この記事はUMITRON Advent Calendar 2024 5日目の記事です
まえがき
この記事は、Amazon SageMaker Examplesを読んでみた 〜End To End ML Lifecycle & Prepare Data編〜の続きです。
この記事がどのようなものかについては、そちらをご参照ください。
本日は、Deploy and Monitorについてまとめます。
Deploy and Monitor
推論用エンドポイントのデプロイやその管理方法に関するサンプル群。
さまざまデプロイ形態や、モデルの更新、精度の監視方法について記載されている。
本カテゴリにおいても、基本的かつ画像処理の関連があるサンプルのみピックアップして記載する。
概要
- 2つのモデルを一つの推論用エンドポイントとしてデプロイし、A/Bテストを実施
- まず、各モデルが1:1の比重で呼び出されるようにデプロイする
- 指定せずに推論をリクエストすると上記比重で呼び出される
- テスト用データを使い、各モデルの精度を比較する
- 精度の良いモデルのみが呼び出されるように、比重を1:3, 0:1と変化させていく
主要なAPI呼び出し
| カテゴリ |
メソッド |
説明 |
| 学習と推論 |
SageMaker.Client.create_model |
推論用のモデルを作成 |
| インフラ管理 |
sagemaker.session.production_variant |
推論用のエンドポイント構成(バリアント)を定義。ノートブックでは各モデルがリクエストされる比重をinitial_weightで設定している |
| インフラ管理 |
SageMaker.Client.endpoint_from_production_variants |
バリアントから推論用のエンドポイントを作成。エンドポイント設定も自動作成される。引数production_variantsにバリアントのリストを渡すと、複数のモデルを持つエンドポイントを作成できる |
| 学習と推論 |
SageMaker.Client.invoke_endpoint |
エンドポイントに推論をリクエスト。引数TargetVariantにバリアント名を指定すると特定のバリアントで推論させることができる。 |
| 監視とトラッキング |
CloudWatch.Client.get_metric_statistics |
指定されたメトリックの統計データを取得。ノートブックでは各バリアントのリクエスト数を取得している |
| インフラ管理 |
SageMaker.Client.describe_endpoint |
エンドポイントの状態を取得 |
| インフラ管理 |
SageMaker.Client.update_endpoint_weights_and_capacities |
各モデルがリクエストされる比重とインスタンス数を設定。ノートブックでは各モデルがリクエストされる比重のみを更新している。 |
| インフラ管理 |
SageMaker.Client.delete_endpoint |
エンドポイントを削除 |
所感
- 徐々に新しいモデルの比重を上げながらデプロイする動作を自動化するためには、後に紹介するデプロイガードレールを使えばよさそう
- 自作モデルをデプロイする際は、こういったテストがしやすいようにエンドポイントのインタフェースの設計は慎重にするべきだと感じた
概要
- 高速オートスケーリングを設定し、オートスケーリングされる様子をモニタリングする
- 通常はスケーリング要否の判断は1分毎だが、高速オートスケーリングでは10秒毎に判断される
- 上記をhuggingfaceのmeta-llama/Meta-Llama-3-8B-Instructモデルを使ってテストする
主要なAPI呼び出し
| カテゴリ |
メソッド |
説明 |
| インフラ管理 |
sagemaker.huggingface.get_huggingface_llm_image_uri |
huggingfaceのコンテナイメージのURIを取得 |
