2019/9/29 投稿
2019/11/8 やや見やすく編集(主観)
2020/2/1 SGDの解説Link追加
2020/8/17 図がないとよくわからないと思い図を追加
2020/9/21 コメントより補足説明追加と図の更新
2022/7/2 図の更新、新たな図の追加、文章修正
2022/11/6 畳み込みの映像更新
0. この記事の対象者
- Pythonを触ったことがあり,実行環境が整っている人
- PyTorchをある程度触ったことがある人
- PyTorchによるCNNの実装でより深くコード理解がしたい人
- この長くて大変恐縮な記事を読み切る根気がある人
1. はじめに
昨今では機械学習に対してPython言語による研究が主である.
なぜならPythonにはデータ分析や計算を高速で行うためのライブラリ(moduleと呼ばれる)がたくさん存在するからだ.
その中でも今回はPyTorchと呼ばれるmoduleを使用し,Convolutional Neural Networks(CNN)のexampleコードを徹底的に解説していく.
全体のコードは最後に貼っておくので,説明が煩わしい方はそちらから見てほしい.
ただしこの記事は自身のメモのようなもので,あくまで参考程度にしてほしいということと,簡潔に言うために正確には間違った表現や言い回しをしている場合があるが,そこはどうかご了承していただきたい.
2. 事前知識
Pythonには他プログラミング言語同様,「型」というものが定義した変数には割り当てられており,中でも「list型」,「tuple型」,「dictionary型」が初心者にとっての最初の壁としてよく出てくるように思う.
さらに,moduleとして「numpy」というものもあり,このnumpyが持つ特殊な型,「ndarray型」もよく出てくる.
ここではあえて説明はしないが,わからない人は是非検索をしてそれぞれをしっかり理解しておいてほしい.
3. PyTorchのインストール
PyTorchを初めて使用する場合,PythonにはPyTorchがまだインストールされていないためコマンドプロンプトなどでのインストールをしなければならない.
下記のLinkに飛び,ページの下の方にある「QUICK START LOCALLY」で自身の環境のものを選択し,現れたコマンドをcmd等で入力する(コマンドをコピペして実行で良いはず).
さらに,今回は「torchvision」というmoduleも使用するためこちらもインストールしておいてほしい.
(大抵は公式サイトにあるコマンドをそのまま実行すればインストールされる)
4. CNNとは
CNN(Convolutional Neural Networks) は直訳すると畳み込みニューラルネットワークというもので,入力されるdataに関して畳み込みという処理を複数回行うことでその入力data(例えば画像)から特徴を抽出していく.
特にこのCNNは画像の特徴を抽出するのに非常に優れており,昨今では様々な画像を用いた機械学習に用いられている.
畳み込みについて説明すると,以下の図のようなことが行われている.
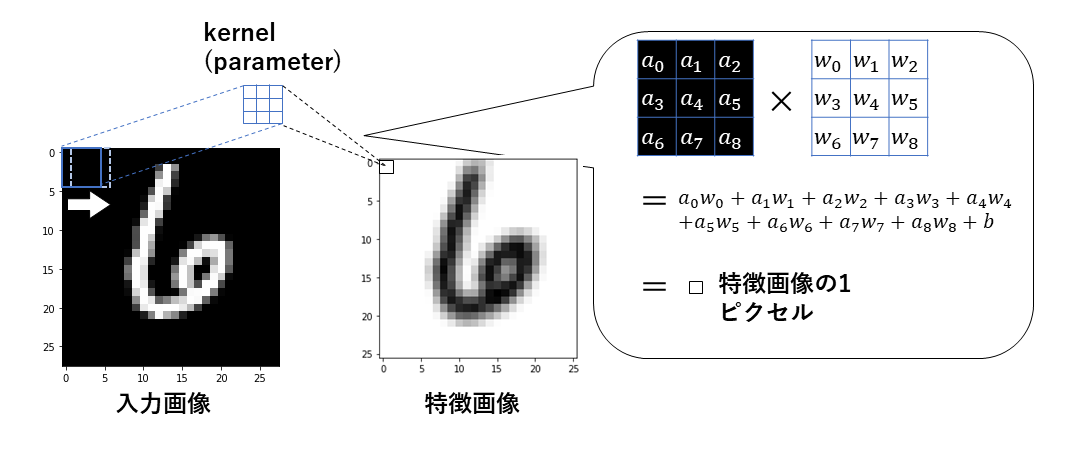
kernel (parameter) と書いてある青い枠が畳み込みをするためのパラメータである.
このkernelが入力画像の左上の領域と重なり,重なった部分の要素ごとに掛け算をしてそれらをすべて足したものが特徴画像の1ピクセルとなる.
その計算の詳細を吹き出し内に書いている.
そして次の1ピクセルを計算する際は入力画像の左上の領域が右に1ピクセルだけスライドして同じ計算をする(白の矢印).
これが入力画像の一番右まで行くと今度は一番左に戻って下に1ピクセルだけスライドし,同じことが繰り返される.
こうして特徴画像が出来上がるのだ.
畳み込みをしている様子をアニメーションで作ってみたので参考にしてほしい.
左図が入力画像で,左図の赤い枠内の3x3ピクセルがカーネルである.
右図が出力の特徴量で,1ピクセルごと出力されているのがわかる.
(この動画はmanimというpythonライブラリを使っており、これを作るPythonプログラムは要望があればここに追記する.)
畳み込みの途中経過を切り出したのが下の図である
このように3x3の重なった部分との演算で右図の1ピクセルを出力し,右にスライドする(白い矢印).
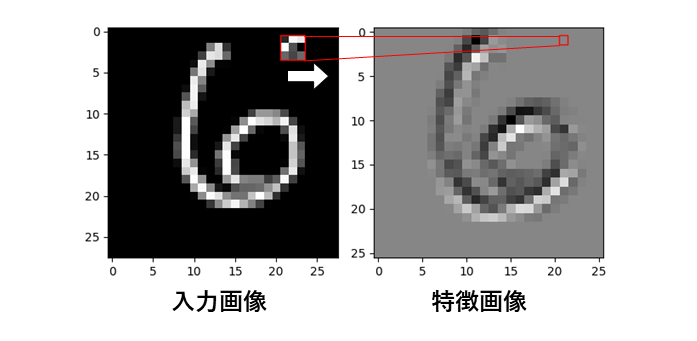
ここで見るように特徴画像のサイズがやや小さくなっていることに注意する(28x28から26x26へ).
