はじめに
基礎統計量をまとめてCSVファイルで出力するコードを書く。CSVファイルで出力できれば、WindowsであればそのままExcel形式にして資料として共有することができる。データには量的変数と質的変数があるため、それぞれに対応する基礎分析を行う必要があるが、本記事ではまずどちらにも関わると考えられる「データ型」および「データの欠損数」を出力する。データはdefault of credit card clients Data Setを扱う。
本筋とは関係ないが、上記データはxlsx形式なので一度ダウンロードしてCSV形式に変換(ファイル名もcredit.csvに変更)している。(xls形式やxlsx形式はパッケージを使えば読み込めるらしい。そのうち試してみよう。)
データ読み込みとヘッダの準備
データを読み込んで不必要な列を削除し、ヘッダのデータフレームを準備する。
readCsv.r
d <- read.csv(file="credit.csv", header=TRUE, skip=1)
d <- d[, !colnames(d) %in% c("ID") # "ID"列を削除
h <- colnames(d) # ヘッダ
h <- data.frame(h)
colnames(h) <- "ROWNAMES"
データ型の調査
以下コードでデータ型を求める。Rでデータ型を調べるclassについてでも書いたが、列全体をclassの引数に入れてもその中でより大きいデータ型を出力してくれる。そのため、 NULL などが含まれていても(例えば数値データが1つのみ入っていて、その他データが欠損値であっても) numeric を返してくれる。欠損値が " " などの character 型の場合は本来欲しい numeric は返ってこないため、 read.csv の時点で na.strings などを用いて処理しておく必要がある。
datatype.r
datatype <- array(dim=ncol(d))
for(i in 1:ncol(d)){
datatype[i] <- class(d[,i])
}
CSV形式での出力
上記で求めたデータ型と欠損数をヘッダにひもづけて出力する。
export.r
h$class <- datatype
h$is.na <- apply(is.na(d), 2, sum)
h$is.not.na <- apply(!is.na(d), 2, sum)
write.csv(x=h, file="summary.csv")
出力結果は以下のようになる。
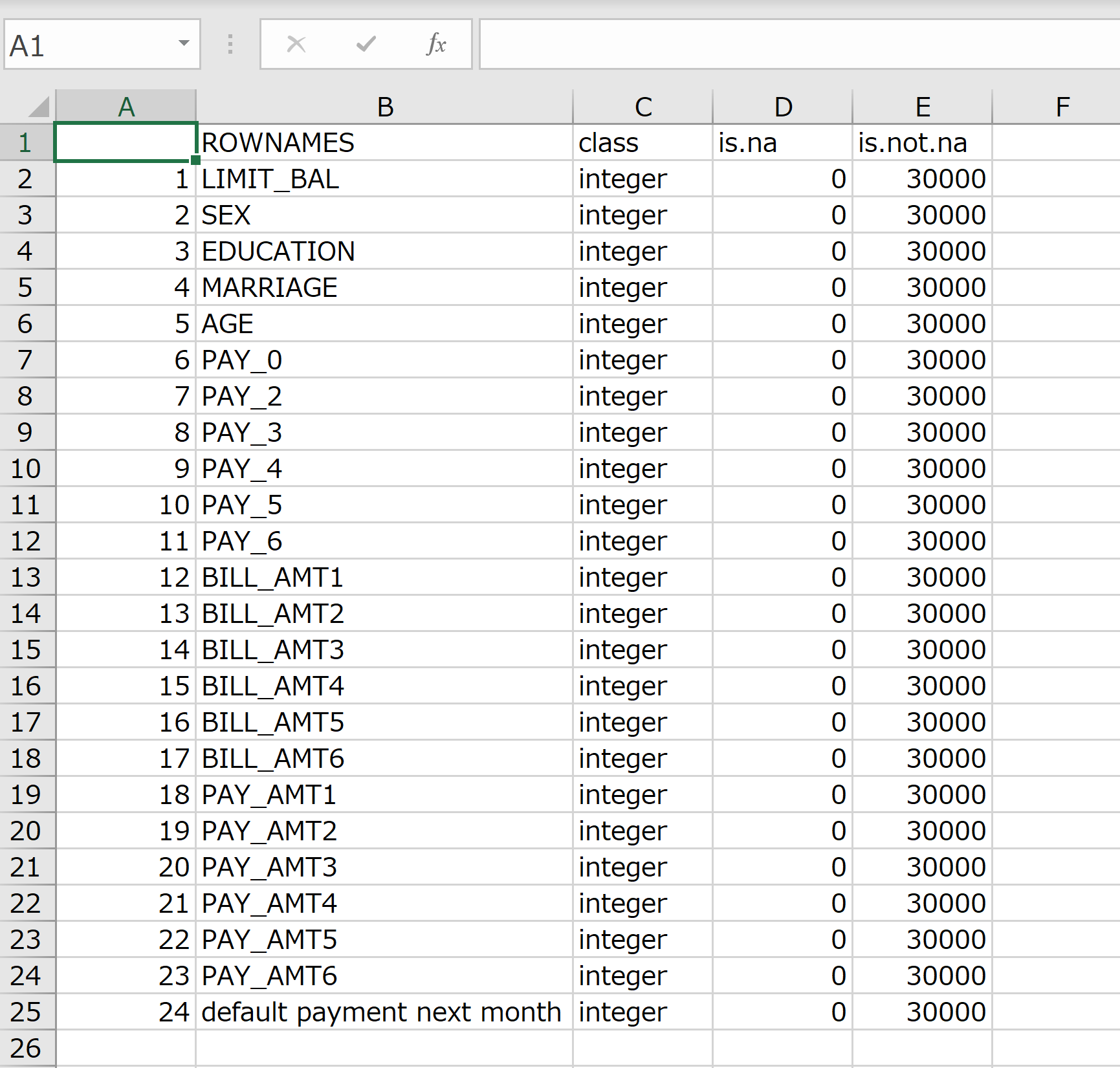
以降の記事で量的変数および質的変数の基礎分析を行って、CSV形式で出力をしていく。