tl;dr
- 筋トレ推定アプリを作った
- Qoreはリザーバコンピューティングというアルゴリズムを使っている
- スマホで取得できる加速度データから時系列データの分類タスクを行った
- 精度はかなりいい
- テストデータで、精度 99.6%
- これで筋肉エンジニアになれる っはず
戦略
- スマホ(iphone)で加速度センサーデータを収集
- x, y, z軸3つの成分をもつ時系列データが手に入る
- 腕立て、腹筋、スクワット、腹筋ローラーの4種目の筋トレで学習
- スマホだけで、どんな筋トレをしたかがわかる
データの収集
-
スマホを、ズボンのポケットに入れたまま筋トレする
- 今回は、いずれの筋トレにおいても、同じ向きでスマホをポッケに入れる
- 違う向きにしたりすると、より推定は難しくなると思われる
-
加速度測定には、以下のアプリを使わせて頂いた
- 「加速度・ジャイロスコープ・磁力センサーロガー」
- 測定間隔は 0.1 sec
-
行った筋トレ回数
- 腕立て:21回(~35 sec)
- 腹筋:20回 (~66 sec)
- スクワット:20回 (~51 sec)
- 腹筋ローラ(座りコロ):12回 (~50 sec)
-
データ量を増やすためには、もっと筋トレしなければならない
- いずれマッチョになれるはず
-
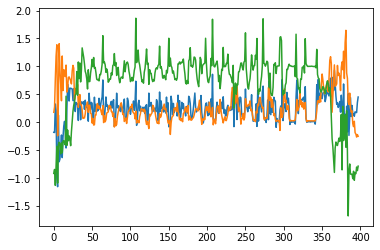
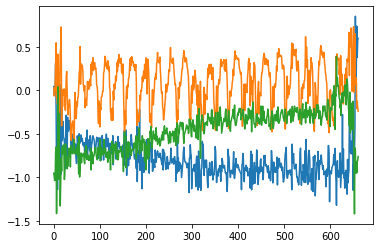
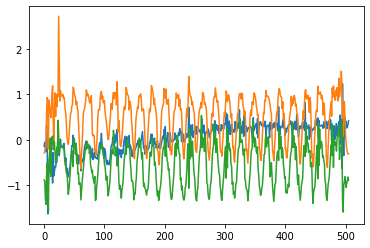
以下が、実際に測定できた加速度の生データ
-
腕立て伏せ
- 腹筋
- スクワット
- 腹筋ローラー(座りコロ)
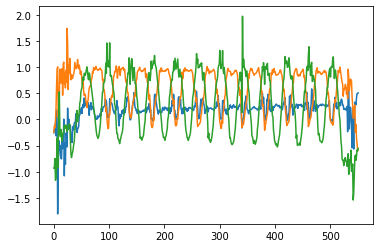
- 周期的になっていて、思ったよりキレイなデータが取れた
データの前処理
- QoreSDKが提供する、qore_sdk.utils を使ってみた
-
sliding_window
- 時系列を複数の小時系列に分割する
- APIにデータを渡すために必要な前処理である(3次元にする)
-
under_sample
- クラス当たりのサンプル数を揃える
- 実測したデータには、データ数の偏りがあった
- 普通、機械学習では、データ数の大きいデータに精度が引っ張られてしまうので、一番数が少ないクラスのデータ数に合わせた
-
sliding_window
- なお学習の際には、入力データのサイズに制限がある
- N*T*V < 150,000 && N*T < 10,000
- 最初、各アルファベットが指す意味がわからなかったが(もと生物物理系なので、カノニカルアンサンブルか!?とも思ったが)、以下だと思われる
- N: 小時系列データ数
- T: 小時系列の長さ(time?)
- V: 特徴量の数(今回の場合は、x, y, zの加速度3個)
学習と推論
- 学習と推論は、サンプルコードとまるっきり同じ
- 以下で、アカウント情報を設定
client = WebQoreClient(username=username,
password=password,
endpoint=endpoint)
- 以下で学習
res = client.classifier_train(X=X_train, Y=y_train)
print(res)
# {'res': 'ok', 'train_time': 7.2200915813446045}
- 学習は、7.2秒ほどで終わりました
- 結構早い
- テスト(推論)
res = client.classifier_test(X=X_test, Y=y_test)
print(res)
{'accuracy': 0.9964285714285714, 'f1': 0.9964301018846474, 'res': 'ok'}
- 精度は、0.9964
- 高い!
