はじめに
connpassイベントのキャンセル率が高いとの発言をたびたび目にします。
実際どの程度キャンセルされているのか、pandas, matplotlibの練習を兼ねて調べてみました。
TL;DR
- 全体の平均キャンセル率は27.5%
- 前払い制や参加上限のないイベントではキャンセル率が半減する
- キャンセル処理をせず当日参加しなかったものは集計できていないため、実際のキャンセル率はさらに高い
- 意外な結果はなし
データ収集
コードはこちらです。
hookbook/connpass-analyses
取得方法
python collect.py --s 201901 --e 201902
connpass API
公式にAPIが用意されているため、これを利用します。
パラメータ詳細はリンク先参照してください。
※過度な検索やクローリングに対しては、アクセス制限を施す可能性があります。robots.txt を尊守してください。
User-agent: *
Crawl-delay: 5
Allow: /
Disallow: /series/optout/
Disallow: /account/
def get_event_data_ym(ym: int, seve_csv: bool = False) -> pd.DataFrame:
"""指定年月のconnpassイベント情報をDataFrameとして返す。
Parameters
----------
ym : int
取得するイベントの開催年月。
save_csv : bool, default False
取得した情報を保存するか。
Returns
-------
df : DataFrame
指定年月のconnpassイベント情報。
"""
df = pd.DataFrame(columns=df_columns)
# イベント件数
count = get_event_info(ym, 1, 1)['results_available']
for i in range((count // 100) + 1):
# イベント情報取得
events = get_event_info(ym, (i * 100) + 1)['events']
time.sleep(SLEEPING_SECONDS)
for event in events:
# connpassで受け付けているイベントのみを対象とする
if event['event_type'] == 'participation':
# キャンセル数や決済方法を取得
scraped_dict = get_event_data(event['event_url'])
time.sleep(SLEEPING_SECONDS)
# api とスクレイピング結果を結合
se = pd.Series({**event, **scraped_dict}, index=df.columns)
df = df.append(se, ignore_index=True)
if seve_csv:
# 途中経過をcsv保存
df.to_csv(DATASET_DIR + 'dataset_temp.csv', mode='a')
return df
スクレイピング
APIで取得できない情報は各イベントページをスクレイピングして取得しました。
- キャンセル者数
- 有料イベントかどうか
- 参加費
- 参加者選出方法(先着順・抽選)
connpassイベントでは一つのイベントに対して複数の募集があるケースがあります。
それぞれ別々に集計するのが望ましいのですが、簡単のために上に表示されている募集を優先して取得しました。
- 有料と無料の募集が混在している場合は、有料と判定
- 先着順・抽選どちらもある場合は、上に表示されている方式と判定
- 複数の参加費設定がある場合は、上に表示されている参加費
def get_event_data(url: str) -> dict:
"""connpassイベントページより追加情報を取得する。
Parameters
----------
url : str
connpassイベントのurl。
Returns
-------
event_dict : dict[str, Any]
イベント情報dict。
"""
try:
html = urlopen(url)
except Exception:
# アクセス失敗した場合には全てNoneで返す
event_dict = {
'canceled': None,
'lottery': None,
'firstcome': None,
'freedom': None,
'prepaid': None,
'postpaid': None,
'amount': None
}
return event_dict
soup = BeautifulSoup(html, 'html.parser')
canceled = 0
