強化学習でスーパーマリオをクリアする話の続きです。読んでいない方は先にそちらを読んでおいた方がいいかもしれません。
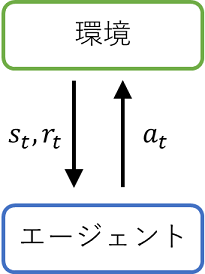
- エージェントは環境から時刻$t$の状態$s_{t}$と報酬$r_{t}$を受け取る
- エージェントは$s_{t}$に応じた行動$a_{t}$を環境に渡す
- 環境は$a_{t}$を用いて時刻を1ステップ分進めて時刻$t+1$の状態$s_{t+1}$と報酬$r_{t+1}$を得る
- エージェントは環境から$s_{t+1}, r_{t+1}$を受け取る
- 1に戻る
強化学習では以上のような手順を繰り返すことで得られる報酬$r_{t}$の総和(の期待値)を最大化する方策を得ることを目的とします。報酬は学習のための重要なシグナルであり、報酬が全く手に入らない条件では学習は進みません。また、そこまで極端でなくとも稀にしか報酬が得られない(ほとんどの時刻で$r_{t}=0$となる)ような条件では学習が難しくなります。
前回はマリオが右に進むごとに報酬を与えるようにしたためエージェントは頻繁に報酬を受けとることができ、比較的短い学習量でゴールできました。これをマリオがゴールできた場合のみに与えるようにすると同じ量の学習を行っても上手くクリアできません。
好奇心
環境からの報酬が与えられない場合の代理の報酬として、まだ訪れたことのない状態に訪れることができたなら報酬を与えることを考えます。つまり、新しい状態に対する好奇心の強さに報酬を与えることで探索を促します。
状態の目新しさを評価するためのネットワークを用意してそこからの出力を報酬として扱う手法としてIntrinsic Curiosity Moduleが提案されています。
Intrinsic Curiosity Module (ICM)
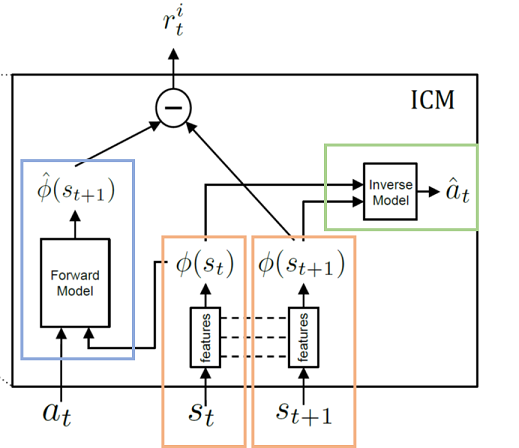
ICMは3つのモジュールからなっています。
Features:状態$s_{t}$から特徴$\phi(s_{t})$を抽出する
Forward Model:ある時刻の特徴$\phi(s_{t})$と行動$a_{t}$から次の時刻$t+1$の状態の特徴$\hat{\phi}(s_{t+1})$を予測する
Inverse Model:ある時刻の特徴$\phi(s_{t})$と次の時刻の特徴$\phi(s_{t+1})$からその間で取られた行動$\hat{a}_{t}$を予測する
ICMの学習
ICMは以下の2つの損失の和を最小化するように学習します。
$\mathcal{L}_{forward} = || \phi(s_{t+1}) - \hat{\phi}(s_{t+1})||_2 $
$\mathcal{L}_{inverse} = - \sum a_{t} \log \hat{a_t}$ (cross entropy誤差)
ICMによる報酬
$r_t^i = || \phi(s_{t+1}) - \hat{\phi}(s_{t+1})||_2$を報酬とします。
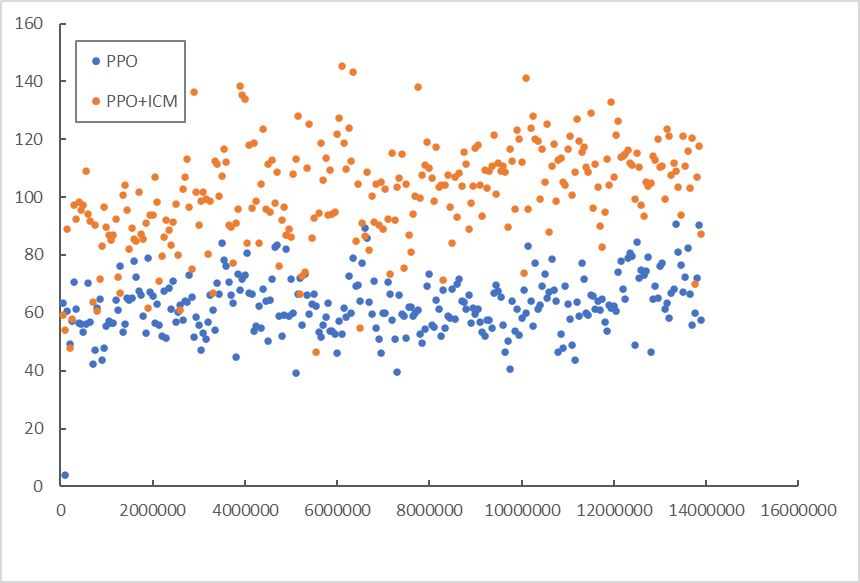
実験
スーパーマリオブラザーズ1-1で環境からの報酬を全く与えずに学習を行いました。
評価時には右に移動すると報酬が与えられる環境を用いました。
PPOとPPOにICMを組み合わせたもので報酬和の中央値を比較しています。
ICMありの方が報酬和が大きくなっていることがわかります。
ただし、ステージをクリアできる割合についてはPPO+ICMで(2/128)程度になりました(PPOでは(0/128)なのでICMによって改善はしていそうです。)