はじめに
安倍政権の重要施策の地方創生。東京一極集中を是正し、地方の人口減少に歯止めをかけ、日本全体の活力を上げることを目的とした一連の政策のことですが、これによって地方公共団体への国の支援がどう変わっていったのかテキストマイニングの勉強も兼ねてやってみました。
地域再生計画
今回用いたのは地域再生制度に基づいて作成される地域再生計画というもの。地域再生制度とは、地域経済の活性化や地域における雇用機会の創出を総合的かつ効果的に推進するため、地域が行う自主的かつ自立的な取組を国が支援するものです。地方公共団体は、地域再生計画を作成し、内閣総理大臣の認定を受けることで、当該地域再生計画に記載した事業の実施に当たり、財政、金融等の支援措置を活用することができます。
例えば、企業やNPO法人の施設の農地転用の可能化や、地方に本社機能を移した企業への税制優遇措置などの規制緩和、観光客の誘致、道路や港のインフラ整備などの事業に対する補助金などがあります。この地域再生制度ですが、地方創生が謳われる平成17年から開始されていて、途中、地方創生の概念などを踏まえて、制度変更がなされています。
なので、この地域再生計画を地方創生の開始前後で切り分けて、分析すれば、地方創生で国の地方公共団体への支援がどう変化したのかが分かるのかなと思いました。
データの出所
地域再生計画はそれぞれの地方公共団体が作り、内閣総理大臣が認定するものですが、これまで認定された計画はこちらから入手可能です。
https://www.kantei.go.jp/jp/singi/tiiki/tiikisaisei/saiseikeikaku.html
ここの「現在活用されている計画」と「計画期間が終了した計画」をマージして、Excelでごにょごにょしたものを今回は使用します。整形後のデータはGitHubに上げています。
https://github.com/hrkzz/regional_revitalization_plan
それではPythonに読み込ませて、データの解析を。
環境
Windows Subsystem for Linux
Ubuntu 18.04
Python 3.6
mecab of 0.996
辞書はmecab-ipadic-NEologd
フォントはNotoSansMonoCJKkr-Regular.otf
今回で一番苦労したのはMeCabとかCaBochaとかmecab-ipadic-NEologdのインストールだったりする…。あとは、ずっと英語でやってたこともあり、jupyterでの日本語表記とかも大変でした。No more tofuとか初めて知りました。この辺りは色んな方が記事を書いているので、ググってみてください(それでもかなり大変でしたが…)。
パッケージの読み込み。
# 基本ライブラリ
import numpy as np
import pandas as pd
# 可視化のライブラリ
import matplotlib.pyplot as plt
from matplotlib.pylab import rcParams
from matplotlib.font_manager import FontProperties
font_path = "/mnt/c/ubuntu_home/font/NotoSansMonoCJKkr-Regular.otf"
font_prop = FontProperties(fname=font_path)
import seaborn as sns
from adjustText import adjust_text
# フォルダをいじるライブラリ
import os
import glob
# テキストマイニングのためのライブラリ
import MeCab
# コレスポンデンス分析のためのライブラリ
import mca
データの読み込み
data = pd.read_excel('regional_revitalization_plan.xlsx', encoding = 'Shift_JISx0213')
data.head(1)
data.shape
(5920, 24)
ということで、今回読み込んだのは、5920件の地域再生計画です。データ量としてはまずまず。24行もあるカラムは、こちら。
data.columns
Index(['id', 'ongoing', 'pref', 'codepref', 'pref_code', 'city', 'codecity',
