この記事は何?
グラフを扱う機能を直接持たない PostgreSQL で、GraphRAG に使うためのグラフインデックスの生成に挑戦してみた話です。
MCP の登場とともに表舞台では話題になることが少なくなった RAG(Retrieval Augmented Generation:検索拡張生成)ですが、実務上はまだまだ RAG を組み込んだシステムに取り組んでいるケースがそこそこあるのでは?と思います。
というわけで、JAWS-UG AI/ML #27 の中で LT 発表した内容をもとに記事化しておきます。
当日の発表資料はこちらです。
GraphRAG について…の説明はしません!
前述の JAWS-UG AI/ML #27 の中でわかりやすく説明してくださった方がいらっしゃるので、そちらの発表資料をご確認ください。
LlamaIndex とは?
ざっくりいうと、RAG 向けの検索インデックス用フレームワークです。
よく比較対象になる LangChain よりもインデックスの構築と検索(retrieve)・データの投入など(RAG 向けの)インデックス関連に特化しています。
LlamaIndex の Property Graph Index
プロパティグラフで構成されるインデックス実装です。
このインデックスはノードとエッジ(リレーション)で構成されています。
エッジは方向性をもった矢印で表現され(有向グラフ)、ノードとエッジはラベル(カテゴリ・タイプ)とプロパティ(メタデータ)を持つことが可能です。
プロパティグラフには様々な情報を格納できますが、デフォルト(SimpleLLMPathExtractorとImplicitPathExtractorの組み合わせ)ではトリプレット(主語・述語・目的語)と、文章チャンクの接続関係がインデックスに展開されます。
なお本来、LlamaIndex には PostgreSQL+pgvector 用のグラフストア実装は含まれていないのですが、今回は TiDB 向けの実装を PostgreSQL+pgvector 用に移植して試しました。
Amazon Q Developer の GitHub 統合を使ってみました。なお LlamaIndex が持つ pgvector 向けのベクトルストア実装との兼ね合いで、Psycopg 3 を後ほど Psycopg 2 に入れ替えました。
この時点の Amazon Q Developer GitHub 統合は、出力トークン数の上限で作業が止まる・過去に Issue でやりとりした履歴をコンテキストに含めてくれないなどの問題があり、かなり苦労しました。
完成したグラフストア実装はこちらです。
サンプルプログラムから試す
サンプルプログラムはこちらに置いてあります。
インデックス生成と Streamlit によるシンプルなチャットを実装しています。
インストール・準備などは GitHub リポジトリの README に記載していますのでこちらでは省略します。
インデックス生成
PostgreSQL 上に、INDEXではなくTABLEのデータ行として生成されます。
$ python indexing.py
Parsing nodes: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 7.20it/s]
Extracting paths from text: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [00:25<00:00, 1.29s/it]
Extracting implicit paths: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [00:00<00:00, 29715.22it/s]
Generating embeddings: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 2.11it/s]
Generating embeddings: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:01<00:00, 5.04it/s]
Interleafはムーアの法則によって影響を受けた企業でした。頭の良い人材と優れた技術を持っていたにもかかわらず、1990年代にIntel製プロセッサの性能が指数関数的に向上したことで、専用高性能ハードとそれに対応したソフトウェアを提供していた企業として苦境に立たされました。
一方、Viawebはウェブベースのオンラインストア作成ツールとして開発されました。当初は「Webgen」という名前でしたが、後にViawebに改名されました。このソフトウェアはユーザーが自分のウェブブラウザ上でストアを構築できる初のツールでした。サーバーサイドコードはすべてLispで書かれており、製品は成功して顧客も増えていきました。最終的に1998年にYahoo!に買収され、創業者たちは大きな利益を得ることになりました。
最後の行は「InterleafとViawebでは何が起きましたか?」という質問に対する回答です。
処理内容は概ね以下のとおりです。
- 文書のチャンク化
- 文書を 1,000 文字前後(デフォルト)の文章に分割して保存
- 1 文書あたり 1 つの親(
node)ノードを生成 - チャンク化した文章を
text_chunkノードとして保存
- 1 文書あたり 1 つの親(
- 文書を 1,000 文字前後(デフォルト)の文章に分割して保存
- チャンクの接続関係(前後・親)をグラフ化
-
text_chunkノードから親ノードを指すSOURCEエッジを生成 -
text_chunkノードに保存された文章の前後関係を表すPREVIOUS/NEXTエッジを生成
-
- トリプレットの抽出
- チャンク化した文章から「主語+述語+目的語」の組み合わせをいくつか抽出
- 主語と目的語を
entityノードとして個別に保存 - 主語・述語・目的語の関係性をエッジとして保存
- 抽出元の文章チャンクを示す ID(識別子)をノード・エッジそれぞれのプロパティに記録
- 主語と目的語を
- ベクトル検索用の埋め込みベクトルを保存
-
text_chunkノードには文章チャンクの埋め込みベクトル -
entityノードにはキーワード(主語・目的語)の埋め込みベクトル -
nodeノードには保存せず(null)
-
インデックスデータを確認してみる
PostgreSQL の中に格納されたインデックスデータを確認してみます。
postgres=# \x auto
Expanded display is used automatically.
