はじめに
Chainerが"Chainer v7はChainerの最後のメジャーリリースとなる予定"と発表し,"研究開発に使用するフレームワークをPyTorchへ順次移行"することを発表しました[1].
それにともない,QiitaでもChainer ⇒ PyTorch移行を試してみた[2],Chainer PyTorch同盟 VS TensorFlow(Keras)[3],pyTorchでCNNsを徹底解説[4]など多数の記事が上がってきています.
本記事は,MNISTを使用して,CNNを例に書き方を比較します.
注意事項
ChainerのTrainerは使用しません.
PytorchのSequentialは使用しません.
Pytorchのインストールは,Pytorch公式の通りです.
使用する環境に合わせて選択すると,コマンドができあがります.

使用したバージョン
次のバージョンを使用しました.
python 3.6.10
numpy 1.18.1
chainer 7.1.0
cupy-cuda101 7.1.1
pytorch 1.4.0
cudatoolkit 10.1.243
torchvision 0.5.0
import関係
import関係を比較していきます.
import numpy as np
import chainer
import chainer.links as L
import chainer.functions as F
from chainer import optimizers
from chainer import Chain, datasets
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
ChainerとPytorchの関係は次の表のようになっています.
| Chainer | Pytorch | 内容 |
|---|---|---|
| import chainer | import torch | コア部分 |
| import chainer.links as L | import torch.nn as nn | ネットワーク関係 |
| import chainer.functions as F | import torch.nn.functional as F | 関数関係 |
| from chainer import optimizers | import torch.optim as optim | 最適化関数関係 |
| from chainer import Chain, datasets | from torchvision import datasets, transforms | データベースや他 |
ネットワークの構築
ここでは,Chainerと比較するためにPytorchのSequentialやModuleListは使いません.
LeNet[5]に似た形で書いてみます.
class CNN(Chain):
def __init__(self):
super(CNN, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(1, 6, 5)
self.conv2 = L.Convolution2D(6, 16, 5)
self.fc1 = L.Linear(256, 120)
self.fc2 = L.Linear(120, 64)
self.fc3 = L.Linear(64, 10)
def forward(self, x):
x = F.max_pooling_2d(F.relu(self.conv1(x)), 2)
x = F.max_pooling_2d(F.relu(self.conv2(x)), 2)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*4*4, 120)
self.fc2 = nn.Linear(120, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), 2)
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
ほぼ同じであることが上より見て取れると思います.注意が必要な点は,Pytorchでは,Convolutionのあとにフルコネクトを行う場合,明示的に記述する必要があります.コード上のx = torch.flatten(x, 1)の部分です.
この書き方は,
x = x.view(x.size(0), -1)
でも
x = x.reshape(x.size(0), -1)
でも同じ意味になります.
Convolution
ChainerもPytorchも頭から,入力チャネル数,出力チャネル数,カーネルサイズとなっています.
ストライドとパディングのデフォルト値は,どちらもstride=1,padding=0です.
- Chainer
Convolution2D(self, in_channels, out_channels, ksize=None, stride=1, pad=0, nobias=False, initialW=None, initial_bias=None, *, dilate=1, groups=1)
- Pytorch
Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
Linear
Chainer・Pytorchどちらも,入力チャネル数,出力チャネル数です.
- Chainer
Linear(in_size: Optional[int], out_size: Optional[int] = None, nobias: bool = False, initialW: Union[chainer.types.AbstractInitializer, numpy.generic, bytes, str, memoryview, numbers.Number, numpy.ndarray, None] = None, initial_bias: Union[chainer.types.AbstractInitializer, numpy.generic, bytes, str, memoryview, numbers.Number, numpy.ndarray, None] = None)
- Pytorch
Linear(in_features, out_features, bias=True)
Conv→Linear(Convolutionの出力サイズ)
Chainerでは,自身で計算せず自動計算してくれます.
例えば,次のように書きます.
self.conv2 = L.Convolution2D(None, 16, 5)
self.fc1 = L.Linear(None, 120)
しかし,Pytorchでは自動計算が実装されていないので,計算して書く必要があります。
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*4*4, 120)
計算方法は,公式サイトでも紹介されています.