線形回帰、簡単な深層学習と比較
- これもサンプルコードのままです
- 線形回帰
- 学習時間:0.28547000885009766[sec]
- 精度: 0.9964285714285714
- MLP (Using Sklearn)
- 学習時間: 0.7626857757568359[sec]
- 精度: 0.9928571428571429
- 両者とも、わずかにQoreSDKより低いが、依然精度高い
- 問題が簡単過ぎたか?
使ってみた感想
- SDKはシンプルで使いやすかった
- 精度は高かったが、線形回帰とMLPでも十分な精度が出てしまった
- 問題が簡単過ぎた可能性がある
- もっと難しい推定タスクを試してみたい
- 今回、試せなかったqore_sdk.featurizerを使うとどうなるか検証してみたい(時間があれば)
以下、調べたことや整理したこと
Qoreのアルゴリズム
以下の記事(アドベントカレンダー1日目)に、簡単な解説が載っている。
リザーバコンピューティングの世界 ~Qoreとともに~ - Qiita
リザーバコンピューティングを応用し、いくつか手を加えたものとなっています。
独自に改良を重ね、リザーバ内部はもちろん、前処理と後処理にも独自の仕組みを開発することで、小さなリザーバサイズでも高精度なモデルを実現
とのことらしい。
下記論文がベースになってるっぽい?
Van der Sande, Guy & Brunner, Daniel & Soriano, Miguel. (2017). Advances in photonic reservoir computing. Nanophotonics. 6. 561-576. 10.1515/nanoph-2016-0132.
時間があるときに読んでみたい。
具体的な手順のコード
以下のレポジトリに、jupyter notebookを公開しました。
手順に関しては、READMEとノートブックのスクリプトをご覧ください。
GitHub - hnishi/muscle_QoreSDK_AdvCal2019
QoreSDKでできること
-
classification 分類タスク
-
regression 回帰タスク
-
時系列の周波数分解による特徴抽出(使った場合と使わない場合で比較したい)
-
時系列を複数の小時系列に分割(使いやすかった)
-
ラベルの数合わせをする関数(使いやすかった)
-
せっかくなので、QureSDKの機能をフルに使いたいと思った
-
変化点検知や異常検知ができるようになってほしい
公式ドキュメントリンク
advent repo
GitHub - qcore-info/advent-calendar-2019: 深層学習以外の機械学習と応用技術 by QuantumCore Advent Calendar 2019
QoreSDK doc
QoreSDK 0.1.0 documentation
2019/12/22 追記
Featurizer を使うと、精度がさらに上がった
class 数 40 になるように、周波数分解による特徴抽出を行う。
n_filters = 40
featurizer = Featurizer(n_filters)
X = featurizer.featurize(X, axis=2)
テストデータに対する QoreSDK 精度が以下
acc= 1.0
f1= 1.0
elapsed_time:52.20956110954285[sec]
精度 1 という結果。
なお、逆に、ロジスティック回帰と MLP では、Featurizer を使う前より精度が下がった。
===LogisticRegression(Using Sklearn)===
elapsed_time:0.2480778694152832[sec]
acc= 0.6291666666666667
f1= 0.630372638509498
===MLP(Using Sklearn)===
elapsed_time:8.673331499099731[sec]
acc= 0.95
f1= 0.9502859082452324
筋トレをしていない状態を追加
筋トレをしていない状態を、分類タスクのクラスに追加した。
(昼食の準備をしているところを、コントロールとしてデータ収集を行った。)
この場合も、精度は 1 となった。
作業に使ったノートブックはこちら。
https://github.com/hnishi/muscle_QoreSDK_AdvCal2019/blob/master/muscle_QoreSDK_v2.ipynb
新規に取得したデータで検証
学習の時に使ったのとは別のデータセットを、腹筋ローラーで作成。
このデータを使って推論を行った。
作業に使ったノートブックはこちら。
https://github.com/hnishi/muscle_QoreSDK_AdvCal2019/blob/master/muscle_QoreSDK_v2.ipynb
結果、この検証データに対する精度は以下
- QoreSDK
- acc= 0.6855791962174941
- f1= 0.8134642356241235
- LogisticRegression(Using Sklearn)
- acc= 0.20094562647754138
- f1= 0.3346456692913386
- MLP(Using Sklearn)
- acc= 0.27423167848699764
- f1= 0.43042671614100186
QoreSDK で約 7 割の正解率となった。
もっと精度をあげるためには、筋トレのそれぞれの種目に対して、様々なパターンの学習データを拡充して学習させる必要がありそう。