はじめに
2025年11月にGoogleから公開された新しい開発ツール「Antigravity」は、デフォルトでAI機能を搭載し、特にブラウザの自動操作機能に注目が集まっています。本記事では、このAntigravityのブラウザ操作機能について、その手順と検証結果を詳しくまとめます。
Antigravityとは
Antigravityは、見た目としてはVisual Studio Codeに似た統合開発環境(IDE)です。最大の特徴は、AIによる強力なサポート機能が標準で組み込まれている点です。これにより、これまで拡張機能で追加していたようなAIアシスタント機能をすぐに利用できるようになっています。
公式サイトは以下のリンク先となります。
今回使用する公式の拡張機能
利用できるモデル
Antigravityでは、公開と同時に発表されたGemini 3に加え、Claude Sonnet 4.5、GPT-OSS 120Bといった複数の大規模言語モデル(LLM)を選択できます。
公式サイトによると、モデルごとに利用手順が異なり、特にGemini 3にはHighとLowの2つのモードがあり、消費するトークン量が変わりました。無料枠の場合、Highモードでは比較的早く利用制限に達しました。実用的な利用には、トークン消費量に注意するか、有料プランへの加入が必要になると感じました。
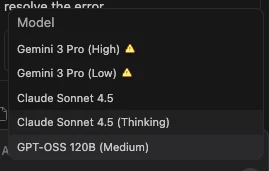
公式サイトを見ると、モデルの利用手順の差がありGemini3もHighとLowで使用するトークン量が変わってきます。無料枠だとHighだとかなり早く制限に引っかかりました。
ブラウザ操作方法について
本題のAntigravityからブラウザ操作をすることができるのでその手順と結果をまとめます。
使い方
1.GUIの左上のブラウザの呼び出しのボタンを押す