入力サイズ$(H_i , W_i)$,カーネルサイズ,padding,strideから出力サイズ$(H_o , W_o)$が求められます.

他には,定番のConvolutional Neural Networkをゼロから理解するがあります.このサイトはアニメーション付きで紹介しています.
データの読み込み
MNISTのデータを使用します.
# Load the MNIST dataset
def DataSet(train_batch_size, test_batch_size):
# データの読み込み(ローカルになければダウンロード)
TrainDataset, TestDataset = chainer.datasets.get_mnist(ndim=3)
# データの分割
split_at = int(len(TrainDataset) * 0.8)
train, valid = datasets.split_dataset_random(TrainDataset, split_at)
train_data_size = len(train)
valid_data_size = len(valid)
# Iteratorにバッチサイズでセット
train_iter = chainer.iterators.SerialIterator(train, batch_size=train_batch_size)
valid_iter = chainer.iterators.SerialIterator(valid, batch_size=train_batch_size)
test_iter = chainer.iterators.SerialIterator(TestDataset, batch_size=test_batch_size, repeat=False, shuffle=False)
return train_data_size, valid_data_size, train_iter, valid_iter, test_iter
# Load the MNIST datasets
def DataSet(train_batch_size, test_batch_size):
# データの読み込み(ローカルになければダウンロード)
trans = transforms.ToTensor()
Train_DataSet = datasets.MNIST('~/dataset/MINST/', train=True, download=True, transform=trans)
Test_DataSet = datasets.MNIST('~/dataset/MINST/', train=False, download=True, transform=trans)
# データの分割
n_samples = len(Train_DataSet) # 全データ数
train_size = int(n_samples * 0.8) # 学習データは全データの8割
val_size = n_samples - train_size # 評価データは残り
train_dataset, valid_dataset = torch.utils.data.random_split(Train_DataSet, [train_size, val_size])
# DataLoaderにバッチサイズでセット
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=train_batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=train_batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(Test_DataSet, batch_size=test_batch_size, shuffle=False)
return train_loader, valid_loader, test_loader
データの読み込み
Chainerでは,chainer.datasets.get_mnist()で読み込めます.ndim=3でshpaeが$(1,28,28)$になります.
Pytorchでは, datasets.MNIST('root', train=True, download=True, transform=trans)で読み込めます.train=Trueでtraining.ptからデータセットを作成し,他はtest.ptから作成します.download=Trueでネットからデータセットをダウンロードし,ルートディレクトリに配置します。データセットが既にダウンロードされている場合,再度ダウンロードされることはないです.transform=transは設定された関数で変換したものを返します.
今回は,trans = transforms.ToTensor()と設定しました.
この関数は,PIL画像または$[0,255]$の範囲のnumpy.ndarray(H x W x C)を$[0.0, 1.0]$の範囲の形状(C x H x W)のtorch.FloatTensorに変換します。
データの分割
Chainerは,train, valid = datasets.split_dataset_random(TrainDataset, split_at)で学習用と検証用に分割できます.split_atで学習に使用する枚数を決めます.
Pytorchは,train_dataset, valid_dataset = torch.utils.data.random_split(Train_DataSet, [train_size, val_size])で学習用と検証用に分割できます.train_sizeは学習に使用する枚数を,val_sizeは検証に使用する枚数を決めます.
Iterator,DataLoaderの設定
Chainerでは,SerialIteratorにデータ,バッチサイズなどを設定します.
train_iter = chainer.iterators.SerialIterator(train, batch_size=train_batch_size)
valid_iter = chainer.iterators.SerialIterator(valid, batch_size=train_batch_size)
test_iter = chainer.iterators.SerialIterator(TestDataset, batch_size=test_batch_size, repeat=False, shuffle=False)
Pytorchでは,DataLoaderにデータ,バッチサイズなどを設定します.