postgres=# \d
List of relations
Schema | Name | Type | Owner
--------+---------------------+----------+----------
public | pg_nodes | table | postgres
public | pg_relations | table | postgres
public | pg_relations_id_seq | sequence | postgres
(3 rows)
pg_nodesがノード用テーブル、pg_relationsがエッジ用テーブルですね。
それぞれの定義を見てみます。
ノード用テーブルの定義
postgres=# \d pg_nodes
Table "public.pg_nodes"
Column | Type | Collation | Nullable | Default
------------+-----------------------------+-----------+----------+---------
id | character varying(512) | | not null |
text | text | | |
name | character varying(512) | | |
label | character varying(512) | | not null |
properties | jsonb | | |
embedding | vector(1024) | | |
created_at | timestamp without time zone | | not null | now()
updated_at | timestamp without time zone | | not null | now()
Indexes:
"pg_nodes_pkey" PRIMARY KEY, btree (id)
Referenced by:
TABLE "pg_relations" CONSTRAINT "pg_relations_source_id_fkey" FOREIGN KEY (source_id) REFERENCES pg_nodes(id)
TABLE "pg_relations" CONSTRAINT "pg_relations_target_id_fkey" FOREIGN KEY (target_id) REFERENCES pg_nodes(id)
ノード用テーブルには埋め込みベクトルembeddingが持てるようになっています。
エッジ用テーブルの定義
postgres=# \d pg_relations
Table "public.pg_relations"
Column | Type | Collation | Nullable | Default
------------+-----------------------------+-----------+----------+------------------------------------------
id | integer | | not null | nextval('pg_relations_id_seq'::regclass)
label | character varying(512) | | not null |
source_id | character varying(512) | | |
target_id | character varying(512) | | |
properties | jsonb | | |
created_at | timestamp without time zone | | not null | now()
updated_at | timestamp without time zone | | not null | now()
Indexes:
"pg_relations_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"pg_relations_source_id_fkey" FOREIGN KEY (source_id) REFERENCES pg_nodes(id)
"pg_relations_target_id_fkey" FOREIGN KEY (target_id) REFERENCES pg_nodes(id)
ノード用テーブルに含まれる label(タイプ)の種類と内訳
postgres=# SELECT label, COUNT(*) AS label_count FROM pg_nodes GROUP BY label ORDER BY label;
label | label_count
------------+-------------
entity | 242
node | 1
text_chunk | 20
(3 rows)
-
node:text_chunkの親(1 文書あたり 1 レコード) -
text_chunk: 文章をチャンク化(分割)したもの(nodeの子) -
entity: エンティティ(トリプレットに含まれる主語・目的語)
ノード行
postgres=# SELECT id, length(text) AS text_length, name, label, properties, (embedding IS NOT NULL) AS embedding_exists, created_at, updated_at FROM pg_nodes WHERE label = 'node';
-[ RECORD 1 ]----+-------------------------------------
id | c29a6201-5921-4a01-bf6c-5cbf13f246dd
text_length |
name |
label | node
properties | {}
embedding_exists | f
created_at | 2025-06-21 13:47:11.327101
updated_at | 2025-06-21 13:47:11.327101
「親」にあたります。文書チャンクも埋め込みベクトルも持ちません。
テキストチャンク行
postgres=# SELECT id, length(text) AS text_length, name, label, properties, (embedding IS NOT NULL) AS embedding_exists, created_at, updated_at FROM pg_nodes WHERE label = 'text_chunk' ORDER BY created_at LIMIT 2;
-[ RECORD 1 ]----+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
id | 74b585c0-6889-46eb-9c3c-75d4e68dae78
text_length | 975
name |
label | text_chunk
