これは翻訳記事
1. はじめに
OpenAI の gpt-image 生成モデルは、生産品質のビジュアルと高度に制御可能なクリエイティブワークフローを目的としています。これらは、プロフェッショナルなデザインタスクと反復的なコンテンツ作成に適しており、ワークフローによっては高品質なレンダリングと低遅延のユースケースをサポートします。
主な機能には以下が含まれます:
- 高忠実度のフォトリアリズム:自然な照明、正しい素材、豊かな色レンダリング
- 柔軟な品質-遅延トレードオフ:低い設定で高速生成が可能で、以前の世代の画像モデルよりも視覚品質を上回る
- 堅牢な顔とアイデンティティの保存:編集、キャラクターの一貫性、多段階ワークフロー用
- 信頼できるテキストレンダリング:鮮明な文字、レイアウトの一貫性、画像内の強いコントラスト
- 複雑な構造化ビジュアル:インフォグラフィック、図、複数パネルの構成を含む
- 正確なスタイル制御とスタイル転送:最小限のプロンプティングでブランドデザインシステムからファインアートまで対応
- 強力な世界知識と推論:オブジェクト、環境、シナリオの正確な描写を可能にする
このガイドでは、gpt-image-2 の実世界の生産ユースケースから得られたプロンプティングパターン、最善のプラクティス、例のプロンプトを強調します。これは私たちの最も能力の高い画像モデルで、より強力な画像品質、改善された編集パフォーマンス、生産ワークフローへのより広範なサポートを提供します。低品質設定は遅延に敏感なユースケースに特に強力で、中品質と高品質は最大忠実度が必要な場合に適しています。
1.1 OpenAI 画像モデルパラメータ
このセクションは、このガイドでカバーされる画像モデルのリファレンスで、以下に焦点を当てています:
- モデル名
- サポートされる
outputQuality値 - サポートされる
input_fidelity値 - サポートされる
size/ 解像度動作 - ワークフロー別の推奨ユースケース
モデル概要
2026年4月21日現在、OpenAI は以下の画像モデルを提供しています。
| モデル | outputQuality |
input_fidelity |
解像度 | 推奨使用 |
|---|---|---|---|---|
gpt-image-2 |
low, medium, high
|
無効。このモデルでは input_fidelity が機能せず、デフォルトで高忠実度出力 |
以下の制約を満たす任意の解像度 | 新しいビルドのデフォルト推奨。最高品質の生成と編集、テキスト重い画像、フォトリアリズム、コンポジティング、アイデンティティに敏感な編集、少ないリトライでコストが低いワークフローで使用。 |
gpt-image-1.5 |
low, medium, high
|
low, high
|
1024x1024, 1024x1536, 1536x1024, auto
|
移行中の既存の検証済みワークフローを維持。新しい作業では品質、編集信頼性、または柔軟なサイジングが重要になる場合に gpt-image-2 を優先。 |
gpt-image-1 |
low, medium, high
|
low, high
|
1024x1024, 1024x1536, 1536x1024, auto
|
レガシー互換性のみ。新しいワークフローを開始したり、プロンプトを更新したりする場合、移行を検証しながら短期安定性を必要とする場合にのみ gpt-image-1 を維持。 |
gpt-image-1-mini |
low, medium, high
|
low, high
|
1024x1024, 1024x1536, 1536x1024, auto
|
コストとスループットが主な制約の場合:大規模バッチバリアント生成、迅速なアイデア生成、プレビュー、軽量パーソナライゼーション、強力な生成や編集パフォーマンスを必要としないドラフトアセット。 |
gpt-image-2 サイズオプション
gpt-image-2 は、size パラメータで渡される任意の解像度をサポートしますが、以下の制約をすべて満たす必要があります:
- 最大エッジ長は
3840px未満 - 両方のエッジは16の倍数
- 長辺と短辺の比率は3:1を超えない
- 総ピクセル数は8,294,400を超えない
- 総ピクセル数は655,360未満ではない
出力画像が 2560x1440 ピクセル(3,686,400総ピクセル)を超える場合、一般に2Kと呼ばれ、結果がより変動的になる可能性があるため、実験的として扱う。
人気の gpt-image-2 サイズ
これらは上記の制約に適合する有用な参照ポイントです:
| ラベル | 解像度 | 備考 |
|---|---|---|
| HD ポートレート | 1024x1536 |
標準ポートレートオプション |
| HD ランドスケープ | 1536x1024 |
標準ランドスケープオプション |
| 正方形 | 1024x1024 |
一般的なデフォルト |
| 2K / QHD | 2560x1440 |
人気のワイドスクリーンフォーマットと gpt-image-2 の信頼性の高い上限境界 |
| 4K / UHD | 3840x2160 |
実験的な上端ターゲット。最大エッジルールが文字通り < 3840 と強制される場合、最も近い有効サイズ(例:3824x2144)に丸める |
モデルを選択するタイミング
- ほとんどの生産ワークフローで
gpt-image-2をデフォルトとして選択。全体として最も強力なモデルで、現在gpt-image-1.5またはgpt-image-1を使用しているチームの高品質出力の適切なアップグレードターゲット。 - 速度とユニット経済が決定を支配する場合、
gpt-image-2を品質:低で選択。この設定は多くのユースケースで十分な品質を提供し、高ボリューム生成と実験に強いフィット。gpt-image-1-miniもこれらのユースケースで試すことができるが、品質:低が同様に機能するのを見てきた。 -
gpt-image-1.5またはgpt-image-1は、プロンプト移行を検証し、回帰テスト出力、または移行の準備ができていない古いワークフローを維持する場合にのみ維持。
gpt-image-1.5 と gpt-image-1 からの推奨アップグレードパス
現在 gpt-image-1.5 または gpt-image-1 を使用しているワークフローでは、推奨は:
- カスタマー向けアセット、フォトリアリスティック生成、編集重いフロー、ブランドに敏感なクリエイティブ、画像内テキストワークフロー、またはより良い初回品質が手動レビューやリランを減らすワークフローで
gpt-image-2にアップグレード。 - コストを下げるための大規模バッチの場合、
gpt-image-1-miniをレガシーモデルではなく検討。 - 移行中、最初にプロンプトをほぼ同じに保ち、実際のワークロードで出力品質、遅延、リトライレートを比較した後にのみ調整。
2. プロンプティングの基礎
以下のプロンプティングの基礎は、GPT 画像生成モデルに適用され、生成、編集、インフォグラフィック、広告、人間画像、UI モックアップ、コンポジティングワークフローでのアルファテストで繰り返し現れたパターンに基づいています。
-
構造 + 目標: プロンプトを一貫した順序で書く(背景/シーン → 対象 → 主要な詳細 → 制約)し、意図された使用(広告、UI モック、インフォグラフィック)を指定して「モード」と洗練のレベルを設定。複雑なリクエストでは、短いラベル付きセグメントまたは改行を使用し、1つの長い段落を避ける。
-
プロンプト形式: 維持しやすい形式を使用。最小プロンプト、記述的な段落、JSONのような構造、指示スタイルのプロンプト、タグベースのプロンプトはすべて、意図と制約が明確であればうまく機能する。生産システムでは、創造的なプロンプト構文よりも読みやすいテンプレートを優先。
-
具体性 + 品質のヒント: 素材、形状、テクスチャ、視覚メディア(写真、水彩、3D レンダー)について具体的にし、必要な場合にのみターゲット「品質レバー」(例:フィルムグレイン、テクスチャードブラシストローク、マクロディテール)を追加。フォトリアリズムの場合、「photorealistic」という言葉をプロンプトに直接含めて、モデルのフォトリアリスティックモードを強くエンゲージ。「real photograph」、「taken on a real camera」、「professional photography」、または「iPhone photo」などの同様のフレーズも役立つが、詳細なカメラ仕様は緩く解釈される可能性があるため、高レベルなルックと構成に主に使用。
-
遅延 vs 忠実度: 遅延に敏感または高ボリュームのユースケースでは、