どれだけサイズが小さくなるのはカーネルのサイズ(今回は3x3)により変わり,以下のlinkのページ下の方の「Shape」から手計算で求めることができる.
畳み込み後の画像サイズ
5. 今回の問題設定
今回はMNISTと呼ばれる手書き数字の白黒画像を用いて説明を行う.
以下がMNISTの画像である.

サイズは28x28ピクセルで,0~9の数字をもつ10クラスで用意されている.
これを使って分類問題(Classification) と呼ばれる問題を解くこととする.
この問題は1つの画像を入力してそれが何のクラスか(何の数字か)をあてる問題である.
ちなみに画像は以下のように各ピクセルごとに値をもつため,今回は28x28=784個の値を持った画像を入力する.

値が0ほど黒く,値が大きいほど白くなる.
6. PyTorchによるCNN実装
6-1. PyTorchに用意されている特殊な型
numpyにはndarrayという型があるようにPyTorchには「tensor型」という型が存在する.
ndarray型のように行列計算などができ,互いにかなり似ているのだが,tensor型はGPUを使用できるという点で機械学習に優れている.
なぜなら機械学習はかなりの計算量が必要なため計算速度が早いGPUを使用するからだ.
ただし,機械学習においてグラフの出力や画像処理などでnumpyも重要な役割を持つ.
そのためndarrayとtensorを交互に行き来できるようにしておくことがとても大切である.
tensor型の操作や説明は下記Linkより参照していただきたい.
PyTorchのtensor型とは
6-2. PyTorchのimport
ここからはコマンドプロンプト等ではなくPythonファイルに書き込んでいく.
下記のコードを書くことでmoduleの使用をする.
import torch
import torchvision
ついでにnumpyもimportしておく.
import numpy
6-3. Datasetの取得
PyTorchのtorchvision moduleには主要なDatasetがすでに用意されており,たった数行のコードでDatasetのダウンロードから前処理までを可能とする.
結論から言うと3行のコードでDatasetの運用が可能となり,ステップごとに言えば,
- transformsによる前処理の定義
- Datasetsによる前処理&ダウンロード
- DataloaderによるDatasetの使用
という流れになる.
ここでは簡単に解説するがそれぞれのステップについて詳しく知りたい場合は以下のLinkを参照してほしい.
PyTorchのtransforms,Datasets,Dataloaderの説明と自作Datasetの作成と使用
6-3-1. transformsによる前処理の定義
以下に前処理の定義を示す.
trans = torchvision.transforms.ToTensor()
この1行は,これから取得するDatasetの中身がndarray型のデータ集合であるため,前処理でtensor型にしたい.
そのためこのtransという変数をndarrayからtensorへと変換する関数のようなものにした(本当はtransはクラスインスタンスであるが気にしない).
もう少し詳しく言うと,以下のようにこのtransを使用でき,
a = trans(ndarrayのdata)
ndarrayのdataを各画像のピクセル値(輝度)を [0,1]の範囲にしつつtensor型に変換し,変数aに渡している.
ここで例えばtensor変換だけでなくそのあとに正規化をしたい場合は以下のようにする.
trans = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.5,), (0.5,))])
torchvision.transforms.Composeは引数で渡されたlist型の[~~~~,~~~~,...]というのを先頭から順に実行していくものである.
そのためlist内の前処理の順番には十分注意する.
こうすることでtransという変数はTensor変換と正規化を一気にしてくれるハイブリッドな変数になった.
その他にもたくさんのtransformsがあり,それらは以下のLinkより参照してほしい.
torchvision.transforms 公式サイト
6-3-2. Datasetsによる前処理&ダウンロード
以下にダウンロードを示す.
trainset = torchvision.datasets.MNIST(root = 'path', train = True, download = True, transform = trans)
まずは引数の説明をしていく.
-
root
Datasetを参照(または保存)するディレクトリを「path」の部分に指定する.
そのディレクトリに取得したいDatasetが存在すればダウンロードせずにそれを使用する. -
train
Training用のdataを取得するかどうかを選択する.
FalseにすればTest用のdataを取得するが,この2つの違いはdata数の違いと思ってくれて良い. -
download
rootで参照したディレクトリにDatasetがない場合ダウンロードするかどうかを決めることができる. -
transform
定義した前処理を渡す.
こうすることでDataset内のdataを参照する時にその前処理を自動で行ってくれる.
今回はMNISTを使用したが,他の使用できるDatasetは下記のLinkより参照して使用して欲しい.
その時のコードも大体同じである.
torchvision.datasets 公式サイト
取得したtrainsetをそのまま出力してみると以下のようなDatasetの内容が表示されるはずだ.
print(trainset)
------'''以下出力結果'''--------
Dataset MNIST
Number of datapoints: 60000
Root location: rootで指定したpathが出るはず
Split: Train
StandardTransform
Transform: Compose(
ToTensor()
Normalize(mean=(0.5,), std=(0.5,))
)
これだけ見るとDatasetなのにどうやってdataを見ているの?となるが,dataの参照は以下のようにすれば良い.
print(trainset[0])
------'''以下出力結果'''--------
(tensor([data内容]), そのdataに対応する正解label)
これでDatasetの0番目のdataを参照できる.
実は実際にDatasetのdataを使用するときも配列の参照のようにdataを参照している.
6-3-3. DataloaderによるDatasetの使用
DataloaderによるDatasetの使用は下記のコードで実行する.
trainloader = torch.utils.data.DataLoader(trainset, batch_size = 100, shuffle = True, num_workers = 2)
まずは引数の説明をしていく.
