拡散言語モデルを作ろう!
大規模言語モデル(LLM)が流行っている昨今、もちろんいろいろなモデルがあるわけですが、その中でも個人的に注目しているのが、拡散言語モデルです。
なんで注目しているのか?、というと、まあこの記事を読んだから、というのが一つあります。
加えて、以前少し話題になった、Mercury coderの性能(特に生成速度)が異常に早かったためです。
そんな中、つい先日の発表で、googleからも拡散言語モデルである、Gemini diffusionが発表されました。
その勢いに任せて、実際に拡散モデルを作ってコードを見てみよう、というのが今回の記事の趣旨になります。
私本人は専門家ではない(予防線)ので、いろいろと至らぬ点があると思いますが、そこはご容赦を。
コードも基本的にはAi生成(claude4 sonnet)になりますが、動作確認はとれていますので、その点についてもご容赦いただけたらと思います。
一般的LLMと拡散言語モデル
まずは総説的な話から始めます。
一般的LLMってどんなもの
まずは一般的なLLMについてです。
ベースとなるモデル
基本的に、モデルとしてはTransformerというディープラーニングモデルの、decoder部分を使用しています。
Transformerというモデルは、次の論文で用いられたモデルであり、本当にすべての起点になった論文です。
もともとは、翻訳のタスクのために生み出されたモデルだったものが、改良されて現在まで来ています。
(all you need構文、個人的には嫌い)
このモデルがなんで強いのか?というと、一番は文中の要素について、前後関係を考慮できるからだという風に言われているはずです。
以前までのモデルは、行ってしまえば文の先頭から末端の方向にかけて情報を徐々に伝えていく、みたいな形だったものが、前後関係を考慮できる、つまり文中の各要素について、互いにどのように影響しているかを考慮できるようになりました。
Attention機構
文中の各要素の関係性を考慮できる、という性質は、主にこのAttention機構によって獲得されています。
詳しい説明は別記事に譲るとして、ここではこの機構によって、文脈依存的な要素をとらえられるようになり、計算量が入力文字列の二乗に比例する形になった、というところだけ押さえてもらえたらと思います。
一般的LLMでの文章生成
実際に、じゃあLLMに文章を生成させるとなったとき、どのような処理がされているか?についてです。
すさまじく雑に言うと、今までの入力と出力を加味して、次の単語を一つずつを予測する、という形で生成されています。
段階を分けて書くと、
1. 入力をモデルに入れる
2. 入力をもとに、それらしいものを一単語出力する
3. 入力と出力された単語をセットにしてモデルに入れる
4. 入れられたものをベースにそれらしいものを一単語出力する
5. 3~4を繰り返す
という流れになっています。なので、出力する文章が長くなればなるほど、計算量が増大して、出力に必要な時間も長くなっていきます。
ここで大事なのは、あくまで次単語予測の繰り返しであるということです。
一般的LLMでの学習過程
一般的LLMでは、大別して2つの学習過程に分かれています。
1. 事前学習
2. 事後学習
の二つです。
LLMは、基本的に次単語予測を行います。ですので、学習の際もそれに倣って、ひたすら文章を食わせて、その次の単語は何か?を予測させるというステップを繰り返します。
例えば、私はリンゴが好きです。、という文章が学習データセットの中にあったとしたら、まず、私、を食わせて、次の、は、を出力させるよう訓練し、次に、私は、を食わせて、リンゴ、を出力させようとします。これを、集めた大量の文章データセットを用いて行います。
この学習方法の利点としては、別に正解用データなどを作る必要がなく、ただ文章を食わせればいいので、例えば翻訳タスクのように、原文と翻訳文の二つが必要だ、ということも無いので、非常に準備が楽で大量に用意できるということです。
事後学習については、おおざっぱに言うと、好ましい方向にチューニングする、というステップになります。
例えば、ある入力に対して、好ましい出力を用意しておき、モデルの出力をそれに近づけるように学習させるといったものや、モデルに複数パターン出力させて、それを見た人間が好ましさを評価し、モデルに学習させることで、人にとって好ましい出力をさせるようにするといったものが挙げられます。
これらの過程を経て一般的LLMが作られています。
一般的LLMの課題
ではそんなLLMの課題はどんなものかというと、主に二つあると思っていて、それは