cancel = soup.find(href=url + 'participation/#cancelled')
if cancel is not None:
canceled = cancel.text[9:-2]
# 抽選 or 先着順(混在している場合には表示順上位の内容を優先)
lottery = False
firstcome = False
free = False
participant_decision_list = soup.find_all('p', class_='participants')
for participant_decision in participant_decision_list:
if '抽選' in participant_decision.text:
lottery = True
break
elif '先着' in participant_decision.text:
firstcome = True
break
# 抽選でも先着順でもないイベント
free = not lottery and not firstcome
# 会場払い or 前払い(混在している場合には表示順上位の内容を優先)
prepaid = False
postpaid = False
# 金額(表示順上位・有料を優先)
amount = 0
payment_list = soup.find_all('p', class_='join_fee')
for payment in payment_list:
payment_text = payment.text
if '(前払い)' in payment_text:
prepaid = True
amount = re.sub(r'\D', '', payment_text)
break
elif '(会場払い)' in payment_text:
postpaid = True
amount = re.sub(r'\D', '', payment_text)
break
event_dict = {
'canceled': canceled,
'lottery': lottery,
'firstcome': firstcome,
'free': free,
'prepaid': prepaid,
'postpaid': postpaid,
'amount': amount
}
return event_dict
取得した項目
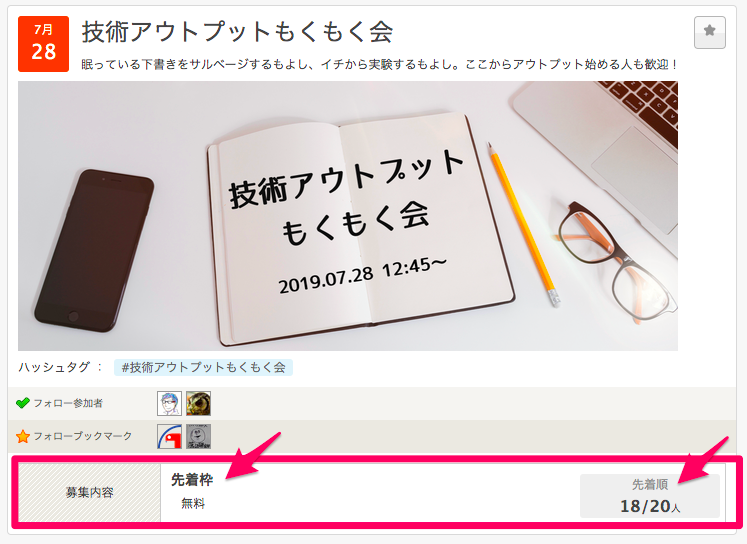
2011年11月〜2019年6月のイベントデータを対象に、67,557件を取得しました。
| フィールド | 説明 | 取得方法 | 値 |
|---|---|---|---|
| event_id | イベントID | API | 139640 |
| title | タイトル | API | 技術アウトプットもくもく会 |
| catch | キャッチ | API | 眠っている下書きをサルベージするもよし、イチから実験するもよし。 |
| event_url | connpass.com 上のURL | API | https://connpass.com/event/139640/ |
| hash_tag | Twitterのハッシュタグ | API | 技術アウトプットもくもく会 |
| address | 開催場所 | API | 東京都港区南青山 1 丁目12-3 (LIFORK MINAMI AOYAMA S209) |
| place | 開催会場 | API | StockMark, Inc. |
| lat | 開催会場の緯度 | API | 35.668502700000 |
| lon | 開催会場の経度 | API | 139.724649300000 |
| started_at | イベント開催日時 | API | 2019-07-28T12:45:00+09:00 |
| ended_at | イベント終了日時 | API | 2019-07-28T19:30:00+09:00 |
| limit | 定員 | API | 20 |
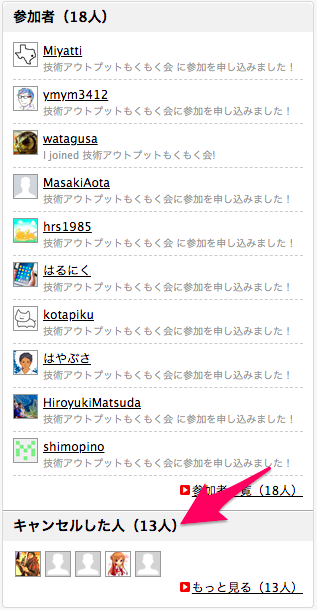
| accepted | 参加者数 | API | 18 |
| waiting | 補欠者数 | API | 0 |
| canceled | キャンセル人数 | スクレイピング | 13 |
| lottery | 参加者決定方法(抽選) | スクレイピング | False |
| firstcome | 参加者決定方法(先着順) | スクレイピング | True |
| freedom | 参加者決定方法(無制限) | スクレイピング | False |
| prepaid | 支払い方法(前払い) | スクレイピング | False |
| postpaid | 支払い方法(会場払い) | スクレイピング | False |