| インフラ管理 |
sagemaker.huggingface.HuggingFaceModel.deploy |
huggingfaceモデルを使って、モデルの作成、エンドポイント設定の作成、エンドポイント作成を実施。huggingfaceのモデルID等はHuggingFaceModelクラス初期化時に設定する。 |
| 学習と推論 |
sagemaker.predictor.Predictor.predict |
エンドポイントに推論をリクエスト |
| 学習と推論 |
SageMaker.Client.invoke_endpoint |
エンドポイントに推論をリクエスト。ノートブックで使用されているautoscalingモジュール内で使われている |
| インフラ管理 |
ApplicationAutoScaling.Client.register_scalable_target |
オートスケーリングにおける、インスタンス数の最小値と最大値を決める |
| インフラ管理 |
ApplicationAutoScaling.Client.put_scaling_policy |
オートスケーリングのポリシーを設定。TargetTrackingScalingPolicyConfigurationで詳細を定義している |
| インフラ管理 |
SageMaker.Client.describe_endpoint |
エンドポイントの状態を取得。ノートブックでは、現在のインスタン数を取得するため、autoscalingモジュール内で使われている |
概要
主要なAPI呼び出し
| カテゴリ |
メソッド |
説明 |
| インフラ管理 |
ApplicationAutoScaling.Client.put_scaling_policy |
オートスケーリングのポリシーを設定する。StepScalingPolicyConfigurationで詳細を定義している |
| 監視とトラッキング |
CloudWatch.Client.put_metric_alarm |
エンドポイントの状態を監視。AlarmActionsにput_scaling_policyで設定したオートスケーリング設定を指定している。(Period = 60になっているが、おそらく10の間違い) |
概要
- Titanic datasetで学習されたXGBoostによる生存予測モデルを非同期推論としてデプロイ
- 推論をリクエストし、結果が出力されるS3パスをポーリングすることで推論の完了を確認
主要なAPI呼び出し
| カテゴリ |
メソッド |
説明 |
| 学習と推論 |
sagemaker.image_uris.retrieve |
組み込みアルゴリズムのECR image URIを取得 |
| インフラ管理 |
SageMaker.Client.create_model |
推論用のモデルを作成 |
| インフラ管理 |
SageMaker.Client.create_endpoint_config |
推論用のエンドポイント設定を作成。ノートブックではAsyncInferenceConfigを設定し、非同期推論になるようにしている |
| インフラ管理 |
SageMaker.Client.create_endpoint |
推論用のエンドポイントを作成 |
| インフラ管理 |
SageMaker.Client.describe_endpoint |
エンドポイントの状態を取得 |
| インフラ管理 |
ApplicationAutoScaling.Client.put_scaling_policy |
オートスケーリングのポリシーを設定 |
| データ準備 |
sagemaker.session.Session.upload_data |
S3にデータをアップロード |
| 学習と推論 |
SageMakerRuntime.Client.invoke_endpoint_async |
非同期推論エンドポイントに推論をリクエスト |
| データ準備 |
