地域再生計画をテキストマイニングして地方創生分析ーデータ編の続きです。
関数の定義
まずはMeCabを使った単語分解のための関数。[単語、品詞1、品詞2]の順でpandasのデータフレームの形で出力します。stemをTrueにすると形態素、Falseにすると使われている単語になります。わざわざデータフレームにして品詞を抽出したのは、分析過程で不必要な品詞が結構出てくるものの、場合によって使い分けたいということがあるためです。
def Mecab_WordList_POS(texts, stem=True,
POS1=['連体詞','名詞','副詞','動詞','接頭詞','接続詞','助動詞','助詞','形容詞','記号','感動詞','フィラー','その他']):
'''
this is a function to return a pandas dataframe with 'term', 'POS1' and 'POS2'.
you can set a posture you want:'連体詞','名詞','副詞','動詞','接頭詞','接続詞','助動詞','助詞','形容詞','記号','感動詞','フィラー','その他'
also, you can choose True or False in 'stem', meaning stem=True gives you stemmed word.
'''
if not type(texts) == pd.Series:
texts = pd.Series(texts)
POS1=POS1
tagger = MeCab.Tagger('mecab -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd')
tagger.parse('')
result = pd.DataFrame(columns=['term', 'pos1', 'pos2'])
if stem==True:
for text in texts:
node = tagger.parseToNode(text)
word_class = []
while node:
word = node.surface
wclass = node.feature.split(',')
if wclass[0] != u'BOS/EOS':
if wclass[6] == None:
if wclass[0] in POS1:
word_class.append((word,wclass[0],wclass[1],""))
else:
if wclass[0] in POS1:
word_class.append((wclass[6],wclass[0],wclass[1]))
node = node.next
word_class = pd.DataFrame(word_class, columns=['term', 'pos1', 'pos2'])
result = pd.concat([result, word_class])
if stem==False:
for text in texts:
node = tagger.parseToNode(text)
word_class = []
while node:
word = node.surface
wclass = node.feature.split(',')
if wclass[0] != u'BOS/EOS':
if wclass[6] == None:
if wclass[0] in POS1:
word_class.append((word,wclass[0],wclass[1],""))
else:
if wclass[0] in POS1:
word_class.append((word,wclass[0],wclass[1]))
node = node.next
word_class = pd.DataFrame(word_class, columns=['term', 'pos1', 'pos2'])
result = pd.concat([result, word_class])
return result.reset_index(drop=True)
次は単純に単語のみを引っ張り出してくる関数。こっちはtargetで'line'とすれば、ラインごとの単語をリストにし、それをさらにリストにしたものを抽出(list of list)、'whole'とすれば、文書全体の単語をリストにしたものを抽出します。たぶん、こんなに長い必要はない…。
def Mecab_WordList(texts, target, stem=True,
POS1=['連体詞','名詞','副詞','動詞','接頭詞','接続詞','助動詞','助詞','形容詞','記号','感動詞','フィラー','その他']):
'''
this is a function to return a list of 'term'.
you have to choose 'line' or 'whole' in 'target'. 'line' gives you list of list of terms line by line and 'whole' gives you a list of terms with whole text.
you can set a posture you want:'連体詞','名詞','副詞','動詞','接頭詞','接続詞','助動詞','助詞','形容詞','記号','感動詞','フィラー','その他'
also, you can choose True or False in 'stem', meaning stem=True gives you stemmed word.
