初めまして。
株式会社ハイマックスの平田と申します。
記事とは無関係ですが、約1年を経て念願(!)のQiita Organizationの作成が叶ったことをこの場を借りて報告いたします。
さて先日、社内のMattermostから使える文書検索サービスをリリースしました。
単なる全文検索ではなく、Word2VecとTF-IDFで文書をベクトル化(≠Doc2Vec)し、検索ワードとの距離による検索を行っています。これにより、文書上と多少表現が異なる検索ワードでもヒットするようになります。
この記事では、サービスを作ってMattermostから使えるようにするまでの流れをソースコード(抜粋)付きで紹介します。
作ったもの
Mattermostのチャンネルのいずれかで、例えば「/bot テスト」と入力すると…
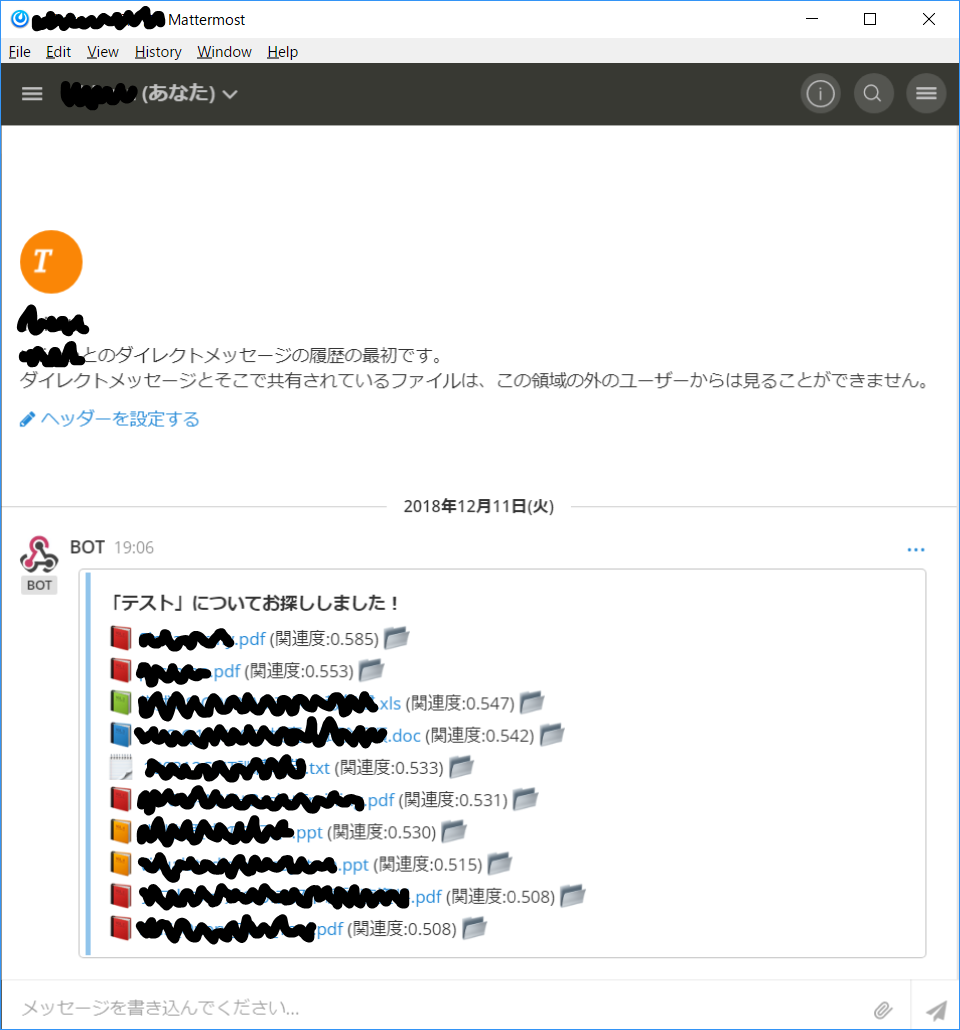
こんな感じで社内の文書管理システムから関連する文書のリンクを返してくれます。
作った動機
作った動機は主に、
- 社内の文書管理システムを使いやすくしたい: 検索機能がとにかく使いにくく、現在のフォルダ内の文書名でしか検索できない(サブフォルダや本文は対象外)
- 社員のニーズが知りたい: 社員の業務環境を改善するために社員がどんな情報を必要としているか知りたいが、各部門への問合せ記録が一切残っていない
- Mattermostの部外ユーザを増やしたい: 自分たちの一方的な情報発信ではなく、双方向に情報を交換することでシナジーを生むための仕組み(チャットツール)を部外に広めたい
- データアナリティクスの手法を使って何か意味のあるものを作りたい
といったものです。
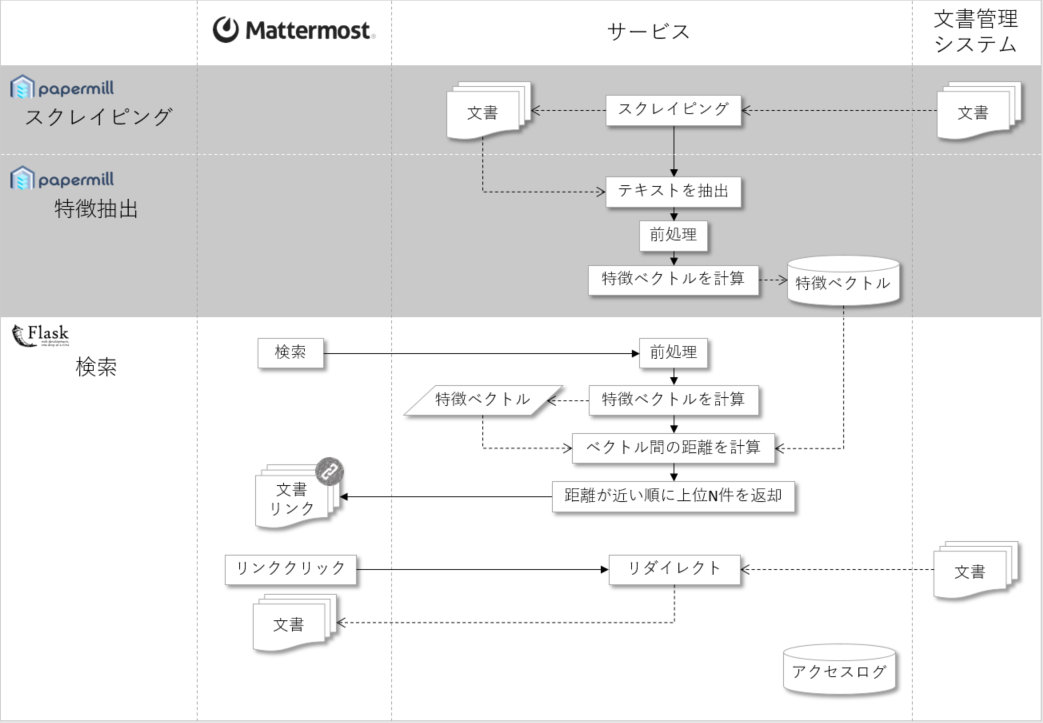
サービスの仕組み
サービスは大きく分けて次の3つの機能に分かれています。
- スクレイピング(バッチ): 文書管理システムからすべての文書をダウンロードする
- 特徴抽出(バッチ): すべての文書からテキストを抽出し、Word2VecとTF-IDFを使って文書の特徴ベクトルを計算する
- 検索(オンライン): 検索ワードを受け取って関連する文書のリンクを返却する
スクレイピング
スクレイピングは文書管理システムからすべての文書をダウンロードする機能で、仕組みはSeleniumでルートから深さ優先探索するというシンプルなものです。
が、サーバリソースを気にして待機・リトライさせたり、DOMが使い回しされていて非同期通信のレスポンスを受け取ったタイミングがわからないため小技を使ったりして、今回作るのに最も苦労した機能です。
詳細は割愛します。
特徴抽出
特徴抽出は文書の特徴ベクトルを計算する機能です。
文書からファイル名を抽出する
ファイルパスからフォルダと拡張子を除いたファイル名を抽出します。
import os
def get_filename(path):
return os.path.splitext(os.path.basename(path))[0]
文書から本文を抽出する
Word、Excel、PowerPoint、PDF、テキストファイルから本文を抽出します。
Word(.doc, .docx)の読み込み
拡張子が.docの場合、LibreOfficeで.docxに変換します。
result = subprocess.run(['libreoffice', '--headless', '--convert-to', 'docx', path, '--outdir', outdir])
Wordから本文を抽出するプログラムは次のようになります。
from docx import Document
def docx2text(path):
doc = Document(path)
return '\n'.join([p.text for p in doc.paragraphs])
Excel(.xls, .xlsx, .xlsm)の読み込み
Excelから本文を抽出するプログラムは次のようになります。
import pandas as pd
def xls2text(path):
