この記事はうるるAdvent Calendar 2022の8日目の記事です。
久しぶりにアドベントカレンダー参加して楽しいです。
最近は実務領域の業務が増えてきたので、現場観点とこれまでの経験の複合的な観点で記事を書いてみようと思いました。
はじめに
この記事は、初めて社内にデータ基盤を構築しようとしている中での思考の移り変わりや大切にしてきた考えを書き起こしたものです。
※正確に本当に初めてなのかどうかは未確認
筆者はデータエンジニアリングに専門性を持っているわけではないので、もしより良い考え方などフィードバックがあれば是非コメントのほどお願いします!
データ基盤について
今回書く記事で「データ基盤」が指すものは、一般的なものと相違ないイメージを持っています。
利用用途としてデータ可視化やデータ分析を実現するための基盤と捉えて頂くのが正確です。
前提の説明
我々は NJSS というサービスを1つの事業として運営しています。
わたしはその事業の中のエンジニアとしてサービスの成長に従事しています。
この NJSS のサービスにおいて、以下の背景がありました。
- 2021/07にシステムフルリプレイスの前半戦完遂
- 2022/07にシステムフルリプレイスの後半戦完遂
所属していた正社員は当然、パートナーであるエンジニアの方々のお力も含めて総力戦で走り抜き、なんとか成し遂げました。
※フルリプレイスに関する話には今回触れませんが、レガシー程度10年超えのシステムのリプレイスを成し遂げた関係各位に対しては感謝と尊敬を感じています
データ基盤というテーマに結びつくまでの課題
さて、システムのフルリプレイスは完了しましたが、そのことによって我々エンジニアとしての仕事は完遂でしょうか。
当然、そんなことはありません。
我々のような事業会社のエンジニアチームに期待され、発揮すべき価値領域は以下の2つだと捉えています。
- 新たな価値提供のための開発能力を基にした新機能/追加機能の提供
- 既存価値の維持のための運用能力を基にした安定的な機能提供
便宜的に機能提供という言葉で書いてみていますが、要は開発と運用の双方が成り立って初めて価値が認められるのが事業会社エンジニアだと考えています。
そして特に後者のほうが事業会社エンジニアが発揮すべき真の価値だと個人的には考えているのですが、それは一旦置いておきます。
事業運営上の課題
上記2つのテーマを狙う上で、課題にあったのが下記の観点でした。
- 開発すべき新機能を考える上での判断材料が乏しい
- どのような価値をどれだけ与えることができているのか確認するための材料が乏しい
つまり、確認できるデータが乏しい状況にありました。
上で掲げた課題についてはユーザーの利用状況にも繋がるもので、エンジニアチームだけではなく事業チーム全体の課題とも考えられ、重要課題でした。
この課題に対して、事業の企画チームのメンバーが立ち上がりました。
