ALB 同様、CloudFront のログの取り込みについても Elasticsearch Service 6.8 / Lambda Python 3.8 対応化メモを残しておきます。
こちらの記事のアップデートです。
※ほとんど ALB と同じ手順です。
手順
1. Amazon Elasticsearch Service の起動
ALB の元記事のとおりです(省略)。
2. Ingest Pipeline の設定
CloudFront の元記事と同じですが再掲します。
設定(CloudFront用)
$ curl -H "Content-Type: application/json" -XPUT 'https://XXXXX-XXXXXXXXXXXXXXXXXXXXXXXXXX.ap-northeast-1.es.amazonaws.com/_ingest/pipeline/cflog' -d '{
"processors": [{
"grok": {
"field": "message",
"patterns":[ "%{TIMESTAMP_ISO8601:timestamp} %{NOTSPACE:x_edge_location} (?:%{INT:sc_bytes:int}|-) %{IPORHOST:c_ip} %{WORD:cs_method} %{HOSTNAME:cs_host} %{NOTSPACE:cs_uri_stem} %{INT:sc_status:int} %{GREEDYDATA:referrer} %{GREEDYDATA:User_Agent} %{GREEDYDATA:cs_uri_query} %{GREEDYDATA:cookies} %{WORD:x_edge_result_type} %{NOTSPACE:x_edge_request_id} %{HOSTNAME:x_host_header} %{URIPROTO:cs_protocol} (?:%{INT:cs_bytes:int}|-) %{NUMBER:time_taken:float} %{NOTSPACE:x_forwarded_for} %{NOTSPACE:ssl_protocol} %{NOTSPACE:ssl_cipher} %{WORD:x_edge_response_result_type}" ],
"ignore_missing": true
}
},{
"remove":{
"field": "message"
}
}, {
"user_agent": {
"field": "User_Agent",
"target_field": "user_agent",
"ignore_failure": true
}
}, {
"remove": {
"field": "User_Agent"
}
}]
}'
3. AWS Lambda ファンクションの作成
IAM Role の作成
ALB の元記事のとおりです(省略)。
Lambda ファンクションの作成
- .zip ファイル作成(Amazon Linux 2 上で)
Lambda用アップロードファイル.zip化
$ python3 -m venv dev
$ . dev/bin/activate
(dev) $ mkdir cf_log_to_es_s3
(dev) $ cd cf_log_to_es_s3/
(dev) $ pip install requests requests_aws4auth -t ./
(省略)
(dev) $ rm -rf *.dist-info
(dev) $ vi lambda_function.py
(ここで「lambda_function.py」のコードを入力)
(dev) $ zip -r ../cflog.zip *
- コード(Python 3.8 用)
lambda_function.py
import boto3
import os
import gzip
import requests
from datetime import datetime
from requests_aws4auth import AWS4Auth
def lambda_handler(event, context):
print('Started')
es_index = os.environ['ES_INDEX_PREFIX'] + "-" + datetime.strftime(datetime.now(), "%Y%m%d")
region = os.environ["AWS_REGION"]
service = 'es'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
bucket = event["Records"][0]["s3"]["bucket"]["name"]
key = event["Records"][0]["s3"]["object"]["key"]
s3 = boto3.resource('s3')
s3.Bucket(bucket).download_file(key, '/tmp/log.gz')
with gzip.open('/tmp/log.gz', mode='rt') as f:
data = ""
for line in f:
if not line.strip().startswith('#'):
data += '{"index":{"_index":"%s","_type":"log"}}\n' % es_index
data += '{"message":"%s"}\n' % line.strip().replace('"', '\\"').replace('\t', ' ').replace(' ', 'T', 1).replace(' ', 'Z ', 1)
if len(data) > 3000000:
_bulk(data, awsauth)
data = ""
if data != "":
_bulk(data, awsauth)
return 'Completed'
def _bulk(data, awsauth):
es_host = os.environ['ES_HOST']
pipeline = os.environ['PIPELINE_NAME']
url = 'https://%s/_bulk?pipeline=%s' % (es_host, pipeline)
headers = {'Content-Type': 'application/json'}
response = request(url, awsauth, headers=headers, data=data)
if response.status_code != requests.codes.ok:
print(response.text)
def request(url, awsauth, headers=None, data=None):
return requests.post(url, auth=awsauth, headers=headers, data=data)
- 環境変数
CloudFront の元記事と同じですが再掲します。
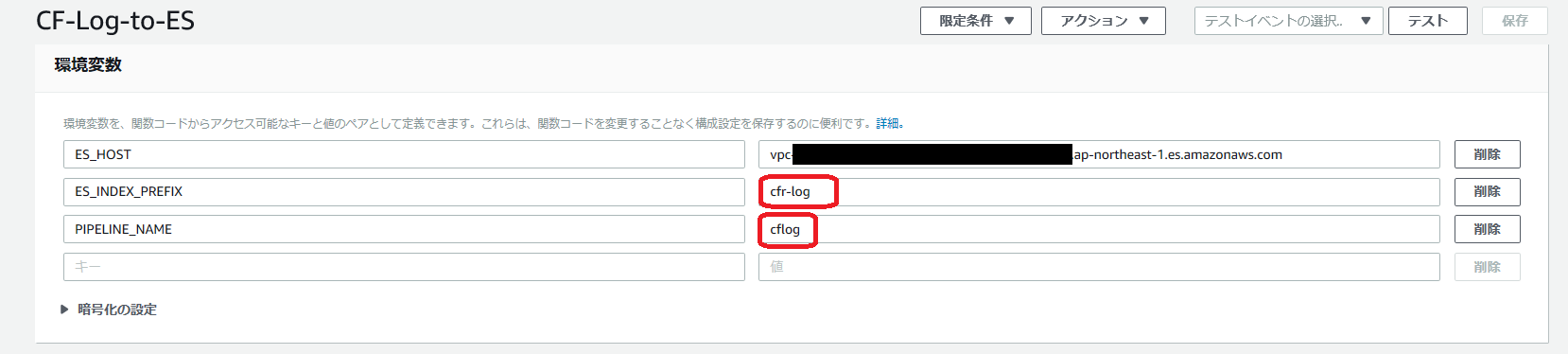
- アクセスログが保存されている S3 バケットのトリガー
- Lambda の実行用ロール・タイムアウト時間・メモリサイズ・ネットワーク設定
などはALB の元記事のとおりです(省略)。