この記事はUMITRON Advent Calendar 2024 13日目の記事です
まえがき
この記事は、Amazon SageMaker Examplesを読んでみた 〜End To End ML Lifecycle & Prepare Data編〜の続きです。
この記事がどのようなものかについては、そちらをご参照ください。
先日はDeploy and Monitorについてまとめました。
当初、本日はBuild and Train Modelsについてのみまとめる予定でしたが、後述する理由により紹介するサンプルが少なくなってしまったので、MLOpsについてもまとめます。
Build and Train Models
様々なモデルの学習方法が記載されたサンプル群
個々の組み込みアルゴリズムやフレームワークのコンテナの使い方に関するサンプルが多く、基本的な部分はこれまでのものと重複するので、学習過程の可視化と自作アルゴリズムコンテナの作成方法に関するサンプルのみについて記す
Visualize Training Jobs and Performance of Your Model Using TensorBoard on SageMaker
概要
- TensorBoard on Amazon SageMakerを使って学習ログを可視化する
- PyTorchで分類器を学習し、その学習過程を可視化する
主要なAPI呼び出し
| カテゴリ | メソッド | 説明 |
|---|---|---|
| 学習と推論 | sagemaker.pytorch.PyTorch.fit | PyTorchのコンテナを使って推論用モデルを学習。ノートブックでは引数tensorboard_output_configを設定することで、学習ログをリアルタイムでS3にアップロードするようにしている |
| 監視とトラッキング | .sagemaker.interactive_apps.tensorboard.TensorBoardApp.get_app_url | TensorBoradアプリケーションへのURLを生成する。SageMaker Studioで実行している場合はURLが生成され、それ以外の場合はSageMakerコンソールへのURLが生成される |
所感
- サポートされいるフレームワークは、TensorFlow、PyTorch、Hugging Face Transformersで、最近使われているものはカバーされている
- Cloud watchを使って学習過程を可視化するよりも簡単にできるかもしれないと感じた
- 自作コンテナで学習する場合も、sagemaker.estimator.Estimatorの初期化時にtensorboard_output_configが設定できるので、torch.utils.tensorboardでログを適切なディレクトリに出力すればできそうだがサンプルは見つからなかった
Building your own container as Algorithm / Model Package
概要
- SageMakerに独自アルゴリズムを実装する
- 独自アルゴリズムを動作させるdocker imageをECRに登録
- ローカル or ノートブック上で上記の動作を確認する
- トレーニングジョブを実行し、バッチ変換でテスト
- 推論用エンドポイントをデプロイ
- 独自アルゴリズムをパッケージ化して登録する
- 登録したアルゴリズムをファインチューニングして推論用エンドポイントをデプロイ
- AWSマーケットプレイスに出品する
主要なAPI呼び出し
| カテゴリ | メソッド | 説明 |
|---|---|---|
| データ準備 | sagemaker.session.Session.upload_data | S3にデータをアップロードする。boto3でアップロードする場合と異なり、指定が無い場合デフォルトのバケットが選択される(無ければ作成される)。また、戻り値がS3 URIになっており、そのまま他のsagemaker関連の設定に使える。 |
| 学習と推論 | sagemaker.estimator.Estimator.fit | トレーニングジョブを実行。インフラ周りの設定はEstimatorインスタンス作成時に行う |
| 学習と推論 | sagemaker.estimator.Estimator.transformer.transform | バッチ変換ジョブを実行 |
| インフラ管理 | sagemaker.estimator.Estimator.create_model | 推論用のモデルを作成 |
| インフラ管理 | sagemaker.estimator.Estimator.deploy | 推論用エンドポイントを作成。 |
| ノートブックではインスタンスタイプを指定することでリアルタイム推論でデプロイしている。 | ||
| 学習と推論 | sagemaker.predictor.Predictor.predict | エンドポイントに推論をリクエスト |
