この記事は、エムスリーキャリア Advent Calendar 20223 の21日目の記事です。
はじめに
データ基盤移行の背景
こんにちは。エムスリーキャリア Webグループの本間です。
これまで弊社では、データ基盤としてオンプレのDWHを利用していました。しかし、オンプレのDWHはハードウェアやソフトウェアのメンテナンスが必要で、運用コストや管理負荷がかかってしまうという課題がありました。また、弊社では複数のシステムが散在しており、オンプレのDWHでは、全てのデータを一元管理することができず、データの一元化が困難である状況でした。
そこで、これらの課題に対処するために、データ基盤の構築方法を見直すことに決定しました。その結果、クラウド上でデータ基盤を構築することを選択しました。クラウドへの移行によって、ハードウェアやソフトウェアのメンテナンスが不要になり、運用コストや管理負荷が軽減されることを目指しました。さらに、クラウドのデータウェアハウスは、複数のシステムからのデータを一元管理できるだけの拡張性を持っているため、データの一元化を実現することも目指しました。
こんなデータ基盤にしたかった
データ基盤の完成図
こだわったのは、とにかくシンプルであること、それとフルマネージドであることです。基盤の維持にかかる運用コストを最小化できる構成にこだわりました。
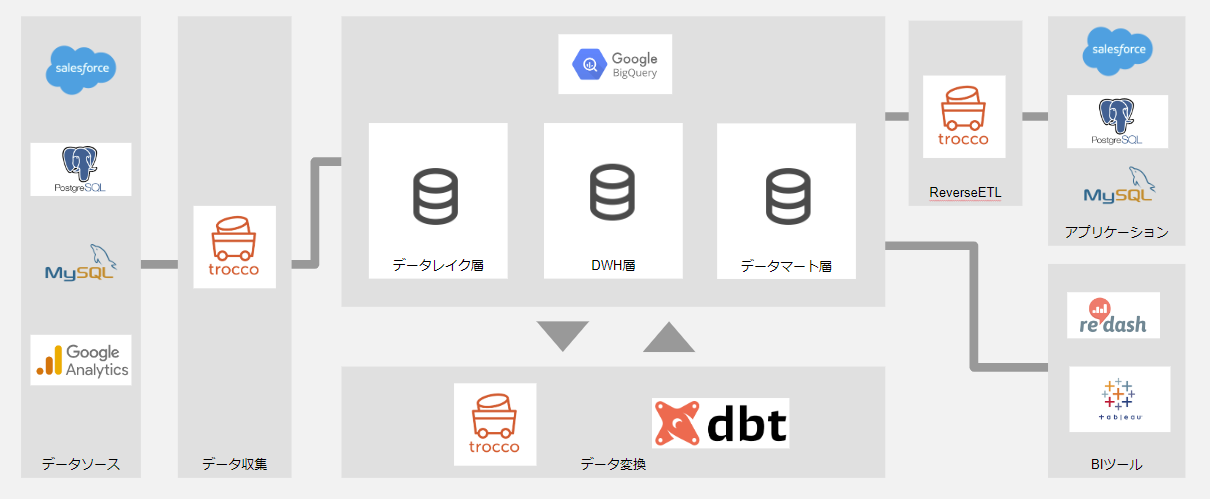
左側に各種システムのデータソース、真ん中にデータウェアハウス、右側に各アプリケーションを配置しています。
データソースの対象は、業務で利用している複数組織にまたがるSalesforceのデータ、各システムのクラウド上にあるDB、マーケティングで利用している各種広告データなどが対象になります。
データウェアハウスの部分は「BigQuery」を採用しました。BigQueryは論理的にデータレイク層、DWH層、データマート層に分けることにしました。データレイク層にオブジェクトストレージを利用することも検討しましたが、データウェアハウスと同じ分析用DBに格納することにしています。
データ収集基盤としては「trocco」を採用しました。データ変換の部分もtroccoのデータマート定義を使って実現しますが、将来的にはdbtの利用も視野にいれています。データウェアハウスからReverseETLにより各アプリケーションにデータを書き戻すこともtroccoで実現したいと考えています。
データ基盤の構築に求めた要件
弊社の現状を考慮し、以下の3点を重視したデータ基盤を構築したいと考えました。
- 基盤のメンテナンスが不要で、専任の担当者が不要であること
- データパイプラインの構築に開発が必要ないこと
- 処理速度が高速であること
データウェアハウスにBigQueryを採用した理由
データウェアハウスに BigQuery を採用した理由は、主に以下の3点です。
- 処理の高速化が成熟していること
- エコシステムが充実していること
- GCPの各種サービスとの連携が容易であること
まず、「処理の高速化が成熟している」という点です。次に、「充実したエコシステム」という点になります。国内において多数の事例が存在し、情報が豊富に揃っている点になります。最後に、「GCPの各種サービスとの容易な連携」という点が挙げられます。これにより、将来的にデータを活用した様々な施策に伴う開発がスムーズに実施できると考えました。