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=train_batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=train_batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(Test_DataSet, batch_size=test_batch_size, shuffle=False)
ネットワーク生成と最適化関数の設定,GPUの使用設定
# ネットワークの生成
model = CNN()
# GPUが使えればGPUを使う
if chainer.cuda.available:
device = chainer.get_device(0)
print("use gpu")
else:
device = -1
print("use cpu")
model.to_device(device)
# 最適化関数の設定
opt = optimizers.Adam()
opt.setup(model)
# GPUが使えれば使う
device = "cuda" if torch.cuda.is_available() else "cpu"
print("use "+device)
# ネットワークの生成
model = CNN().to(device)
# 最適化関数の設定
optimizer = optim.Adam(model.parameters())
最適化関数の設定
Chainer,Pytorchどちらも同じような設定方法です.
使用できる関数の一部を紹介します.
| Chainer | Pytorch |
|---|---|
| chainer.optimizers.AdaDelta(rho=0.95, eps=1e-06) | torch.optim.Adadelta(lr=1.0, rho=0.9, eps=1e-06, weight_decay=0) |
| chainer.optimizers.AdaGrad(lr=0.001, eps=1e-08) | torch.optim.Adagrad(lr=0.01, lr_decay=0, weight_decay=0, initial_accumulator_value=0, eps=1e-10) |
| chainer.optimizers.Adam(alpha=0.001, beta1=0.9, beta2=0.999, eps=1e-08, eta=1.0, weight_decay_rate=0, amsgrad=False, adabound=False, final_lr=0.1, gamma=0.001) | torch.optim.Adam(lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False) |
| chainer.optimizers.AdamW(alpha=0.001, beta1=0.9, beta2=0.999, eps=1e-08, eta=1.0, weight_decay_rate=0) | torch.optim.AdamW(lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0.01, amsgrad=False) |
| chainer.optimizers.RMSprop(lr=0.01, alpha=0.99, eps=1e-08, eps_inside_sqrt=False) | torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False) |
| chainer.optimizers.SGD(lr=0.01) | torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False) |
学習
epoch_num = 10
train_loss_log = []
train_acc_log = []
val_loss_log = []
val_acc_log = []
print("epoch:",epoch_num,"batch size:",train_batch_size)
print("start train.")
import time
for epoch in range(epoch_num):
start_time = time.perf_counter()
avg_train_loss, avg_train_acc = TrainBatch(train_data_size, train_batch_size, train_loader, device, model, opt)
end_time = time.perf_counter()
s_val_time = time.perf_counter()
avg_val_loss, avg_val_acc = ValidBatch(valid_data_size, train_batch_size, val_loader, device, model)
e_val_time = time.perf_counter()
proc_time = end_time - start_time
val_time = e_val_time - s_val_time
print("Epoch[{}/{}], train loss: {loss:.4f}, valid loss: {val_loss:.4f}, valid acc: {val_acc:.4f}, "\
"train time: {proc_time:.4f}sec, valid time: {val_time:.4f}sec"\
.format(epoch+1, epoch_num, loss=avg_train_loss, val_loss=avg_val_loss, val_acc=avg_val_acc,
proc_time=proc_time, val_time=val_time))
train_loss_log.append(avg_train_loss)
train_acc_log.append(avg_train_acc)
val_loss_log.append(avg_val_loss)
val_acc_log.append(avg_val_acc)
epoch_num = 10
train_loss_log = []
train_acc_log = []
val_loss_log = []
val_acc_log = []
# 誤差関数の設定
loss_func = nn.CrossEntropyLoss()
print("epoch: ",epoch_num," batch size:", train_batch_size)
print("start train.")
import time
for epoch in range(epoch_num):
start_time = time.perf_counter()
avg_train_loss, avg_train_acc = TrainBatch(train_data_size, train_loader, device, model, loss_func, optimizer)
end_time = time.perf_counter()
s_val_time = time.perf_counter()
avg_val_loss, avg_val_acc = ValBatch(val_data_size, val_loader, device, model, loss_func)
e_val_time = time.perf_counter()
proc_time = end_time - start_time
val_time = e_val_time - s_val_time
print("Epoch[{}/{}], train loss: {loss:.4f}, valid loss: {val_loss:.4f}, valid acc: {val_acc:.4f}, "\
"train time: {proc_time:.4f}sec, valid time: {val_time:.4f}sec"\
.format(epoch+1, epoch_num, loss=avg_train_loss, val_loss=avg_val_loss, val_acc=avg_val_acc,
proc_time=proc_time, val_time=val_time))
train_loss_log.append(avg_train_loss)
train_acc_log.append(avg_train_acc)
val_loss_log.append(avg_val_loss)
val_acc_log.append(avg_val_acc)
ChainerもPytorchもどちらもミニバッチ学習のループです.