| 学習と推論 | SageMaker.Client.create_algorithm | アルゴリズムを登録。学習アルゴリズムと関連コンテナイメージが含まれる。TrainingSpecificationとInferenceSpecificationにAdditionalS3DataSourceを設定することで、学習の際の初期重みを登録できる(つまり、ファインチューニングできるようになる) |
| 学習と推論 | SageMaker.Client.create_model_package | モデルパッケージを登録。推論モデルと関連コンテナイメージ、モデルデータが含まれる(create_modelで作成されるデプロイ用のモデルとは別物) |
| 学習と推論 | SageMaker.Client.create_training_job | トレーニングジョブを作成 |
| 学習と推論 | SageMaker.Client.create_model | 推論用モデルを作成。ノートブックではモデルパッケージから作成している |
| インフラ管理 | SageMaker.Client.create_endpoint_config | 推論用のエンドポイント設定を作成 |
| インフラ管理 | SageMaker.Client.create_endpoint | 推論用のエンドポイントを作成 |
| 学習と推論 | SageMaker.Client.invoke_endpoint | エンドポイントに推論をリクエスト |
所感
- 独自アルゴリズムを実装する場合、大枠はこのノートブックのコピペでよさそう(マーケットプレイスへの出品は除く)
- アルゴリズムのパッケージ化をする場合は、ファインチューニングとモデルの登録部分は別ファイルにしても良さそう
- パッケージ化の必要性については、後に紹介するMLOpsのサンプルでは基本的にパッケージ化していることから、パッケージ化するのがデファクトなのかもしれない
- パッケージ化することで、再現性が担保されやすくなったり、CI/CDパイプラインとの統合が容易になるメリットが大きいのかもしれない
- ローカルでテストをする場合、アーキテクチャの違いで環境構築に苦労することがあるので、SageMaker Notebookの方がスムーズに開発ができそう
- ローカルでのテストを諦めると、テストのためにトレーニングジョブの実行やエンドポイント作成を毎回する必要があるのでテストに時間がかかる
- ノートブックインスタンスの使用料金が別途発生する点に注意
- sagemaker.session.Session.upload_dataで作成されるデフォルトバケットは(
sagemaker-<region>-<account_id>)になるので、アルゴリズム毎にバケットを分ける等、整理したい場合は指定したほうが良さそう- Sessionのインスタンスを作成する際にdefault_bucket引数に指定するのが良さそう
MLOps
MLモデルのためのCI/CDに関する機能のサンプル群
Infrastructure-as-codeを実現するためのSageMaker Pipelinesや、MLflowとの連携によるモデル管理に関するサンプルがある
MLflowはそれをサービングするリソースが別途必要になることから、小規模プロジェクトには不向きと考え省略し、SageMaker Pipelinesの中でも基本的なもののみについて記す
また、1サンプルだけあったLinage Trackingについても記す
Model Lineage Tracking
概要
- Model linageデータをグラフにして可視化する
- Model linageデータ:データセット、トレーニングジョブ、デプロイ等、機械学習モデルの生成や運用に関わるプロセスを追跡・記録し、依存関係や履歴を明確にするための情報
- データは以下4つのカテゴリで構成されている
- Artifacts:: データ、モデル、メトリクス、ログ等の結果物や中間生成物
- Trial components:データ準備、モデル学習、評価など、トレーニングの各ステージを構成する要素
- Actions:各操作の実行履歴(例:ジョブ実行、モデルデプロイ、エンドポイント更新)
- Contexts:特定のエンティティ(例:エンドポイント、モデルパッケージ)や論理的プロセス(例:モデル学習、評価)をグループ化したもの
- データは以下4つのカテゴリで構成されている
- Model linageデータ:データセット、トレーニングジョブ、デプロイ等、機械学習モデルの生成や運用に関わるプロセスを追跡・記録し、依存関係や履歴を明確にするための情報
- グラフの可視化はNeptune MLで行う
主要なAPI呼び出し
| カテゴリ | メソッド | 説明 |
|---|---|---|
| 監視とトラッキング | sagemaker.lineage.artifact.Artifact.list | Artifactsの一覧を取得 |