1. すでに出力されたものを修正できない
2. 一度に一単語しか出力できない
という二つです。どうして課題だと思っているかというと、一度出力したものを修正出来ず、基本的に前までの内容に依存して次の単語を出力するので、一度間違ったとしても方向転換が難しいということ、そして出力の速度を劇的に上げることが困難であるということです。
(ここでは、reasoningモデルのaha momentのようなものや、reflectionによる改善などの話は触れません。めんどいので)
なので、これらの課題を解決できるようなモデルが求められていた、と考えています。
余談 現状の生成速度を上げるための試み
現在、出力速度に関しては、ハードウェアを最適化する、ソフトウェアを最適化するなどの方法で頑張っているところがあります。
-
ハードウェア最適化
根本的な話で、出力速度の一番のネックは、メモリ帯域となっています。これはどうやら、ノイマン型コンピューターを使っているために起きているらしい(wiki調べ)ですが、これを改善するために色々な手段がとられています。
例えば、GPUに載せるVRAMを、通常のゲーム向けグラボに搭載されている、GDDR系ではなく、HBM系にする、などです。これによって、メモリ帯域を無理やり改善して性能を上げたりしています。
実際、NVIDIAのAI向け?GPUである、H100とH200は、演算性能自体は同じですが、メモリ帯域が増えただけで、性能が向上しています。
別のメモリ帯域改善手法としては、SRAMを活用するといったものがあります。SRAMはCPUなどの演算を行う部分に最も近い記憶領域ですが、代わりに容量の確保が難しいものとなっています。この容量を確保するために、チップのサイズをハチャメチャに大きくして、ある程度容量を確保するとともに、メモリ帯域も他とは桁が3~4つほど異なるようなチップを提供している企業も在ったりします。(cerebras)
ハードウェア最適化では、そもそもGPUを使わずに、transformerモデル専用にチューニングされた計算機を作っている企業も在ったりします。(Etched、groq(イーロンマスクのgrokとは別)など) -
ソフトウェア最適化
ソフトウェア最適化の面(というか高速化)で一番有名なものとしては、Flash attentionや、KVキャッシュなどがあったりします。
Flash attentionは、SRAMを使って効率的にAttention部分の計算を行うような手法になります。
先ほどSRAMを使って高速化する、みたいな話をしましたが、この手法を非常にざっくり言うと、SRAMを有効に使うことで、メモリ帯域が低いHBMへの書き込みを可能な限り減らして速度を向上させるものになっています。それに加えて、計算方法も前回の結果を利用して逐次的に更新できるようにしていたはずです。
これらによって、単純に推論を回すよりもかなり高速に計算を行うことが可能になっています。
KVキャッシュは、以前計算したものを記憶しておいてその結果を再利用することで高速化する手法になります。
仕組みなどの言及は避けます(わからん)が、実際に使用する時は、KVキャッシュの分メモリー容量を圧迫することになり、もし高速なメモリの容量で収まらなかったら、SSDなどのストレージにデータが保管されて、速度が格段に遅くなる、といった現象が発生しうることになります。なので、そこはハードウェアコストとの兼ね合いになります。
まとめr、速度向上というだけでも、本当に様々な取り組みが行われています。
外野から見ていると楽しい。
拡散言語モデル
拡散言語モデルについてです。
そもそも拡散モデルって何?
そもそも、拡散モデルとは一体何なのでしょうか?
おそらく皆さんはStable diffusionというお絵描きAIについて聞いたことがあると思いますが、そのベースとなるモデルのことです。
ざっくりというと、ノイズを除去する過程を学習するというものです。(正直ちゃんと説明できるほど分かってないので、別記事に譲ります。)
じゃあ拡散言語モデルってどんなもの?
拡散言語モデルは、拡散モデルがノイズを除去していくことで生成するものだったのに対して、maskを徐々にとっていく形で文章を生成するものです。
例えば、私は????が好きです。、という文章があったときに、この文章をモデルに投げて、????となっている部分(maskされている部分)を、前後関係から推定して、完全な文(例えば、私はみかんが好きです。など)を出力するものになっています。
なので、拡散モデルでいうところのノイズはmaskにあたり、これを徐々にとっていく、というものになります。
何が利点なのか?