-
第1引数
先程取得したDatasetを入れる. -
batch_size
1回のtrainingまたはtest時に一気に何個のdataを使用するかを選択.
datasetの全data数を割り切れる値にしなければならない.← 割り切れなくてもよかった.ただし,最後のbatch数が少なくなる. -
shuffle
dataの参照の仕方をランダムにする. -
num_workers
並列処理をするかどうかで,2以上の場合その値だけ並行処理をする.
コメントで寄せられたので記述.Windows OSを使用している場合,num_worksが2以上だとエラーが起こることがあるらしい.
エラーが起こる場合はnum_works=1や0とするとよい.
ちなみに,取得したtrainloaderを出力しても以下のようなオブジェクトタイプしか表示されない.
print(trainloader)
------'''以下出力結果'''--------
<torch.utils.data.dataloader.DataLoader object at 0x7fdffa11ada0>
Datasetのように中身が見たい場合,配列の参照のようにするとエラーが起こる.
なぜならDataLoaderは配列ではなくiteratorというものを返しているためである.
無理やり中身を見ようとするならば以下のようにすれば良い.
for data,label in trainloader:
break
print(data)
print(label)
------'''以下出力結果'''--------
tensor([[data1], [data2],..., [data100]])
tensor([label1, label2,..., label100])
このように1回の取得でdataとlabelはバッチサイズ(今で言うと100)だけ取得され,もちろん各dataとlabelは対応しあっている.
図で見てみると
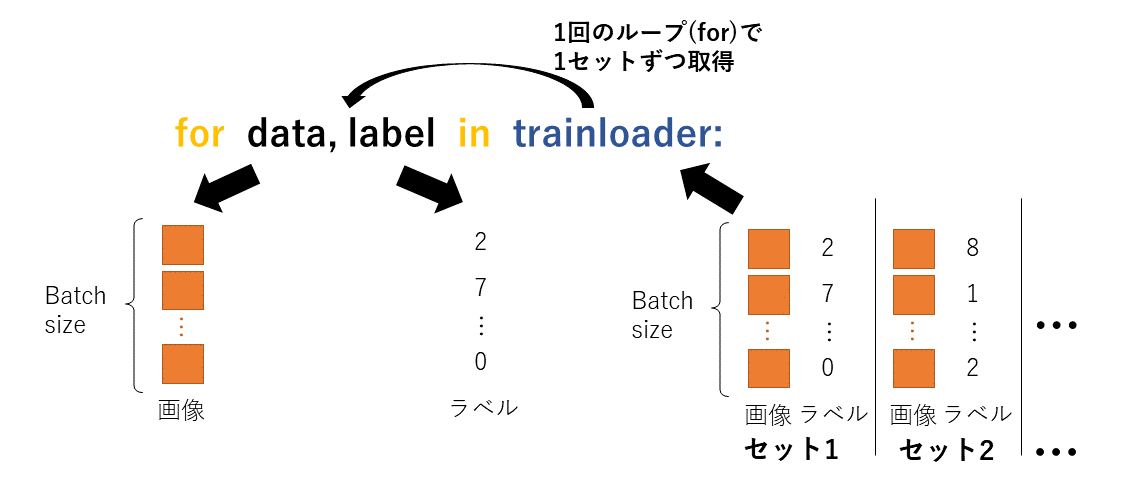
このようにtrainloaderは全dataと対応するlabelをBatch毎に分けてセットで持ち,その1セットを変数detaとlabelに渡している.
ただし,この確認は絶対に学習する前に同じプログラム内ではやらない方が良い.
なぜならtrainloaderはiteratorであるため今回呼び出したdataは全データを見きるまで二度と見られることがなくなってしまう.
(iteratorは最初のセット100個を取り出すと次回の呼び出しからは次のセット100個を取り出す)
つまりこの参照をしてしまった100個のdataは2周目に入るまで見られなくなってしまう.
そこに十分注意してほしい.
6-3-4. test用datasetの取得
training用のdataset取得がわかればtest用もほとんど同じである.
以下にコードを示す.
testset = torchvision.datasets.MNIST(root = '~/Documents/work/MNISTDataset/data', train = False, download = True, transform = trans)
testloader = torch.utils.data.DataLoader(testset, batch_size = 100, shuffle = False, num_workers = 2)
違う点とすればdatasetsの引数train=Falseであることと,dataloaderの引数shuffle=Falseとなっているところだけである.
shuffleがFalseなのはTestの時にはdataをランダムに取得する必要がないからである.
transformは同様のtransを使用する.
6-4. Networkの定義
今回はCNNを作成するが,作成にはいくつかの手法がある.
- 「nn.XXXXX」を用意したclassベースで作る
- 「nn.XXXXX」をnn.Seaquentialを使って作る
- torchvisionに用意されている既存のモデル(VGGやResNet)を使う
その中でも今回私は 「nn.XXXXX」を用意したclassベースで作る.
以下に簡単なCNNを作った.
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(2, stride=2)
self.conv1 = nn.Conv2d(1,16,3)
self.conv2 = nn.Conv2d(16,32,3)
self.fc1 = nn.Linear(32 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.pool(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool(x)
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
まず最初にtorch module内の「torch.nn」をimportする.
その際「as nn」と書くことで以降使用するときに「nn.XXXX」と書くだけで使用できるようになる.
続いて以下にnetworkの中身を上から順に説明していく.
6-4-1. classとしてNetworkを作成
Networkをclassとして作成する.
雛形で言えばこんな形になる.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
......
def forward(self, x):
......
以下各行の説明.
-
1行目
classの定義をする.
classの後の「Net」はただのclass名だから好きなもので良い.
その名前の後の「nn.Module」はこのclassがnn.Moduleというclassを継承していることを意味する.
なぜ継承するかというとnn.ModuleがNetworkを使用する上でパラメータ操作などの重要な機能を持つためである. -
2行目
「def __init__(self)」は初期化関数の定義で,コンストラクタなどと呼ばれる.
初めてclassを呼び出したときに,その実態をインスタンスと呼び,インスタンスが生成されたときにinitの中身が実行される. -
3行目
「super(Net, self).__init__()」は継承したnn.Moduleの初期化関数(nn.Moduleの中の__init__())を起動している.
super()の引数の「Net」はもちろん自身が定義したclass名である. -
最後の行
「def forward(self, x)」には実際のネットワークの処理を書いていく.