df_dict = pd.read_excel(path, sheet_name=None, header=None)
result = '\n'.join(['\n'.join(row.dropna().astype('str')) for df in df_dict.values() for i, row in df.iterrows()])
# 日付を文字列に変換すると'00:00:00'が末尾に付くため除去する
result = result.replace('00:00:00', '').strip()
return result
少しわかりにくいですが、全シートの全行について空のセルを除去したのち改行コードで結合しています。
PowerPoint(.ppt, .pptx)の読み込み
拡張子が.pptの場合、Wordと同様にLibreOfficeで.pptxに変換します。
PowerPointから本文を抽出するプログラムは次のようになります。
from pptx import Presentation
def pptx2text(path):
prs = Presentation(path)
return '\n'.join([paragraph.text for slide in prs.slides for shape in slide.shapes if shape.has_text_frame for paragraph in shape.text_frame.paragraphs])
これも少しわかりにくいですが、全スライドのテキストフレームを持っている全オブジェクトの全段落について改行コードで結合しています。
PDF(.pdf)の読み込み
PDFMiner.sixに付属するpdf2txt.pyを使って、PDFから本文を抽出します。1
import re
def pdf2text(path):
lines = !pdf2txt.py {path}
text = '\n'.join(lines)
# CJK文字が(cid:XXXXX)のように文字化けするため除去する
text = re.sub(r'\(cid:\d+\)', '', text)
return text
このプログラムではCJK文字が(cid:XXXXX)のように文字化けすることがあります。
PDFを発行した製品によってはCJK文字を文字コードではなくグリフIDで表している2らしく、真偽の程は不明ですがグリフIDから文字へのマッピングができていないような気がします。
テキストファイル(.txt)の読み込み
ShiftJISやUTF-8のテキストファイルが混在しているため、文字コードの自動判別を行ってから本文を抽出します。3
from chardet.universaldetector import UniversalDetector
def get_encoding(path):
detector = UniversalDetector()
with open(path, mode='rb') as f:
for binary in f:
detector.feed(binary)
if detector.done:
break
detector.close()
return detector.result['encoding']
def txt2text(path):
with open(path, encoding=get_encoding(path)) as f:
return f.read()
テキストをクリーニングする
半角カタカナを全角に、全角英数字を半角に、大文字を小文字にします。
import mojimoji
def clean_text(text):
text = mojimoji.han_to_zen(text, digit=False, ascii=False)
text = mojimoji.zen_to_han(text, kana=False)
text = text.lower()
return text
MeCabでテキストを単語に分かちする
1テキストを単語に分かちします。不要な品詞は除外、活用形は原形にします。
import MeCab