一般的LLMで上げた課題は
1. すでに出力されたものを修正できない
2. 一度に一単語しか出力できない
の二つになりますが、これらを拡散言語モデルは解決(少なくとも多少まし)することが出来ます。
拡散言語モデルを用いた文章生成は以下のような流れになります。
1. 入力とそれに続くmaskトークン列を合わせてモデルに入れる
2. モデルがmaskトークンの一部を予測して穴埋めする
3. 一部のmaskトークンが穴埋めされた文字列(入力+maskトークン列)を再度モデルに入れる
4. 2~3を繰り返す
重要な点として、モデルに文字列を入力するたびに、全てのトークンについての確率計算が行われることから、もし初期段階で間違えたトークンを出力していたとしても、後のステップでそれを改善することが出来ます。
また、一度のステップで穴埋めされるトークンの数は、1つだけではなく、ある程度自由に決めることが出来ます。ですので、一度のサイクルで1トークンしか出力できない、という問題を解決することが出来ます。
実際どんなモデルがどんな風に出力してるの?
ここで一度、実際にどうなっているかを見ていきたいと思います。
今回は、この論文で提唱されているモデル(LLaDa)を見ていきます。
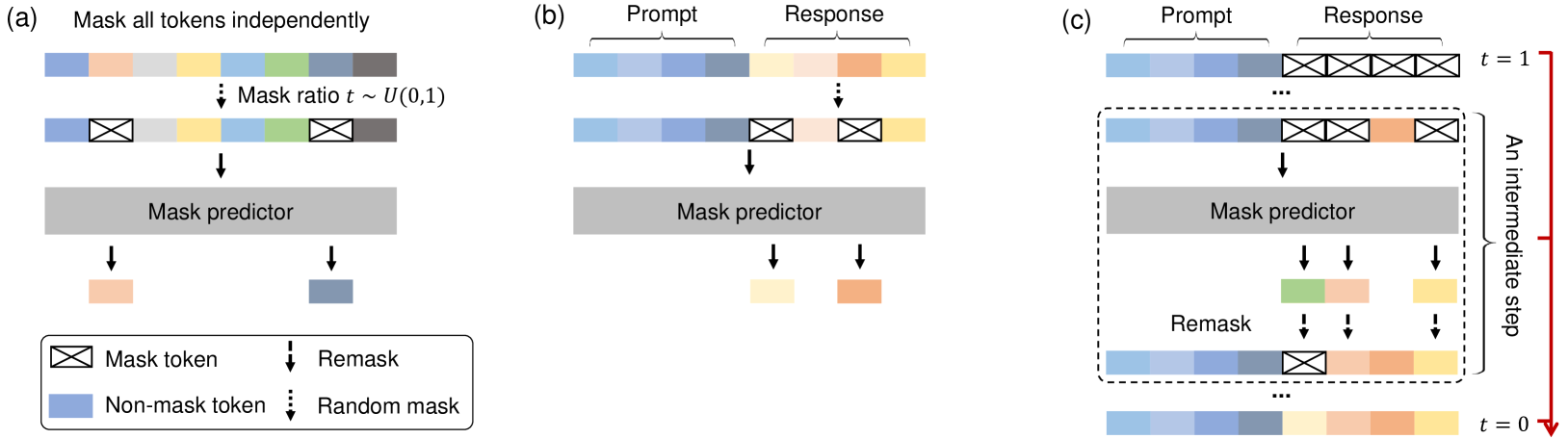
LLMの学習には、大別して事前学習と事後学習があるという話を、一般的LLMのパートでしましたが、今回はそれにのっとった形式となっています。
まず一番左が、大量に用意した文章データを用いた事前学習のフェイズです。ここでは、文章の一部をmaskしてモデルに流し、そのmaskを予測させる、という形で学習を行っています。この形式であっても、正解データを別で用意する必要がないので、一般的LLM同様に学習させやすいです。
真ん中が、事後学習になります。この図では、入力と好ましい出力をセットで与え、出力の部分の一部のみをmaskし、maskを予測させることで、入力に対して好ましい出力を学習させています。
一番みgが、実際の生成過程です。これまで、maskを外す形で学習させてきたことから、ユーザーの入力に対してmaskトークン列をつなげてモデルに入力し、そのmaskを外させる形で文章生成を行っています。
まとめ
以上の点から、一般的LLMの課題を解決できるものとして、拡散言語モデルが注目されていると考えられます。
ここから、実際にコードを生成させて、そのコードを詳しく見ていきます。
実際にコードを見る
今回は、主に二つのコードを見ていきます。
一つは、下記のサイトから見ることのできる、単純なGPTのコードです。
もう一つは、先ほどの単純なGPTのコードを、claude4 sonnetに投げて、無理やり拡散型言語モデルに直させたものです。(コード動作確認済み)
一般的LLM(GPT)のコードを見る
コードを見ます。
初期設定
# 必要ライブラリのinstall
import torch
import torch.nn as nn
from torch.nn import functional as F
# ハイパーパラメーター
batch_size = 64 # how many independent sequences will we process in parallel?