sagemaker.session.read_s3_file |
S3からファイルを読み込む。ノートブックでは”NoSuchKey”をコードに含むエラーが出なくなるまで読み込みをトライし続けることで非同期推論の完了を待っている。 |
| インフラ管理 |
ApplicationAutoScaling.Client.deregister_scalable_target |
オートスケーリングの設定を削除 |
| インフラ管理 |
SageMaker.Client.delete_endpoint |
エンドポイントを削除 |
所感
- 非同期推論のエンドポイント設定でNotificationConfigを記載することで、推論完了時もしくはエラー発生時にAmazon SNSで通知を送ることができるらしい。推論完了後すぐにそれを知りたい場合や、Lambda等SNS通知を受け取れる他のシステムと連携する場合はその方がいいかもしれない
概要
主要なAPI呼び出し
| カテゴリ |
メソッド |
説明 |
| インフラ管理 |
sagemaker.model.Model.deploy |
推論用のモデル、エンドポイント設定の作成及びエンドポイントのデプロイを行う。ノートブックでは、引数のasync_inference_configに非同期推論の設定(sagemaker.async_inference.async_inference_config.AsyncInferenceConfig)を渡すことで非同期推論としてデプロイしている。 |
| 学習と推論 |
sagemaker.predictor_async.AsyncPredictor.predict_async |
非同期推論エンドポイントに推論をリクエスト。AsyncPredictorはsagemaker.model.Model.deployの戻り値として取得できる。 |
所感
- 他のメッソドについてもそうだが、SageMaker Python SDKの方が高レベルな分コード量が少なくなり読みやすいと感じた
概要
- Torchserveをモデルサーバとして、SageMakerでダイナミックバッチング可能なリアルタイム推論エンドポイントをデプロイ
- ダイナミックバッチング:複数のリクエストをまとめてバッチ推論することで、リソース利用効率を向上させスループットを高める
- ノートブックでは、3つのリクエストが溜まったらバッチ推論するように設定されている(100秒間リクエストがなければ3つ未満でも推論を実行する)
主要なAPI呼び出し
| カテゴリ |
メソッド |
説明 |
| 学習と推論 |
sagemaker.image_uris.retrieve |
組み込みアルゴリズムのECR image URIを取得 |
| インフラ管理 |
sagemaker.pytorch.model.PyTorchModel.deploy |
Torchserveをモデルサーバとして推論用エンドポイントをデプロイ。ノートブックではリアルタイム推論としてデプロイしている。 |
| 学習と推論 |
sagemaker.predictor.Predictor.predict |
エンドポイントに推論をリクエスト |
所感
- ダイナミックバッチングはSageMakerの基本機能として実装されておらず、SageMakerの機能だけで実現しようとするとリクエストを制御するためのサーバをlambda等で別途自作する必要があるらしいので、ダイナミックバッチングを使いたい場合はTorchServeを使うメリットが大きいと感じた
- 実際にこのサンプルを動かしていないのでわからないが、リアルタイム推論は60秒でタイムアウトするので、ダイナミックバッチングの待ち時間が100秒だと、リクエスト数が少ない場合、処理される前にタイムアウトしてしまう気がする
概要
- PCAとDBSCANアルゴリズムのバッチ変換用エンドポイントをデプロイ
- PCAとDBSCANそれぞれに対して推論用エンドポイントを作成する
主要なAPI呼び出し
| カテゴリ |
メソッド |
説明 |
| インフラ管理 |