| 監視とトラッキング | sagemaker.lineage.trial_component.TrialComponent.list | Trial componentsの一覧を取得 |
| 監視とトラッキング | sagemaker.lineage.action.Action.list | Actionsの一覧を取得 |
| 監視とトラッキング | sagemaker.lineage.context.Context.list | Contextsの一覧を取得 |
| 監視とトラッキング | sagemaker.lineage.association.Association.list | 上記4つの構成要素間のエッジを取得 |
所感
- これらの関連性はWebコンソールからも確認できるものが多い気がするが、一望するのは難しいため、モデル開発の全体像を視覚的に表現するには良い機能かもしれない
Orchestrate Jobs to Train and Evaluate Models with Amazon SageMaker Pipelines
概要
- SageMaker Pipelinesでデータ準備からエンドポイントのデプロイまでの一連の流れを定義する
-
処理の流れは以下の画像の通り (ノートブックより引用)
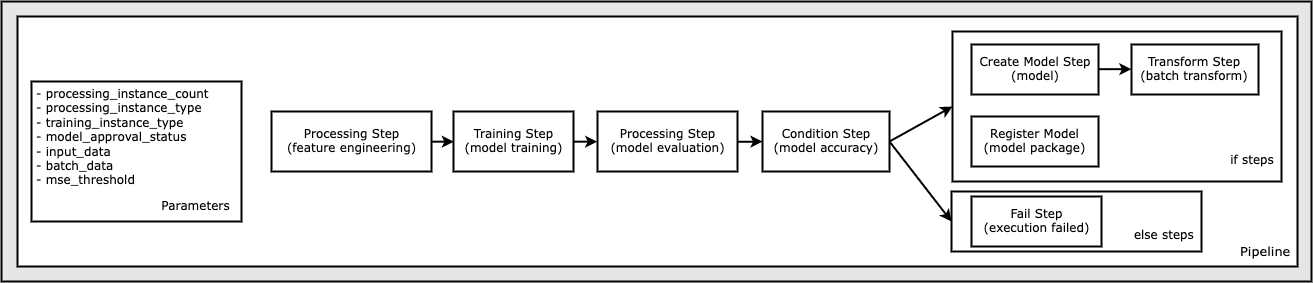
-
SageMaker Pipelinesを使うことで、各ステップの依存関係を明示的に定義できる
-
- UCI Machine Learning Abalone Dataset でアワビの年齢推定器をXGBoostで学習し、バッチ変換としてデプロイ
- 類似例 SageMaker Pipelines:California Housing datasetで住宅価格予測器をニューラルネットで学習し、バッチ変換としてデプロイ
主要なAPI呼び出し
| カテゴリ | メソッド | 説明 |
|---|---|---|
| パイプライン構築 | sagemaker.sklearn.processing.SKLearnProcessor.run | scikit-learn用のコンテナでSageMaker processing jobを実行。ノートブックでは、SKLearnProcessorインスタンス作成時にsagemaker.workflow.pipeline_context.PipelineSessionを渡すことで、この関数呼び出し時に処理は実行されず、ジョブに渡される引数を定義し、それをもとにsagemaker.workflow.steps.ProcessingStepを作成することでステップを定義している |
| パイプライン構築 | sagemaker.estimator.Estimator.fit | トレーニングジョブを実行。ノートブックでは、上記同様、Estimatorインスタンス作成時にPipelineSessionを渡すことで引数を定義し、それをもとにステップを定義している |
| パイプライン構築 | sagemaker.processing.ScriptProcessor.run | 処理ジョブを実行。ノートブックでは、上記同様、ScriptProcessorインスタンス作成時にPipelineSessionを渡すことで引数を定義し、それをもとにステップを定義している |
| パイプライン構築 | sagemaker.model.Model.deploy | 推論用モデルをデプロイ。ノートブックでは、上記同様、Modelインスタンス作成時にPipelineSessionを渡すことで引数を定義し、それをもとにステップを定義している |
| パイプライン構築 | sagemaker.workflow.pipeline.Pipeline.upsert | パイプラインの作成。インスタンス作成時に、各ステップの定義と依存関係を登録している |
| パイプライン構築 | sagemaker.workflow.pipeline.Pipeline.start | パイプラインの実行 |
| パイプライン構築 | sagemaker.workflow.pipeline._PipelineExecution.describe | パイプラインの状態確認。_PipelineExecutionインスタンスは上記upsert関数の戻り値として取得する |
| パイプライン構築 | sagemaker.workflow.pipeline._PipelineExecution.wait | パイプラインの完了を待つ |
| パイプライン構築 | sagemaker.workflow.pipeline._PipelineExecution.list_steps | パイプラインの各ステップの進行状況や結果を確認 |
所感
- 処理フローをパイプラインとして定義することで、ワークフロー全体をコード化して管理することが徹底されるのもメリットだと感じた
- 手動プロセスとの混合が避けられ、手順全体をバージョン管理できる
- デプロイステップをLambdaで実行する例がSageMaker Pipelines Lambda Stepにあるが、Lambdaにするメリットはこの例のみからでは理解できなかったが、以下のようなときはLambdaを使う必要があるかもしれない
- 他のAWSサービスでPipeline外からもデプロイをトリガーする必要があるとき
- AWS外のリソースに変更を加える必要があるとき
Basic Pipeline for Batch Inference using Low-code Experience for SageMaker Pipelines
概要
- SageMaker Pipelinesの
@stepデコレータを使ってモデル構築のパイプラインを構築-
@stepデコレータ:SageMaker Pipelines内でステップを定義。Python関数をステップとして登録できる- ノートブックでは、以下3つのパラメータを設定している
- name:ステップの名前
- instance_type:使用するインスタンスタイプ
- keep_alive_period_in_seconds:次のステップで利用されるまでインスタンスを生存させる秒数(これにより、以降のステップでインスタンスの起動を省略できる)
- これにより、より簡素にパイプラインを構築できる
- ノートブックでは、以下3つのパラメータを設定している
-
- 乳がんの診断データから良性か悪性かを予測分類器をXGBoostで学習し、バッチ変換としてデプロイ
主要なAPI呼び出し
| カテゴリ | メソッド | 説明 |
|---|---|---|
| インフラ管理 | sagemaker.serve.builder.model_builder.ModelBuilder.build().register | モデルパッケージの作成と登録 |
| インフラ管理 | SageMaker.Client.describe_model_package | モデルパッケージの情報を取得。ノートブックではモデルアーティファクトのS3URIを取得している |
| パイプライン構築 | sagemaker.workflow.pipeline.Pipeline.upsert | パイプラインの作成。インスタンス作成時に、@stepデコレータを付与して定義した関数とその依存関係を登録する |
| パイプライン構築 | sagemaker.workflow.pipeline.Pipeline.start | パイプラインの実行 |
| パイプライン構築 | sagemaker.workflow.pipeline._PipelineExecution.describe | パイプラインの状態確認。_PipelineExecutionインスタンスは上記upsert関数の戻り値として取得する |
| パイプライン構築 | sagemaker.workflow.pipeline._PipelineExecution.wait | パイプラインの完了を待つ |
| パイプライン構築 | sagemaker.workflow.pipeline._PipelineExecution.list_steps | パイプラインの各ステップの進行状況や結果を確認 |
所感
- デコレータを使うことで、各処理ステップを独立した関数として記述することが強制されるので、再利用性が高まるだけでなくコードの保守性も上がるように感じた
- 個人的には、
@stepデコレータを使った例の方が各ステップの入出力の関係を追いやすかった
- 個人的には、
-
開発ガイドに記されているように、可能ならローカル(ノートブックインスタンス上)でテストし、次に
@remoteデコレータでリモート環境でユニットテスト、@stepデコレータでパイプラインに組み込むという手順を踏めばスムーズに開発を進められそう
Use SageMaker Pipelines With Step Caching
概要
- SageMaker Pipelinesのキャッシュを有効にする方法とそのテスト
- キャッシュを有効にすると各ステップの引数が追跡され、引数が一致する場合はキャッシュを使用する様になる。ただし、処理結果に影響の無い引数は追跡されない
- サンプルでは、インスタンスタイプを変更するとキャッシュされた結果が使われるが、前処理のスクリプトが変更されるとキャッシュが使われないことを試している
- キャッシュの動作確認が目的のため、前処理ステップとトレーニングステップのみのパイプラインを定義している
主要なAPI呼び出し
| カテゴリ | メソッド | 説明 |
|---|---|---|
| パイプライン構築 | sagemaker.sklearn.processing.SKLearnProcessor.run | scikit-learn用のコンテナでSageMaker processing jobを実行。ノートブックでは、SKLearnProcessorインスタンス作成時にsagemaker.workflow.pipeline_context.PipelineSessionを渡すことで、この関数呼び出し時に処理は実行されず、ジョブに渡される引数を定義し、それをもとにsagemaker.workflow.steps.ProcessingStepを作成することでステップを定義している |
