はじめに
この記事では、 juce の AudioProcessorGraph クラスが、AudioProcessor 同士の複雑な接続状態に対して、どのように再生処理を行っているのかを解説します。1
今回の記事では、AudioProcessorGraph クラスの再生処理の肝である GraphRenderSequence クラスの解説と、RenderSequenceBuilder クラスの途中までを解説します。 RenderSequenceBuilder の細かい処理は次回の記事で解説します。
juce のソースは、バージョン 5.4.5 のものを使用します。
AudioProcessorGraph とは
AudioProcessorGraph は、 juce の AudioProcessor クラス同士を接続して、まとめて再生処理を行うクラスです。以降では AudioProcessorGraph で管理する AudioProcessor 同士の接続状態をグラフと呼ぶことにします。
juce では、オーディオプラグインを AudioProcessor の派生クラスとして扱うので、 プラグイン同士を AudioProcessorGraph 上で接続して、グラフを構築できます。オーディオプラグインに限らず、なにかオーディオ/MIDI 信号を生成したり加工したりするようなクラスがある場合に、それを AudioProcessor の派生クラスとして実装すれば、オーディオプラグインと同じようにグラフを構築できます。
また、 AudioProcessorGraph は、それ自身が AudioProcessor の派生クラスになっているため、 AudioProcessorGraph の中に別の AudioProcessorGraph を入れ子にすることもできます。
グラフを扱う処理の難しさについて
オーディオアプリケーションでプラグイン同士の複雑なグラフを正しく扱うのは、意外と面倒です。これは以下のような理由のためです。
- Audio/MIDI という、ふたつの性格のことなるデータを扱う必要がある。
- 一般的に、オーディオデータは、事前に設定したブロックサイズによって決まる大きさを持つ固定長バッファにオーディオ信号を書き込んで受け渡し、MIDI データは可変サイズのバッファに MIDI メッセージを書き込んで受け渡す。また、チャンネルの概念が Audio/MIDI でことなる。
- グラフを変更する処理が、再生処理と競合しないように注意する必要がある。
- リアルタイムに再生/編集を行うアプリケーションでは、これを正しく実装しないと、再生が頻繁に途切れたりクラッシュしたりする。
- グラフの状態に合わせて、各プラグインで発生するレイテンシを正しく償却する必要がある。
- これを正しく実装しないと、複雑なグラフを構築したときに、別々の経路を流れてくる音のタイミングがずれてしまう。
- フィードバック接続2 に対処する必要がある。
juce の AudioProcessorGraph クラスは、これらのうち 1-3 を実装していて、4については、フィードバック接続が存在する場合、その一部を自動的に切り離してフィードバック接続を解消する仕組みを実装しています。
AudioProcessorGraph の再生処理の仕組み
以降では、 AudioProcessorGraph クラスが実際にどのようにして、複雑なグラフに対して再生処理を行っているのかを見ていきます。
juce のソースは、バージョン 5.4.5 のものを使用します。
GraphRenderSequence とは
AudioProcessorGraph が再生処理を行うときに、一番重要なクラスが、 GraphRenderSequence です。
template <typename FloatType>
struct GraphRenderSequence
{
// GraphRenderSequence 構築時のグラフ状態にしたがって再生処理を行う
void perform (AudioBuffer<FloatType>& buffer, MidiBuffer& midiMessages, AudioPlayHead* audioPlayHead);
// ...
};
このクラスの perform() メンバ関数が AudioProcessorGraph のグラフを順番にたどって再生処理する役割を担っています。このため、 AudioProcessorGraph の processBlock() メンバ関数は、実質的な再生処理をほとんどこの perform() メンバ関数に任せています。
template <typename FloatType, typename SequenceType>
static void processBlockForBuffer (AudioBuffer<FloatType>& buffer, MidiBuffer& midiMessages,
AudioProcessorGraph& graph,
std::unique_ptr<SequenceType>& renderSequence,
Atomic<int>& isPrepared)
{
// ...
const ScopedLock sl (graph.getCallbackLock());
if (isPrepared.get() == 1)
{
if (renderSequence != nullptr)
// ここで GraphRenderSequence::perform() を呼び出して再生処理を行う
renderSequence->perform (buffer, midiMessages, graph.getPlayHead());
}
// ...
}
void AudioProcessorGraph::processBlock (AudioBuffer<float>& buffer, MidiBuffer& midiMessages)
{
if (isPrepared.get() == 0 && MessageManager::getInstance()->isThisTheMessageThread())
handleAsyncUpdate();
processBlockForBuffer<float> (buffer, midiMessages, *this, renderSequenceFloat, isPrepared);
}
GraphRenderSequence のテンプレート引数について
GraphRenderSequence クラスは、テンプレート引数に浮動小数点型を受け取ります。
オーディオ信号処理を実装する場合、 float 型でデータを受け渡す 32 bit 浮動小数点数での信号処理と、 double 型でデータを受け渡す 64 bit 浮動小数点数での信号処理は、型の違いを無視すればほとんど同じようなコードを実装することになります。
GraphRenderSequence クラスではテンプレートを使用することでコードを共通化し、浮動小数点型の違いをほとんど意識しないで済むようにしています。それぞれの浮動小数点型のための GraphRenderSequence は、以下のように別名が付けられています。
struct AudioProcessorGraph::RenderSequenceFloat : public GraphRenderSequence<float> {};
struct AudioProcessorGraph::RenderSequenceDouble : public GraphRenderSequence<double> {};
AudioProcessorGraph はこれらのクラスを以下のように unique_ptr のメンバ変数として保持していて、 32 bit 浮動小数点数での信号処理と 64 bit 浮動小数点数での信号処理のどちらも呼び出せるようにしています。
std::unique_ptr<RenderSequenceFloat> renderSequenceFloat;
std::unique_ptr<RenderSequenceDouble> renderSequenceDouble;
GraphRenderSequence の再構築について
GraphRenderSequence はある時点でのグラフの状態をもとに再生処理を行います。そのため、プラグインを繋ぎ変えてグラフの状態が変わったり、バッファサイズ/サンプリングレートが変更されたりしたときには、 AudioProcessorGraph クラスは triggerAsyncUpdate() メンバ関数を呼び出して、 GraphRenderSequence クラスの再構築をリクエストします。
triggerAsyncUpdate() メンバ関数によるリクエストは、 handleAsyncUpdate() メンバ関数によって非同期に処理されます。
void AudioProcessorGraph::handleAsyncUpdate()
{
buildRenderingSequence();
isPrepared = 1;
}
ここで呼び出している buildRenderingSequence() メンバ関数の中で GraphRenderSequence が作り直されます。このメンバ関数の詳細については後ほど詳しく見ていきます。
renderOps について
GraphRenderSequence は、 renderOps というメンバ変数を持っています。
OwnedArray<RenderingOp> renderOps;
renderOps は RenderingOp クラスの配列になっています。 RenderingOp クラスは、AudioProcessorGraph の再生処理で行うひとつひとつの処理を表す抽象基底クラスで、具体的には、以下のような処理を表します。
- 指定したバッファの内容を、別のバッファにコピーする。
- レイテンシを償却するためにオーディオの再生タイミングを調整する。
- プラグインの 1 ブロック分の再生処理を呼び出す。など。
renderOps はこれらの処理を順番に並べたもので、言わば AudioProcessorGraph が行う再生処理の手順書になっています。したがって現在のグラフに合わせてこの手順書を用意できれば、あとはこれを順番に実行していくだけで AudioProcessorGraph の再生処理を実行できます。実際に GraphRenderSequence::perform() メンバ関数ではそのようにして再生処理を実行しています。
for (auto* op : renderOps)
op->perform (context);
手順書を用意する処理、すなわち renderOps を用意する処理は、 GraphRenderSequence を再構築する buildRenderingSequence() の中で行われます。