sagemaker**.amazon.amazon_estimator.**get_image_uri |
組み込みアルゴリズムのイメージURIを取得。現在はsagemaker.image_uris.retrieve()の利用が推奨されている。 |
| ノートブックではPCAアルゴリズムのイメージURIを取得している |
|
|
| 学習と推論 |
sagemaker.estimator.Estimator.fit |
モデルの学習 |
| 学習と推論 |
sagemaker.transformer.Transformer.transform |
バッチ変換ジョブを実行。 |
| Transformerインスタンスはsagemaker.estimator.Estimator.transformerで取得できる |
|
|
| 学習と推論 |
sagemaker.transformer.Transformer.wait |
バッチ変換ジョブの終了を待機 |
| インフラ管理 |
sagemaker.estimator.Estimator.deploy |
推論用エンドポイントを作成。ノートブックではインスタンスタイプを指定することでリアルタイム推論でデプロイしている。 |
| インフラ管理 |
SageMaker.Client.delete_endpoint |
推論用エンドポイントを削除 |
概要
- 旧モデルから新モデルへの切り替えを自動で段階的に行うdeployment guardrailsのサンプル
- サンプルでは、3つのインスタンスの推論エンドポイントを一定時間ごとに1インスタンスずつ新モデルに切り替えている
- 切り替え方法は3種類ある(各画像はサンプルノートブックより引用)
-
Linear traffic shifting(本サンプル):新エンドポイントを作成し、一定時間ごとに一定割合ずつトラフィックを新エンドポイントのインスタンスにに切り替える。各スッテプでエラーをが出ないか検証し、途中エラーが発生したらロールバックする。すべてのトラフィックが新エンドポイントに切り替わったら旧エンドポイントを削除する。
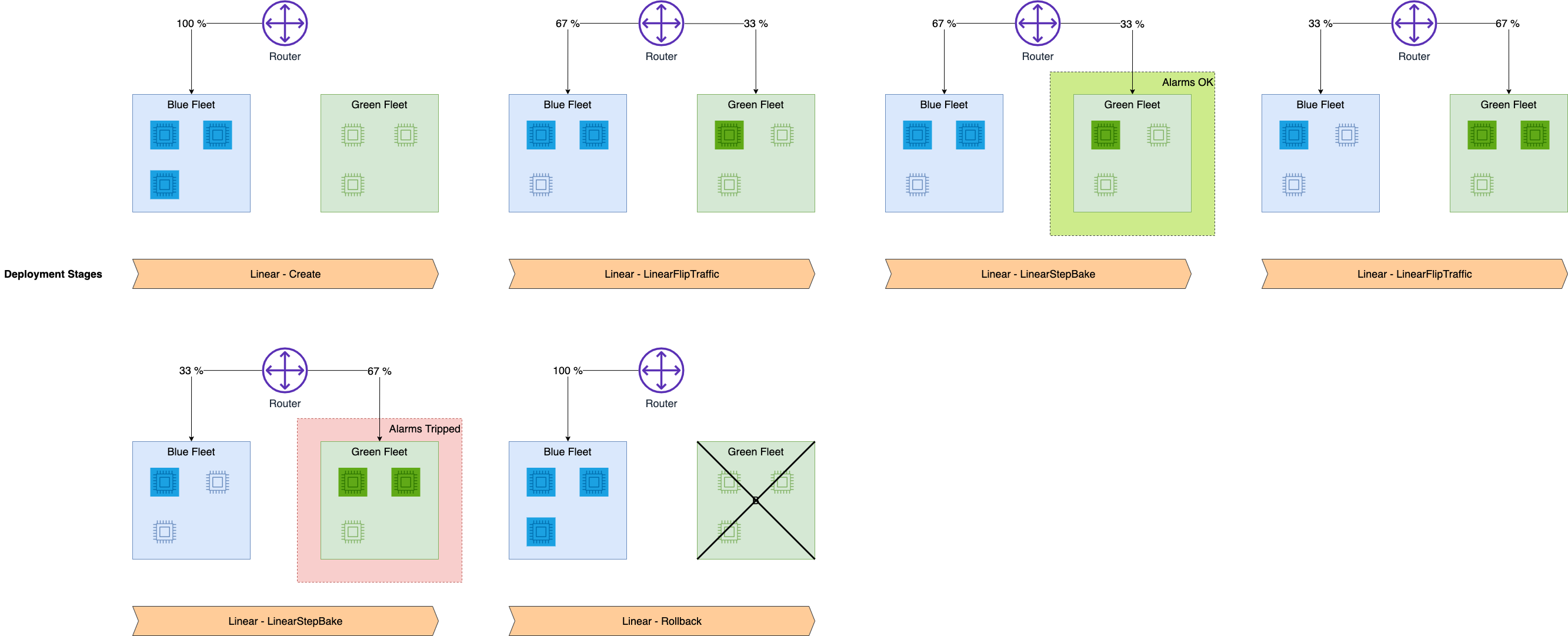
-
Canary traffic shifting(サンプル):新エンドポイントを作成し、一部のトラフィックを新エンドポイントのインスタンスに切り替える。そこでエラーが出なければ残りのトラフィックを新エンドポイントに切り替える。すべてのトラフィックが新エンドポイントに切り替わったら旧エンドポイントを削除する。linear traffic shiftingと比べて検証回数は少なくなるが、素早くリリースできる。

-
Rolling deployment(サンプル):新エンドポイントを作成し、一定時間ごとに一定割合ずつトラフィックを新エンドポイントのインスタンスにに切り替えるが、作成されるインスタンスは検証に使う分のみ(前記2つの方法は全インスタンスが作成される)。各スッテプでエラーをが出ないか検証し、途中エラーが発生したらロールバックする。エラーが発生しない場合、新エンドポイントで検証が終了したら数だけ旧エンドポイントのインスタンスを削除する。各ステップでインスタンスの再起動等が必要になる分、linear traffic shiftingと比べ移行時間はかかるが、更新期間中に起動されるインスタンス数を最小化できる(=コストを最小化できる)
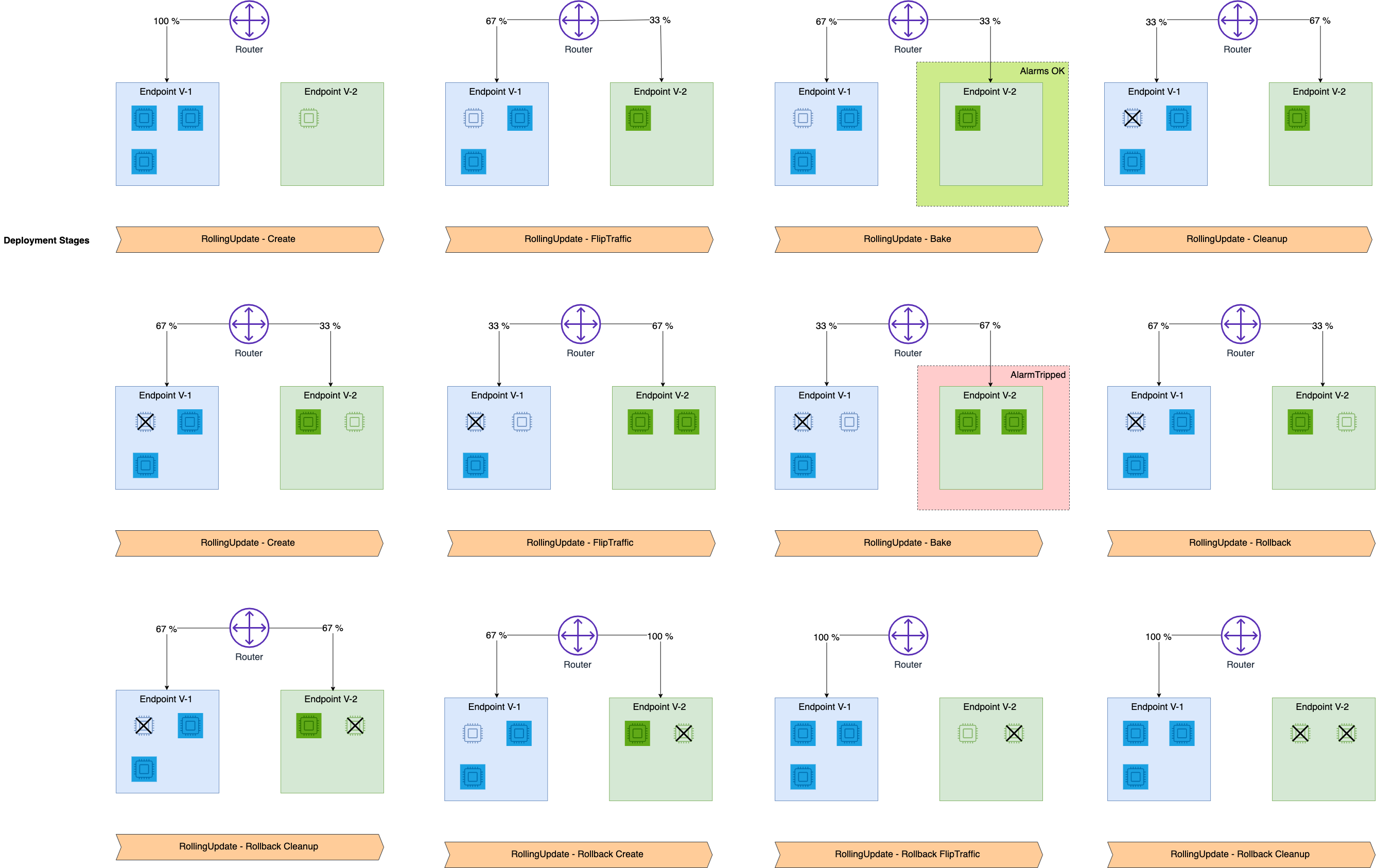
主要なAPI呼び出し
| カテゴリ |
メソッド |
説明 |
| 学習と推論 |
sagemaker.image_uris.retrieve |
組み込みアルゴリズムのECR image URIを取得 |
| インフラ管理 |
SageMaker.Client.create_model |
推論用のモデルを作成 |
| インフラ管理 |
SageMaker.Client.create_endpoint_config |
推論用のエンドポイント設定を作成 |