'code', 'plan_name', 'plan_abs', 'timing', 'date_seireki', 'change',
'num_measure', 'measure1', 'measure2', 'measure3', 'measure4',
'measure5', 'measure6', 'measure7', 'measure8', 'measure9', 'measure10',
'year'],
dtype='object')
idは計画ごとの番号。ダブっている計画がないので、全部で5920あります。
ongoingは0なら終了した計画、1なら継続中の計画。
prefは計画の主体となる地方公共団体が属する都道府県。
codeprefは都道府県のコード。都道府県をまたいだ計画は48を振っています。
pref_codeはcodeprefとprefを繋ぎ合わせたもの。可視化の時に使います。
cityは市町村名。都道府県の事業の場合は都道府県名を入れています(例:北海道北海道)。
codecityは6桁のコード。広域の場合は000000を振っています。
codeはcodeprefとcodeを繋ぎ合わせたもの。
plan_nameは計画名。
plan_absは計画の概要。
timingは認定された回数。
date_seirekiは認定日の西暦表示。
changeは計画を変更した回数。
num_measureは認定地域再生で支援されることになった国の施策の数。
measure1~10は支援された具体的な施策名(ワイド標記とセンスがなくすみません)。
yearは認定された年(これは後からPythonで付け加えました)。
データ探索(EDA)
認定回ごとの計画数
rcParams['figure.figsize'] = 15,4
data[['date_seireki','plan_name']].groupby(['date_seireki']).agg(['count']).plot.bar()
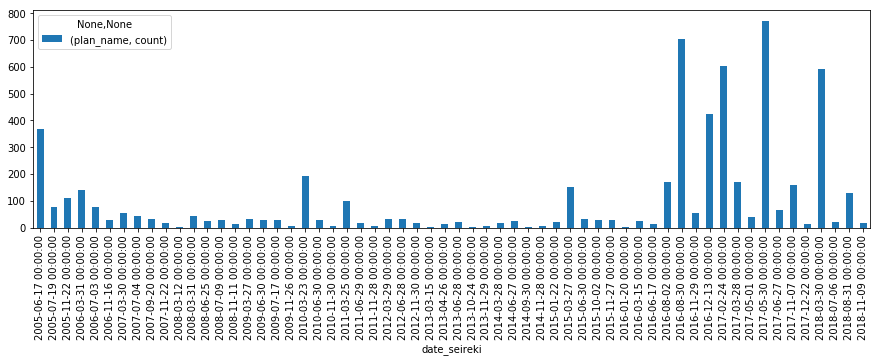
後半にドバっと増えてますが、回数ごとにばらつきがありますね。たぶん、認定回で見るより、年数ごとで見た方がいいのでは。
認定年ごとの計画数
data['year'] = pd.DatetimeIndex(data.date_seireki).year
rcParams['figure.figsize'] = 15,4
data[['year','plan_name']].groupby(['year']).agg(['count']).plot.bar()
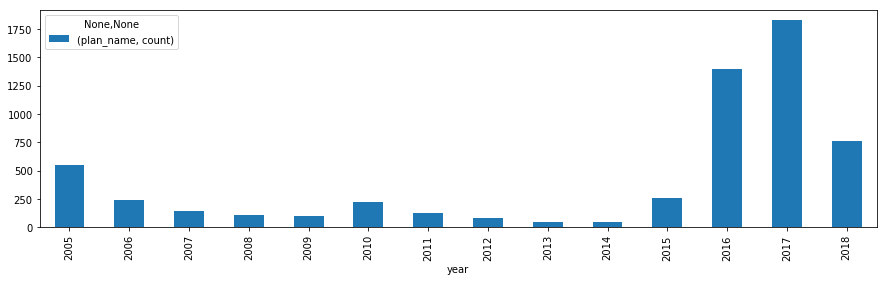
地方創生が本格的に始まった2016年から急に増えてますが、2018年は下がり気味。
都道府県ごとの計画数
rcParams['figure.figsize'] = 15,4
data[['codepref','plan_name']].groupby(['codepref']).agg(['count']).plot.bar()
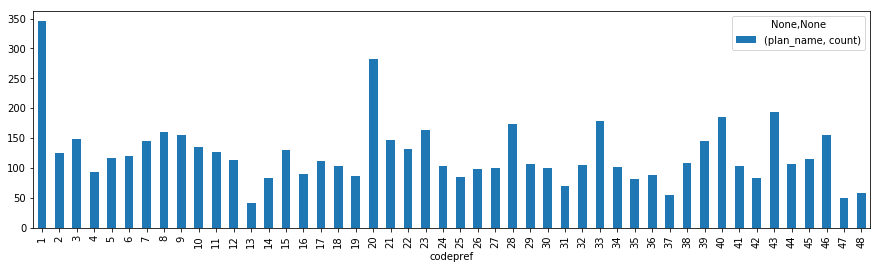
市町村数が多い01北海道がダントツですね。次に20長野県。13東京都が少ないのは納得で、37香川県も市町村数が少ないのでこんなところ。47沖縄県は地方創生よりも、独自の沖縄振興施策の方が使い勝手がいいので、数字は低めに出てます。たぶん、各都道府県の市町村数で割った値で見るべきなんでしょう…。
国の支援策
measure_list = data.iloc[:,14:24].unstack().dropna().reset_index(drop=True)
len(np.unique(measure_list))
106
ということで、認定地域再生計画に基づく国の支援の種類は106。結構多いですね。
word_freq(measure_list).head(10)

word_freqという独自の関数を使っていますが、詳細は後で書きたいと思います。地方創生推進交付金が2303件とダントツですね。2位の地方創生拠点整備交付金も結構な件数で、地方創生が始まってからの支援策が圧倒的な地位を。これがあるので、2016年以降の地域再生計画の認定件数が伸びてるんですね。ちなみに5位のまち・ひと・しごと創生寄附活用事業に関連する寄附を行った法人に対する特例は企業版ふるさと納税のことです。