そしてその彼がユーザーレポートという形で、どの機能をどれだけ使っているのかを可視化したダッシュボードが構築され、事業チーム全体でそのユーザーレポートの活用を開始しました。
非常に素晴らしい取り組みだと、この動きを見て感じたのを記憶しています。
データ活用を始めてから出てきた課題
一方でそのユーザーレポートの活用を進める動きの中でも課題が新たに出てきました。
このユーザーレポートは Google BigQuery + Looker Studio(旧Googleデータポータル) で構成されており、レポート上に数値が出るまでの流れとして
- サービスDBに対して集計用のSQLクエリを実行
- 実行結果をCSVで吐き出し
- CSVを BigQuery で読み込み
という手順を経ています。この手順を手動で行う形で運用です。
この手動運用に当然辛みを感じ始めるという課題が出てきました。
また、この手順の中で他に存在していた課題として下記のようなものが挙げられます。
- 集計用のクエリが重量級のものがあり、サービスDB上でクエリを発行するのが怖い😰
- 集計用のクエリが重量級のものがあり、そもそも結果が返ってくるまえにタイムアウトしてしまう😢
- 集計結果が大量になり、CSVとして吐き出せない(GUIツールを提供しているが、このツールがメモリ枯渇して落ちてしまう)😭
- 集計用のクエリを投げるタイミングを見計らう必要がある(アクセスが少なくCPUやメモリのリソースに余裕がある夜間など)🧐
加えて、事業戦略上の動きとして大量のデータをリストとして抽出するような動きが必要となり、上記とまったく同じ課題に遭遇する状況を目にしました。
データを取り扱う専用の環境を作り、さらに手順の自動化をすることでこれらの課題に対処していくしかないと考え、データ基盤を構築することを提案し動き出したという背景になります。
データ基盤に関する技術選定
当初考えていた構成
| 領域 | 利用技術 |
|---|---|
| データソース | サービスDB / ログ / Salesforce / Google Analytics |
| データレイク | Amazon S3 |
| ETL系ツール | AWS Glue / Athena |
| データウェアハウス | Amazon Redshift / Google BigQuery |
| BIツール | Amazon QuickSight / Looker Studio |
思考として、AWSの各種サービスを使ってAWS上に存在するデータ量が多いので、Redshift 一択だろうという考えをしていました。
また Amazon Aurora でスケーリング容易性があるとは言えサービスDB本体に負荷をかけるのは憚られるため、スナップショットを S3 にエクスポートし、それらを Glue で扱ってデータウェアハウス(DWH)に流し込むような考えもしていました。