6-4-2. 初期化関数の定義
以下に初期化関数部分のみを再掲する.
def __init__(self):
super(Net, self).__init__()
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(2, stride=2)
self.conv1 = nn.Conv2d(1,16,3)
self.conv2 = nn.Conv2d(16,32,3)
self.fc1 = nn.Linear(32 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 10)
この中で定義した「self.xxxxx」という変数はclassを呼び出したインスタンスが保持する.
なので,convolutionやfully connectなどの学習に必要なパラメータを保持したいものなどをここに書いていく.
以下にコードの説明をする.
-
nn.ReLU()
活性化関数というもので,各層の後に必ずと言っていいほど使用される処理である.
種類は他にもあるが,最もよく使われているのがReLUである.
ReLUは正の値はそのままで,負の値は0になるように変換する. -
nn.MaxPool2d(2, stride=2)
poolingと呼ばれる特徴量をサンプリングして減らす処理である.
このパラメータの場合,データサイズが半分になるような処理をする(サイズの小数点以下は切り下げられる). -
nn.Conv2d(1,16,3)
convolution(畳み込み)の定義で,第1引数はその入力のチャネル数,第2引数は畳み込み後のチャネル数,第3引数は畳み込みをするための正方形フィルタ(カーネル)の1辺のサイズである.
最初の畳み込みの例でも言ったが畳み込み後の画像サイズは小さくなるため,畳み込みの例で紹介したlinkで計算しておく. -
nn.Conv2d(16,32,3)
2つ目のConvの定義で,基本は1つ目と同じように引数を設定する.
第1引数は入力のチャネル数になるが,1つ目のConvの出力が16channelなので,それに合わせる. -
nn.Linear(32 * 5 * 5, 120)
fully connectの定義で,第1引数は入力のサイズ(ただし入力は行列ではなくベクトルでなければならない),第2引数は出力後のベクトルサイズを示す.
この場合の第1引数の意味は入力ベクトルがベクトルになる前のdataでは32Channel × 5Height× 5Width(5×5の特徴画像が32枚)となっていたことがわかる.
この特徴画像が5x5になることはConvとPoolingによるサイズ縮小を手計算で求める必要がある.
どうやって特徴画像(行列の形)をベクトルにするかは6-4-3で説明する. -
nn.Linear(120, 10)
2つ目のfully connectの定義で,基本は1つ目と同じように引数を設定する.
また出力が10になっているのは,MNISTが10クラスのデータセットなため,10クラス分の出力をする
これらの他にも多数の機能をPyTorchは用意しており,それらは以下のLinkから参照してほしい.
torch.nn 公式サイト
今回はMNISTを使用する上で作成しているので,他のDatasetにすると細かい引数が変わるので注意する.
(例えばMINSITは白黒画像なため1チャネルだが、カラー画像にすると最初の畳み込みの入力は3チャネルになる)
6-4-3. 処理内容の定義
以下に処理部分のみ再掲する.
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.pool(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool(x)
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
「def forward(self, x)」の引数xがこのネットワークに対しての入力dataである.
もちろんこのxはdataloaderから取得したバッチサイズ数のdata群である.
このように入力xを__init__()で定義した各層(self.XXXXX)に上から順に入力していく.
実際にどのように処理されていくかを詳しく説明していく.
-
conv1(x), relu(x), pool(x)について
まず上から3つのconv1~poolまでの処理を図で説明する.
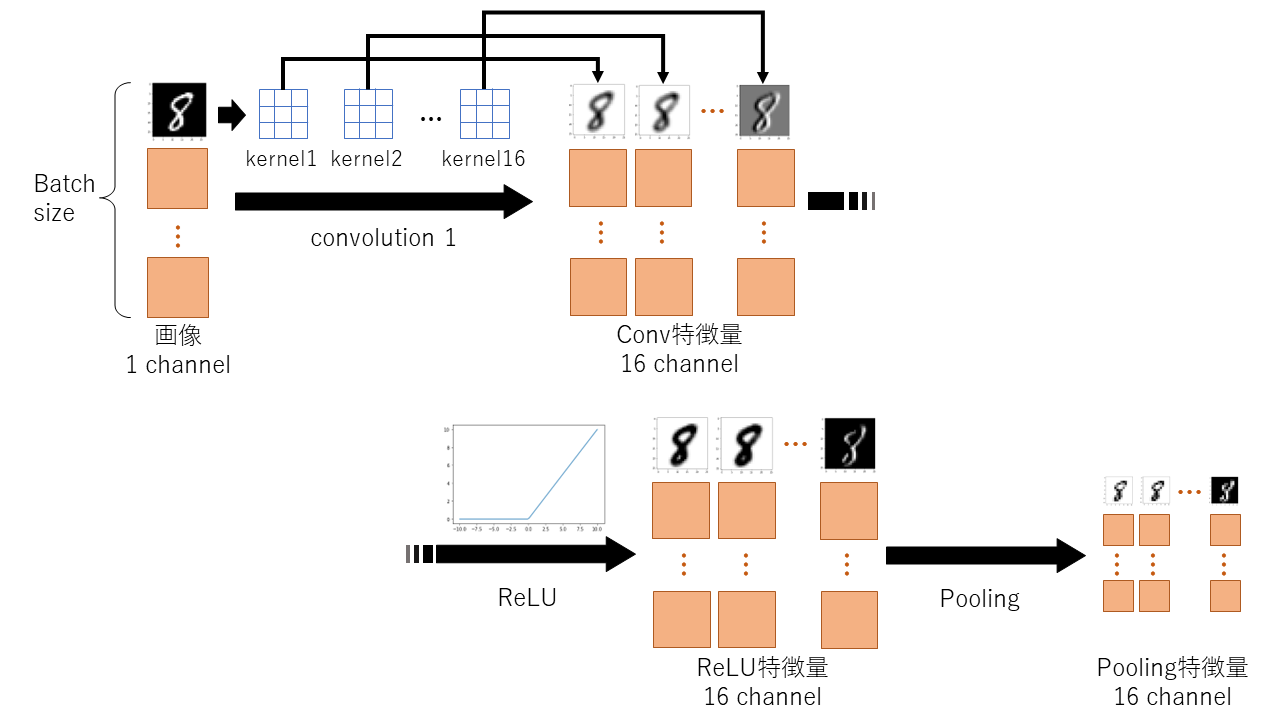
まずバッチサイズ分の1チャネルの入力画像が16個のkernel(parameter)を通じて16チャネルの特徴を得る.