block_size = 256 # what is the maximum context length for predictions?
max_iters = 5000
eval_interval = 500
learning_rate = 3e-4
device = 'cuda' if torch.cuda.is_available() else 'cpu'
eval_iters = 200
n_embd = 384
n_head = 6
n_layer = 6
dropout = 0.2
# ------------
torch.manual_seed(1337)
学習用のテキストデータ変換など
# wget https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt
# 今回の学習用テキストデータ
with open('input.txt', 'r', encoding='utf-8') as f:
text = f.read()
# here are all the unique characters that occur in this text
# 今回は単純にするため、アルファベット一文字ずつを分割し、それぞれを1tokenとしている
# 通常のLLMであれば、トークンにする方法はもっと複雑だが、原理的には同じ
chars = sorted(list(set(text)))
vocab_size = len(chars)
# create a mapping from characters to integers
# ここで、アルファベット->トークンIDの変換辞書と、その逆を作成している。
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers
decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string
# Train and test splits
data = torch.tensor(encode(text), dtype=torch.long)
n = int(0.9*len(data)) # first 90% will be train, rest val
train_data = data[:n]
val_data = data[n:]
データロードとloss計算関数
# data loading
# データをバッチ単位で切り出すときに使う関数
def get_batch(split):
# generate a small batch of data of inputs x and targets y
data = train_data if split == 'train' else val_data
ix = torch.randint(len(data) - block_size, (batch_size,))
x = torch.stack([data[i:i+block_size] for i in ix])
y = torch.stack([data[i+1:i+block_size+1] for i in ix])
x, y = x.to(device), y.to(device)
return x, y
# 学習に使うlossを計算する関数
# loss:実際の正解とモデルの出力の違いを定量化したもの
@torch.no_grad()
def estimate_loss():
out = {}
model.eval()
for split in ['train', 'val']:
losses = torch.zeros(eval_iters)
for k in range(eval_iters):
X, Y = get_batch(split)
logits, loss = model(X, Y)
losses[k] = loss.item()
out[split] = losses.mean()
model.train()
return out
モデルのパーツ設計部分
# モデルパーツ設計
# attentionの一つのhead部分定義
class Head(nn.Module):
""" one head of self-attention """
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(n_embd, head_size, bias=False)
self.query = nn.Linear(n_embd, head_size, bias=False)
self.value = nn.Linear(n_embd, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# input of size (batch, time-step, channels)
# output of size (batch, time-step, head size)
B,T,C = x.shape
k = self.key(x) # (B,T,hs)
q = self.query(x) # (B,T,hs)
# compute attention scores ("affinities")
wei = q @ k.transpose(-2,-1) * k.shape[-1]**-0.5 # (B, T, hs) @ (B, hs, T) -> (B, T, T)
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)
wei = F.softmax(wei, dim=-1) # (B, T, T)
wei = self.dropout(wei)
# perform the weighted aggregation of the values
v = self.value(x) # (B,T,hs)
out = wei @ v # (B, T, T) @ (B, T, hs) -> (B, T, hs)
return out
# multihead attention部分
# headを複数束ねることで、表現力を向上させている
class MultiHeadAttention(nn.Module):
""" multiple heads of self-attention in parallel """
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
self.proj = nn.Linear(head_size * num_heads, n_embd)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1)
out = self.dropout(self.proj(out))
return out
# 全結合層部分
class FeedFoward(nn.Module):
""" a simple linear layer followed by a non-linearity """
def __init__(self, n_embd):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embd, 4 * n_embd),
nn.ReLU(),
nn.Linear(4 * n_embd, n_embd),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
# attention層と全結合層をつなげた一つのブロック部分の設定
class Block(nn.Module):
""" Transformer block: communication followed by computation """
def __init__(self, n_embd, n_head):
# n_embd: embedding dimension, n_head: the number of heads we'd like
super().__init__()
head_size = n_embd // n_head
self.sa = MultiHeadAttention(n_head, head_size)
self.ffwd = FeedFoward(n_embd)