1エポックの間に,学習→検証をしています.
学習と検証の部分を紹介します.
Train
def TrainBatch(train_data_size, batchsize, train_iter, device, model, opt):
train_loss = 0
train_acc = 0
cnt = 0
for i in range(0, train_data_size, batchsize):
train_batch = train_iter.next()
x, t = chainer.dataset.concat_examples(train_batch, device)
model.cleargrads()
y = model(x)
loss = F.softmax_cross_entropy(y, t)
train_loss += loss.array
acc = F.accuracy(y, t)
train_acc += acc.array
loss.backward()
opt.update()
cnt += 1
avg_train_loss = train_loss / train_data_size
avg_train_acc = train_acc / cnt
return chainer.cuda.to_cpu(avg_train_loss), chainer.cuda.to_cpu(avg_train_acc)
def TrainBatch(train_data_size, train_loader, device, model, loss_func, optimizer):
train_loss = 0
train_acc = 0
cnt = 0
model.train()
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
out = model(data)
loss = loss_func(out, target)
train_loss += loss.item()
#_, pre = torch.max(out, 1)
pre = out.max(1)[1]
train_acc += (pre == target).sum().item()
cnt += target.size(0)
loss.backward()
optimizer.step()
avg_train_loss = train_loss / train_data_size
avg_train_acc = train_acc / cnt
return avg_train_loss, avg_train_acc
どちらもミニバッチを取り出して,ループを回しています.
気になるところは,誤差関数でしょうか.Pytorchでは,事前に関数を設定しておくのを勧めて?いるようです.
Chanierでは,chainer.functionsに誤差関数が定義されていますが,Pytorchでは,torch.nnにあります.(torch.nn.functionalにも同じ関数があるようですが,それぞれの特徴は未調査です)
※Pytorchでは,学習のときに,model.train()と宣言する必要があります.
Valid
def ValidBatch(valid_data_size, batchsize, valid_iter, device, model):
val_loss = 0
val_acc = 0
cnt = 0
for i in range(0, valid_data_size, batchsize):
valid_batch = valid_iter.next()
x, t = chainer.dataset.concat_examples(valid_batch, device)
y = model(x)
loss = F.softmax_cross_entropy(y, t)
val_loss += loss.array
acc = F.accuracy(y, t)
val_acc += acc.array
cnt += 1
avg_val_loss = val_loss / valid_data_size
avg_val_acc = val_acc / cnt
return chainer.cuda.to_cpu(avg_val_loss), chainer.cuda.to_cpu(avg_val_acc)
def ValBatch(val_data_size, val_loader, device, model, loss_func):
val_loss = 0
val_acc = 0
cnt = 0
model.eval()
with torch.no_grad(): # 必要のない計算を停止
for data, target in val_loader:
data, target = data.to(device), target.to(device)
out = model(data)
loss = loss_func(out, target)
val_loss += loss.item()
#_, pre = torch.max(out, 1)
pre = out.max(1)[1]
val_acc += (pre == target).sum().item()
cnt += target.size(0)
avg_val_loss = val_loss / val_data_size
avg_val_acc = val_acc / cnt
return avg_val_loss, avg_val_acc
どちらもミニバッチを取り出して,ループを回しています.学習と基本同じです.
※Pytorchでは,検証のときに,model.eval()と宣言する必要があります.
比較実験
使用したマシンは,以下の通りです.