このkernelはそれぞれが3x3のパラメータを持ち,16個全てのkernelが異なるパラメータを持っている.つまりここでのパラメータの総数は16x3x3=144である(ほんとはバイアス16個分もさらに追加されて144+16=160個である).
これがチャネル数が増えているカラクリとなっている.
それにReLUという活性化関数(グラフのような0以下は全て0になる関数)を適用させる.
そしてpoolingを行うことで特徴画像サイズが半分となる. -
conv2(x)について
同様にconv2に関しても見てみる.
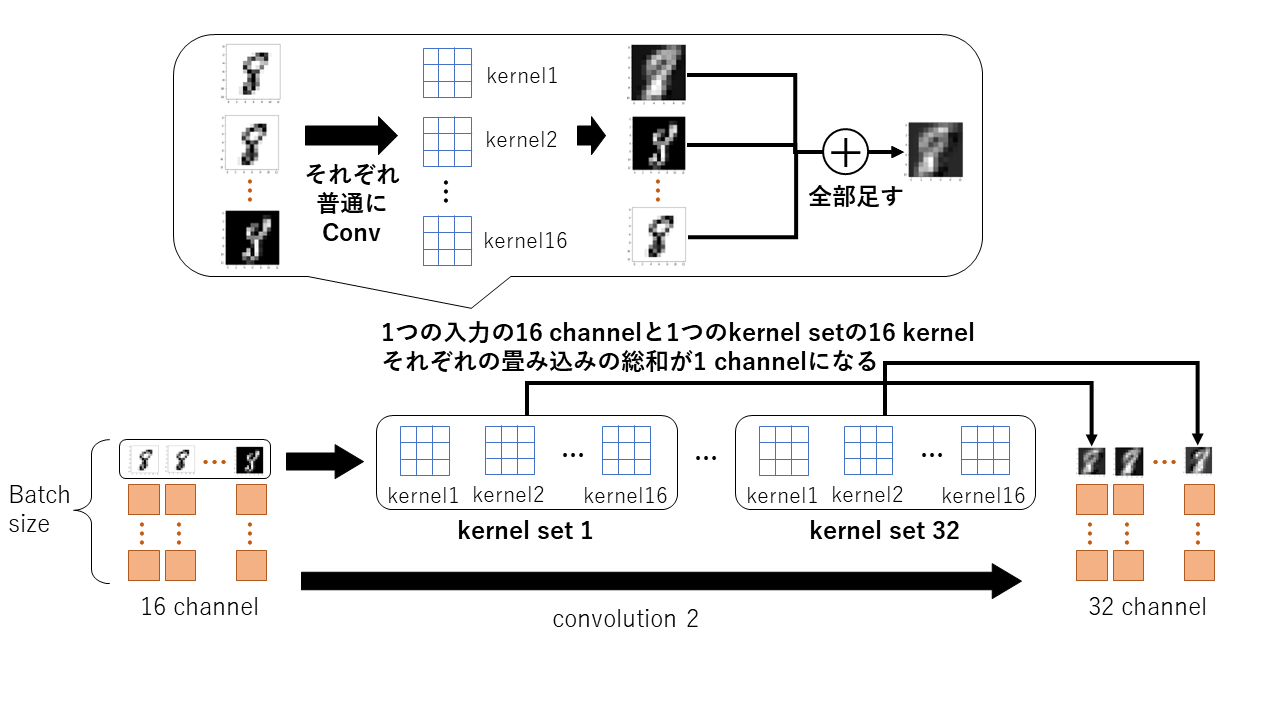
このように16チャネルの入力に対してconv2は16個のkernelを1セットにしたものを32セット持っており,1セットと16チャネルの入力を用いて出力の特徴画像1チャネルを求めている(これが32個あるから32チャネルとなる).
ちなみにここでも各kernelは3x3のパラメータを持ち,全てのkernelのパラメータは異なる.
ここでのパラメータの総数は32x16x3x3=4608である(ほんとはバイアス32x16=512個分もさらに追加されて4608+512=5120個である). -
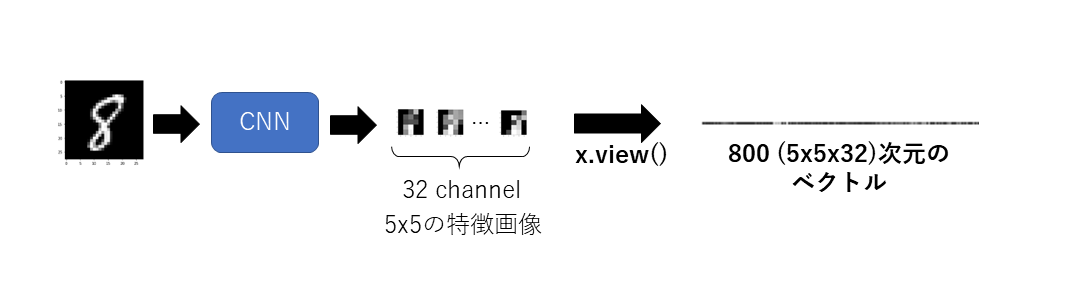
view(~~~)について
「x.view(x.size()[0], -1)」はtensor型xの形を変換するもので,view(a,b)とみたときに引数aを縦,引数bを横とみた行列に変換することができる.
今回は行列形式を1本のベクトルにするため,Bach内の各1サンプルに対する特徴画像を横長に伸ばすイメージである.
例えばサンプルが一つの時はview(1, XXXX)とすれば1行XXXX列にすることで横長のベクトルに伸ばすことができる.
ここでXXXXに今回の特徴量である実際の値 5x5x32を入れてもいいのだが,view(1, -1)とするだけで同じことが実装できる.
