最近Googleからリリースされたテキスト埋め込みモデルEmbeddingGemma(ローカルで動作)が気になっていたので、日本語テキストに対してどんな感じなのか試してみました。
今回は世間でよく使われがちなMultilingual-E5-largeとRuri: Japanese General Text Embeddingsを比較対象としてモデルの振る舞いを観察してみます。
(定量的な評価はしていません。)
実行環境
- WSL2 Ubuntu 24.04
- Python 3.12
事前準備
今回はおなじみのLivedoorニュースのデータセットを使います。
# ライブラリのインストール
pip install -U pandas scikit-learn matplotlib fugashi sentencepiece unidic-lite
pip install -U sentence-transformers git+https://github.com/huggingface/transformers@v4.56.0-Embedding-Gemma-preview
# データのダウンロード
wget https://www.rondhuit.com/download/ldcc-20140209.tar.gz
# ライブラリのインポート
import tarfile
import re
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.metrics.pairwise import cosine_similarity
import matplotlib.pyplot as plt
import torch
from sentence_transformers import SentenceTransformer
データの整形
今回の分析対象は、簡単に各記事のタイトルとします。
Livedoorニュースデータには、各ニュース記事に対して9種類トピックとタイトル、本文などが付いていますが、そこからトピックとタイトルを抜き出して使います。
タイトルには【】で囲われたラベリングが付いていることがあり、それによりトピック分類に影響がありそうなので削除する処理も入れています。
# Livedoorニュースデータから記事のテキストを読み込む
with tarfile.open('ldcc-20140209.tar.gz', 'r:gz') as tar:
data = {
file.name: tar.extractfile(file).read().decode()
for file in tar if (
(file.name.count('/') == 2)
and file.name.split('/')[2].startswith(file.name.split('/')[1] + '-')
and file.name.split('/')[2].endswith('.txt')
)
}
# データを整形してDataFrame形式にする
data = pd.DataFrame([
{
'topic': filename.split('/')[1],
'filename': filename.split('/')[2],
'url': text.splitlines()[0],
'date': text.splitlines()[1],
'title': text.splitlines()[2],
'body': '\n'.join(text.splitlines()[3:]),
} for filename, text in data.items()
])
def remove_brackets(text: str) -> str:
'''
文字列から【】で囲まれた部分(括弧自体を含む)を削除
'''
pattern = r'【((.|\n)*?)】'
# 【】で囲まれた部分がなくなるまで、繰り返し置換を行う
while re.search(pattern, text):
text = re.sub(pattern, '', text)
return text.strip()
# タイトルからトピックを推察できるようなラベリングを削除(【】で囲われているもの)
data['title'] = data['title'].map(remove_brackets)
data = data[data['title'] != ''].reset_index(drop=True).copy()
可視化するときにトピック別で色を付けたいのでそれ用の辞書も作っておきます。
topic_color = {topic: f'C{i}' for i, topic in enumerate(data['topic'].unique())}
topic_color
{'topic-news': 'C0',
'sports-watch': 'C1',
'smax': 'C2',
'peachy': 'C3',
'movie-enter': 'C4',
'livedoor-homme': 'C5',
'kaden-channel': 'C6',
'it-life-hack': 'C7',
'dokujo-tsushin': 'C8'}
モデルの読み込み
コメントアウトのところを切り替えてモデルを変更します。
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model_id = 'google/embeddinggemma-300M'
# model_id = 'intfloat/multilingual-e5-large'
# model_id = 'cl-nagoya/ruri-large-v2'
model = SentenceTransformer(model_id).to(device=device)
ベクトル化
vectors = model.encode(data['title'])
# 可視化のためにPCAで2次元に変換
pca = PCA(n_components=2, random_state=0)
pca_vectors = pca.fit_transform(vectors)
可視化
plt.figure()
for topic, color in topic_color.items():
plt.scatter(
x=pca_vectors[data['topic'] == topic][:,0],
y=pca_vectors[data['topic'] == topic][:,1],
s=2,
color=color,