'''
POS1=POS1
tagger = MeCab.Tagger('mecab -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd')
tagger.parse('')
if target == 'line':
if stem==True:
result = []
for i in range(0, len(texts)):
each_result = []
node = tagger.parseToNode(texts[i])
word_class = []
while node:
word = node.surface
wclass = node.feature.split(',')
if wclass[0] != u'BOS/EOS':
if wclass[0] in POS1:
if wclass[6] == None:
each_result.append(word)
else:
each_result.append(wclass[6])
node = node.next
result.append(each_result)
if stem==False:
result = []
for i in range(0, len(texts)):
each_result = []
node = tagger.parseToNode(texts[i])
word_class = []
while node:
word = node.surface
wclass = node.feature.split(',')
if wclass[0] != u'BOS/EOS':
if wclass[0] in POS1:
if wclass[6] == None:
each_result.append(word)
else:
each_result.append(word)
node = node.next
result.append(each_result)
elif target == 'whole':
if stem==True:
result = []
for text in texts:
node = tagger.parseToNode(text)
while node:
word = node.surface
wclass = node.feature.split(',')
if wclass[0] != u'BOS/EOS':
if wclass[6] == None:
if wclass[0] in POS1:
result.append(word)
else:
if wclass[0] in POS1:
result.append(wclass[6])
node = node.next
if stem==False:
result = []
for text in texts:
node = tagger.parseToNode(text)
while node:
word = node.surface
wclass = node.feature.split(',')
if wclass[0] != u'BOS/EOS':
if wclass[6] == None:
if wclass[0] in POS1:
result.append(word)
else:
if wclass[0] in POS1:
result.append(word)
node = node.next
return result
次は品詞に加えて、ファイル名もつけたものを吐き出す関数。この辺り、一つにまとめたかったのですが、時間がなく…。コレスポンデンス分析に使います。
def word_list_with_fileID(file_type):
'''
this is a function to return a list of 'term', 'pos1', 'pos2', 'file_id'.
before using this function, you need to specify a directory path where there are necesarry files analysed.
then, you set a file type like csv or txt.
'''
if file_type == 'csv':
result = pd.DataFrame(columns=['term', 'pos1', 'pos2', 'file_id'])
files = glob.glob('*.csv')
for i in range(0,len(files)):
each_file = pd.read_csv(files[i], index_col=False)
each_file = each_file.iloc[:,0]
each_file_word_list = Mecab_WordList_POS(each_file)
each_file_word_list['file_id'] = files[i]
result = pd.concat([result,each_file_word_list])
result = result.reset_index(drop=True)
return result
if file_type == 'txt':
result = pd.DataFrame(columns=['term', 'pos1', 'pos2', 'file_id'])
files = glob.glob('*.txt')
for i in range(0,len(files)):
each_file = pd.read_csv(files[i], header=None, index_col=False)
each_file = each_file.iloc[:,0]
each_file_word_list = Mecab_WordList_POS(each_file)
each_file_word_list['file_id'] = files[i]
result = pd.concat([result,each_file_word_list])