- Intel Core i5-6600K 3.50GHz
- RAM 16.0GB
- Windows10 Home 64bit
- GeForce GTX 1070 (ビルドバージョン 441.66)
学習速度
Chainer
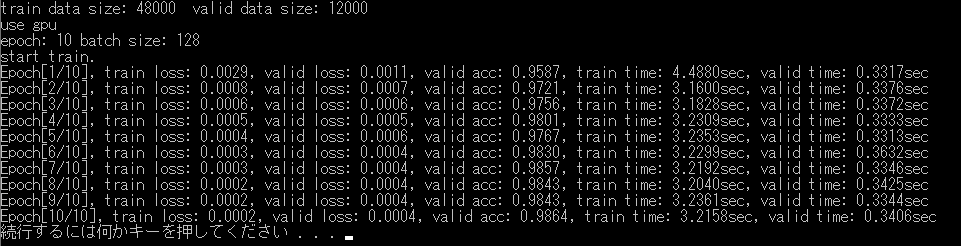
およそ3秒で学習が進んでいます.
Pytorch
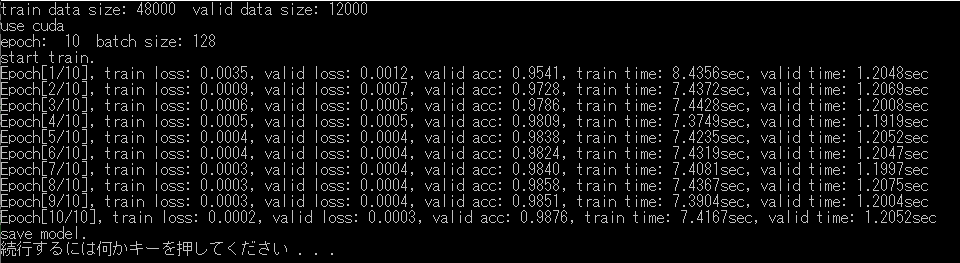
およそ7秒で学習が進んでいます.
以上より,若干Chainerの方が速いです.
誤差と正解率
Chainer
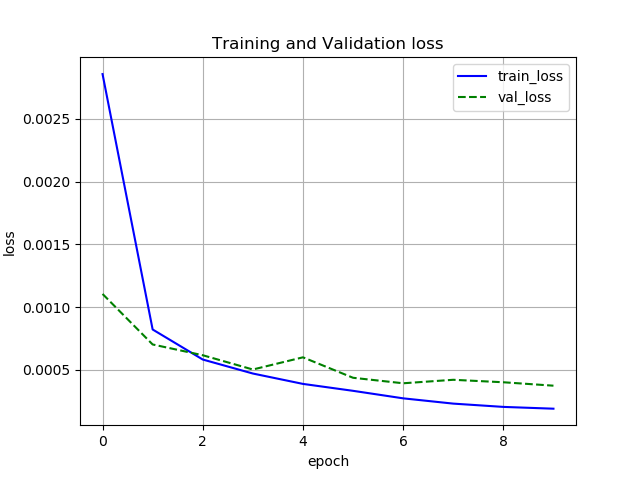
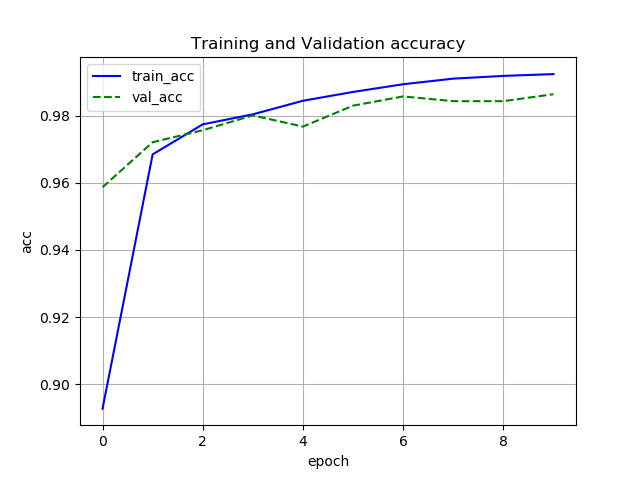
Pytorch
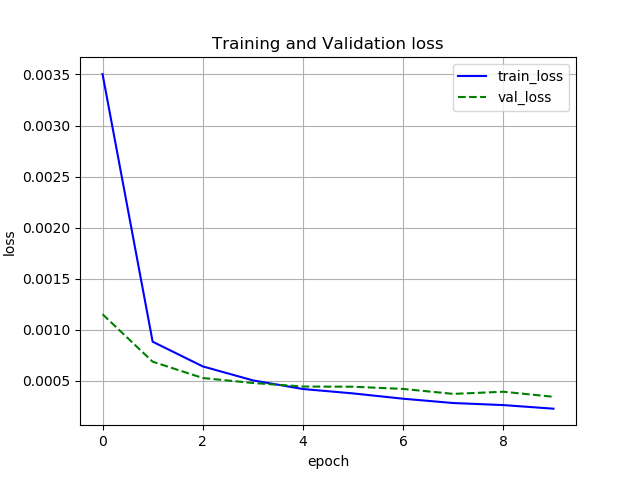
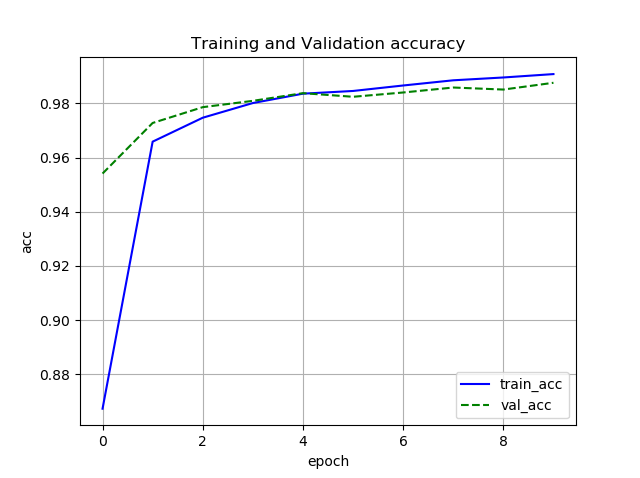
どちらも収束は同じような感じです.
結論
Chainerを書いていた人は,Pytorchにスムースに移行できると思います.
今後,Pytorch関連の記事はより増えていくと思いますので,よりPytorchを使用する人は増えるのではないでしょうか.
今後は,torch.nnとtorch.nn.functionalで動きがどう変わるのか調べてみます.
おまけ
モデルの保存と読み込み
torch.save(model.state_dict(), "mymodel.ckpt")で,「mymodel.ckpt」の名前で保存できます.
mymodel.load_state_dict(torch.load("mymodel.ckpt"))```で読み込みができます.
Pytorchで書いたコードの全体像を張っておきます.
```python:pytorch
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from matplotlib import pyplot as plt
import pandas as pd
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*4*4, 120)
self.fc2 = nn.Linear(120, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), 2)
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# data
def DataSet(train_batch_size, test_batch_size):
trans = transforms.ToTensor()
Train_DataSet = datasets.MNIST('~/dataset/MINST/', train=True, download=True, transform=trans)
Test_DataSet = datasets.MNIST('~/dataset/MINST/', train=False, download=True, transform=trans)
# データの分割
n_samples = len(Train_DataSet) # 全データ数
train_size = int(n_samples * 0.8) # 学習データは全データの8割
val_size = n_samples - train_size # 評価データは残り
train_dataset, valid_dataset = torch.utils.data.random_split(Train_DataSet, [train_size, val_size])
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=train_batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=train_batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(Test_DataSet, batch_size=test_batch_size, shuffle=False)
return train_loader, valid_loader, test_loader
def TrainBatch(train_data_size, train_loader, device, model, loss_func, optimizer):
