前記事で解説したプログラムは,
3.add(2).add(10)
というプログラムに対して
{ value: 15, add: [Function: add] }
という結果を出力しました.
前回最後に解説した「字句解析」では,test/single.txtの内容を次のような「字句(トークン)」という単位に分けました.
0:[number] 3
1:[dot] .
2:[identifier] add
3:[lpar] (
4:[number] 2
5:[rpar] )
6:[dot] .
7:[identifier] add
8:[lpar] (
9:[number] 1
10:[rpar] )
↑の出力では字句を[種類] 内容という形式で表示しています.これらはプログラムからはTokenオブジェクトでアクセスします。「種類」をtype,「内容」をtextというプロパティでアクセスできます.なお、Tokenオブジェクトはlib/TreeTypes.ts内で定義されています。
構文解析
今回は,前回のプログラム(index.ts)の★Bで出力されている↓の部分を生成しているプログラムlang/MyParser.tsについてみて行きます.
Call {
left:
MemberAccess {
left: Call { left: [MemberAccess], args: [Array] },
name: Identifier { text: 'add' } },
args: [ NumberLiteral { value: 1 } ] }
import Parser from '../lib/Parser';
import { ValueExpression, NumberLiteral, Identifier, Call, MemberAccess } from './Expressions';
import { Token } from '../lib/TreeTypes';
export default function MyParser(tokens:Token[]){
const parser:Parser=new Parser(tokens);//★E
function parse() {
try {
const res=parseExpression();
if (!parser.eot()) throw parser.parseError("Not EOF");
return res;
} catch (e) {
if (parser.maxParseError) throw parser.maxParseError;
else throw e;
}
}
function parseExpression():ValueExpression {
return parseApplication();
}
function parseElement():ValueExpression {
if (parser.nextTokenIs("number")) return parseNumberLiteral();
if (parser.nextTokenIs("identifier")) return parseIdentifier();
throw parser.parseError();
}
function parseApplication():ValueExpression {
let res=parseElement();
while(true) {
if (parser.nextTokenIs("lpar")) {
parser.readToken("lpar");
const args:ValueExpression[]=[parseExpression()];
parser.readToken("rpar");
res=new Call(res, args);
} else if (parser.nextTokenIs("dot")) {
parser.readToken("dot");
const ident=parseIdentifier();
res=new MemberAccess(res, ident);
} else break;
}
return res;
}
function parseNumberLiteral():NumberLiteral {
const t=parser.readToken("number");
return new NumberLiteral(parseFloat(t.text));
}
function parseIdentifier():Identifier {
const t=parser.readToken("identifier");
return new Identifier(t.text);
}
return {parse};
}
Parserの作成
Parser(lib/Parser.ts)は構文解析を行うための基本的な機能を提供します.トークンの配列tokensを渡して作成します.
const parser:Parser=new Parser(tokens);//★E
Parserには次のメソッドがあります.
-
parser.eot()トークンの最後まで読み終わっていればtrue -
parser.nextTokenIs(type)次に読めるトークンの種類がtypeであればtrue.(トークンの最後まで読み終わっている場合はfalse) -
parser.readToken(type)次に読めるトークンの種類がtypeであればそのトークンを読み進め,そのトークンをTokenオブジェクトとして返す.トークンの種類がtypeでなければParseErrorを投げる -
parser.parseError(message?)ParseError(構文解析エラー)を投げる.
lang/MyParser.tsには,parse****という関数がいくつか定義されています.