| パイプライン構築 | sagemaker.estimator.Estimator.fit | トレーニングジョブを実行。ノートブックでは、上記同様、Estimatorインスタンス作成時にPipelineSessionを渡すことで引数を定義し、それをもとにステップを定義している |
| パイプライン構築 | sagemaker.workflow.pipeline.Pipeline.upsert | パイプラインの作成。インスタンス作成時に、各ステップの定義と依存関係を登録している |
| パイプライン構築 | sagemaker.workflow.pipeline.Pipeline.start | パイプラインの実行 |
| パイプライン構築 | sagemaker.workflow.pipeline._PipelineExecution.describe | パイプラインの状態確認。_PipelineExecutionインスタンスは上記upsert関数の戻り値として取得する |
| パイプライン構築 | sagemaker.workflow.pipeline._PipelineExecution.wait | パイプラインの完了を待つ |
| パイプライン構築 | sagemaker.workflow.pipeline._PipelineExecution.list_steps | パイプラインの各ステップの進行状況や結果を確認 |
| パイプライン構築 | sagemaker.workflow.pipeline.Pipeline.update | パイプラインの更新 |
SageMaker Pipeline - Local Mode
概要
- SageMaker Pipelinesの各ジョブをローカルで実行する
- SageMaker Studioではローカル実行ができない
- PipelineSessionクラスの代わりにLocalPipelineSessionを使用する
- これまでの例と異なり、FrameworkProcessorを使うことでジョブが実行されるコンテナに追加のPythonパッケージをインストールしている
主要なAPI呼び出し
| カテゴリ | メソッド | 説明 |
|---|---|---|
| パイプライン構築 | sagemaker.processing.FrameworkProcessor.get_run_args | ProcessingStepで実行するジョブの入出力を取得。ノートブックでは、引数source_dirに実行するスクリプトとrequirements.txtを圧縮したファイルのS3パスを指定している |
| パイプライン構築 | sagemaker.workflow.pipeline.Pipeline.upsert | パイプラインの作成。インスタンス作成時に、各ステップの定義と依存関係を登録している |
| パイプライン構築 | sagemaker.workflow.pipeline.Pipeline.start | パイプラインの実行 |
| パイプライン構築 | sagemaker.workflow.pipeline._PipelineExecution.describe | パイプラインの実行 |
| パイプライン構築 | sagemaker.workflow.pipeline._PipelineExecution.list_steps | パイプラインの各ステップの進行状況や結果を確認 |
所感
-
@stepデコレータを使う場合はインスタンスの指定が必須なので、単に@stepデコレータを外してローカルでテストすればよいのかもしれない(LocalPipelineSessionもあくまでクラウドで実行する前のテストという立ち位置)- この方法ならSageMaker Studioでも実行できるので、テストのしやすさという観点でも
@stepデコレータの方が便利かもしれない
- この方法ならSageMaker Studioでも実行できるので、テストのしやすさという観点でも
ウミトロンは、「持続可能な水産養殖を地球に実装する」というミッション実現に向けて、日々プロダクト開発・展開にチーム一丸となって邁進しています。
ウミトロンのニュースや活動状況を各種SNSで配信していますので、ぜひチェックいただき、来年も応援よろしくお願いします!
Facebook https://www.facebook.com/umitronaqtech/
X https://x.com/umitron
Instagram https://www.instagram.com/umitron.aqtech/
Linkedin https://www.linkedin.com/company/umitron