しかしやはり、BigQuery を使い始めた状況で、それを載せ替えさせるのも一苦労だし、DWHが2つ存在していくような可能性も想定するとイマイチな考えでした。
そこで考えたのが以下の構成です。
現在の初期構成
| 領域 | 利用技術 |
|---|---|
| データソース | サービスDB |
| データレイク | |
| ETL系ツール | Datastream for BigQuery |
| データウェアハウス | Google BigQuery |
| BIツール | Looker Studio |
| 構成管理 | Dataform |
出口戦略ではないですが、「データを利用する場面から考えるとよい」ということをAWSのSAの方からアドバイスを頂き、利用者である事業チームメンバーが Google Workspace を使っていることとの相性も考え、Google系のサービスに寄せていくことにしました。
ダッシュボードを Google Workspace 上で管理できたりと、とても使い勝手がよいです。
この考え方をしようとしたときに、 Datastream がリリースされたことが判断の決め手ともなりました。
Datastream は AWS で言うと DMS のようなもので、レプリケーション系のツールになります。
まず初期構成で実現しようとしている範囲がSQLクエリで集計を実現できる範囲であったため、複雑なデータ変換処理も必要とせずシンプルにデータを BigQuery 上に流し込み、BigQuery 上でビュー/マテリアライズド・ビュー機能を使ってデータマートを作成してしまおうという考えをしています。
DWH を BigQuery に寄せることができれば Salesforce や Google Analytics のデータの取り込みも容易になるため、将来的に想定している状態に対してもアプローチがしやすくなると考えました。
将来的に想定している構成
| 領域 | 利用技術 |
|---|---|
| データソース | サービスDB / ログ / Salesforce / Google Analytics |
| データレイク | Amazon S3 |
| ETL系ツール | Datastream for BigQuery / Athena / BigQuery Data Transfer Service |
| データウェアハウス | Google BigQuery |
| BIツール | Looker Studio |
| 構成管理 | Looker or Dataform |
技術選定を進める中で考慮していたポイント
1. シンプルに実現できないかを考える
システム間の連携が増えることで運用が大変になることは想像に難くないと思います。