これらの理由から、BigQueryを採用することに決定しました。
データウェアハウスの選択については、最後まで悩みました。他の製品をギリギリまで検討していましたが、最終的にBigQueryを採用することに決断しました。現在、すでに運用が始まっており、弊社の環境においてこの決断は正しかったと感じています。
データパイプラインにtroccoを採用した理由
データパイプラインに trocco を採用した理由は、主に以下の3点です。
- 必要な機能が提供されている
- 国内のサービスである
- 他サービスでは実現できないことができたこと
まず大前提として、「データ収集に必要な機能が提供されている」点が挙げられます。データ転送だけでなく、各処理のワークフロー管理が行えること、さらにReverseETLとして利用できることも、採用した理由の一つ目になります。
次に「国内のサービスである」という点が重要です。日本のサービスであるため、情報収集が容易で、サポートも受けやすいということが、二つ目の理由となります。
最後に、「他サービスでは実現できないことができた」点が挙げられます。技術検証を実施した際に、実現したい機能がtroccoで実現可能であったことが、最後の理由となります。
これらの理由から、troccoを採用することに決定しました。
実際のスケジュール
2023年2月後半にデータ基盤の構築プロジェクトが立ち上がりました。そこから、要件の整理、設計、技術検証、社内手続き、契約、移行作業の実施を進めてきました。メインのデータに関しては、既存のオンプレからBigQueryに移行できたのが2023年8月に実施することができました。およそ半年でクラウド上にデータ基盤を構築することができました。
今後
データ基盤の構築が完了した後も、継続的な改善と最適化を進めていく予定です。データ基盤を活用し、当初考えていた目的の達成に向けて積極的に取り組んでいきます。
また、今後の展望として以下のような事項にも取り組んでいきたいと考えています。
- 履歴データの管理
- メタデータの管理
- dbtの導入
さいごに
最後まで読んでいただきありがとうございます。
私たちエムスリーキャリアでは、様々なシステム開発を通して、医療業界や事業の課題に向き合っています。エムスリーキャリアでは積極的にエンジニアを募集しております。
明日以降も エムスリーキャリア Advent Calendar 2023 は続きます。引き続きお楽しみください。
参考文献
データ基盤をクラウドに構築するにあたり、様々な書籍や動画を参考にさせていただきました。ありがとうございます。
- 実践的データ基盤への処方箋
- エンジニアのためのデータ分析基盤入門
- データ指向アプリケーションデザイン
- Google Cloudではじめる実践データエンジニアリング入門
- DX時代のデータマネジメント大全
- 実践ビッグデータ分析基盤開発 ストーリーで学ぶGoogle BigQuery
- Google Cloud実践活用術 データ分析・システム基盤編
- エンタープライズのためのGoogle Cloud
- Tableauデータ分析 ~入門から実践まで~
- Data Engineering Study(すべての回を視聴させていただきました)
- 2022年、dbt で作るデータ基盤の現場の話