self.ln1 = nn.LayerNorm(n_embd)
self.ln2 = nn.LayerNorm(n_embd)
def forward(self, x):
x = x + self.sa(self.ln1(x))
x = x + self.ffwd(self.ln2(x))
return x
モデル全体部分設定
class GPTLanguageModel(nn.Module):
def __init__(self):
super().__init__()
# each token directly reads off the logits for the next token from a lookup table
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
self.position_embedding_table = nn.Embedding(block_size, n_embd)
self.blocks = nn.Sequential(*[Block(n_embd, n_head=n_head) for _ in range(n_layer)])
self.ln_f = nn.LayerNorm(n_embd) # final layer norm
self.lm_head = nn.Linear(n_embd, vocab_size)
# better init, not covered in the original GPT video, but important, will cover in followup video
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
def forward(self, idx, targets=None):
B, T = idx.shape
# idx and targets are both (B,T) tensor of integers
# まず、トークン列をembedding(埋め込みベクトル)に加工
tok_emb = self.token_embedding_table(idx) # (B,T,C)
# 位置情報を追加
pos_emb = self.position_embedding_table(torch.arange(T, device=device)) # (T,C)
x = tok_emb + pos_emb # (B,T,C)
# 実際にモデルに流す
x = self.blocks(x) # (B,T,C)
x = self.ln_f(x) # (B,T,C)
logits = self.lm_head(x) # (B,T,vocab_size)
if targets is None:
loss = None
else: # targetがある、つまり正解データがある学習フェーズでの処理
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
def generate(self, idx, max_new_tokens):
# idx is (B, T) array of indices in the current context
for _ in range(max_new_tokens):
# crop idx to the last block_size tokens
idx_cond = idx[:, -block_size:]
# get the predictions
logits, loss = self(idx_cond)
# focus only on the last time step
logits = logits[:, -1, :] # becomes (B, C)
# apply softmax to get probabilities
probs = F.softmax(logits, dim=-1) # (B, C)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)
return idx
実際の学習フェーズ
# modelを設定し、GPUに流す
model = GPTLanguageModel()
m = model.to(device)
# print the number of parameters in the model
# モデルのパラメーター数の出力
print(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')
# create a PyTorch optimizer
# optimizer(計算したlossをもとにどれくらいパラメーターを変更するか?を決めるもの)をセット
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
# 実際の学習フェーズ
for iter in range(max_iters):
# every once in a while evaluate the loss on train and val sets
if iter % eval_interval == 0 or iter == max_iters - 1:
losses = estimate_loss()
print(f"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")
# sample a batch of data
xb, yb = get_batch('train')
# evaluate the loss
# モデル出力と正解との差を計算
logits, loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True) # optimizerの初期化
loss.backward()
optimizer.step()
文字列生成
# generate from the model
# 実際に文字列を生成させる
# 今回は、トークンIDの0を入れて生成させている。
context = torch.zeros((1, 1), dtype=torch.long, device=device)
print(decode(m.generate(context, max_new_tokens=500)[0].tolist()))
#open('more.txt', 'w').write(decode(m.generate(context, max_new_tokens=10000)[0].tolist()))
以上のような流れになっていました。
追ってみると案外そこまで複雑ではなかったりしますが、まあめんどくさいです。
パーツそれぞれで実際のモデルとの差異はありますが、原理的には同じなので、一度見ておくといいかもです。
拡散言語型モデルコード(made by Claude4 Sonnet)を見る
今度は、拡散言語型モデルのコードを見ます。
先ほどのコードとの大きな違いとしては、maskトークンに関連した処理が追加されているという点です。
実際のchatlog
初期設定
import torch
import torch.nn as nn
from torch.nn import functional as F
import random
# hyperparameters
batch_size = 32 # 拡散モデルは計算が重いのでバッチサイズを小さく
block_size = 256
max_iters = 5000
eval_interval = 500
learning_rate = 1e-4 # 拡散モデルには小さめの学習率
device = 'cuda' if torch.cuda.is_available() else 'cpu'
eval_iters = 200
n_embd = 384
n_head = 6
n_layer = 6
dropout = 0.2
mask_prob = 0.15 # BERTライクなマスク確率
diffusion_steps = 5 # 拡散ステップ数
# ------------
torch.manual_seed(1337)
学習用のテキストデータ変換など
# データの読み込み(元のコードと同じ)
with open('input.txt', 'r', encoding='utf-8') as f:
text = f.read()
chars = sorted(list(set(text)))
vocab_size = len(chars)
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
encode = lambda s: [stoi[c] for c in s]
decode = lambda l: ''.join([itos[i] for i in l])
# 特殊トークンの定義
MASK_TOKEN = vocab_size # マスクトークン
vocab_size += 1 # 語彙サイズを1増加
data = torch.tensor(encode(text), dtype=torch.long)
n = int(0.9*len(data))
train_data = data[:n]
val_data = data[n:]
mask関連処理、データロードとloss計算関数
# 注意
# オリジナルの論文とは処理を変更している(というか直す余力がなかった)
# 本来なら、全体をランダムにマスクしたのち、モデルに流して、その結果からmaskトークンを予測されたトークンで置き換える
# 次のステップでは、置き換えた場所で、信頼性の低い場所を再度maskしてモデルに流す
# なので、初期のmaskトークンの位置を把握する必要がある
# 今回はそういうことをせず、ステップに応じたマスク確率から、全トークンの中からランダムでmaskしている
def random_mask_tokens(tokens, mask_prob=0.15):
"""
トークン列をランダムでマスク化する関数
Args:
tokens: 入力トークン列 (B, T)
mask_prob: マスク確率
Returns:
masked_tokens: マスクされたトークン列
mask_positions: マスクされた位置のマスク
"""
B, T = tokens.shape
mask_positions = torch.rand(B, T) < mask_prob
masked_tokens = tokens.clone()
masked_tokens[mask_positions] = MASK_TOKEN
return masked_tokens, mask_positions
def progressive_unmask(original_tokens, current_step, total_steps):
"""
段階的にマスクを解除する関数(拡散プロセス)
"""
B, T = original_tokens.shape
# 現在のステップに基づいてマスク確率を決定
current_mask_prob = mask_prob * (total_steps - current_step) / total_steps
mask_positions = torch.rand(B, T) < current_mask_prob
masked_tokens = original_tokens.clone()
masked_tokens[mask_positions] = MASK_TOKEN
return masked_tokens, mask_positions
def get_batch(split):
"""拡散モデル用のバッチ取得関数"""
data = train_data if split == 'train' else val_data
ix = torch.randint(len(data) - block_size, (batch_size,))
x = torch.stack([data[i:i+block_size] for i in ix])
x = x.to(device)
return x
@torch.no_grad()
def estimate_loss():
out = {}
model.eval()
for split in ['train', 'val']:
losses = torch.zeros(eval_iters)
for k in range(eval_iters):
X = get_batch(split)
loss = compute_diffusion_loss(X)
losses[k] = loss.item()
out[split] = losses.mean()
model.train()
return out
モデルのパーツ設計部分
class Head(nn.Module):
"""BERT型のアテンションヘッド(双方向)"""
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(n_embd, head_size, bias=False)
self.query = nn.Linear(n_embd, head_size, bias=False)
self.value = nn.Linear(n_embd, head_size, bias=False)
# GPTと違い、因果マスクは使わない(双方向アテンション)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
B, T, C = x.shape
k = self.key(x) # (B,T,hs)
q = self.query(x) # (B,T,hs)
# 双方向アテンション(因果マスクなし)
wei = q @ k.transpose(-2,-1) * k.shape[-1]**-0.5 # (B, T, T)
wei = F.softmax(wei, dim=-1) # (B, T, T)
wei = self.dropout(wei)
v = self.value(x) # (B,T,hs)
out = wei @ v # (B, T, T) @ (B, T, hs) -> (B, T, hs)
return out
class MultiHeadAttention(nn.Module):
"""マルチヘッドアテンション"""
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
self.proj = nn.Linear(head_size * num_heads, n_embd)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1)
out = self.dropout(self.proj(out))
return out
class FeedForward(nn.Module):
"""フィードフォワードネットワーク"""
def __init__(self, n_embd):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embd, 4 * n_embd),
nn.GELU(), # BERTではGELUを使用
nn.Linear(4 * n_embd, n_embd),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
class Block(nn.Module):
"""Transformerブロック(BERT型)"""
def __init__(self, n_embd, n_head):
super().__init__()
head_size = n_embd // n_head
self.sa = MultiHeadAttention(n_head, head_size)
self.ffwd = FeedForward(n_embd)
self.ln1 = nn.LayerNorm(n_embd)
self.ln2 = nn.LayerNorm(n_embd)
def forward(self, x):
x = x + self.sa(self.ln1(x))
x = x + self.ffwd(self.ln2(x))
return x
モデル全体部分設定
class DiffusionLanguageModel(nn.Module):
"""拡散言語モデル(BERT型エンコーダー)"""
def __init__(self):
super().__init__()
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