def text2wakati(text):
tagger = MeCab.Tagger('-Ochasen')
parsed_text = tagger.parse(text)
# 除外する品詞
stop_parts = ('名詞-接尾-形容動詞語幹', 'その他', 'フィラー', '副詞', '助動詞', '助詞', '動詞-接尾', '動詞-非自立', '名詞-動詞非自立的', '名詞-特殊-助動詞語幹', '名詞-接尾-サ変接続', '名詞-接尾-副詞可能', '名詞-接尾-人名', '名詞-接尾-助動詞語幹', '名詞-接尾-形容動詞語幹', '名詞-接尾-特殊', '名詞-非自立', '感動詞', '接続詞', '接頭詞-動詞接続', '接頭詞-形容詞接続', '形容詞-接尾', '形容詞-非自立', '記号-一般', '記号-句点', '記号-括弧閉', '記号-括弧開', '記号-空白', '記号-読点', '連体詞')
return '' if not parsed_text else ' '.join([y[2] for y in [x.split('\t') for x in parsed_text.splitlines()[:-1]] if (len(y) == 6) and (not y[3].startswith(stop_parts))])
原因不明ですがparsed_textがNoneになることがあります。その場合は空文字を返すようにしています。
TF-IDFを計算する
sklearn.feature_extraction.text.TfidfVectorizerを使ってTF-IDFを計算します。計算結果を ${\bf w}$ とします。
from sklearn.feature_extraction.text import TfidfVectorizer
def get_tfidf_and_feature_names(corpus):
vectorizer = TfidfVectorizer(token_pattern=u'(?u)\\b\\w+\\b')
return vectorizer.fit_transform([text2wakati(clean_text(text)) for text in corpus]), vectorizer.get_feature_names()
w, feature_names = get_tfidf_and_feature_names(corpus)
corpusはすべての文書のファイル名のリスト、または本文のリストです。
デフォルトだと長さ1の単語がカウントされないため、token_pattern=u'(?u)\\b\\w+\\b'を指定しています。4
文書の特徴ベクトルを計算する
まずTF-IDFのfeature_namesに対する単語ベクトルの行列 ${\bf v}=(v_{0}, ... , v_{N-1})$ を作ります。ここで $N$ はfeature_namesの数です。
今回は、東北大学の乾・鈴木研究室が公開している5日本語Wikipediaから作成された300次元の訓練済みWord2Vecを使います。
v = np.asarray([word_vectors(word) for word in feature_names])
次に ${\bf w}$ と ${\bf v}$ の内積を計算し、文書ごとの ${\bf w}$ の平均で除算します。要するにTF-IDFを重みとする単語ベクトルの加重平均を計算します。
doc_title_vectors = (w @ v) / w.sum(axis=0)
doc_title_vectorsはファイル名の特徴ベクトルです。同様に本文の特徴ベクトルdoc_content_vectorsを計算し、2つの特徴ベクトルの平均を計算します。
doc_vectors = np.nanmean([doc_title_vectors, doc_content_vectors], axis=0)
これを文書の特徴ベクトルとします。文書の数を $M$ とすると、特徴ベクトルは $M$ 行 $300$ 列の行列になっています。