(この-1の意味はもう片方の確定しているサイズになるように -1側を自動でサイズ調節するということである)
そして今回は1つのサンプルではなくミニバッチ数分のサンプルがあるためx.size()[0]で入力のミニバッチ数を指定している.
これが6-4-2で言った行列をベクトルの形に変換する操作である.
「x.size()」について詳しく説明すると,xのサイズを返すもので (Batchsize,Channel,Height,Width) というtuple型が返ってくる.
そのtupleの0番目を x.size()[0] で指定しているから,書き換えるとこの文は「x.view(Batchsize, -1)」ということになっている.
ということで行数がBatchsize(今の場合100個)になるように列数を自動調節し,100個の行ベクトルができたことになる(つまり100個の行列データを100個のベクトルデータにした).
以下は1サンプルに対してviewを行ったときの例である.
- fc1(x)について
viewによって特徴画像をベクトルにできたので,fully connect層(全結合層)に適応させることができる.
fc1は以下のようなことを行っている.
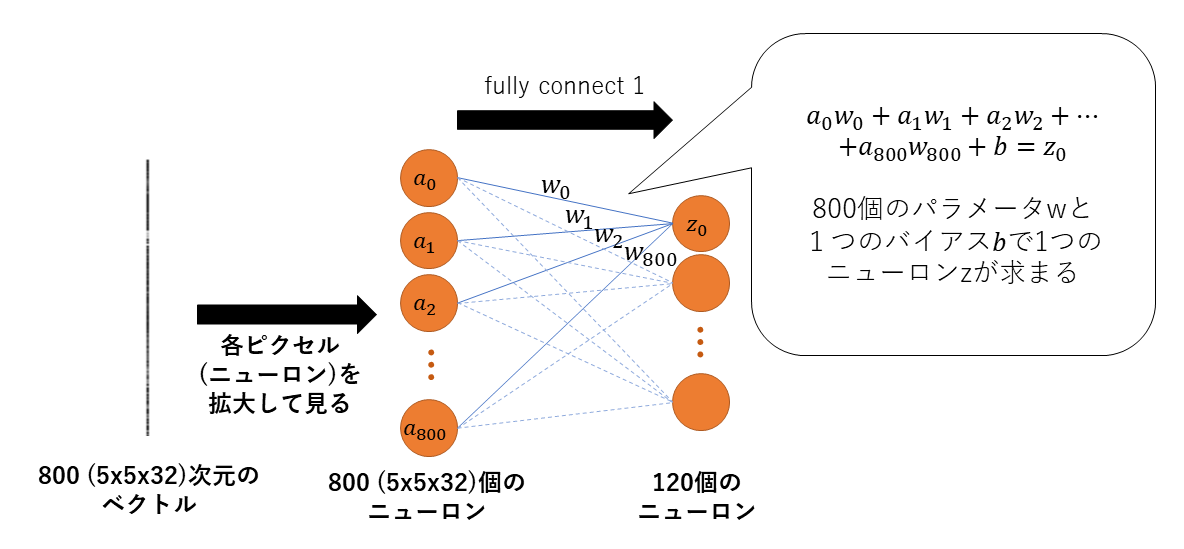
ここでは見やすくするために先ほどの例で使った800次元のベクトルを縦に書いている.
このベクトルの各値をニューロンといい拡大して簡単に真ん中のようなオレンジの丸で見てみる.
このすべてのニューロンから青色の線に沿って出力側の一つのニューロンzになっている.
詳しい計算は吹き出し内に書いている.
ここでwとは学習パラメータ(重みともいう)で,図で言うと青色の線上にあるものと考えてよい.
同様に他のニューロンzも異なる重みwで求まる.
全結合層の重みは800x120=96000個と,畳み込みに対して非常に学習パラメータが多いことが分かる(ほんとはバイアス800個分もさらに追加されて96000+800=96800個である).
このforward関数内では変数xは「x = self.XXXXX(x)」のように毎回更新されている.
変数が更新されても良いことを覚えておこう.
6-5. Networkの準備とloss関数と最適化手法
以下にコードを示す.
import torch.optim as optim
device = torch.device("cuda:0")
net = Net()
net = net.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.0001, momentum=0.9, weight_decay=0.005)
-
1行目
まず最初に,最適化を定義するために「torch.optim」をimportした.
このmoduleは最適化の手法を多数持っている. -
3行目
「device = torch.device("cuda:0")」はGPUを使用する際にどのGPUを使用するかを決めている.
この場合 "cuda:0" を使用するということを変数deviceにもたせている.
使っているPCの環境にGPUが複数あるなら「"cuda:番号"」とすればそのGPUを使用できる(または単に「 "cuda" 」とすれば番号など気にせずにGPUを使用できる).
またcpuを使用したい場合は「 "cpu" 」とすれば良い. -
4行目
「 net = Net() 」は先程定義したNetworkを作成している(インスタンスの生成という).
netがNetwork内の変数や演算用のパラメータなどを保持することとなる.
また,この瞬間にNet()の初期化関数__init__()が起動している.
netを出力するとnetの詳細が見れる.
print(net)
------'''以下出力結果'''--------
Net(
(relu): ReLU()
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv1): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=800, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=10, bias=True)
)
-
5行目
「net = net.to(device)」は作成したNetworkであるnetが3行目で指定した「device」を使用するようにしている.
この「xxx.to(device)」はGPUとCPUを行き来するときにもよく使用する. -
6行目
「criterion = nn.CrossEntropyLoss()」はloss関数を定義している(損失関数とも言い,学習をするための罰則の値を決める).
このnnは先程importしたtorch.nnのことで,実はtorch.nnはNetwork内の演算以外にもlossを計算するための関数も多数用意しくれている.
今回はその中でも「nn.CrossEntropyLoss()」を使用し,criterionという変数にその機能をもたせる.
criterionを出力すると何を使用しているかがわかる.
print(criterion)
------'''以下出力結果'''--------
CrossEntropyLoss()
- 7行目
「optimizer = optim.SGD(net.parameters(), lr=0.0001, momentum=0.9, weight_decay=0.005)」は最適化手法であり,このoptim moduleが多数の手法を用意している.