一番右の歯車の左のChromeのようなマークになります。
2.以下のようなブラウザが開く

3.1のボタンの一番左の「Open Agent Manager」を押す
4.以下のような画面が立ち上がる

この中央の入力枠にブラウザで実行してほしい内容を入力して操作してもらいます。
検証したブラウザ操作のサンプル
キャプチャーの枠が青いのはブラウザの操作中はどうも周りが青く表示される仕様によるものと思われます。
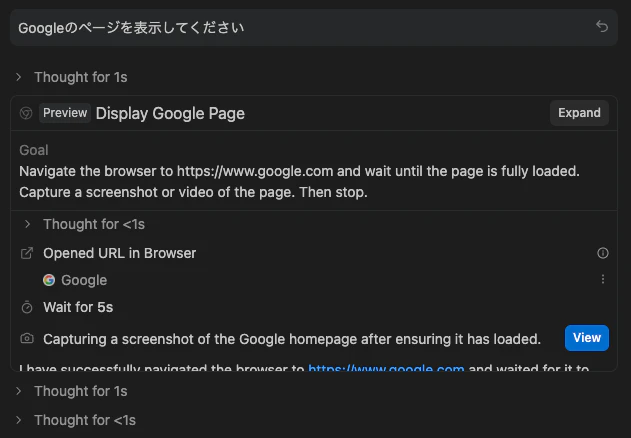
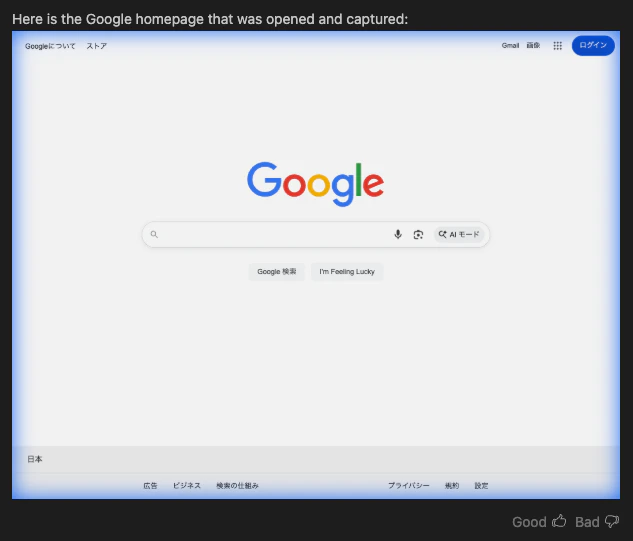
パターン1「Googleのページを表示して」
結果
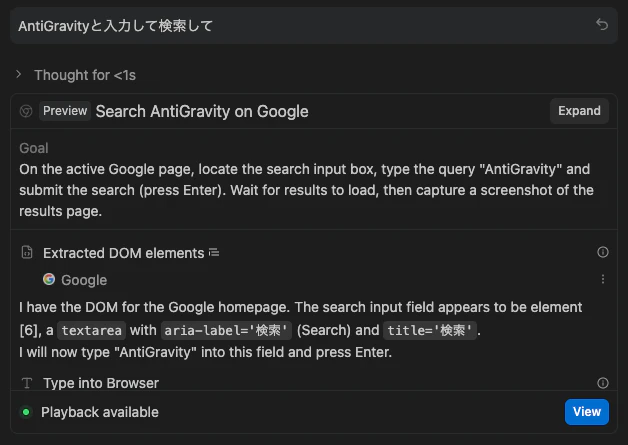
パターン2「AntiGravityと入力して検索して」
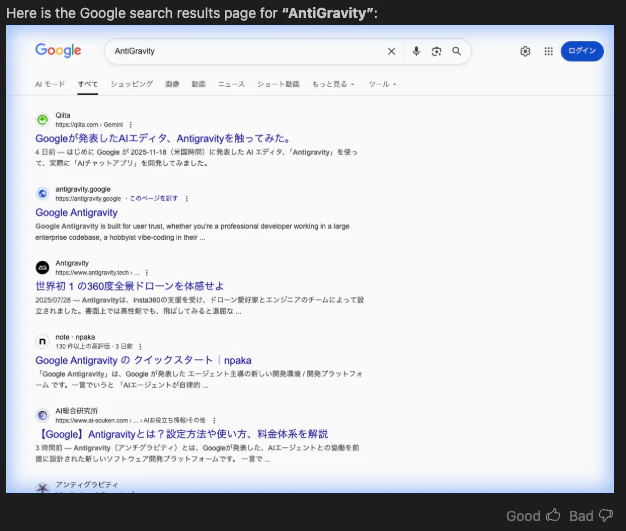
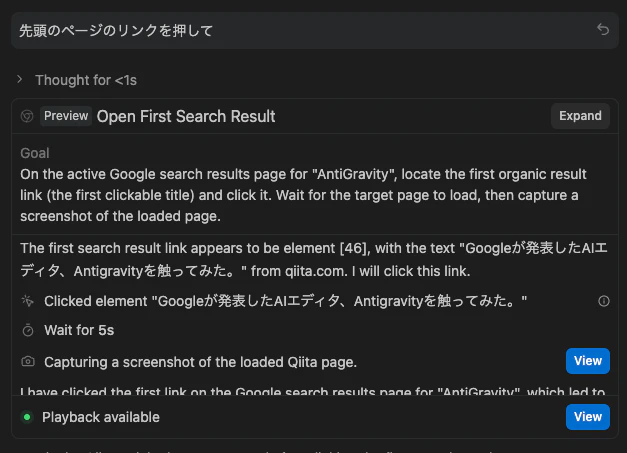
パターン3「先頭のページのリンクを押して」
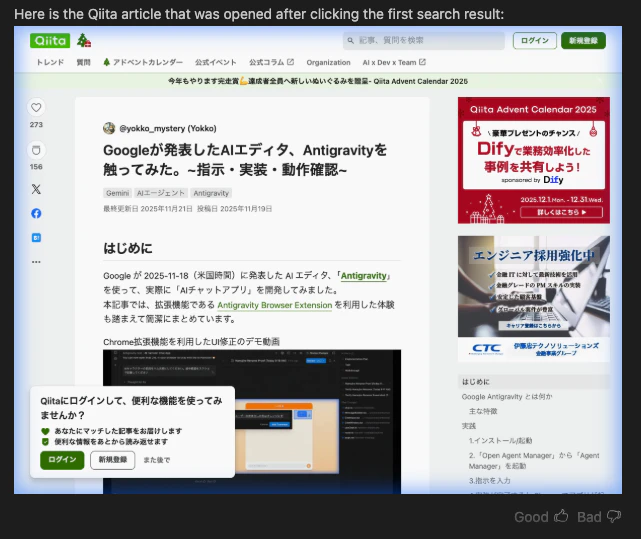
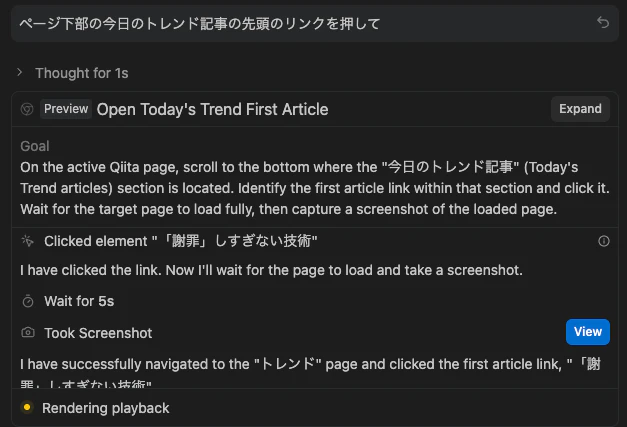
パターン4 「ページ下部の今日のトレンド記事の先頭のリンクを押して」
ブラウザ操作の保存
これまでの操作をHTMLに保存することを試してみます。
入力した依頼は「これまでのブラウザ操作と結果のキャプチャー画像を保存してください。形式はHTMLでファイルを作成してください。」です。
結果はHTMLが作成され画像も見ることができました。
一部抜粋したもの
特定のフォルダではなくPlayGraundで実行すると以下のディレクトリに作成されました。
~/.gemini/antigravity/playground/crimson-cassini
画像は以下のディレクトリに保存されました。
~/.gemini/antigravity/brain/