検索で使うため、特徴ベクトルをpickle.dumpsでPickle化してデータベースに保存しておきます。
検索
検索はFlaskを使ったWeb APIで、検索ワードを受け取って関連する文書のリンクを返却する機能です。
検索ワードをクリーニングする
特徴抽出のclean_textを使います。
検索ワードを単語に分かちする
特徴抽出のtxt2wakatiを使います。
検索ワードの特徴ベクトルを計算する
文書の特徴ベクトルはTF-IDFを重みとする加重平均でしたが、検索ワードはTF-IDFが計算できないので単語ベクトルの平均を特徴ベクトルとします。
words = text2wakati(clean_text(query)).split()
v = np.asarray([word_vectors(word) for word in words])
query_vector = v.nanmean(axis=0).reshape(1, -1)
queryが検索ワードです。reshapeしているのは文書の特徴ベクトルと形を合わせるためです。
検索ワードと文書のコサイン類似度を計算する
特徴抽出で作った文書の特徴ベクトルをデータベースからすべて取得します。特徴ベクトルはPickle化されているので、pickle.loadsで非Pickle化します。
取得した文書の特徴ベクトルと検索ワードの特徴ベクトルのコサイン類似度を計算します。
def cosine_similarity(X, Y):
return (X @ Y.T) / np.sqrt(np.nansum(np.power(X, 2), axis=1) * np.nansum(np.power(Y, 2), axis=1))
similarities = cosine_similarity(doc_vectors, query_vector)
doc_vectorsはNaNを含む可能性があるので、sklearn.metrics.pairwise.cosine_similarityは使わず、np.nansumを使って計算します。
スコアが高い順に上位10件の文書のリンクを返却する
np.argsortでスコアが高い順に上位10件のインデックスを取得します。
上位10件としているのは、Mattermostのメッセージに入れられる文字数が最大16,3836で、文書10件しか入れられなかったためです。(URLにかなり文字数を取られています)
result_indexes = np.argsort(similarities[:, 0])[:10]
このインデックスを使って文書の情報(ファイル名やURL)をまとめたpd.DataFrameを作ります。
作る過程は省略しますが、結果として次のようなテーブルができます。
| id | filename | file_extension | file_url | folder_url | score |
|---|---|---|---|---|---|
| 1 | ファイル1.docx | docx | https:.../folder1/file1.docx | https:.../folder1/ | 0.XXX |
| 2 | ファイル2.xlsx | xlsx | https:.../folder2/file2.xlsx | https:.../folder2/ | 0.XXX |
| ... |
このテーブルからMattermostに表示するためのJSONを作ります。
Mattermostの表示はtitleとfieldsに分かれていて、fieldsはfieldのリストになっています。
fieldは3行を超えるとアコーディオンが閉じた状態になるので、1行ずつ分割しています。
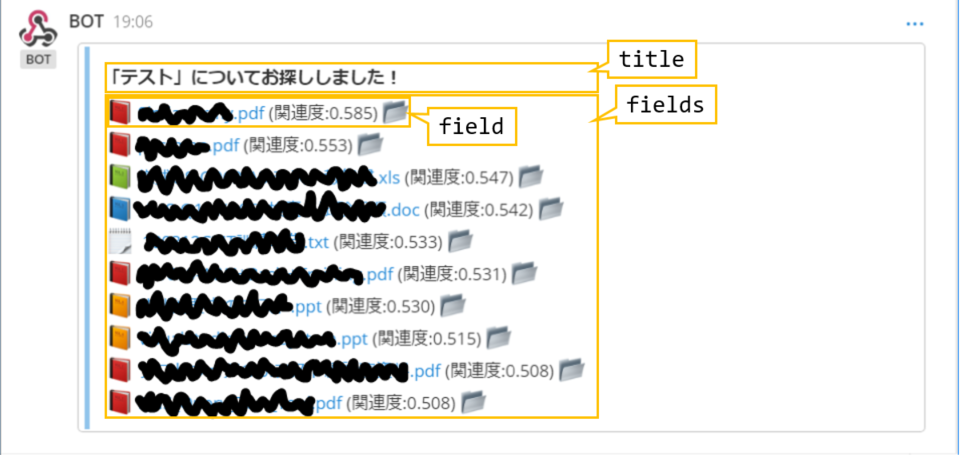
検索ワードを受け取って関連する文書を求め、Mattermostに返却するWeb APIは次のようになります。
from flask import Flask, request, jsonify, redirect
import string, random
app = Flask(__name__)