label=topic,
)
plt.title(model_id)
plt.grid()
plt.legend(fontsize=8)
plt.show()
plt.close()
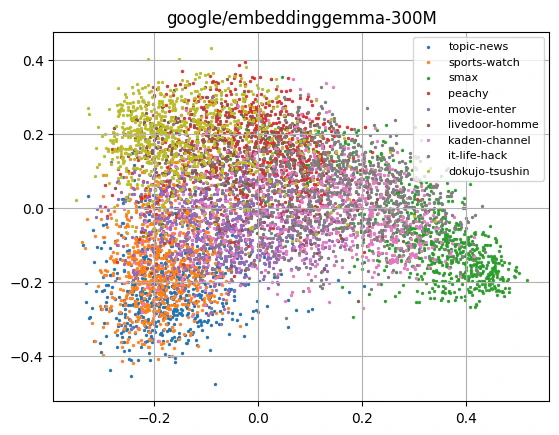
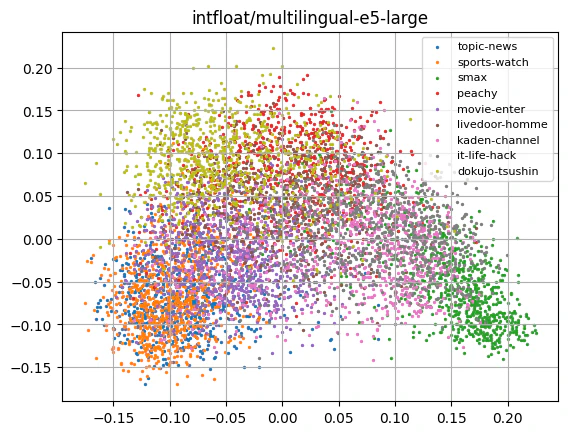
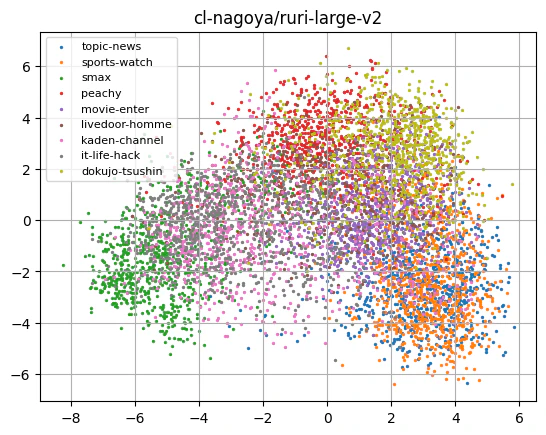
どれも似たような感じになるんですね。トピックのまとまり具合はどのモデルも大差ない気がします。
この中ではEmbeddingGemmaが一番topic-newsとsports-watchを分離できているような感じにも見えます。(多分。)
コサイン類似度での近辺となるテキストサンプル
データの中からサンプルとして「人気シリーズの新たなラインナップ! ニコンが「Nikon 1 J2」を発売」というタイトルに対して、コサイン類似度が上位となるタイトルを取ってきました。
for i, row in pd.DataFrame({
'topic': data['topic'],
'title': data['title'],
'cosine_similarity': cosine_similarity(vectors[[5530]], vectors)[0],
}).sort_values('cosine_similarity', ascending=False).head(5).reset_index(drop=True).iterrows():
print(i)
print('topic', row['topic'])
print('title', row['title'])
print('cosine_similarity', row['cosine_similarity'])
0
topic kaden-channel
title 人気シリーズの新たなラインナップ! ニコンが「Nikon 1 J2」を発売
cosine_similarity 1.000000238418579
1
topic kaden-channel
title 流行のミラーレスカメラがニコンからもついに!「Nikon 1 J1」「Nikon 1 V1」が発表
cosine_similarity 0.7450875043869019
2
topic kaden-channel
title 高性能な高品位ボディ! パナソニックがフラットタイプミラーレス一眼「LUMIX DMC−GX1」を発売
cosine_similarity 0.6137073636054993
3
topic kaden-channel
title 無線LAN搭載のミラーレス一眼! ソニーが「NEX-5R」を海外発表
cosine_similarity 0.6017153263092041
4
topic kaden-channel
title ニコン、光学14倍ズームを搭載した高倍率モデルのデジカメ「COOLPIX L610」を発売
cosine_similarity 0.600810706615448
0
topic kaden-channel
title 人気シリーズの新たなラインナップ! ニコンが「Nikon 1 J2」を発売
cosine_similarity 1.0
1
topic kaden-channel
title 流行のミラーレスカメラがニコンからもついに!「Nikon 1 J1」「Nikon 1 V1」が発表
cosine_similarity 0.908493161201477
2
topic kaden-channel
title キヤノン、高画質と小型軽量化を両立したミラーレスカメラ「EOS M」を発売
cosine_similarity 0.8679439425468445
3
topic kaden-channel
title ニコン、Android搭載Wi−Fi対応デジカメなどCOOLPIX Sシリーズ3機種を発売
cosine_similarity 0.8662406206130981
4
topic kaden-channel
title 今年は満を持して新製品ラッシュ?ソニーからデジタル一眼カメラ“α”(アルファ)シリーズ発売
cosine_similarity 0.8631361722946167
0
topic kaden-channel
title 人気シリーズの新たなラインナップ! ニコンが「Nikon 1 J2」を発売
cosine_similarity 1.000000238418579
1
topic kaden-channel
title 流行のミラーレスカメラがニコンからもついに!「Nikon 1 J1」「Nikon 1 V1」が発表
cosine_similarity 0.8967389464378357
2
topic kaden-channel
title 今年は満を持して新製品ラッシュ?ソニーからデジタル一眼カメラ“α”(アルファ)シリーズ発売
cosine_similarity 0.8277535438537598
3
topic kaden-channel
title デジタル一眼レフカメラは現在コスパ重視の傾向、来年は新製品ラッシュの予感!
cosine_similarity 0.8242273926734924
4
topic kaden-channel
title ニコン、光学14倍ズームを搭載した高倍率モデルのデジカメ「COOLPIX L610」を発売
cosine_similarity 0.8228214979171753
どのモデルも違和感ないものが類似度上位にきましたね。
違いとしましては類似度の値でしょうか。
類似度上位のものでもEmbeddingGemmaでは0.745とかである一方、E5では0.908、Ruriでは0.896となりました。
EmbeddingGemmaは他と比べて日本語テキスト同士の距離は大きくなるということでしょうか。
ここからは推測ですが、EmbeddingGemmaは他と比べて文章同士の細かい違いをより表現しやすいモデルなのかなと思いました。
まとめ
簡単な日本語に対しては基本どれ使っても表現力に大きな差はないのかなと思います。
ただ、パラメータ数はEmbeddingGemmaが303M、E5が560M、Ruriが337MとEmbeddingGemmaが最も軽量となっています。
出力次元数もEmbeddingGemmaが768、E5が1024、Ruriが1024と、EmbeddingGemmaが最も小さく、扱いやすいのではと思います。
つまりEmbeddingGemmaを使うと良いと思います。