| amount | 参加費 | スクレイピング | 0 |
データ編集
イベントページが404のデータを除外
len(df[df['canceled'].isnull()])
# 3
# canceled が欠損しているデータは404として除外
df.dropna(subset=['canceled'], inplace=True)
実施されなかったイベントを除外
len(df.query( "accepted == 0"))
# 7566
# 参加者がいなかったイベントは、イベント自体がキャンセルされたとして除外
df = df.query( "accepted != 0")
カテゴリ変数追加
# 参加者決定方法
# 抽選:0
# 先着順:1
# 無制限:2
df.loc[df['lottery'] == True, 'decision_type'] = 0
df.loc[df['firstcome'] == True, 'decision_type'] = 1
df.loc[df['freedom'] == True, 'decision_type'] = 2
df['decition_type'] = df['decision_type'].astype(int)
df['decision_type'].value_counts()
# 1 49821
# 0 5443
# 2 4724
# Name: decision_type, dtype: int64
# 支払い方法
# 無料:0
# 前払い:1
# 会場払い:2
df.loc[df['amount'] == 0, 'paid_type'] = 0
df.loc[df['prepaid'] == True, 'paid_type'] = 1
df.loc[df['postpaid'] == True, 'paid_type'] = 2
df['paid_type'] = df['paid_type'].astype(int)
df['paid_type'].value_counts()
# 0 42372
# 2 15926
# 1 1690
# Name: paid_type, dtype: int64
データ確認
# イベント開始時刻をインデックスに指定
df_ts = df.set_index('started_at')
df_ts.index = pd.to_datetime(df_ts.index, utc=True).tz_convert('Asia/Tokyo').tz_localize(None)
# 集計用列の追加
df_ts['post_count'] = 1
# 開始時刻順に並び替え
df_ts.sort_index(inplace=True)
# マルチインデックス指定
df_multi = df_ts.set_index([df_ts.index.year, df_ts.index.month, df_ts.index.weekday,
df_ts.index.hour, df_ts.index])
df_multi.index.names = ['year', 'month', 'weekday', 'hour', 'date']
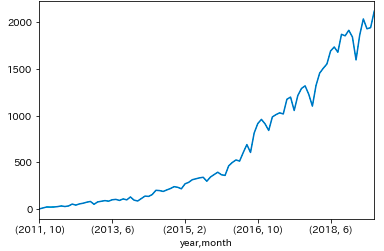
年月別のイベント数推移
ym = df_multi.sum(level=['year', 'month']).post_count.sort_index()
ym.plot()
plt.show()
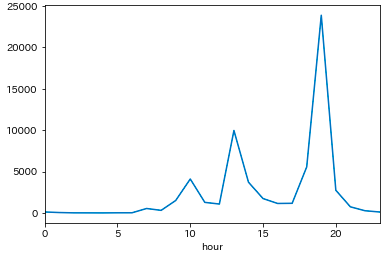
時刻別のイベント数
- 19時開始に集中している
hour = df_multi.sum(level='hour').post_count.sort_index()
# hour
# 0 115
# 1 47
# 2 9
# 3 6
# 4 1
# 5 15
# 6 18
# 7 535
# 8 310
# 9 1501
# 10 4097
# 11 1275
# 12 1073
# 13 9956
# 14 3708
# 15 1735
# 16 1143
# 17 1162
# 18 5555
# 19 23876
# 20 2736
# 21 737
# 22 265
# 23 113
# Name: post_count, dtype: int64
hour.plot()
plt.show()
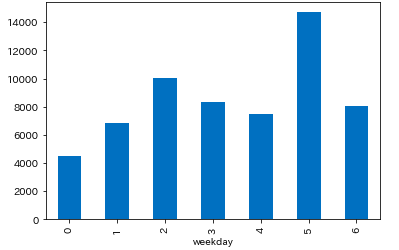
曜日別のイベント数
- 水曜、土曜はイベントが多い
weekday = df_multi['post_count'].sum(level='weekday').sort_index()