train_loss = 0
train_acc = 0
cnt = 0
model.train()
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
out = model(data)
loss = loss_func(out, target)
train_loss += loss.item()
#_, pre = torch.max(out, 1)
pre = out.max(1)[1]
train_acc += (pre == target).sum().item()
cnt += target.size(0)
loss.backward()
optimizer.step()
avg_train_loss = train_loss / train_data_size
avg_train_acc = train_acc / cnt
return avg_train_loss, avg_train_acc
def ValBatch(val_data_size, val_loader, device, model, loss_func):
val_loss = 0
val_acc = 0
cnt = 0
model.eval()
with torch.no_grad(): # 必要のない計算を停止
for data, target in val_loader:
data, target = data.to(device), target.to(device)
out = model(data)
loss = loss_func(out, target)
val_loss += loss.item()
#_, pre = torch.max(out, 1)
pre = out.max(1)[1]
val_acc += (pre == target).sum().item()
cnt += target.size(0)
avg_val_loss = val_loss / val_data_size
avg_val_acc = val_acc / cnt
return avg_val_loss, avg_val_acc
def ViewGraph(epoch_num, train_loss_log, train_acc_log, val_loss_log, val_acc_log):
plt.figure()
plt.plot(range(epoch_num), train_loss_log, color="blue", linestyle="-", label="train_loss")
plt.plot(range(epoch_num), val_loss_log, color="green", linestyle="--", label="val_loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("loss")
plt.title("Training and Validation loss")
plt.grid()
plt.figure()
plt.plot(range(epoch_num), train_acc_log, color="blue", linestyle="-", label="train_acc")
plt.plot(range(epoch_num), val_acc_log, color="green", linestyle="--", label="val_acc")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("acc")
plt.title("Training and Validation accuracy")
plt.grid()
plt.show()
def main():
#データの読み込み
train_batch_size = 128
test_batch_size = 1000
train_loader, val_loader, test_loader = DataSet(train_batch_size=train_batch_size, test_batch_size=test_batch_size)
train_data_size = len(train_loader.dataset)
val_data_size = len(val_loader.dataset)
print("train data size:",train_data_size," valid data size:", val_data_size)