| インフラ管理 |
SageMaker.Client.create_endpoint |
推論用のエンドポイントを作成 |
| 学習と推論 |
SageMaker.Client.invoke_endpoint |
エンドポイントに推論をリクエスト |
| 監視とトラッキング |
CloudWatch.Client.put_metric_alarm |
エンドポイントの状態を監視。ノートブックでは、"Invocation5XXErrors"が発生したときか、"ModelLatency"が10秒を超えたときにアラームがトリガーされるように設定している |
| インフラ管理 |
SageMaker.Client.update_endpoint |
エンドポイントの更新。ノートブックでは、LINEAR traffic shiftingで旧エンドポイントを33%ずつ新エンドポイントに切り替えていく。その際、先程設定したアラームがトリガーされたらロールバックされる。 |
所感
- 新モデルの安全なデプロイが自動化されており、マルチモデルインスタンスの重みを変更する方法よりも洗練されているように感じた
- しかし、インスタンス単位で切り替えるため、1インスタンスしかないエンドポイントを切り替える場合はこの方法が使えない(1度に全トラフィックが新モデルに切り替わる)ことに注意が必要だと感じた
概要
- Churn(顧客の離脱)予測モデルの異常をリアルタイムで監視する
- SageMaker Model Monitorを使って、どのような尺度がどうなったら異常と判断するかを自動決定する
- Data captureを有効にして推論用エンドポイントをデプロイすることで、入出力をS3に保存する
- 保存されたデータをSageMaker Model Monitorを使って正解データと比較し、劣化が検知されたアラートを出す
- このノートブックは動作確認を目的としており、正解データはランダムに生成している
主要なAPI呼び出し
| カテゴリ |
メソッド |
説明 |
| 学習と推論 |
sagemaker.image_uris.retrieve |
組み込みアルゴリズムのECR image URIを取得 |
| インフラ管理 |
sagemaker.model.Model.deploy |
推論用のモデル、エンドポイント設定の作成及びエンドポイントのデプロイを行う。ノートブックでは、引数のdata_capture_configにsagemaker.model_monitor.DataCaptureConfigを渡し、入出力をS3に保存するようにしている |
| 学習と推論 |
sagemaker.predictor.Predictor.predict |
エンドポイントに推論をリクエスト |
| 監視とトラッキング |
sagemaker.model_monitor.ModelQualityMonitor.suggest_baseline |
モデルが異常だと判断するための評価指標としきい値を自動決定(ベースラインニング)する |
| 監視とトラッキング |
sagemaker.model_monitor.ModelQualityMonitor.latest_baselining_job |
ベースラインニングの結果を取得する |
| 学習と推論 |
SageMaker.Client.invoke_endpoint |
エンドポイントに推論をリクエスト。ノートブックでは、引数のInferenceIdにユニークなIDを渡すことで後に作成する正解データと照合できるようにしている |
| 監視とトラッキング |
sagemaker.model_monitor.ModelQualityMonitor.create_monitoring_schedule |
定期的なモニタリングを設定する。引数のenable_cloudwatch_metricsをTrueにすることでモニタリング結果がcloud watchに送信される |
| 監視とトラッキング |