buildRenderingSequence() メンバ関数について
buildRenderingSequence() は、現在の AudioProcessorGraph の状態をもとに GraphRenderSequence を構築するメンバ関数で、以下のような実装になっています。
void AudioProcessorGraph::buildRenderingSequence()
{
// -- (1)
std::unique_ptr<RenderSequenceFloat> newSequenceF (new RenderSequenceFloat());
std::unique_ptr<RenderSequenceDouble> newSequenceD (new RenderSequenceDouble());
{
MessageManagerLock mml;
// -- (2)
RenderSequenceBuilder<RenderSequenceFloat> builderF (*this, *newSequenceF);
RenderSequenceBuilder<RenderSequenceDouble> builderD (*this, *newSequenceD);
}
{
const ScopedLock sl (getCallbackLock());
// -- (3)
newSequenceF->prepareBuffers (getBlockSize());
newSequenceD->prepareBuffers (getBlockSize());
}
// -- (4)
if (anyNodesNeedPreparing())
{
{
const ScopedLock sl (getCallbackLock());
renderSequenceFloat.reset();
renderSequenceDouble.reset();
}
for (auto* node : nodes)
node->prepare (getSampleRate(), getBlockSize(), this, getProcessingPrecision());
}
const ScopedLock sl (getCallbackLock());
// -- (5)
std::swap (renderSequenceFloat, newSequenceF);
std::swap (renderSequenceDouble, newSequenceD);
}
RenderSequenceFloat と RenderSequenceDouble はそれぞれ、 float 版と double 版の GraphRenderSequence を表します。
buildRenderingSequence() では、まず (1) の段階でGraphRenderSequence() の新しいインスタンスを作成します。
// -- (1)
std::unique_ptr<RenderSequenceFloat> newSequenceF (new RenderSequenceFloat());
std::unique_ptr<RenderSequenceDouble> newSequenceD (new RenderSequenceDouble());
この時点ではまだ renderOps を含め GraphRenderSequence の状態はなにも再生用に準備されていません。それを行うのが (2) で登場する RenderSequenceBuilder クラスです。
// -- (2)
RenderSequenceBuilder<RenderSequenceFloat> builderF (*this, *newSequenceF);
RenderSequenceBuilder<RenderSequenceDouble> builderD (*this, *newSequenceD);
RenderSequenceBuilder クラスは、コンストラクタで AudioProcessorGraph 自身と GraphRenderSequence を引数に取ります。そして、現在のグラフをもとに renderOps を構築したり、各 Node(AudioProcessor を AudioProcessorGraph 上で管理するためのラッパークラス)の再生処理でどれだけのバッファが必要になるかを算出します。3
必要なバッファを算出する仕組みについて、もう少し補足します。
AudioProcessorGraph はグラフの再生処理の中で、一度データを書き込んだバッファであっても上書きして再利用して良い場合は積極的に再利用し、余分なメモリを消費しないで済むように実装しています。ただしそのため、グラフの再生処理全体でいくつのバッファが必要になるかが、各 Node のチャンネル数だけではなく、接続状態によっても変わることになります。