quality="low"から開始し、視覚要件を満たすかどうかを評価。多くの場合、生成を大幅に高速化しながら十分な忠実度を提供。小さなまたは密集したテキスト、詳細なインフォグラフィック、クローズアップポートレート、アイデンティティに敏感な編集、高解像度出力の場合、最大忠実度が必要な場合にmediumまたはhighを比較。 -
構成: フレーミングと視点(クローズアップ、ワイド、トップダウン)、視点/角度(アイレベル、ローワングル)、照明/ムード(ソフトディフューズ、ゴールデンアワー、高コントラスト)を制御。レイアウトが重要な場合、配置を呼び出す(例:「ロゴトップライト」、「対象中央に左にネガティブスペース」)。ワイド、シネマティック、低光、雨、ネオンシーンでは、スケール、大気、色について追加の詳細を追加して、モデルがムードを表面リアリズムとトレードしないように。
-
人々、ポーズ、アクション: シーン内の人々については、スケール、ボディフレーミング、視線、オブジェクトインタラクションを記述。例:「全身が見える、足を含む」、「テーブルの子供サイズ相対」、「本を開いた下を見る、カメラを見ない」、または「ハンドルバーを自然に握る」。これらの詳細はボディプロポーション、アクションジオメトリ、視線アライメントに役立つ。
-
制約(何を変えるか vs 保存): 除外と不変を明示的に述べる(例:「ウォーターマークなし」、「余分なテキストなし」、「ロゴ/商標なし」、「アイデンティティ/ジオメトリ/レイアウト/ブランド要素を保存」)。編集の場合、「Xのみ変更」+「他はすべて同じ」を使用し、各イテレーションで保存リストを繰り返してドリフトを減らす。編集が外科的な場合、飽和、コントラスト、レイアウト、アロー、ラベル、カメラアングル、または周囲のオブジェクトを変更しないようにも言う。
-
画像内のテキスト: リテラルテキストを 引用符 または ALL CAPS に置き、タイポグラフィの詳細(フォントスタイル、サイズ、色、配置)を制約として指定。トリッキーな単語(ブランド名、珍しいスペル)の場合、文字ごとのスペルを改善するために文字ごとにスペルアウト。小さなテキスト、密集した情報パネル、多フォントレイアウトがある画像の場合、
mediumまたはhigh品質を使用。 -
複数画像入力: 各入力を インデックスと説明 で参照(「Image 1: 製品写真… Image 2: スタイルリファレンス…」)し、それらがどのように相互作用するかを記述(「Image 2 のスタイルを Image 1 に適用」)。コンポジティングの場合、どの要素がどこに移動するかを明確に(「Image 1 の鳥を Image 2 の象に置く」)。
-
反復ではなくオーバーロード: 長いプロンプトはうまく機能するが、デバッグはクリーンベースプロンプトから小さな単一変更フォローアップで開始する方が簡単(「照明を暖かくする」、「余分な木を削除」、「元の背景を復元」)。参照を使用してコンテキストを活用(「以前と同じスタイル」または「対象」)が、ドリフトを開始した場合に重要な詳細を再指定。
3. セットアップ
これを一度実行します。これにより:
- API クライアントを作成
- images フォルダーに
output_images/を作成 - base64 画像を保存するための小さなヘルパーを追加
編集に使用する参照画像を input_images/ に置く(または例のパスを更新)。
import os
import base64
from openai import OpenAI
client = OpenAI()
os.makedirs("../../images/input_images", exist_ok=True)
os.makedirs("../../images/output_images", exist_ok=True)
def save_image(result, filename: str) -> None:
"""
最初の返された画像を output_images フォルダー内の指定されたファイル名に保存します。
"""
image_base64 = result.data[0].b64_json
out_path = os.path.join("../../images/output_images", filename)
with open(out_path, "wb") as f:
f.write(base64.b64decode(image_base64))
from IPython.display import HTML, Image, display
def display_image_grid(items, width=240):
cards = []
for item in items:
title = item.get("title", "")
label = f'<div style="font-weight:600;margin-bottom:8px">{title}</div>' if title else ""
cards.append(
'<div style="text-align:center">'
+ label
+ f'<img src="{item["path"]}" width="{width}" style="max-width:100%;height:auto;" />'
+ '</div>'
)
display(HTML('<div style="display:flex;flex-wrap:wrap;gap:16px;align-items:flex-start">' + ''.join(cards) + '</div>'))
以下の例では、私たちの最も能力の高い画像モデル gpt-image-2 を使用します。
4. ユースケース — 生成(テキスト → 画像)
4.1 インフォグラフィック
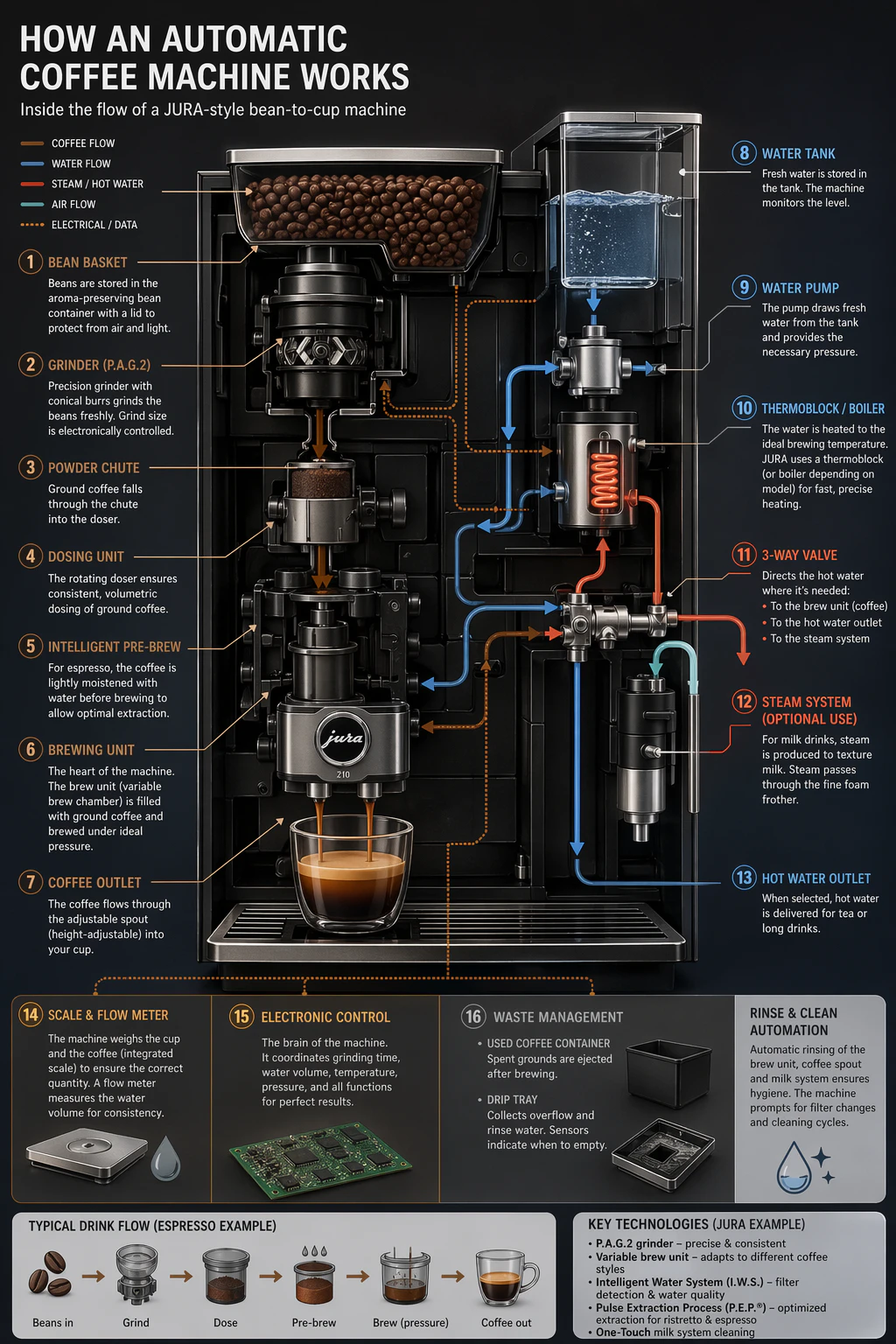
インフォグラフィックを使用して、学生、幹部、顧客、または一般公衆向けに構造化された情報を説明。エクスプレーナー、ポスター、ラベル付き図、タイムライン、「視覚 wiki」アセットなどの例。密集したレイアウトまたは画像内テキストが重い場合、出力生成品質を "high" に設定することを推奨。
prompt = """
Jura のような自動コーヒーマシンの機能とフローの詳細なインフォグラフィックを作成。
豆バスケットから、粉砕、スケール、水タンク、ボイラーなど。
技術的かつ視覚的にフローを理解したい。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "infographic_coffee_machine_gpt-image-2.png")
出力画像:
4.2 画像内の翻訳
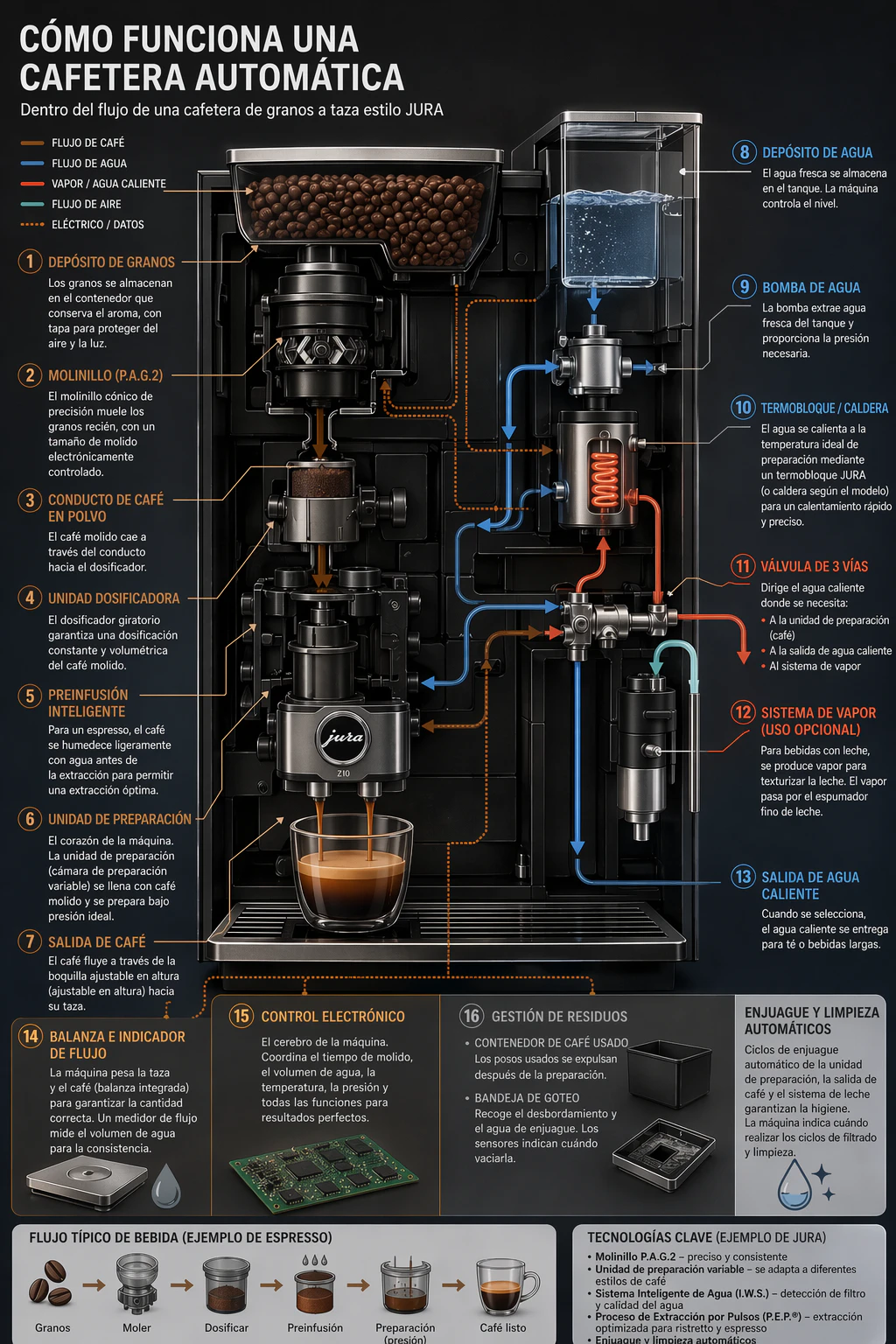
既存のデザイン(広告、UI スクリーンショット、パッケージング、インフォグラフィック)をレイアウトをゼロから再構築せずに別の言語にローカライズするために使用。テキスト以外はすべて保存—タイポグラフィスタイル、配置、スペーシング、階層を一貫して保ち、正確に翻訳し、余分な単語なし、必要に応じてリフローなし、意図しないロゴ、アイコン、または画像の編集なし。
prompt = """
インフォグラフィックのテキストをスペイン語に翻訳。画像の他の側面を変更しない。
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/output_images/infographic_coffee_machine_gpt-image-2.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "infographic_coffee_machine_sp_gpt-image-2.png")
出力画像:
4.3 「自然」に感じるフォトリアリスティック画像
本物のフォトリアリズムを得るために、モデルをリアルな写真がその瞬間にキャプチャされているかのようにプロンプト。写真言語(レンズ、照明、フレーミング)を使用し、リアルテクスチャ(毛穴、しわ、ファブリックウェア、欠陥)を明示的に要求。スタジオポリッシュやステージングを示唆する言葉を避ける。詳細が重要な場合、quality="high" を設定。
prompt = """
小さな漁船に立つ老水夫の写実的なカジュアル写真を作成。
彼はしわ、毛穴、日焼けテクスチャの荒れた肌を持ち、腕にいくつかのフェードした伝統的な水夫のタトゥー。
彼はデッキの近くに座る犬のそばでネットを調整している。35mm フィルム写真のように撮影、中クローズアップ、アイレベル、50mm レンズ使用。
ソフトな沿岸照明、浅い被写界深度、微妙なフィルムグレイン、自然な色バランス。
画像は正直でポーズなしで感じ、リアルな肌テクスチャ、着用された素材、日常の詳細。グローマライズなし、重いリタッチなし。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "photorealism-gpt-image-2.png")
出力画像:

4.4 世界知識
GPT 画像生成モデルは、強力な推論と世界知識を組み合わせることができる。例えば、1969年8月16日のニューヨーク州ベセルに設定されたシーンを生成するよう求められると、イベントについて明示的に言われなくてもウッドストックを推測し、正確で文脈に適した画像を生成。
prompt = """
1969年8月16日のニューヨーク州ベセルでの現実的な屋外群衆シーンを作成。
フォトリアリスティック、時代的に正確な衣装、ステージング、環境。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "world_knowledge-gpt-image-2.png")
出力画像:

4.5 ロゴ生成
強力なロゴ生成は明確なブランド制約とシンプルさから来る。ブランドの個性と使用ケースを記述し、強力な形状、バランスの取れたネガティブスペース、スケーラビリティを備えたクリーンでオリジナルなマークを要求。
パラメータ "n" を指定して、生成したいバリエーションの数を指定できます。
prompt = """
Field & Flour という会社のオリジナルで非侵害のロゴを作成。
ロゴは暖かく、シンプルで、タイムレスに感じる。クリーンでベクターのような形状、強力なシルエット、バランスの取れたネガティブスペースを使用。
シンプルさを詳細よりも優先して、小さく大きく明確に読む。フラットデザイン、最小ストローク、必要でない限りグラデーションなし。
プレーンバックグラウンド。寛大なパディングで中央に配置された単一ロゴを提供。ウォーターマークなし。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
n=4 # ロゴの4つのバージョンを生成
)
# 4つの画像を別々のファイルに保存
for i, item in enumerate(result.data, start=1):
image_base64 = item.b64_json
image_bytes = base64.b64decode(image_base64)
with open(f"../../images/output_images/logo_generation_{i}_gpt-image-2.png", "wb") as f:
f.write(image_bytes)
出力画像:
| オプション 1 | オプション 2 | オプション 3 | オプション 4 |
|---|---|---|---|
 |
 |
 |
 |
4.6 広告生成
広告生成は、純粋な技術的な画像仕様ではなくクリエイティブブリーフのようにプロンプトを書くのが最適。ブランド、オーディエンス、文化、コンセプト、構成、正確なコピーを記述し、モデルがそれらの境界内で味覚主導のクリエイティブ決定を行うようにする。これは初期キャンペーン探求に役立つ。モデルがオーディエンスのヒントを解釈し、芸術的方向を推測し、広告を考慮されたものにする視覚的詳細を提案できるため。
より強力な結果を得るために、ブランドポジショニング、望ましい雰囲気、ターゲットオーディエンス、シーン、タグラインを同じプロンプトに含む。テキストが画像に表示される必要がある場合、正確に引用し、クリーンで読みやすいタイポグラフィを要求。
prompt = """
Thread というブランドのクールなインカルチャー広告 / ファッションショットを与えて。
それはヒップな若いストリートブランド。広告は友達が一緒にハングアウトしていて、「Yours to Create」というタグラインを示す。
若者のストリートウェアオーディエンス向けに洗練された、現代的、エネルギッシュで、味わい深いものに感じるようにする。
クリーンな構成、強力なカラーディレクション、自然なポーズ、プレミアムファッションフォトグラフィーの手がかりを使用。
広告レイアウトに統合され、明確で読みやすく、一度タグラインをレンダリング。
余分なテキストなし、ウォーターマークなし、無関係なロゴなし。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "thread_ad_gpt-image-2.png")
出力画像:

4.7 ストーリーからコミックストリップ
ストーリーからコミック生成では、明確な視覚ビートをパネルごとに定義。説明を具体的でアクション指向に保つことで、モデルがストーリーを読みやすい、よくペースの取れたパネルに翻訳できる。
prompt = """
4つの等しいサイズのパネルを持つ垂直コミックスタイルのリールを作成。
パネル1:所有者が前ドアから出て行く。ペットはガラスの後ろの窓枠に小さく、目を大きく、足を高く押さえ、家が突然静かになる。
パネル2:ドアがクリックして閉まる。沈黙が破れる。ペットがゆっくり空の家に向き、姿勢が変わり、可能性で目を鋭くする。
パネル3:家が変身。ペットがソファを所有するように横たわり、近くにクッキー、日光が部屋をスポットライトのように切る。
パネル4:ドアが開く。ペットが入口のそばに完璧に座り、警戒し、構成され、何も起こらなかったかのように。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "comic_reel-gpt-image-2.png")
出力画像:

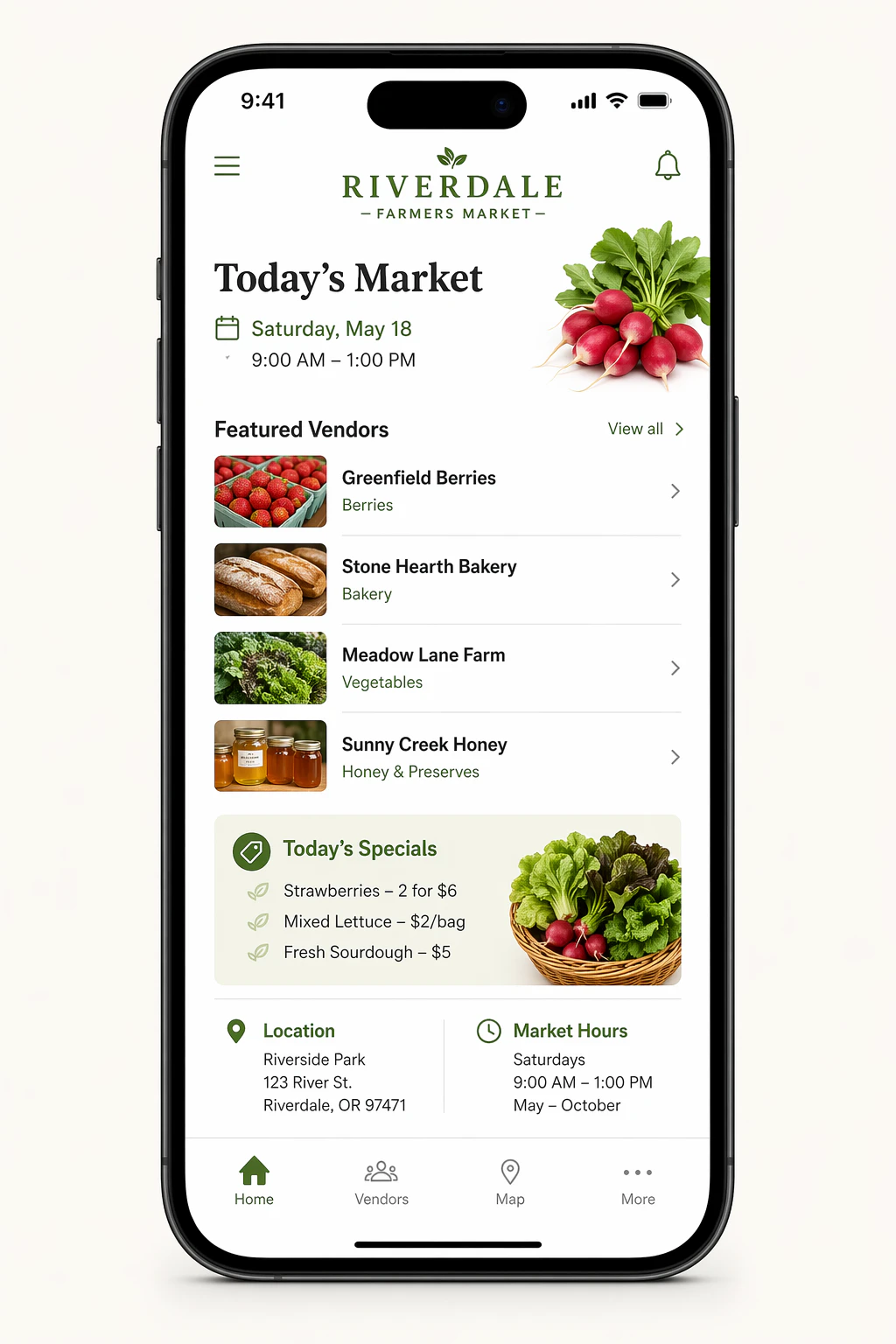
4.8 UI モックアップ
UI モックアップは、製品がすでに存在するかのように記述するのが最適。レイアウト、階層、スペーシング、リアルなインターフェース要素に焦点を当て、結果がデザインスケッチではなく使用可能な、発送されたインターフェースのように見えるようにコンセプトアート言語を避ける。
prompt = """
地元の農民市場の現実的なモバイルアプリ UI モックアップを作成。
今日の市場を示すシンプルなヘッダー、小さな写真とカテゴリを持つベンダーの短いリスト、「今日のスペシャル」セクション、場所と時間の基本情報。
実用的で使いやすくする。白い背景、微妙な自然なアクセントカラー、明確なタイポグラフィ、最小装飾。
それは小さな地元市場の美しい、よくデザインされた、本物のアプリのように見える。
UI モックアップを iPhone フレームに置く。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "ui_farmers_market_gpt-image-2.png")
出力画像:
4.9 科学的 / 教育的なビジュアル
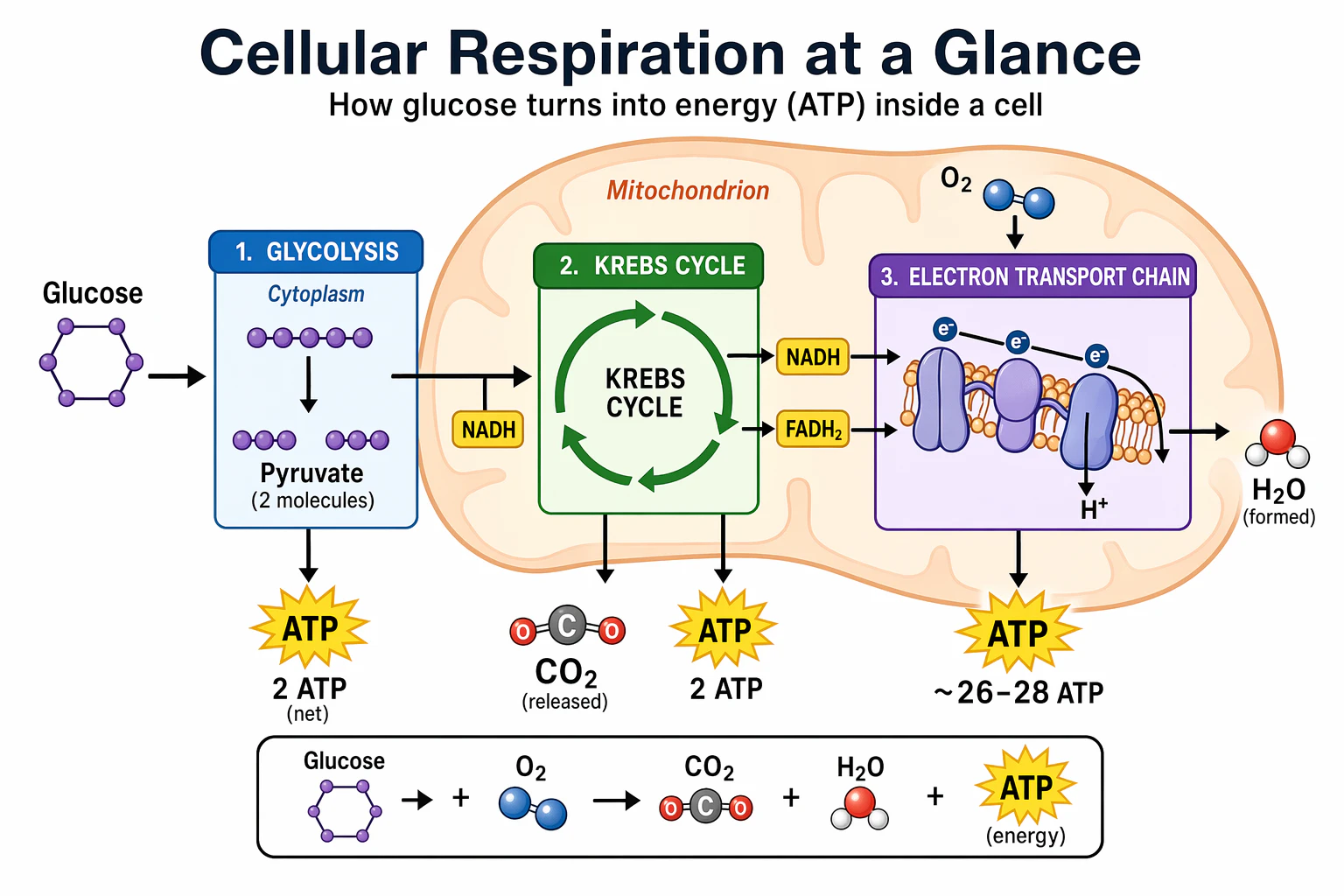
科学的および教育的なビジュアルは、生物学、化学、教室エクスプレーナー、フラット科学アイコンシステム、図、学習アセットに強いフィット。インストラクショナルデザインのブリーフのようにプロンプト:オーディエンス、レッスン目標、視覚形式、必要なラベル、科学的制約を定義。最適な結果を得るために、クリーンでフラットな視覚システムを要求し、一貫したアイコンスタイル、明確な矢印、読みやすいラベル、学生がコンセプトを素早くスキャンできる十分なホワイトスペース。
正確さが重要な場合、必要なコンポーネントを明示的にリストし、何を含めないかを言う。スライドやコース資料で使用される密集したラベル、図、またはアセットの場合、quality="high" を使用。
prompt = """
高校生向けの「細胞呼吸の概要」というタイトルのシンプルな生物学図を作成。
細胞内でグルコースがエネルギーに変わる方法を示す。解糖、TCA サイクル、電子輸送鎖を含める。
ステップを接続する矢印を使用し、主な分子にラベル:グルコース、ピルビン酸、ATP、NADH、FADH2、CO2、O2、H2O。
教室のハンドアウトやスライドのように見える、白い背景、シンプルなアイコン、明確なラベル、読みやすいテキスト。
図を理解しにくくする小さなテキスト、余分な装飾、または何かを避ける。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1536x1024",
quality="high",
)
save_image(result, "scientific_educational_cellular_respiration_gpt-image-2.png")
出力画像:
4.10 スライド、図、チャート、生産性画像
生産性ビジュアルは、純粋なイラストリクエストではなくアーティファクト仕様のようにプロンプトを書くのが最適。正確なデリバラブル(スライド、ワークフローダイアグラム、チャート、ページ画像)を命名し、キャンバスと階層を定義し、リアルなテキストやデータを提供し、視覚言語を記述。これらのプロンプトには実用的制約が含まれる:読みやすいタイポグラフィ、洗練されたスペーシング、装飾的なクラッターなし、ジェネリックストックフォト処理なし。
スライド、チャート、図重いアセットの場合、プロンプトに数字とラベルを直接含む。デックスタイル出力にはランドスケープサイズを使用し、小さなテキスト、凡例、軸、またはフットノートを含む画像の場合、quality="high" を使用。
prompt = """
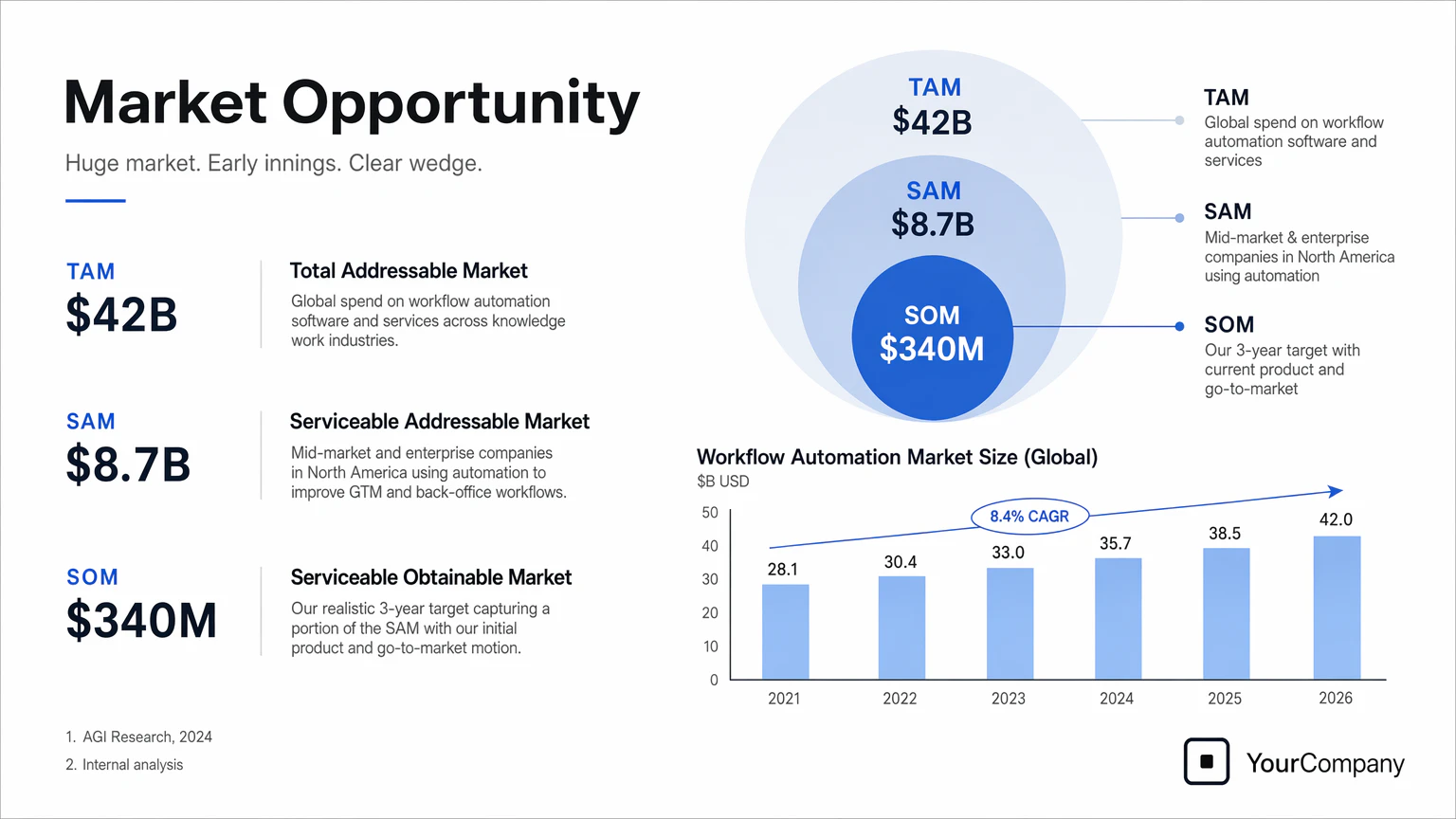
YC 支援のスタートアップからの本物のシリーズ A 資金調達スライドである「市場機会」というタイトルのピッチデックスライドを1つ作成。
白い背景、Inter のようなモダンなサンセリフタイポグラフィ、クリスプで最小限のレイアウトを使用。スライドには以下を含む:
* ミュートブルーとグレーの同心円 TAM/SAM/SOM 図
* 特定の、信じられる市場サイジング番号:
* **TAM:** $42B
* **SAM:** $8.7B
* **SOM:** $340M
* **2021年から2026年** の市場成長を示す下のクリーンなバーチャート、微妙な上昇トレンド
* 小さなフットノート:**"AGI Research, 2024"** と **"Internal analysis"**
* 右下隅の会社ロゴプレースホルダー
デザインは実際に資金を調達したデックに属するように感じる:非常に読みやすいテキスト、明確なデータ階層、洗練されたスペーシング、プロフェッショナルなスタートアップスタイルの視覚言語。
クリップアート、ストックフォトグラフィー、グラデーション、シャドウ、装飾要素、またはジェネリックに見えるものを避ける。
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1536x864",
quality="high",
)
save_image(result, "market_opportunity_slide_gpt-image-2.png")
出力画像:
5. ユースケース — 編集(テキスト + 画像 → 画像)
5.1 スタイル転送
スタイル転送は、リファレンス画像の 視覚言語 (パレット、テクスチャ、ブラシワーク、フィルムグレインなど)を保持しながら、対象やシーンを変更する場合に役立つ。最適な結果を得るために、何を一貫して保つか(スタイルキュー)と何を変えるか(新しいコンテンツ)を記述し、ドリフトを防ぐために背景、フレーミング、「余分な要素なし」などのハード制約を追加。
prompt = """
入力画像の同じスタイルを使用して、白い背景でオートバイに乗る男を生成。
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/pixels.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "motorcycle_gpt-image-2.png")
入力画像:
![]()
出力画像:

5.2 仮想衣類試着
仮想試着は、アイデンティティ保存が重要な e コマースプレビューに最適。モデルをロック(顔、ボディ形状、ポーズ、髪、表情)し、 ガーメントのみ を変更し、現実的なフィット(ドレーピング、フォールド、オクルージョン)プラス一貫した照明/シャドウを要求して、アウトフィットが自然に着用されているように見える—not pasted on。
prompt = """
提供された衣類画像を使用して女性の画像を編集。顔、顔の特徴、肌の色、ボディ形状、ポーズ、またはアイデンティティをどのような方法でも変更しない。彼女の正確な肖像、表情、ヘアスタイル、プロポーションを保存。既存のポーズとボディジオメトリにガーメントを自然にフィットさせ、現実的なファブリック動作で置き換える。元の写真と照明、シャドウ、色温度を一致させて、アウトフィットがフォトリアリスティックに統合され、貼り付けられたように見えないように。背景、カメラアングル、フレーミング、または画像品質を変更せず、アクセサリー、テキスト、ロゴ、ウォーターマークを追加しない。
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/woman_in_museum.png", "rb"),
open("../../images/input_images/tank_top.png", "rb"),
open("../../images/input_images/jacket.png", "rb"),
open("../../images/input_images/tank_top.png", "rb"),
open("../../images/input_images/boots.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "outfit_gpt-image-2.png")
入力画像:
| フルボディ | アイテム 1 |
|---|---|
 |
 |
| アイテム 2 | アイテム 3 |
 |
 |
出力画像:

5.3 描画 → 画像(レンダリング)
スケッチからレンダーワークフローは、ラフな描画をフォトリアリスティックコンセプトに変えながら、元の意図を保持するのに最適。プロンプトをスペックのように扱う:レイアウトとパースを保存し、 リアリズムを追加 するために適切な素材、照明、環境を指定。「新しい要素/テキストを追加しない」を含めて創造的な再解釈を避ける。
prompt = """
この描画をフォトリアリスティック画像に変える。
正確なレイアウト、プロポーション、パースを保存。
スケッチ意図に一貫した現実的な素材と照明を選択。
新しい要素やテキストを追加しない。
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/drawings.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "realistic_valley_gpt-image-2.png")
入力画像:
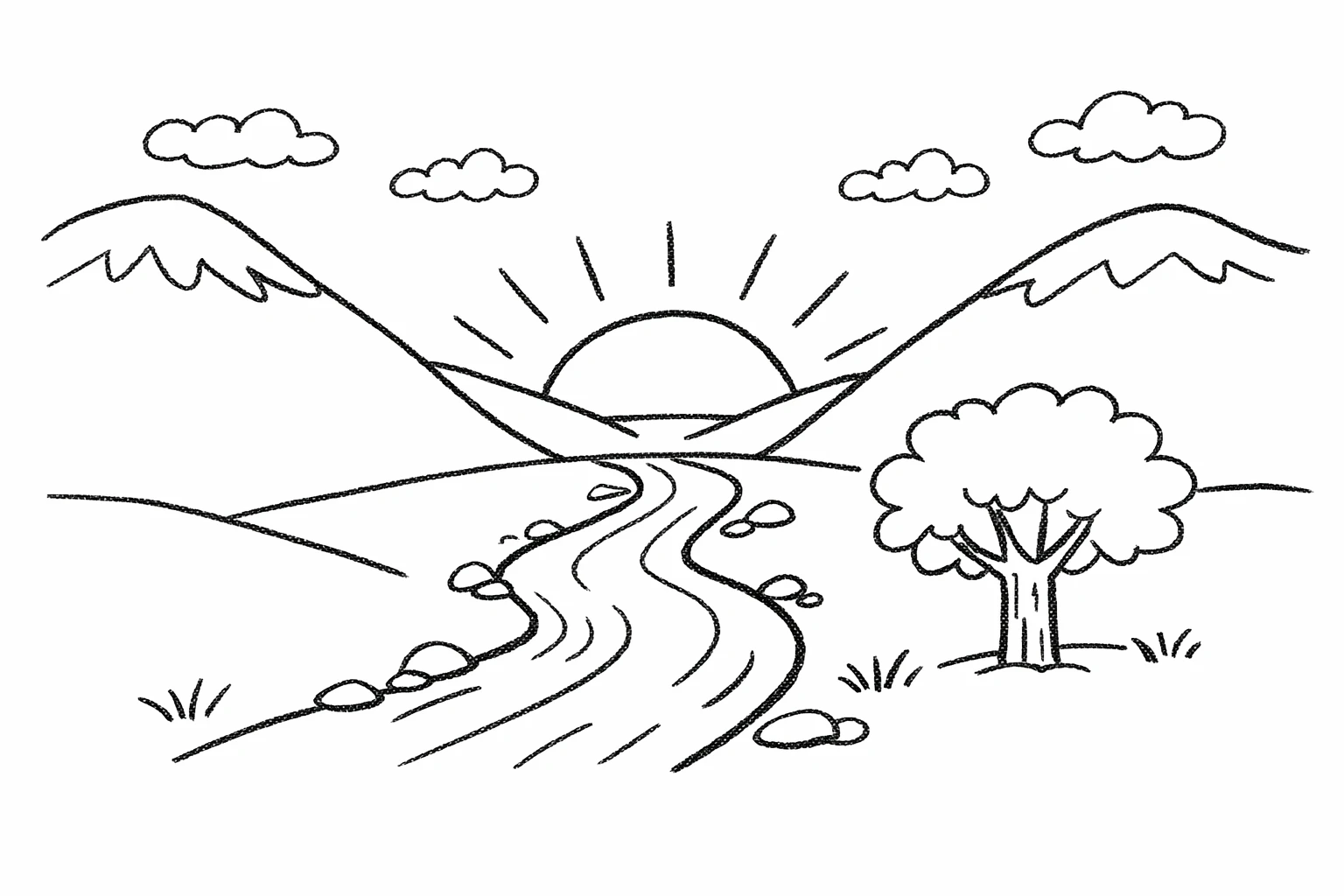
出力画像:

5.4 製品モックアップ(クリーン背景 + ラベル整合性)
製品抽出とモックアップ準備は、カタログ、マーケットプレイス、デザインシステムで一般的に使用。成功はエッジ品質(クリーンシルエット、フリンジング/ハローなし)とラベル整合性(テキストがシャープで変更なし)に依存。gpt-image-2 の場合、出力背景を不透明に保ち、最終透明アセットが必要な場合はダウンストリーム背景除去ステップを使用。スタイル変更せずにリアリズムが必要な場合、軽いポリッシングとオプションの微妙なコンタクトシャドウをプレーンバックグラウンドで要求。
prompt = """
入力画像から製品を抽出し、プレーンな白い不透明背景に置く。
出力:中央製品、クリスプシルエット、ハロー/フリンジングなし。
製品ジオメトリとラベルレジビリティを正確に保存。
軽いポリッシングと微妙な現実的なコンタクトシャドウのみ追加。
製品を再スタイルしない;背景を除去し、軽くポリッシュのみ。
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/shampoo.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
background="opaque",
)
save_image(result, "extract_product_gpt-image-2.png")
入力画像:

出力画像:

5.5 マーケティングクリエイティブとリアルテキストインイメージ
マーケティングクリエイティブとリアルインイメージテキストは、迅速な広告コンセプティングに最適だが、タイポグラフィには明示的な制約が必要。正確なコピーを引用し、verbatim レンダリング(余分な文字なし)を要求し、配置とフォントスタイルを記述。テキスト忠実度が不完全な場合、プロンプトを厳しく保ち、読みやすさを改善するために小さな単語/レイアウト調整を繰り返す。
prompt = """
サンセット中のハイウェイシーンでシャンプーの現実的なビルボードモックアップを作成。
ビルボードテキスト(EXACT、verbatim、余分な文字なし):
"Fresh and clean"
タイポグラフィ:ボールドサンセリフ、高コントラスト、中央、クリーンカーニング。
テキストが一度出現し、完全に読みやすいことを確認。
ウォーターマークなし、ロゴなし。
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/shampoo.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "billboard_gpt-image-2.png")
入力画像:
出力画像:

5.6 照明と天候変換
写真を異なるムード、季節、または一日中バリアント(例:晴れ → 曇り、日中 → 夕暮れ、晴れ → 雪)に再ステージングしながら、シーン構成をそのまま保持するために使用。変更するのは環境条件のみ—照明方向/品質、シャドウ、大気、降水、地面の湿気—アイデンティティ、ジオメトリ、カメラアングル、オブジェクト配置を保存して、同じオリジナル写真のように読めるように。
prompt = """
雪が降る冬の夕方に感じるようにする。
"""
result = client.images.edit(
model="gpt-image-2",
input_fidelity="high",
image=[
open("../../images/output_images/billboard_gpt-image-2.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "billboard_winter_gpt-image-2.png")
出力画像:

5.7 オブジェクト除去
人シーンコンポジティングは、ストーリーボード、キャンペーン、「what if」シナリオで顔/アイデンティティ保存が重要な場合に役立つ。リアリズムを固定するために、グラウンデッドフォトグラフィックルック(自然な照明、信じられる詳細、シネマティックグレーディングなし)を指定し、変更してはならない対象についてロック。利用可能な場合、より高い入力忠実度は大きなシーン編集中の類似性を維持するのに役立つ。
prompt = """
男の手から花を除去。他のものは変更しない。
"""
result = client.images.edit(
model="gpt-image-2",
input_fidelity="high",
image=[
open("../../images/output_images/man_with_blue_hat.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "man_with_no_flower_gpt-image-2.png")
入力と出力画像:
| オリジナル入力 | 出力画像 |
|---|---|
 |
 |
5.8 シーンに人を挿入
人シーンコンポジティングは、ストーリーボード、キャンペーン、「what if」シナリオで顔/アイデンティティ保存が重要な場合に役立つ。リアリズムを固定するために、グラウンデッドフォトグラフィックルック(自然な照明、信じられる詳細、シネマティックグレーディングなし)を指定し、変更してはならない対象についてロック。利用可能な場合、より高い入力忠実度は大きなシーン編集中の類似性を維持するのに役立つ。
prompt = """
この人がキャンプサイトを攻撃する大きな現実的な茶色の熊から逃げる高度に現実的なアクションシーンを生成。画像は誰かが撮影した本物の写真のように見える—not an overly enhanced or cinematic movie-poster image.
彼女は画像の中央にあり、カメラから離れて見ていて、アウトドアキャンプアトリビュートを着用し、顔に汚れ、衣類に裂け目。彼女は明らかに恐れていて、熊から逃げることに集中し、後ろのキャンプサイトを破壊している。
キャンプサイトはヨセミテ国立公園にあり、信じられる自然の詳細。時間帯は夕暮れ、自然な照明と現実的な色。一切がグラウンデッドで本物で、スタイル化されず、リアルな瞬間としてキャプチャされたように感じる。シネマティック照明、劇的な色グレーディング、またはスタイル化された構成を避ける。
"""
result = client.images.edit(
model="gpt-image-2",
input_fidelity="high",
image=[
open("../../images/input_images/woman_in_museum.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "scene_gpt-image-2.png")
出力画像:
from IPython.display import Image, display
display(Image(filename="../../images/output_images/scene_gpt-image-2.png", width=500))

5.9 複数画像参照とコンポジティング
複数の入力から単一の信じられる画像に要素を組み合わせるために使用—「このオブジェクト/人をそのシーンに挿入」ワークフローで、すべてを再生成せずに最適。移植するもの(第2画像の犬)をどこに置くか(第1画像の女性の隣)、何を変更しないか(シーン、背景、フレーミング)を明確に指定し、照明、パース、スケール、シャドウを一致させてコンポジットがオリジナル写真で自然にキャプチャされたように見えるように。
prompt = """
第2画像の犬を画像1の設定に置き、女性の隣に、同じ照明、構成、背景のスタイルを使用。他のものは変更しない。
"""
result = client.images.edit(
model="gpt-image-2",
input_fidelity="high",
image=[
open("../../images/output_images/test_woman.png", "rb"),
open("../../images/output_images/test_woman_2.png", "rb"),
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "test_woman_with_dog_gpt-image-2.png")
入力と出力画像:
| オリジナル入力 | 赤いストライプを除去 | 帽子色を変更 |
|---|---|---|
 |
 |
 |
6. 追加の高価値ユースケース
6.1 インテリアデザイン「スワップ」(精密編集)
家具や装飾の変更を視覚化するために、シーン全体を再レンダリングせずにリアルスペースで使用。目標は外科的リアリズム:単一オブジェクトをスワップしながらカメラアングル、照明、シャドウ、周囲のコンテキストを保存して、編集が本物の写真のように見える—not a redesign。
prompt = """
この部屋写真で、白い椅子を木製の椅子に置き換える ONLY。
カメラアングル、部屋照明、床シャドウ、周囲のオブジェクトを保存。
画像の他の側面を変更しない。
フォトリアリスティックコンタクトシャドウとファブリックテクスチャ。
"""
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/input_images/kitchen.jpeg", "rb"),
],
prompt=prompt,
size="1536x1024",
quality="medium",
)
save_image(result, "kitchen-chairs_gpt-image-2.png")
入力と出力画像:
| 入力画像 | 出力画像 |
|---|---|
 |
 |
6.2 3D ポップアップホリデーカード(製品スタイルモック)
季節的なマーケティングコンセプトとプリントプレビューに最適。タクタイルリアリズムを強調—紙層、繊維、折り、ソフトスタジオ照明—so the result reads as a photographed physical product rather than a flat illustration.
scene_description = (
"古いテディベアが思い出の箱の中に座っている暖かいクリスマスシーン、"
"少し着用された毛、ソフトなステッチ修理、窓のそばに置かれ、外に雪が降っている。"
"シーンは子供が成長したが、思い出が残ることを示唆。"
)
short_copy = "Merry Christmas — some memories never fade."
prompt = f"""
クリスマスホリデーカードイラストレーションを作成。
シーン:
{scene_description}
ムード:
暖かく、ノスタルジック、ジェントル、エモーショナル。
スタイル:
プレミアムホリデーカードフォトグラフィー、ソフトシネマティック照明、
現実的なテクスチャ、浅い被写界深度、
味わい深いボケライト、高プリント品質構成。
制約:
- オリジナルアートワークのみ
- 商標なし
- ウォーターマークなし
- ロゴなし
以下のカードテキストのみを含める(verbatim):
"{short_copy}"
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "christmas_holiday_card_teddy_gpt-image-2.png")
出力画像:

6.3 コレクタブルアクションフィギュア / プラッシュキーチェーン(メルコンセプト)
早期メルアイデアとピッチビジュアルに最適。プレミアム製品フォトグラフィーキュー(素材、パッケージング、プリント明確性)を維持しながら、デザインをオリジナルで非侵害に保つ。複数のキャラクターまたはパッケージバリアントを迅速にテストするのに適している。
# ---- 入力 ----
character_description = (
"冬の休暇中に子供たちが遊ぶシンプルなトイプロペラ飛行機のような、"
"丸い翼、前部取り付けスピニングプロペラ、少し着用されたペイントエッジ、"
"クラシックな子供のプロポーション、ノスタルジックなホリデーコレクタブルとしてデザイン。"
)
short_copy = "Christmas Memories Edition"
# ---- プロンプト ----
prompt = f"""
ブリスターパッケージングで {character_description} のコレクタブルアクションフィギュアを作成。
コンセプト:
冬の休暇中に子供たちが遊ぶシンプルなトイ飛行機を思い起こさせるノスタルジックなホリデーコレクタブル。
暖かさ、想像力、子供の驚きを呼び起こす。
スタイル:
プレミアムトイフォトグラフィー、現実的なプラスチックとペイントメタルのテクスチャ、
スタジオ照明、浅い被写界深度、
シャープラベルプリンティング、高級リテールプレゼンテーション。
制約:
- オリジナルデザインのみ
- 商標なし
- ウォーターマークなし
- ロゴなし
以下の包装テキストのみを含める(verbatim):
"{short_copy}"
"""
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "christmas_collectible_toy_airplane_gpt-image-2.png")
出力画像:

6.4 子供の本アートとキャラクター一貫性(複数画像ワークフロー)
複数ページイラストレーションパイプラインでキャラクターのドリフトが許されないように設計。再利用可能な「キャラクターアンカー」がシーン、ポーズ、ページ間で視覚的連続性を確保し、環境的およびナラティブバリエーションを可能にする。
1️⃣ キャラクターアンカー — 再利用可能なメインキャラクターを確立
目標:キャラクターの外見、プロポーション、アウトフィット、トーンをロック。
# ---- 入力 ----
prompt = """
メインキャラクターを紹介する子供の本イラストレーションを作成。
キャラクター:
小さな森のアウトローからインスパイアされた若いストーリーブックヒーロー、
シンプルな緑のフード付きチュニック、ソフトブラウンブーツ、小さなベルトポーチを着用。
キャラクターは優しい表情、優しい目を持ち、勇敢だが暖かいデミナー。
助けるためにのみ使用される小さな木の弓を運び、害を与えない。
テーマ:
キャラクターは小さな森の動物を保護し、救出:リス、鳥、ウサギ。
スタイル:
子供の本イラストレーション、手描き水彩ルック、
ソフトアウトライン、暖かいアースカラー、ウィムジカルでフレンドリー。
ピクチャーブックに適したプロポーション(少しオーバーサイズの頭、表現力のある顔)。
制約:
- オリジナルキャラクター(著作権キャラクターなし)
- テキストなし
- ウォーターマークなし
- キャラクターを明確に展示するためのプレーン森背景
"""
# ---- 画像生成 ----
result = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "childrens_book_illustration_1_gpt-image-2.png")
出力画像:

2️⃣ ストーリー継続 — キャラクターを再利用、ナラティブを進める
目標:同じキャラクター、新しいシーン + アクション。
キャラクターの外見は変更しない。
# ---- 入力 ----
prompt = """
同じキャラクターを使用して子供の本ストーリーを続ける。
シーン:
同じ若い森のヒーローが冬の嵐後に倒れた木から怯えたリスを優しく助ける。
キャラクターはリスに安心を提供するためにリスのかたわらに膝をつく。
キャラクター一貫性:
- 同じ緑のフード付きチュニック
- 同じ顔の特徴、プロポーション、カラーパレット
- 同じ優しく、英雄的な性格
スタイル:
子供の本水彩イラストレーション、
ソフト照明、雪の森環境、
暖かく、快適なムード。
制約:
- キャラクターを再デザインしない
- テキストなし
- ウォーターマークなし
"""
# ---- 画像生成 ----
result = client.images.edit(
model="gpt-image-2",
image=[
open("../../images/output_images/childrens_book_illustration_1_gpt-image-2.png", "rb"), # ステップ1の画像を使用
],
prompt=prompt,
size="1024x1536",
quality="medium",
)
save_image(result, "childrens_book_illustration_2_gpt-image-2.png")
出力画像:

結論
このノートブックでは、gpt-image 生成モデルを使用して、本物の生産設定で持続する高品質で制御可能な画像生成と編集ワークフローを構築する方法を示します。このクックブックは、プロンプト構造、明示的な制約、小さな反復変更を、リアリズム、レイアウト、テキスト精度、アイデンティティ保存を制御するための主要ツールとして強調します。インフォグラフィック、フォトリアリズム、UI モックアップ、ロゴから翻訳、スタイル転送、仮想試着、コンポジティング、照明変更までの生成と編集パターンをカバーします。例全体を通して、クックブックは変更すべきものと不変のものを明確に分離することの重要性を強化し、各イテレーションで不変を再述べしてドリフトを防ぎます。また、品質と入力忠実度設定がユースケースに応じて遅延と視覚精度の間の慎重なトレードオフを可能にする方法を強調します。これらすべてが一緒になって、gpt-image 生成モデルを生産画像ワークフローに適用するための実用的で繰り返し可能なプレイブックを形成します。