result = result.reset_index(drop=True)
return result
単語数を数える関数。前の記事でも使ったものです。
from collections import Counter
def word_freq(word_list):
'''
this is a function to return 'term' and 'frequency' in a text.
'''
count = Counter(word_list)
result = pd.DataFrame.from_dict(count, orient='index').reset_index().rename(columns={'index':'term', 0:'freq'})
result = result.sort_values('freq',ascending=False).reset_index(drop=True)
return result
sklearnのVectorizerを使う上での前処理関数。これもVectorizerと一緒にしたかったが、面倒くさくなってやめました…
def preVectorizer(data):
file_ids = np.unique(data.file_id)
result = list()
for i in range(0, len(file_ids)):
each_word_list = (data[data.file_id == file_ids[i]])['term']
each_word_list = ' '.join(each_word_list)
result.append(each_word_list)
return result
頻度分析
試しに計画概要で使われている単語の頻度を求めてみます。
data_plan_abs_list = Mecab_WordList(data.plan_abs, target='whole', POS1=['名詞','形容詞','動詞'])
word_freq(data_plan_abs_list)
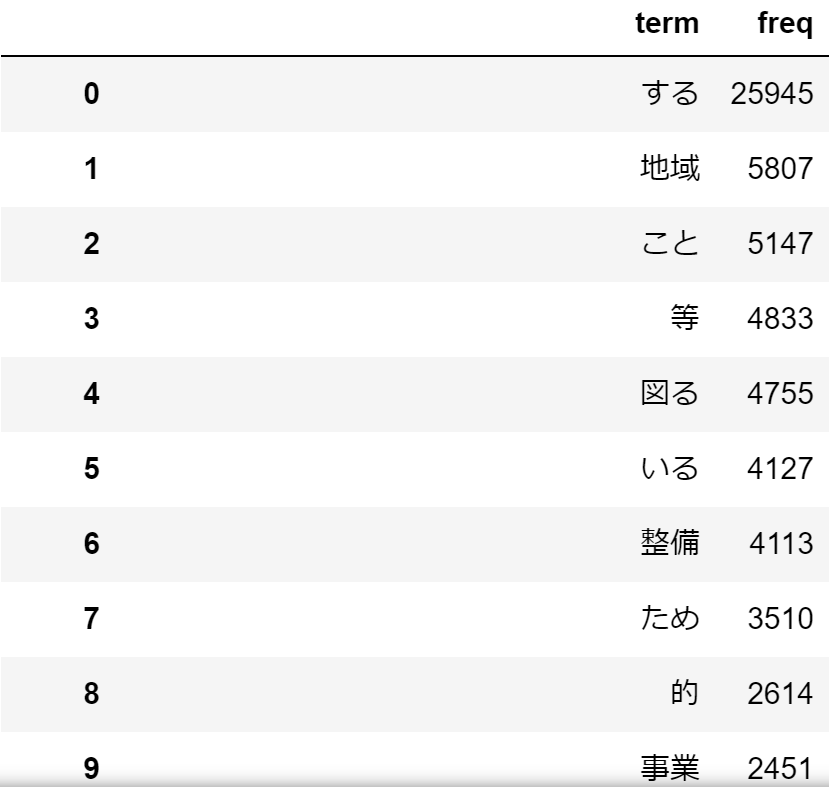
する、こと、等という感じで、あまり意味をなさない単語が多いですね。
ワードクラウド
ワードクラウド(全体)
解析対象にならない単語はstop_termのリストに入れて、個別に排除。その後、ワードクラウドを表示。
stop_term = ['ある','いる','する','できる','なる','思う','いる','れる','図る',
'行う','いう','ため','こと','的','化','等','*']
from wordcloud import WordCloud
wc = WordCloud(font_path="/mnt/c/ubuntu_home/font/NotoSansMonoCJKkr-Regular.otf", regexp="[\w']+",
background_color='white',width=800, height=600,collocations = False, stopwords=stop_term)
wc.generate(' '.join(data_plan_abs_list))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.tight_layout(pad=0)
plt.imshow(wc)
plt.show()

さすが地域再生計画ということで「地域」が一番大きい!あとは整備、産業、観光、事業、活用という感じに。これを地方創生が始まる前と後の2015年で区切って見てみます。差を明確にするために、stop_termを増やしてます。
ワードクラウド(地方創生前)
data_plan_abs_list_before = Mecab_WordList(data.plan_abs[data.year < 2015], target='whole', POS1=['名詞','形容詞','動詞'])
stop_term = ['ある','いる','する','できる','なる','思う','いる','れる','図る',
'行う','いう','ため','こと','的','化','等','*','地域','事業','活用','目指す']
wc = WordCloud(font_path="/mnt/c/ubuntu_home/font/NotoSansMonoCJKkr-Regular.otf", regexp="[\w']+",
background_color='white',width=800, height=600,collocations = False, stopwords=stop_term)
wc.generate(' '.join(data_plan_abs_list_before))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.tight_layout(pad=0)
plt.imshow(wc)
plt.show()

ワードクラウド(地方創生後)
data_plan_abs_list_after = Mecab_WordList(data.plan_abs[data.year >= 2015], target='whole', POS1=['名詞','形容詞','動詞'])
wc.generate(' '.join(data_plan_abs_list_after))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.tight_layout(pad=0)
plt.imshow(wc)
plt.show()

最後の2つの図から分かるのは、地方創生前は施設整備といったハード系の事業と雇用対策事業が多かった(整備、施設、汚水、処理、農業、環境、雇用)が、地方創生後は観光に特化したという具合でしょうか。あとは、地方創生後は連携、推進、支援、促進というゼロから作るよりも、何かを後押しするといった意味合いの単語も増えてきてますね。