app.config['JSON_AS_ASCII'] = False
app.config['JSON_SORT_KEYS'] = False
@app.route('/bot', methods=['POST'])
def api_bot():
# MattermostのユーザIDと検索文字列を取得する
user_id = request.form['user_id']
text = request.form['text']
# 検索時のログと文書リンククリック時のログを関連付けるためのキー(16桁のハッシュ)を発行する
session_id = ''.join([random.choice(string.hexdigits[:16]) for _ in range(16)])
# 検索する
docs = retrieve(text)
result = {
'Content-Type':'application/json',
'response_type':'in_channel',
'attachments': get_attachments(text, docs, user_id, session_id),
'username':'BOT'
}
# ログ出力等(省略)
return jsonify(result)
def get_attachments(text, docs, user_id, session_id:
if 0 >= len(doc_list.index):
return [{
'text': 'すみません。\n「' + text + '」はまだ知らない言葉です…'
}]
else:
return [{
'title': '「' + text + '」についてお探ししました!',
'fields': [get_field(user_id, session_id, row) for i, row in docs.iterrows()]
}]
def get_field(user_id, session_id, doc):
file_icon = get_extension_icon(doc['file_extension'])
file_url = f'{BASE_URL}/doc?user_id={user_id}&session_id={session_id}&doc_id={doc["id"]}&url={doc["file_url"]}'
folder_url = f'{BASE_URL}/doc?user_id={user_id}&session_id={session_id}&doc_id={doc["id"]}&url={doc["folder_url"]}'
score = str(doc['score'])[:5]
return {
'short': False,
'value': f' [{file_icon} {doc["filename"]}]({file_url}) (関連度:{score}) [:open_file_folder:]({folder_url})'
}
def get_extension_icon(extension):
if extension in ('ppt', 'pptx', 'ppsx'):
return ':orange_book:'
elif extension == 'pdf':
return ':closed_book:'
elif extension in ('xls', 'xlsx', 'xlsm'):
return ':green_book:'
elif extension in ('doc', 'docx', 'docm'):
return ':blue_book:'
elif extension == 'txt':
return ':spiral_notepad: '
else:
return ':notebook:'
retrieveが文書の情報をまとめたpd.DataFrameを作る関数です。
session_idはログを集計する際に検索と文書リンククリックを関連付けるためのランダムな16桁のハッシュです。7