# select device
device = "cuda" if torch.cuda.is_available() else "cpu"
print("use "+device)
model = CNN().to(device)
#print(model)
# optimizing
loss_func = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
epoch_num = 10
train_loss_log = []
train_acc_log = []
val_loss_log = []
val_acc_log = []
print("epoch: ",epoch_num," batch size:", train_batch_size)
print("start train.")
import time
for epoch in range(epoch_num):
start_time = time.perf_counter()
avg_train_loss, avg_train_acc = TrainBatch(train_data_size, train_loader, device, model, loss_func, optimizer)
end_time = time.perf_counter()
s_val_time = time.perf_counter()
avg_val_loss, avg_val_acc = ValBatch(val_data_size, val_loader, device, model, loss_func)
e_val_time = time.perf_counter()
proc_time = end_time - start_time
val_time = e_val_time - s_val_time
print("Epoch[{}/{}], train loss: {loss:.4f}, valid loss: {val_loss:.4f}, valid acc: {val_acc:.4f}, "\
"train time: {proc_time:.4f}sec, valid time: {val_time:.4f}sec"\
.format(epoch+1, epoch_num, loss=avg_train_loss, val_loss=avg_val_loss, val_acc=avg_val_acc,
proc_time=proc_time, val_time=val_time))
train_loss_log.append(avg_train_loss)
train_acc_log.append(avg_train_acc)
val_loss_log.append(avg_val_loss)
val_acc_log.append(avg_val_acc)
# モデルの保存
torch.save(model.state_dict(), "mymodel.ckpt")
print("save model.")
ViewGraph(epoch_num, train_loss_log, train_acc_log, val_loss_log, val_acc_log)
if __name__ == '__main__':
main()
紹介したコードをGitHubにアップしました.ご参考までに.
MINST_chainer.py
MNIST_pytorch.py
参考
[1] Chainer/CuPy v7のリリースと今後の開発体制について, https://chainer.org/announcement/2019/12/05/released-v7-ja.html
[2] Chainer ⇒ PyTorch移行を試してみた, https://qiita.com/samacoba/items/63b2741270ab6ced1429
[3] Chainer PyTorch同盟 VS TensorFlow(Keras), https://qiita.com/akiaki_0723/items/43a5c03cbdd06812ef9b
[4] pyTorchでCNNsを徹底解説, https://qiita.com/mathlive/items/8e1f9a8467fff8dfd03c
[5] Yann LeCun, et al., "Gradient-Based Learing Applied to Document Recognition," http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf