイコン的な映り、日常感とはかけ離れやすい
Box/画像が大きいと部分的な重なり等も見られる、日常生活のコンテキストに近い
評価指標
クラス分類との違いはコンフィデンスのしきい値よってBBoxの数が変化する
IoU
物体検出においてはクラスラベルだけでなく, 物体位置の予測精度も評価したい
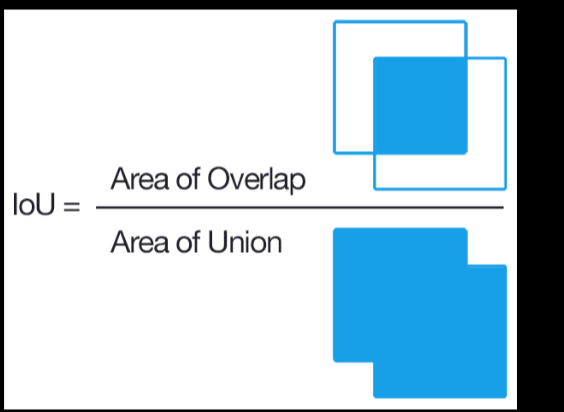
Area of overlap = $TP$
Area of Union = $TP + FP + FN$
Precision/Recal
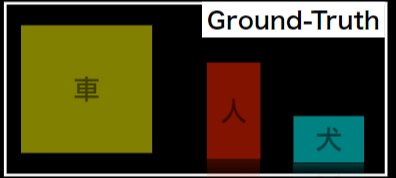
コンフィデンスとIoUでそれぞれの閾値を設定する
conf.の閾値:0.5
IoUの閾値:0.5
| conf. | pred. | IoU |
|---|---|---|
| P1 | 0.92 | 人 |
| P2 | 0.85 | 車 |
| P3 | 0.81 | 車 |
| P4 | 0.70 | 犬 |
| P5 | 0.69 | 人 |
| P6 | 0.54 | 車 |
P1:IoU > 0.5よりTP(人を検出)
P2:IoU < 0.5よりFP
P3:IoU > 0.5よりTP(車を検出)
P4:IoU > 0.5よりTP(犬を検出)
P5:IoU > 0.5であるが既に検出済みなのでFP
P6:IoU < 0.5よりFP
Precision:$\frac{3}{3+3}= 0.50$
Recall:$\frac{3}{0+3}= 1.00$
Average Precision
conf.の閾値:$ \beta $としたとき
Precision:$R( \beta )$
Recall:$P( \beta )$
Precision-Recall curve:$P=f( R )$
Average Precision(PR曲線の下側面積):
$$
AP = \int_0^1 P(R)dR
$$
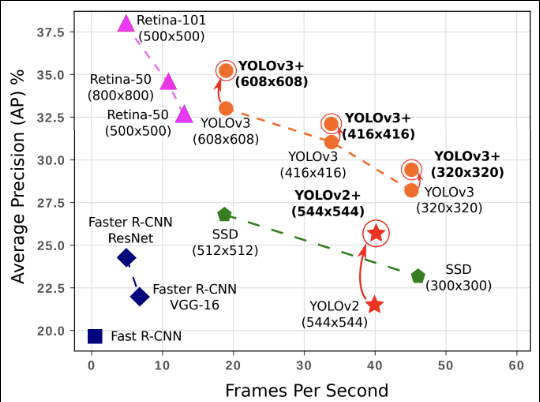
FPS:Flames per Second
物体検知応用上の要請から, 検出精度に加え検出速度も問題となる
セグメンテーション
問題点
畳み込みやプーリングによりが画像の解像度がおちてしまう
入力サイズと同じサイズで各ピクセルに対し単一のクラスラベルをつけなければならない
元のサイズに戻さなければならない→Up-samplingの壁
解決策として以下の二つがある
- Deconvolution
- Transposed
Deconvolution/Transposed
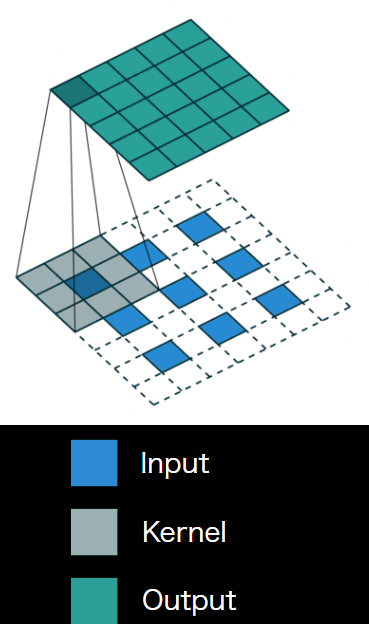
上図はkernel size = 3, padding = 1, stride = 1のDeconv.により 3×3の特徴マップが5×5にUp-samplingされる様子
- 通常のConv.層と同様, カーネルサイズ・パディング・ストライドを指定
- 特徴マップのpixel間隔をstrideだけ空ける
- 特徴マップのまわりに(kernel size - 1) - paddingだけ余白を作る
- 畳み込み演算を行う
逆畳み込みと呼ばれることも多いが畳み込みの逆演算ではないことに注意 →当然, poolingで失われた情報が復元されるわけではない
Dilated Convolution
poolingを使用せずConvolutionの段階で受容野を広げる工夫
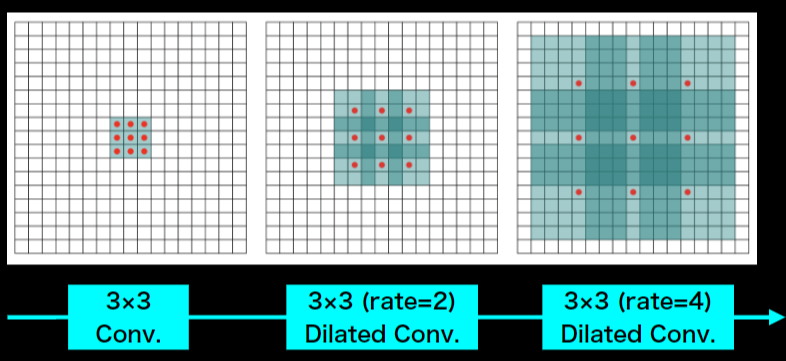
3×3の間に隙間を与える5×5にし受容野を広げる(rate=2)
計算量は3×3と同等
最終的には15×15に受容野を広げられる