最適化手法が一体何をするのかというと,netがもつパラメータが学習のたびに更新されていくのだが,その更新の仕方を決めているのである.
この更新方法は最適化手法により異なり,今回は確率的勾配降下法(SGD)を使うため「optim.SGD()」を使用する.
以下引数の説明.- 第1引数はnetのパラメータを渡す.
- 第2引数の「lr=0.0001」は学習率(learning rate)を意味し,簡単に言えば学習の速度を定義する.
これはなるべく極小であることが望まれるが,学習がなかなか進まない場合はこの値を大きくしていく. - 第3引数の「momentum=0.9」は慣性項を意味し,前回の更新量にmomentumの値倍をした項を更新時にさらに加算する.
これもパラメータの更新に関わるもので,値が大きいほどパラメータは大きく更新される. - 第4引数の「weight_decay=0.005」は正則化項を意味し,更新を抑制することで過学習(over fitting)を抑制してくれる.
これは値が大きいほど学習が遅くなる.
optimizerを出力するとそれぞれの引数の情報を見ることができる
print(optimizer)
------'''以下出力結果'''--------
SGD (
Parameter Group 0
dampening: 0
lr: 0.0001
momentum: 0.9
nesterov: False
weight_decay: 0.005
)
optimizerの引数で渡した「net.parameters()」はnetのパラメータを参照しているわけではなく,netのパラメータのiteratorを返している.
試しに出力をしてみてもパラメータの表示はされない.
print(net.parameters())
------'''以下出力結果'''--------
<generator object Module.parameters at 0x7fb663b45c00>
詳しいNetworkのパラメータの閲覧や操作方法などが気になる方は以下のLinkより参照してほしい.
PyTorchのNetworkのパラメータの閲覧と書き換え
また,詳しいSGDの操作やどう動いているかなどは以下のLinkより参照してほしい.
PyTorch optim SGD徹底解説
6-6. Training&Test
以下にコードを示す.
for epoch in range(100):
for (inputs, labels) in trainloader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
for (inputs, labels) in testloader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
- for epoch in range(100)
1番外側のループで学習を何回するかの学習回数だけ繰り返される.
これをepochといい,今回はepochを100としている.
ここで注意してほしいのが学習回数とパラメータの更新回数は別のものとして考える.
epochは学習回数を意味し,次のfor文による処理が更新回数に相当する.
このコードはTrainingとTestをepochのループ内に各ループとして書いており,1ループ毎(1エポック毎)にそれぞれを実行している.
それぞれの説明を以下に示す.
6-6-1. Training
以下にTrainingのループを示す.
for (inputs, labels) in trainloader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
-
1行目
trainloaderの説明の時のように,中身のdataとlabelをバッチサイズ分取得している.
この時,一回のループではバッチサイズ分の100個の値をとっているわけだから,このループは総data数60000を100で割った600回ぶん回ることがわかる.
この回数が先程言ったパラメータの更新回数であり,iterationと呼ばれる.
もしバッチサイズが減ればiteration回数が増えることは当然のようにわかる. -
2行目
取得したdataとlabelをGPUで使用するようにする. -
3行目
勾配(gradient)情報を0に初期化をしている.
この勾配情報とは後のbackward()という関数により求められるもので,パラメータを更新する際に使用する.
iterationのたびに前の勾配情報が残らないようにするため0にする. -
4行目
取得したdataをNetworkに入力している.
このようにNetworkの使用は「net(data)」とすればnetのforward() が実行される.
outputsはNetworkのforward()の返り値である.
今回の場合は1サンプルに対し10要素あり, outputs=[0.1, 0.2, 0.35, 0.05, 0.05, 0.03, 0.07, 0.05, 0.04, 0.06] のようなtensor型ベクトルとなって返ってくる.
この例だと3番目の値が最も大きいから,このdataは3番目のlabelを予想していることとなる(つまり数字の2だと予測している).
通常の分類問題の場合softmaxと呼ばれる関数により,出力の要素を確率値に変換する.
この10要素のベクトルがバッチ数分ある(つまり100x10の出力が返ってくる). -
5行目
先ほど定義したloss関数を使用する.「criterion(outputs, labels)」とすればoutputsとlabelsとのlossを計算してくれる.
返り値はtensor型の値である.
この時outputsは10個の要素を持ったものだと説明したが,labelに関しては2や6といった画像の数字の答えになっている.
この10要素対1要素からlossを計算するためにcriterionの内部ではlabelをOne hot vectorに変換する.
One hotとはlabelの位置を1とし,他を0としてベクトルであり,2 = [0,0,1,0,0,0,0,0,0,0]となる.
実際には気にしなくても勝手に変換される.
ここでもしかしたら読者様の中に「outputsに対してsoftmaxを最後に使用しなくてよいのか?」と思う方がいるかもしれないが,実はcriterionを定義した「nn.CrossEntropyLoss()」には内部でsoftmaxが実装されている.
もし他のloss関数を使用している場合はその関数がsoftmax等を使用しているかをしっかり確認してほしい. -
6行目
計算したlossから勾配情報を計算している.
この計算をどうやっているかなどの詳しい情報はここでは割愛する.
この勾配情報を用いてcriterionのlossが小さくなるように更新をしていくのである. -
7行目
実際に勾配情報を使用してパラメータの更新をする.
何故「optimizer.step()」によりパラメータが更新されるかというとoptimizerの宣言時にnet.parameters() を渡しているからである.
実は勾配情報はnetのパラメータが一緒に保持している.
6-6-2. Test
以下にTestのループを示す.
for (inputs, labels) in testloader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
Trainingとほとんど同じなので説明は省く.
大きく違う点はTestではパラメータの更新がないためbackward() とstep() が必要ない.
7. まとめソースコード
以下に上の説明を踏まえ,実行中に見やすいよう出力等を追加したまとめのソースコードを示す.