self.position_embedding_table = nn.Embedding(block_size, n_embd)
self.blocks = nn.Sequential(*[Block(n_embd, n_head=n_head) for _ in range(n_layer)])
self.ln_f = nn.LayerNorm(n_embd)
self.lm_head = nn.Linear(n_embd, vocab_size - 1) # MASKトークンは予測対象外
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
def forward(self, idx):
B, T = idx.shape
# 埋め込み
tok_emb = self.token_embedding_table(idx) # (B,T,C)
pos_emb = self.position_embedding_table(torch.arange(T, device=device)) # (T,C)
x = tok_emb + pos_emb # (B,T,C)
# Transformerブロック
x = self.blocks(x) # (B,T,C)
x = self.ln_f(x) # (B,T,C)
logits = self.lm_head(x) # (B,T,vocab_size-1)
return logits
def diffusion_generate(self, length=100, steps=None):
"""拡散プロセスによる生成"""
if steps is None:
steps = diffusion_steps
# 完全にマスクされたシーケンスから開始
sequence = torch.full((1, length), MASK_TOKEN, device=device)
for step in range(steps):
# 現在のシーケンスを予測
logits = self.forward(sequence) # (1, length, vocab_size-1)
# マスクされた位置のみを更新
mask_positions = (sequence == MASK_TOKEN)
if mask_positions.sum() == 0:
break
# 段階的にマスクを解除
unmask_prob = (step + 1) / steps
random_unmask = torch.rand_like(mask_positions.float()) < unmask_prob
positions_to_update = mask_positions & random_unmask
if positions_to_update.sum() > 0:
# 予測されたトークンでマスクを置換
probs = F.softmax(logits, dim=-1)
predicted_tokens = torch.multinomial(probs.view(-1, vocab_size-1), 1).view(1, length)
sequence[positions_to_update] = predicted_tokens[positions_to_update]
return sequence
拡散フェイズでのloss計算
def compute_diffusion_loss(original_tokens):
"""拡散プロセスの損失を計算"""
total_loss = 0.0
for step in range(diffusion_steps):
# 段階的マスク
masked_tokens, mask_positions = progressive_unmask(original_tokens, step, diffusion_steps)
# 予測
logits = model(masked_tokens) # (B, T, vocab_size-1)
# マスクされた位置での損失のみ計算
if mask_positions.sum() > 0:
B, T, C = logits.shape
masked_logits = logits[mask_positions] # (num_masked, vocab_size-1)
masked_targets = original_tokens[mask_positions] # (num_masked,)
# MASKトークンを予測対象から除外するため、ターゲットが範囲外でないかチェック
valid_targets = masked_targets < (vocab_size - 1)
if valid_targets.sum() > 0:
loss = F.cross_entropy(masked_logits[valid_targets], masked_targets[valid_targets])
total_loss += loss
return total_loss / diffusion_steps
実際の学習フェーズ
# モデルの初期化
model = DiffusionLanguageModel()
m = model.to(device)
print(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')
# オプティマイザー
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
# 学習ループ
for iter in range(max_iters):
if iter % eval_interval == 0 or iter == max_iters - 1:
losses = estimate_loss()
print(f"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")
# バッチの取得
xb = get_batch('train')
# 拡散損失の計算
loss = compute_diffusion_loss(xb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
文字列生成
print("\n=== 拡散生成のテスト ===")
with torch.no_grad():
generated = m.diffusion_generate(length=200, steps=10)
# MASKトークンを除去してデコード
generated_clean = generated[0][generated[0] != MASK_TOKEN]
if len(generated_clean) > 0:
result = decode(generated_clean.tolist())
print("Generated text:")
print(result)
else:
print("生成に失敗しました(すべてマスクトークンです)")
> === 拡散生成のテスト ===
> Generated text:
> ftresaimst lase noTaveid,
> And eingett tliloandslaove uf,y
> alou aeved wid verose yhose oarde seet, hhougot ovith glolibleeds dhy verit
> usre das der uunwokes ofok my shuour so, if I lin.
> Annd y er unthe
with torch.no_grad():
generated = m.diffusion_generate(length=200, steps=100)
# MASKトークンを除去してデコード
generated_clean = generated[0][generated[0] != MASK_TOKEN]
if len(generated_clean) > 0:
result = decode(generated_clean.tolist())
print("Generated text:")
print(result)
else:
print("生成に失敗しました(すべてマスクトークンです)")
> Generated text:
> at I.
> Rameason toorm or ime.