sagemaker.model_monitor.ModelQualityMonitor.describe_schedule |
モニタリングの設定状況を確認 |
| 監視とトラッキング |
sagemaker.model_monitor.ModelQualityMonitor.list_executions |
これまでに実行されたモニタリングジョブの一覧を取得 |
| 監視とトラッキング |
CloudWatch.Client.put_metric_alarm |
Cloud watchのアラームを設定。ノートブックでは、監視するメトリックとしきい値にベースラインニングで提案されたものを設定している。 |
所感
概要
- 一つのエンドポイントに複数のコンテナを登録するマルチコンテナエンドポイントをデプロイ
- サンプルとして、MNISTをTensorFlowとPyTorchそれぞれで学習した2つのモデルをデプロイ
- 複数あるコンテナのうちどのコンテナを使うか呼び出し時に指定するDirectモードを使っている
- 複数あるコンテナを指定された順序で連続して呼び出すSerialモードもある
主要なAPI呼び出し
| カテゴリ |
メソッド |
説明 |
| 学習と推論 |
sagemaker.tensorflow.TensorFlow.fit |
TensorFlowのコンテナを使って推論用モデルを学習 |
| 学習と推論 |
sagemaker.tensorflow.TensorFlow.model_data |
学習で作成されたモデルデータのパスを取得 |
| 学習と推論 |
sagemaker.pytorch.PyTorch.fit |
PyTorchのコンテナを使って推論用モデルを学習 |
| 学習と推論 |
sagemaker.pytorch.PyTorch.model_data |
学習で作成されたモデルデータのパスを取得 |
| 学習と推論 |
sagemaker.image_uris.retrieve |
組み込みアルゴリズムのECR image URIを取得 |
| インフラ管理 |
SageMaker.Client.create_model |
推論用のモデルを作成。ノートブックでは、引数Containersに2つのコンテナの設定を渡すことでマルチコンテナにしている。また、引数InferenceExecutionConfigのModeをDirectにすることで、2つのコンテナを直接呼び出せるようにしている(Serialにすると順次実行になる) |
| インフラ管理 |
SageMaker.Client.create_endpoint_config |
推論用のエンドポイント設定を作成 |
| インフラ管理 |
SageMaker.Client.create_endpoint |
推論用のエンドポイントを作成 |
| 学習と推論 |
SageMaker.Client.invoke_endpoint |
エンドポイントに推論をリクエスト。ノートブックでは、引数TargetContainerHostnameで呼び出すコンテナを指定している |
所感
- 以下のような場合、複数のエンドポイントを構築するよりも、マルチコンテナエンドポイントを活用することでコスト効率がよくなる場合がありそう
- 複数のモデルを使用したい場合
- リアルタイム推論をデプロイしたい場合
- 推論頻度が少なくサーバのアイドル時間が多い場合
ウミトロンは、「持続可能な水産養殖を地球に実装する」というミッション実現に向けて、日々プロダクト開発・展開にチーム一丸となって邁進しています。
ウミトロンのニュースや活動状況を各種SNSで配信していますので、ぜひチェックいただき、来年も応援よろしくお願いします!
Facebook https://www.facebook.com/umitronaqtech/
X https://x.com/umitron
Instagram https://www.instagram.com/umitron.aqtech/
Linkedin https://www.linkedin.com/company/umitron