リンククリックにより文書管理システムの文書へリダイレクトさせる
Mattermostに表示されたリンクがクリックされたときに呼び出され、文書管理システムの文書へリダイレクトさせるWeb APIは次のようになります。
@app.route('/doc', methods=['GET'])
def api_doc():
user_id = request.args.get('user_id')
session_id = request.args.get('session_id')
doc_id = request.args.get('doc_id')
url = request.args.get('url')
# ログ出力等(省略)
return redirect(url)
Word2Vecのチューニング
英小文字の単語ベクトルを作る
テキストのクリーニングで大文字を小文字にしているので、英大文字を含む単語の単語ベクトルをコピーして英小文字の単語ベクトルを作ります。
専門用語の単語ベクトルを作る
例えば「DC」という単語には様々な意味があります8が、弊社内で「DC」といえば「確定拠出年金」一択です。そこで「確定拠出年金」の特徴ベクトルを計算し、元の「DC」の単語ベクトルに上書きします。
特徴ベクトルの計算方法は検索ワードと同じで、単語に分かちして単語ベクトルの平均を計算します。
実行
バッチ
バッチ(スクレイピングと特徴抽出)はcrontabで毎日定時実行します。
実行するときは、Papermillというツールを使ってJupyter Notebookのまま実行しています。9
# !/bin/sh
today=`date "+%Y%m%d"`
papermill ~/src/scraping/scraping.ipynb ~/logs/scraping/scraping_log_${today}.ipynb
papermill ~/src/featuring/featuring.ipynb ~/logs/featuring/featuring_log_${today}.ipynb
バッチでエラーが発生するとMattermostに通知されるようにしています。
オンライン
こちらを参考にDockerでNginx+uWSGI+Flaskのイメージを立ち上げて、そこに検索のWeb APIをデプロイしています。
Mattermostから呼び出す
最後に、Mattermostから検索のWeb APIを呼び出すスラッシュコマンドを作成します。
Mattermostのシステム管理者で、メニューの統合機能から作成できます。説明のとおりに設定するだけなので、特に難しいことはないと思います。
コマンドトリガーワードがスラッシュコマンドを使うときのキーワードで、ここでは「bot」としています。
終わり
これで完成です。
任意のチャンネルで「/bot 〇〇」と送信すると、〇〇に関連する文書のリンクが表示されます。自分へのダイレクトメッセージとして使えば、他の人からは見えなくなります。
リンクをクリックすると、文書管理システムにリダイレクトされてファイルをダウンロードできます。
実は実際に作ったのは私ではなく、弊社の若手(2~3年目)3名に3週間くらいで作ってもらったのですが、結構いい感じに検索できます。たまに眠っている文書が見つかったりして面白いです。
文書のベクトル化というアプローチで一番効果を感じたのは、検索の応答時間がとにかく短いということで、Mattermostでスラッシュコマンドを実行してから結果が表示されるまで1秒くらいで終わります。文書管理システムの文書は2,431件、平均55,645文字なので、全文検索すると1秒じゃ終わりません。(ちなみに文書管理システムの文書名のみを対象とした検索機能は5秒かかります)
たまに無関係な文書が検索されることもありますが、私はWord2Vecの威力にただただ感銘を受けるばかりでした。
先日、チャットツールから検索するという点で似たようなもの10を作っている方を見つけたので参考にしつつ、今後は機能拡充も検討していこうと思います。
ここまで読んでいただき、ありがとうございました。
もしお気付きの点等ございましたら、フィードバックいただけますと幸いです。