> On it etsyecs: hf whips o
> And knouchent scoing-giut own rimphe fig wa ol hearyooursiveg mandish tus insuree; re blegrabuck nand tlacv knohand, bon tnlet, a to, iogause thy
これらのコードによって、実際に、モデルを走らせて文章を生成させることが出来ました。(文章と呼べるものではないが、Andとかifとかそれっぽい単語くらいなら出る)
最終的に使ってたGPUメモリは10GBくらいで、処理時間はRTX3060(in linux)で80分くらいでした。重め。
一番見たい!生成速度そんなにちゃうんすか!
見たいのはたった一つ
生成速度どんくらい変わってくるのか?です!
## 設定環境
このテストに関しては、macpro(M4)で、メモリ32GBのノートPCを使っています。
環境は、コンテナ内部で実行しています。
モデルのパラメーター数は、GPT、拡散モデルともに10.78M パラメータとなっています。
それぞれの条件で、10回生成を回して、その平均値を求めています。
モデルは学習を一切していないものを利用しています。
生成時間比較用コード
GPTの方
import time
glandstart = time.time()
for _ in range(10):
start = time.time()
context = torch.zeros((1, 1), dtype=torch.long, device=device)
generates = m.generate(context, max_new_tokens=200)[0].tolist()
print(len(generates))
print(decode(generates))
end = time.time()
print(end-start)
glandend = time.time()
all_time = glandend-glandstart
print(f"10回の生成時間平均:{all_time/10}")
拡散モデルの方
# 生成のテスト
import time
for step in [10,20,30,40,50,60,70,80,90,100]:
# 100回ごとは以下のコードを利用
# for step in [100,200,300,400,500]:
# もっと回数増やす場合は以下
# for step in [500, 750, 1000,1500, 2000]:
start = time.time()
for _ in range(10):
print("\n=== 拡散生成のテスト ===")
with torch.no_grad():
generated = model.diffusion_generate(length=200, steps=step)
# MASKトークンを除去してデコード
generated_clean = generated[0][generated[0] != MASK_TOKEN]
if len(generated_clean) > 0:
print(f"生成トークン数:{len(generated_clean)}")
result = decode(generated_clean.tolist())
print("Generated text:")
print(result)
else:
print("生成に失敗しました(すべてマスクトークンです)")
end = time.time()
print(f"step数:{step}、10回の平均時間:{(end-start)/10}")
結果
| モデル | 生成トークン数 | step数(拡散モデルのみ) | 10回の平均生成時間(s) |
|---|---|---|---|
| simpleGPT | 201 | なし | 11.3 |
| dLLM | 200 | 10 | 0.82 |
| dLLM | 200 | 20 | 1.34 |
| dLLM | 200 | 30 | 1.66 |
| dLLM | 200 | 40 | 2.00 |
| dLLM | 200 | 50 | 2.04 |
| dLLM | 200 | 60 | 2.24 |
| dLLM | 200 | 70 | 2.37 |
| dLLM | 200 | 80 | 2.61 |
| dLLM | 200 | 90 | 2.90 |
| dLLM | 200 | 100 | 3.03 |
| dLLM | 200 | 200 | 4.19 |
| dLLM | 200 | 300 | 5.13 |
| dLLM | 200 | 400 | 5.91 |
| dLLM | 200 | 500 | 6.61 |
| dLLM | 200 | 750 | 8.84 |
| dLLM | 200 | 1000 | 9.35 |
| dLLM | 200 | 1500 | 11.1 |
| dLLM | 200 | 2000 | 13.9 |
と言うことで、かなり早いという結果になりました。
(てか生成が早すぎる)
今回のモデルでは、stepごとに全文からランダムにmaskするようにしているために、ステップ数が2000など異常に増えてもOKになっています。(この辺りはだいぶ実装が雑です。)
感想としては、生成速度という面では非常に強いので、今後の精度面での改善が楽しみです。
まとめ
今回の記事では、一般的LLMと拡散型言語モデルの説明をし、そこにさらに実際のコード解説を挟むという、盛沢山の内容でお送りしました。
予防線貼りまくりですが、今回の記事は完全勢いで執筆されています。なので、かなり隙だらけとは思いますが、そこはご容赦いただけたらと思います。
最後になりますが、この記事を読んで、拡散型言語モデルに興味を持ってくれた方がいたら非常にうれしいなと思います。
(がちぷろの方はぜひとももっとコードリファクタリングしていただけたら・・・・)