このため、 RenderSequenceBuilder では AssignedBuffer というクラスを利用して、どの Node がどのタイミングでどのバッファを利用するかという情報をまとめ、グラフの再生処理に必要なバッファを算出できるようにしています。
RenderSequenceBuilder クラスの実装については、後で詳しく見ていきます。
RenderSequenceBuilder のコンストラクタの中で計算されたバッファの個数は、GraphRenderSequence の numBuffersNeeded/numMidiBuffersNeeded メンバ変数にキャッシュされます。
その後 (3) の箇所で、 AudioProcessorGraph に設定されているブロックサイズと、(2) で計算したバッファの個数をもとに、 GraphRenderSequence に再生処理用のバッファを用意します。この段階で GraphRenderSequence には、グラフの再生処理に必要な renderOps とその処理で利用するバッファが準備できたことになります。
// -- (3)
newSequenceF->prepareBuffers (getBlockSize());
newSequenceD->prepareBuffers (getBlockSize());
(4) の箇所は、再生状態が整っていない Node がある場合の処理で、そのような Node があるときは、古い GraphRenderSequence を先に破棄してから、すべての Node の prepare() メンバ関数を呼び出して、再生状態を準備します。
ここで、古い GraphRenderSequence を先に破棄しなければならない理由は不明です。 anyNodesNeedPreparing() が true になるのは、新たに Node を追加したときや、 AudioProcessorGraph 自体のブロックサイズを変更したときなどであるため、そのような状況に関係している処理だと思いますが、詳しい理由は分かりません。
// -- (4)
if (anyNodesNeedPreparing())
{
{
const ScopedLock sl (getCallbackLock());
renderSequenceFloat.reset();
renderSequenceDouble.reset();
}
for (auto* node : nodes)
node->prepare (getSampleRate(), getBlockSize(), this, getProcessingPrecision());
}
(5) の箇所では、構築した GraphRenderSequence を、古いものと入れ替え、新しい GraphRenderSequence で再生処理が行われるようにしています。
// -- (5)
std::swap (renderSequenceFloat, newSequenceF);
std::swap (renderSequenceDouble, newSequenceD);
次は、 buildRenderingSequence() の一番の肝である、 RenderSequenceBuilder の処理を見ていきます。
RenderSequenceBuilder について
RenderSequenceBuilder クラスは、先に書いたとおり、現在のグラフをもとに
renderOps を構築したり、このグラフの再生処理を行うために必要なバッファの個数を算出したりするクラスです。
コンストラクタは以下のようになっています。ここで RenderSequence は RenderSequenceBuilder クラスのテンプレート引数で、 RenderSequenceFloat か RenderSequenceDouble かどちらかの型になります。
RenderSequenceBuilder (AudioProcessorGraph& g, RenderSequence& s)
: graph (g), sequence (s)
{
// -- (1)
createOrderedNodeList();
// -- (2)
audioBuffers.add (AssignedBuffer::createReadOnlyEmpty()); // first buffer is read-only zeros
midiBuffers .add (AssignedBuffer::createReadOnlyEmpty());
// -- (3)
for (int i = 0; i < orderedNodes.size(); ++i)
{
createRenderingOpsForNode (*orderedNodes.getUnchecked(i), i);
markAnyUnusedBuffersAsFree (audioBuffers, i);
markAnyUnusedBuffersAsFree (midiBuffers, i);
}
// -- (4)
graph.setLatencySamples (totalLatency);
// -- (5)