わたし自身、データエンジニアリングやデータ分析、DataOps といった領域に専門性を持っているわけではないのも含め、やりたいことを実現するためにいかにシンプルな構成を目指せるか、といったことを意識していました。
2. コスト面は大きく気にしない
これまでに記載した選定の経緯の中でコスト面の話を出してきていませんでしたが、そこまで気にしていなかったからというのが理由にあります。
データ量を基準に計算できる部分は試算してみましたが、クエリ実行にかかる料金は正直不透明な要素で計算をしてもあまり意味がないと考えました。
実際にどれだけの人が実行していくか、そのときのクエリ実行にかかる時間やデータ量はどれくらいになるか、といった観点についてはデータの中身やクエリの中身によって変わってくるため、いま計算しても根拠が乏しすぎ、料金計算の方法の違いだけを抑えておけば問題ないと考えました。
また、実際に運用に乗せた後にクエリの見直しやパーティショニングなどでコスト最適化を考えられる手立ては想定できたため、活用状況が見えてきたら考えればよいという温度感で捉え、ここの検討に時間を使うより早く形を作ることを意識していました。
データ分析に関連する各技術を触ってみた上での感想
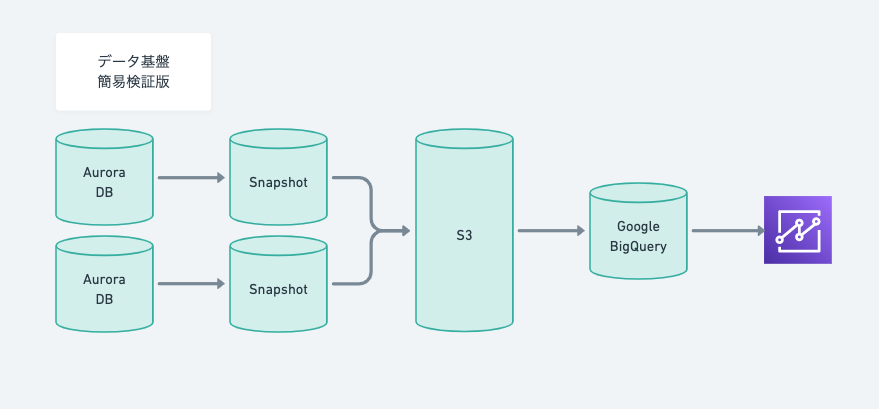
Aurora Snapshot / S3 / Athena
技術検証をする中でこんなことをやってみたことがあります。
- Aurora MySQL(各サービスのアプリ用DB)から Snapshot 取得
- Snapshot を S3 にエクスポート(Parquet 形式に変換)
- AWS Glue でデータカタログ(データ構成定義)を作成
- エクスポートされた Snapshot データに対して Athena にてクエリ発行
- Athena のクエリ実行結果を S3 にエクスポート(CSV形式で保存)
列指向データベースの実行速度神ってる🤩
恥ずかしながら列指向データベースを触ってみたのが始めてで、Parquet形式に変換されたデータベースに対してクエリを投げてみて驚愕をしました。
1つ大きく差が出たものの実数値を持ち出してみると、
| 指向 | 実行環境 | 範囲指定 | 実行時間 | 単位を統一 |
|---|---|---|---|---|
| 行指向 | Aurora MySQL | 1日 | 19分 | 34,200秒/30日 |
| 列指向 | S3 | 30日 | 7.9秒 | 7.9秒/30日 |
34200 / 7.9 = 約4329倍!?!?
用途に合わせた技術を使うことの大切さを実感しました。
Datastream for BigQuery
Datastream を利用して BigQuery へデータを流し込んでみました。
手軽に始められることが本当に嬉しい😊