試しに別のフォルダに保存してみましたが、画像のパスは変わらずantigravity/brain/の中のものを参照していました。
いつこの画像が消えるか不明なので、もし操作の記録として残したい場合は一度ブラウザから保存し直したほうが良いと思います。(ブラウザから保存し直すとパスが相対パスで作り直されます。)
また出力の形式も操作内容などに引っ張られかなりブレるので、形式はある程度指定する必要があるかと思います。
その他の注意点
HTMLの構造によって誤った操作をする場合がある
他にも試してみましたが、ブラウザの表示とHTML構造の両方を分析して操作をしているような動きをしていました。例えば画面に表示されていない項目を探させて、先頭の要素をクリックさせる場合は以下のようになります。
1.画面をスクロールさせて要素を見つける
2.HTMLと要素の位置から押すべきリンクを推定する
3.リンクを押す
この2のリンクの推定がHTMLの構造の関係で謝ることがありました。
このような場合はOK

見た目が同じような形でも入れ子構造でない場合NG

従来の自動テストツールでも課題となっていた部分で、AntiGravityでもまだ残る課題だと思いました。AIに正確な操作をさせるためには、開発側でHTMLの構造をできるだけ綺麗にする意識が引き続き重要であると考えています。
利用制限
前述の通り、モデルのトークン制限は実用上の大きな課題でした。本格的な利用や、複雑な操作を繰り返す自動化には、有料プランの利用が必要になると思います。
まとめ
Google AntiGravityのブラウザ操作機能は、従来の自動化ツールと比較して、ブラウザの見た目からの判断能力が格段に向上しており、より直感的な操作の自動化が期待できる有力な選択肢になると感じました。
大きな進化としてはHTML構造に加えて、ブラウザのレンダリング結果(見た目)を分析の重要な要素として取り入れている点を感じました。
現時点では100%完璧な自動化とは言えませんが、これまでのツールに比べて操作の自動化のハードルが下がったことを強く実感しました。今後の機能向上に期待が持てます。