s.numBuffersNeeded = audioBuffers.size();
s.numMidiBuffersNeeded = midiBuffers.size();
}
コンストラクタではまず、 (1) で、 createOrderedNodeList() メンバ関数を呼び出しています。 createOrderedNodeList() では、グラフに含まれる Node に順序を付け、その結果を orderedNodes メンバ変数に設定します。これによって orderedNodes の先頭が最上流、末尾 を最下流として Node が順序付けられます。
Array<AudioProcessorGraph::Node*> orderedNodes;
次に (2) で、 audioBuffers/midiBuffers というふたつのメンバ変数に、要素をひとつずつ追加しています。 audioBuffers/midiBuffers は、 AssingedBuffer クラスの配列になっていて、どの Node がどのバッファを使用するかを表すテーブルになっています。そのため、名前が混乱しますが audioBuffers/midiBuffers 自体はオーディオ/MIDI データを保持しません。
// -- (2)
audioBuffers.add (AssignedBuffer::createReadOnlyEmpty());
midiBuffers .add (AssignedBuffer::createReadOnlyEmpty());
audioBuffers/midiBuffers の先頭に追加している createReadOnlyEmpty() は、空の入力として使われる特殊なバッファを表しています。
(3) では、 orderedNodes を最上流から順番に処理し、各 Node で必要になる再生処理を renderOps に追加し、必要になるバッファの情報を audioBuffers/midiBuffers に追加します。また、グラフ中を流れるオーディオデータのタイミングを一致させるために、各 Node を流れるオーディオのレイテンシがどれくらいになるかも算出しています。
// -- (3)
for (int i = 0; i < orderedNodes.size(); ++i)
{
createRenderingOpsForNode (*orderedNodes.getUnchecked(i), i);
markAnyUnusedBuffersAsFree (audioBuffers, i);
markAnyUnusedBuffersAsFree (midiBuffers, i);
}
このとき audioBuffers/midiBuffers に追加したいくつかのバッファの情報のうち、後続の Node では参照されることがなく、上書きしてしまっても問題がないバッファが含まれることがあります。 (3) の後半では、そのようなバッファの情報を修正して、自由に使っていいバッファだというマークを付けています。
(4) では、すべての Node を処理し終えて、最終的に算出されたレイテンシ値を AudioProcessorGraph 全体のレイテンシとして設定します。
// -- (4)
graph.setLatencySamples (totalLatency);
(5) では、すべての Node を処理し終えて、最終的に必要だと算出されたバッファの数を GraphRenderSequence のメンバ変数にキャッシュして、処理を終えます。
// -- (5)
s.numBuffersNeeded = audioBuffers.size();
s.numMidiBuffersNeeded = midiBuffers.size();
次に、このコンストラクタで行っている処理をより詳しく見ていきます。
Node の順序付けについて
createOrderedNodeList() メンバ関数の実装は次のようになっています。
void createOrderedNodeList()
{
for (auto* node : graph.getNodes())
{
int j = 0;
for (; j < orderedNodes.size(); ++j)
// もし *node から *orderedNodes.getUnchecked(j) への接続が、
// 直接か間接かに関わらず存在していれば true を返す。
if (graph.isAnInputTo (*node, *orderedNodes.getUnchecked(j)))
break;
orderedNodes.insert (j, node);
}
}
ここでやっている処理は、グラフに含まれるすべての Node に対して、 Node の接続状態をもとにして順序を付けたリストの作成です。この処理によって、 orderedNodes は、先頭が最上流、末尾が最下流を表すリストになります。
ただし、 AudioProcessorGraph のグラフには必ずしも正しい順序が存在するとは限りません。つまり、グラフが連結でない場合(ふたつ以上の独立したグラフが存在している場合)や、フィードバック接続によるループが存在する場合があります。