parseExpression
parseExpressionは日本語にすると「式を構文解析する」という意味です.この連載で作る言語は,プログラム本体は1つの式で表されます(え,2つ以上の計算をしたかったらどうするの,という話はこの後詳しくやっていきます)
で、parseExpressionは今のところparseApplicationを呼んでいるだけなので、次へ。
parseApplication
Applicationと言っても、スマホアプリとかのアレとはあまり関係なくて、ここでは「適用」と訳してください。このネーミングがいいのかどうかは微妙です。
適用とはどういうことかというと、JavaScriptでおなじみの
object.x
という式における .x の部分が、objectに対して、.xという動作(プロパティxを読み出す)を「適用」しています。
また、
f(x)
という式は、fという関数オブジェクトに対して、(x)という動作((x)を引数として関数を呼び出す)を「適用」しています。
また、これらを組み合わせて
object.f(x)
という式もよく見かけますが、これは、objectに対して、.fという動作を「適用」して、それによって読み出された関数オブジェクトに対して(x)を「適用」する、というように、適用を複数回行う場合もあります。
先ほどから出ているこの式は
3.add(2).add(10)
3に対して、.add、(2)、.add、(10)を順に適用したことになります。
さて、parseApplicationの中身を見てみよう……と思いましたが、結構複雑なので、まずは先頭の3の部分に注目しましょう。
parseElement
式の先頭部分、3の部分は「要素(Element)」と呼んでいます。要素には3のような「数値定数(NumberLiteral)」と、aのような「識別子(Identifier)」があります。識別子を使ったコードは後の回で登場します。
function parseElement():ValueExpression {
if (parser.nextTokenIs("number")) return parseNumberLiteral();
if (parser.nextTokenIs("identifier")) return parseIdentifier();
throw parser.parseError();
}
ここの処理では、次に読もうとしているトークンの種類がnumberかidentiferであればそれぞれの処理に移動し、それ以外だったらエラー(構文解析エラー:ParseError)を投げます。
parseNumberLiteral
ここでは、数値定数のトークンを読み込み、「式」を表すオブジェクトの1つ、NumberLiteralオブジェクトを生成します。このオブジェクトの定義はlang/Expressions.tsにあります。
function parseNumberLiteral():NumberLiteral {
const t=parser.readToken("number");
return new NumberLiteral(parseFloat(t.text));
}
parseApplication
さて、parseApplicationを改めてみてみましょう。★Fで、先述の要素(Element)を解析しています。
function parseApplication():ValueExpression {
let res=parseElement();//★F
while(true) {
if (parser.nextTokenIs("lpar")) {//★G
parser.readToken("lpar");
const args:ValueExpression[]=[parseExpression()];
parser.readToken("rpar");
res=new Call(res, args);
} else if (parser.nextTokenIs("dot")) {//★H
parser.readToken("dot");
const ident=parseIdentifier();
res=new MemberAccess(res, ident);
} else break;
}
return res;
}
その後、次の処理をwhile(true) ... で繰り返していきます。
- ★G:次に読めるのが
((lpar)なら、-
(を読み - 「式」を読む(「式」は、最初に解説したparseExpressionを再帰呼び出しして解析)、読んだ結果を配列
argsに入れる1 -
)(rpar)を読む - これまで生成した式と
argsを使って、Callオブジェクトを生成
-
- ★H:次に読めるのが
.(dot)なら、-
.を読み - 識別子(Idenfifier)を読む
- これまで生成した式と識別子を使って、MemberAccessオブジェクトを生成
-
- それ以外のトークンが読めたら、繰り返しを終える
Call、MemberAccessは、NumberLiteralと同様lang/Expressions.tsに定義されている、式を表すオブジェクトです。
もう一度、index.tsの★Bの出力結果を確認すると、Callや、MemberAccessというオブジェクトが生成されているのがわかります。
Call {
left:
MemberAccess {
left: Call { left: [MemberAccess], args: [Array] },
name: Identifier { text: 'add' } },
args: [ NumberLiteral { value: 1 } ] }
理解度チェック
上の表示では、オブジェクトの階層が深くなると中身が表示できていません。表示を行っているのは、index.tsのrunメソッド内です。
function run(src:string) {
const t=MyTokenizer(src);
const tokens=t.tokenize();
tokens.forEach((token,i)=>console.log(`${i}:[${token.type}] ${token.text}`));
const p=MyParser(tokens);
const tree=p.parse();
console.log(tree); // ←ここ
//....(後略)
}
console.logの代わりにconsole.dirを使って、オブジェクトの中身をすべて表示してみましょう。
console.dir(tree, {depth:10});
次のように、test/single.txtの中身を書き換えて、表示がどのように変化するか確認してみましょう。(それぞれ、前に書いた中身を消してから書いてください。複数の式を書くとエラーになります)
33.add3.add(2)3.add(2).add3.add(2).add(10)3.add(2).add(10).add(20)3.add(2.add(10))
また、これらの表示を下のような図で表現してみましょう。このような図のことを、本連載では「構文木」と呼びます。下図は3.add(2)を構文木として表現したものです。
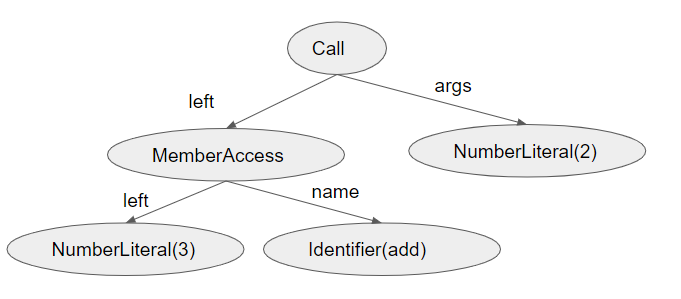
次回は、コードの生成と、それに必要な実行時ライブラリについてみて行きます。
-
この段階では、引数が1つしか使えません。しばらく引数が1つの関数しか出てこないので、必要になったら実装を追加します。 ↩