「データ分析」「データ基盤」などの言葉が多く出回るようになったが、それに追随するように各社でかゆいところに手が届くようなサービス開発をしている様子が見られました。
そんな中で、複雑な設定や何かプログラムを書いて実装しないと実現できないというわけではなく、幾つかの設定を施すだけで DWH にデータを入れていくことを実現できるこのサービスの登場は限られた人的リソースで実現を目論んでいるわたしにとっては非常にありがたいものでした。
せっかくなので少しだけ触れておくと、施した設定は以下のような内容です。
- 接続プロファイルの設定
- ソースとの接続プロファイル作成
- ターゲットとの接続プロファイル作成
- ストリームの作成
- 使用する接続プロファイルを指定
- ストリームの対象とするスキーマ/オブジェクトの選択(不要なデータは対象外として指定可能)
- 新しいデータだけを対象とするか、既に保持しているデータも対象をするかを選択
- ソース側でレプリケーションを可能にするための設定変更
- バイナリログの有効化
- バイナリログ保持期間の設定
- ストリームで利用するユーザーの用意(専用ユーザーを指定したほうが望ましい)
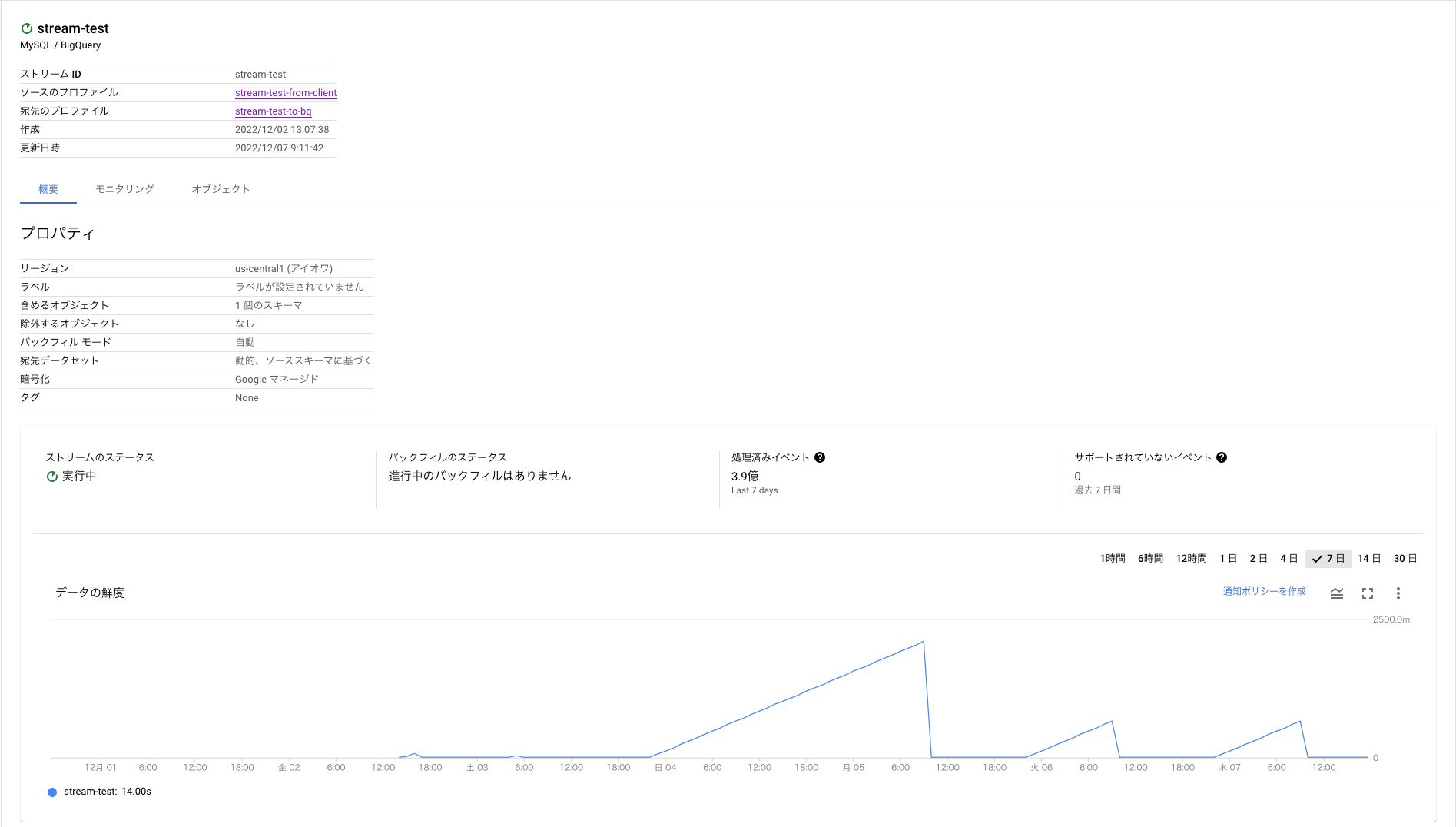
これらの設定を完了させると、以下のようにストリームが開始されて処理された内容を確認することができます。
各オブジェクトごとに状況を確認することもできます。
正確に計測できたわけではないのですが、全部で500GB程度のデータが3時間程度で移行完了しました。
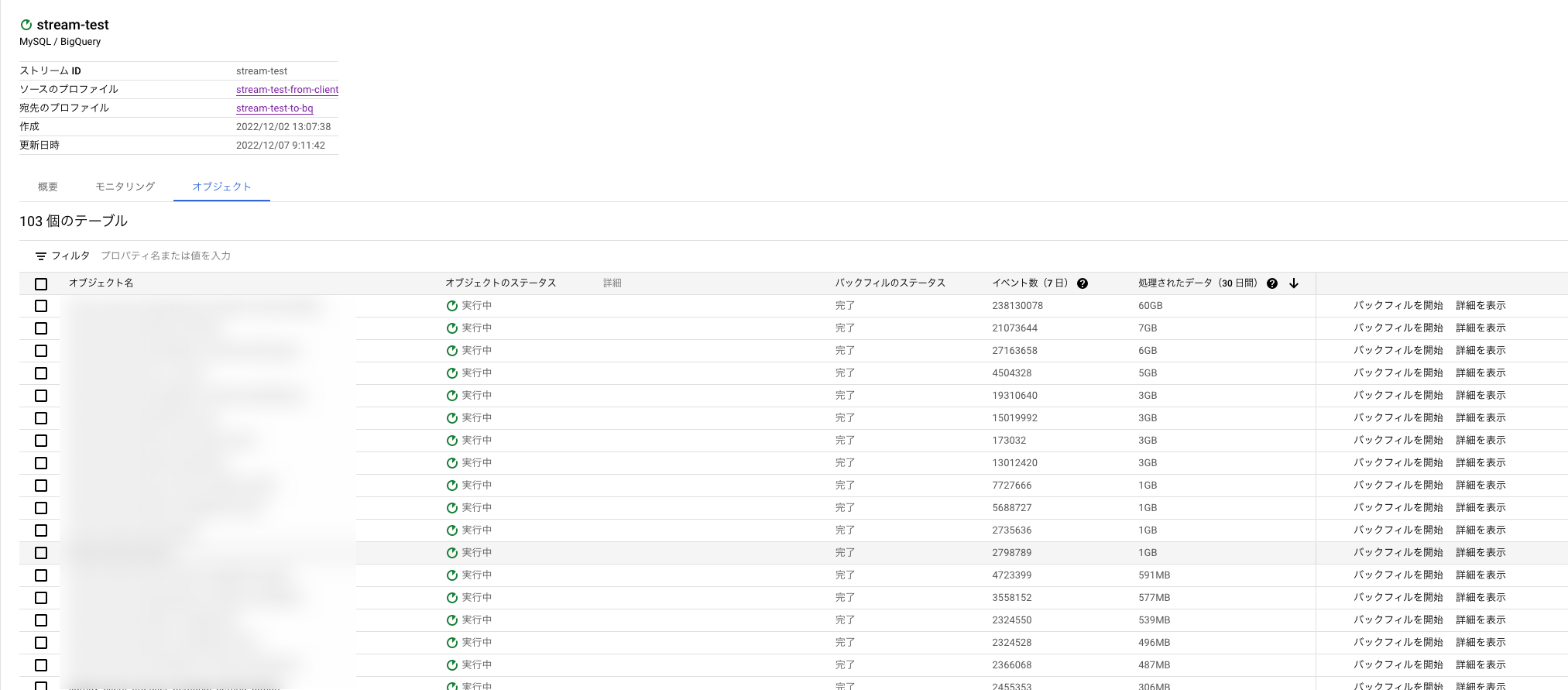
他にもストリーミングの頻度を指定したり、バックフィル(過去データの流し込み)をオブジェクトごとに手動で実行できる(負荷を考慮して実行できる)など細かい設定も可能で、サービスの運用面を想定した活用が可能です。
今後の展望
まずは「将来的に想定している構成」を目指しながら、必要な技術に拡げていくことになると思います。
特にデータガバナンスの観点は大事だと技術顧問からもアドバイスを受けており、データ基盤の活用が進むほど重要性が増す類のものだと考えているため、この辺りを早い段階からケアすることを想定しています。
また、技術を拡げていくときにはこの記事に記載したようなシンプルさを心がける話は忘れずにいたいと思います。
最後に
そしてデータの可視化の先にはデータの分析も当然想定される未来があるため、ここの領域に足を踏み入れるのも面白そうだと感じています。
これからデータの活用ニーズは高まっていくはずなので、一緒に働くデータサイエンティストの方もいたらいいな〜と思っていたりもします。
データサイエンティストに限らず、弊社では多方面の職種で採用活動中ですので、興味ある方は以下の採用ピッチ資料やオウンドメディアをチェックしてください!
明日は期待と信頼の高い @picadar が記事を書きます。
お楽しみに!👋