# weekday
# 0 4491
# 1 6840
# 2 10045
# 3 8346
# 4 7499
# 5 14699
# 6 8068
# Name: post_count, dtype: int64
weekday.plot.bar()
plt.show()
月曜日:0 〜 日曜日:6
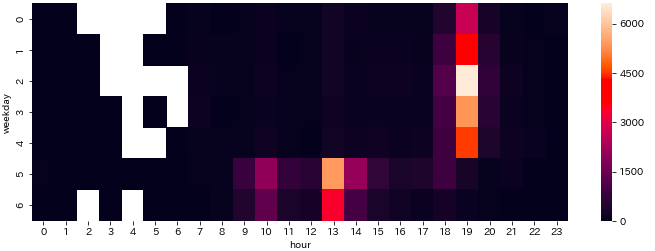
時刻別・曜日別にイベント数
イベント開始時刻をヒートマップ表示してみます。
- 平日の19時と休日の13時(うっすら10時)に偏っている
df_w_h = df_multi['post_count'].sum(level=['weekday', 'hour']).sort_index()
plt.figure(figsize=(12, 4))
sns.heatmap(df_w_h.unstack(level='hour'))
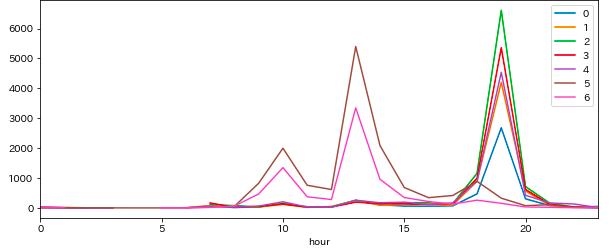
折れ線グラフでも。
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
df_w_h.unstack(level='weekday').plot(figsize=(10, 4), ax=ax)
plt.legend(loc='upper right', bbox_to_anchor=(1, 1))
キャンセル率の確認
キャンセル率の計算方法
キャンセル率は以下で計算します。
(イベントに申し込んだ人数に対するキャンセルした人数の割合。)
キャンセル率 = \frac{キャンセル人数}{参加者数+補欠者数+キャンセル人数}
def get_cancel_rate(df):
return df['canceled'].sum() / (df['accepted'].sum() + df['waiting'].sum() + df['canceled'].sum())
全イベント
- 全データを対象にすると平均で約27.6%
get_cancel_rate(df)
# 0.2755642788195028
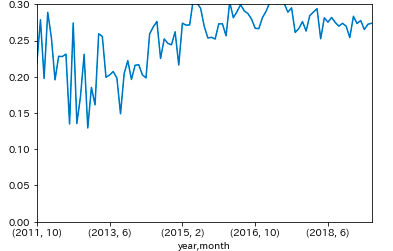
年月別
plt.ylim(0, 0.3)
cr_ym = df_multi.groupby(['year', 'month'], as_index=False).apply(lambda d: get_cancel_rate(d))
cr_ym.plot()
曜日別
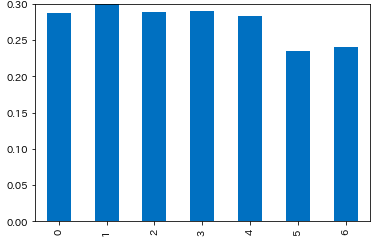
- 土日はキャンセル率が低い
- 祝日は未確認
plt.ylim(0, 0.3)
cr_weekday = df_multi.groupby(['weekday'], as_index=False).apply(lambda d: get_cancel_rate(d))
# 0 0.287851
# 1 0.301708
# 2 0.289396
# 3 0.290123
# 4 0.282869
# 5 0.235157
# 6 0.240867
# dtype: float64
cr_weekday.plot.bar()
月曜日:0 〜 日曜日:6
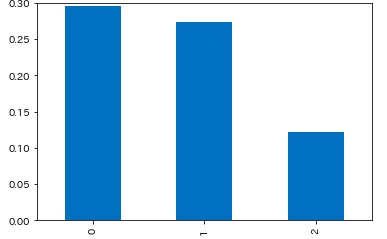
参加者の決定方法別
- 参加者上限がないイベントではキャンセル率が約12.2%
plt.ylim(0, 0.3)
cr_decision_type = df.groupby(['decision_type'], as_index=False).apply(lambda d: get_cancel_rate(d))
# 0 0.295299
# 1 0.274411
# 2 0.121591
# dtype: float64
cr_decision_type.plot.bar()
抽選:0
先着順:1
無制限:2
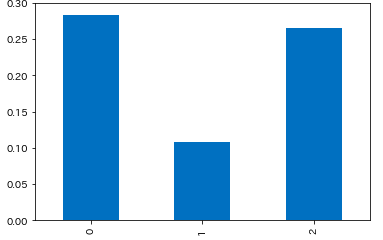
支払い方法別
- 前払いのイベントはキャンセル率が約10.9%
plt.ylim(0, 0.3)
cr_paid_type = df.groupby(['paid_type'], as_index=False).apply(lambda d: get_cancel_rate(d))
# 0 0.283863
# 1 0.108790
# 2 0.265070
# dtype: float64
cr_paid_type.plot.bar()
無料:0
前払い:1
会場払い:2
まとめ
おおむね調査前の予想通りで、意外性のない結果となりました。
この結果はあくまでconnpassイベントページから取得できる情報による調査のため、キャンセル処理をせず当日参加しなかったものは集計できていません。
そのため、実際のキャンセル率はさらに高くなります。
connpassイベントのデータは集まったので、次はイベントキャンセル率の予測モデルを作成してみます。