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt #グラフ出力用module
BATCH_SIZE = 100
WEIGHT_DECAY = 0.005
LEARNING_RATE = 0.0001
EPOCH = 100
PATH = "Datasetのディレクトリpath"
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root = PATH, train = True, download = True, transform = transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size = BATCH_SIZE,
shuffle = True, num_workers = 1) #Windows Osの方はnum_workers=1 または 0が良いかも
testset = torchvision.datasets.MNIST(root = PATH, train = False, download = True, transform = transform)
testloader = torch.utils.data.DataLoader(testset, batch_size = BATCH_SIZE,
shuffle = False, num_workers = 1) #Windows Osの方はnum_workers=1 または 0が良いかも
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(2, stride=2)
self.conv1 = nn.Conv2d(1,16,3)
self.conv2 = nn.Conv2d(16,32,3)
self.fc1 = nn.Linear(32 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.pool(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool(x)
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
device = torch.device("cuda:0")
net = Net()
net = net.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=LEARNING_RATE, momentum=0.9, weight_decay=WEIGHT_DECAY)
train_loss_value=[] #trainingのlossを保持するlist
train_acc_value=[] #trainingのaccuracyを保持するlist
test_loss_value=[] #testのlossを保持するlist
test_acc_value=[] #testのaccuracyを保持するlist
for epoch in range(EPOCH):
print('epoch', epoch+1) #epoch数の出力
for (inputs, labels) in trainloader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
sum_loss = 0.0 #lossの合計
sum_correct = 0 #正解率の合計
sum_total = 0 #dataの数の合計
#train dataを使ってテストをする(パラメータ更新がないようになっている)
for (inputs, labels) in trainloader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
sum_loss += loss.item() #lossを足していく
_, predicted = outputs.max(1) #出力の最大値の添字(予想位置)を取得
sum_total += labels.size(0) #labelの数を足していくことでデータの総和を取る
sum_correct += (predicted == labels).sum().item() #予想位置と実際の正解を比べ,正解している数だけ足す
print("train mean loss={}, accuracy={}"
.format(sum_loss*BATCH_SIZE/len(trainloader.dataset), float(sum_correct/sum_total))) #lossとaccuracy出力
train_loss_value.append(sum_loss*BATCH_SIZE/len(trainloader.dataset)) #traindataのlossをグラフ描画のためにlistに保持
train_acc_value.append(float(sum_correct/sum_total)) #traindataのaccuracyをグラフ描画のためにlistに保持
sum_loss = 0.0
sum_correct = 0
sum_total = 0
#test dataを使ってテストをする
for (inputs, labels) in testloader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
sum_loss += loss.item()
_, predicted = outputs.max(1)
sum_total += labels.size(0)
sum_correct += (predicted == labels).sum().item()
print("test mean loss={}, accuracy={}"
.format(sum_loss*BATCH_SIZE/len(testloader.dataset), float(sum_correct/sum_total)))
test_loss_value.append(sum_loss*BATCH_SIZE/len(testloader.dataset))
test_acc_value.append(float(sum_correct/sum_total))
plt.figure(figsize=(6,6)) #グラフ描画用
#以下グラフ描画
plt.plot(range(EPOCH), train_loss_value)
plt.plot(range(EPOCH), test_loss_value, c='#00ff00')
plt.xlim(0, EPOCH)
plt.ylim(0, 2.5)
plt.xlabel('EPOCH')
plt.ylabel('LOSS')
plt.legend(['train loss', 'test loss'])
plt.title('loss')
plt.savefig("loss_image.png")
plt.clf()
plt.plot(range(EPOCH), train_acc_value)
plt.plot(range(EPOCH), test_acc_value, c='#00ff00')
plt.xlim(0, EPOCH)
plt.ylim(0, 1)
plt.xlabel('EPOCH')
plt.ylabel('ACCURACY')
plt.legend(['train acc', 'test acc'])
plt.title('accuracy')
plt.savefig("accuracy_image.png")
学習をするループ中とその前後に色々なものが追加されているが,それぞれグラフを出力したり実行中の結果を見たりするためのものである.
また,test時にtestloaderのみでなくtrainloaderも使用してtestを行っている(trainloaderが2回使われているが2つ目では更新がない).
どういうことかというと,学習時に使用した画像をもう一度ランダムに使用して精度がどれくらい出るかを見ているのである.
もちろんこのことからtestloaderの中の画像は学習では使用していない未知のデータという扱いである.
ところどころにある「xxx.item()」というのはtensor型のdataから通常のintやdoubleの数字として取り出している.
実際にグラフの結果を見ると以下のようなっている.
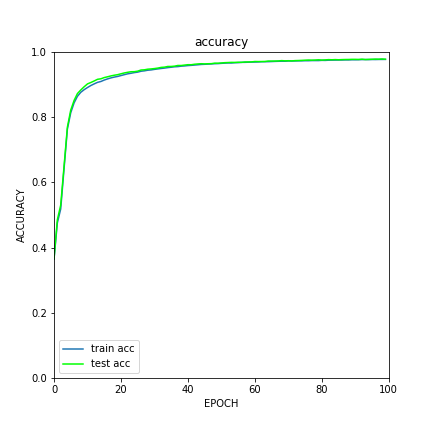
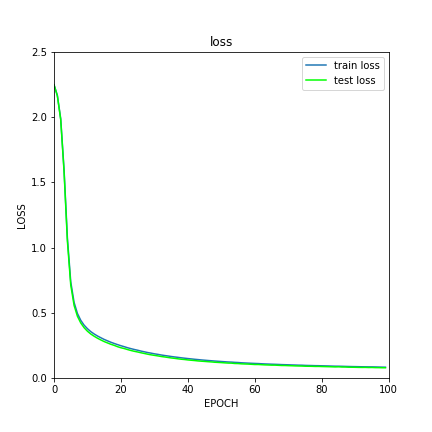
lossが下がるにつれてaccuracy(分類精度)が向上しているのがわかる.
このネットワークで今回使ったパラメータだとMNISTでは分類精度97%くらいは出ることがわかった.
6. ひとこと
今回はPyTorchを使用してCNNを作成し,疑問に思ったことや少しずつ理解していく過程で分かったことなどを踏まえて徹底解説とさせて頂いた.
読みづらい点も多かったと思うが読んでいただきありがとうございます.