連結でないグラフの例:
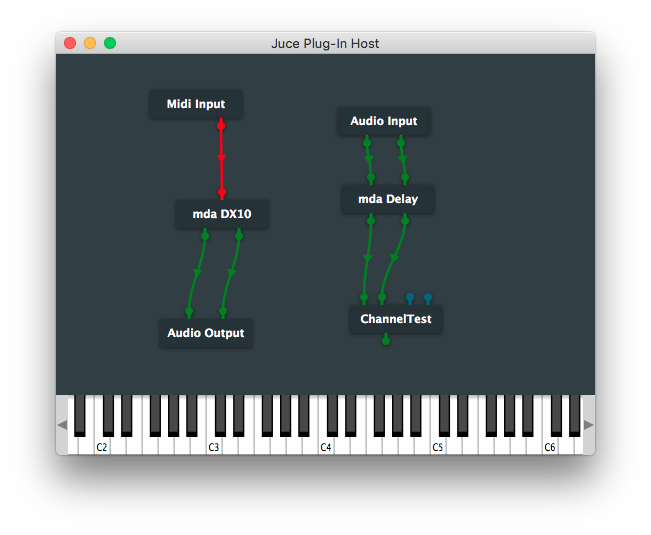
フィードバック接続によるループが存在するグラフの例:
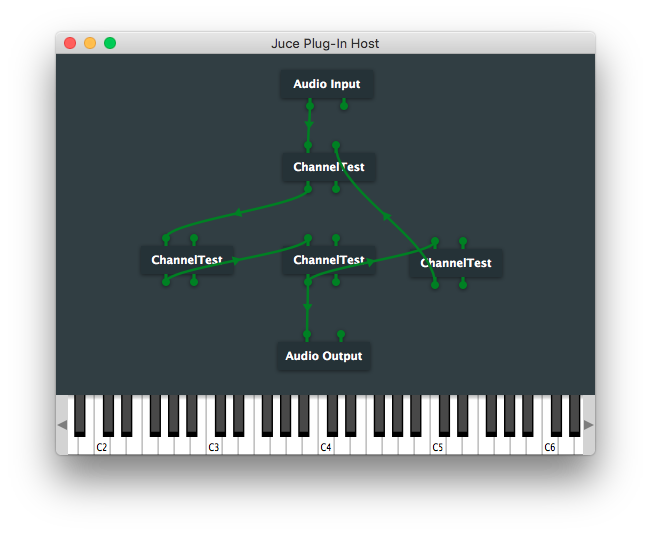
これらに対してどのように順序が付けられるかは、 graph.getNodes() で取得される Node の順番に依存します。しかしともかく、 createOrderedNodeList() メンバ関数はこの仕組みで、 Node 同士の間に順序を付けます。
AssignedBuffer について
AssignedBuffer は、次のように定義されるクラスです。
struct AssignedBuffer
{
AudioProcessorGraph::NodeAndChannel channel;
static AssignedBuffer createReadOnlyEmpty() noexcept { return { { zeroNodeID(), 0 } }; }
static AssignedBuffer createFree() noexcept { return { { freeNodeID(), 0 } }; }
bool isReadOnlyEmpty() const noexcept { return channel.nodeID == zeroNodeID(); }
bool isFree() const noexcept { return channel.nodeID == freeNodeID(); }
bool isAssigned() const noexcept { return ! (isReadOnlyEmpty() || isFree()); }
void setFree() noexcept { channel = { freeNodeID(), 0 }; }
void setAssignedToNonExistentNode() noexcept { channel = { anonNodeID(), 0 }; }
private:
// Node に紐付いてはいないが上書きされてほしくないバッファを表す
static NodeID anonNodeID() { return NodeID (0x7ffffffd); }
// 読み込み専用で空の入力として扱うバッファを表す
static NodeID zeroNodeID() { return NodeID (0x7ffffffe); }
// 自由に上書きして良いバッファを表す
static NodeID freeNodeID() { return NodeID (0x7fffffff); }
};
このクラスは、唯一のメンバ変数として AudioProcessorGraph::NodeAndChannel 型の channel 変数を持っています。 AudioProcessorGraph::NodeAndChannel 型は、 Node の ID とチャンネルのペアです。
struct NodeAndChannel
{
NodeID nodeID;
int channelIndex;
bool isMIDI() const noexcept { return channelIndex == midiChannelIndex; }
bool operator== (const NodeAndChannel& other) const noexcept { return nodeID == other.nodeID && channelIndex == other.channelIndex; }
bool operator!= (const NodeAndChannel& other) const noexcept { return ! operator== (other); }
};
つまり、 AssignedBuffer は、自身がどの Node のどのチャンネルに紐付いているかだけを表すクラスです。また、特殊な用途で使われれるバッファを表すために、特別な Node ID として anonNodeID/zeroNodeID/freeNodeID の3つを定義しています。
AssignedBuffer はそれ自体はバッファーではなく、 RenderSequenceBuilder の audioBuffers/midiBuffers メンバ変数とともに使われることで意味を持ちます。
つまり、 audioBuffers の 7 番目の要素(audioBuffers[6])の値が、AssignedBuffer { { 4, 1 } } だった場合、これは ID が 4 の Node の 2 番目のチャンネルが、 GraphRenderSequence が用意するバッファのうち 7 番目のバッファを使用することを意味しています。
createRenderingOpsForNode() について
記事全体の分量が多くなったので、続きは次回にまわします。