properties | {"doc_id": "c29a6201-5921-4a01-bf6c-5cbf13f246dd", "file_name": "example_ja.txt", "file_path": "/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt", "file_size": 44432, "file_type": "text/plain", "_node_type": "TextNode", "ref_doc_id": "c29a6201-5921-4a01-bf6c-5cbf13f246dd", "document_id": "c29a6201-5921-4a01-bf6c-5cbf13f246dd", "_node_content": "{\"id_\": \"74b585c0-6889-46eb-9c3c-75d4e68dae78\", \"embedding\": null, \"metadata\": {\"file_path\": \"/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt\", \"file_name\": \"example_ja.txt\", \"file_type\": \"text/plain\", \"file_size\": 44432, \"creation_date\": \"2025-05-22\", \"last_modified_date\": \"2025-05-22\"}, \"excluded_embed_metadata_keys\": [\"file_name\", \"file_type\", \"file_size\", \"creation_date\", \"last_modified_date\", \"last_accessed_date\"], \"excluded_llm_metadata_keys\": [\"file_name\", \"file_type\", \"file_size\", \"creation_date\", \"last_modified_date\", \"last_accessed_date\"], \"relationships\": {\"1\": {\"node_id\": \"c29a6201-5921-4a01-bf6c-5cbf13f246dd\", \"node_type\": \"4\", \"metadata\": {\"file_path\": \"/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt\", \"file_name\": \"example_ja.txt\", \"file_type\": \"text/plain\", \"file_size\": 44432, \"creation_date\": \"2025-05-22\", \"last_modified_date\": \"2025-05-22\"}, \"hash\": \"44a04b6b70fe1d8384ccf4c44b97b181d41c98e4677a3a669239937e1a7b0dcd\", \"class_name\": \"RelatedNodeInfo\"}, \"3\": {\"node_id\": \"927e5ae7-a57b-4681-8737-86fc99fa2cb8\", \"node_type\": \"1\", \"metadata\": {}, \"hash\": \"ec5ae25837c6ae9cc0955c3e1bc79787ec7b162a5ee1639acf9a8c5320832fad\", \"class_name\": \"RelatedNodeInfo\"}}, \"metadata_template\": \"{key}: {value}\", \"metadata_separator\": \"\\n\", \"text\": \"\", \"mimetype\": \"text/plain\", \"start_char_idx\": 1, \"end_char_idx\": 976, \"metadata_seperator\": \"\\n\", \"text_template\": \"{metadata_str}\\n\\n{content}\", \"class_name\": \"TextNode\"}", "creation_date": "2025-05-22", "last_modified_date": "2025-05-22"}
embedding_exists | t
created_at | 2025-06-21 13:47:09.82389
updated_at | 2025-06-21 13:47:09.835153
-[ RECORD 2 ]----+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
id | 927e5ae7-a57b-4681-8737-86fc99fa2cb8
text_length | 1007
name |
label | text_chunk
properties | {"doc_id": "c29a6201-5921-4a01-bf6c-5cbf13f246dd", "file_name": "example_ja.txt", "file_path": "/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt", "file_size": 44432, "file_type": "text/plain", "_node_type": "TextNode", "ref_doc_id": "c29a6201-5921-4a01-bf6c-5cbf13f246dd", "document_id": "c29a6201-5921-4a01-bf6c-5cbf13f246dd", "_node_content": "{\"id_\": \"927e5ae7-a57b-4681-8737-86fc99fa2cb8\", \"embedding\": null, \"metadata\": {\"file_path\": \"/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt\", \"file_name\": \"example_ja.txt\", \"file_type\": \"text/plain\", \"file_size\": 44432, \"creation_date\": \"2025-05-22\", \"last_modified_date\": \"2025-05-22\"}, \"excluded_embed_metadata_keys\": [\"file_name\", \"file_type\", \"file_size\", \"creation_date\", \"last_modified_date\", \"last_accessed_date\"], \"excluded_llm_metadata_keys\": [\"file_name\", \"file_type\", \"file_size\", \"creation_date\", \"last_modified_date\", \"last_accessed_date\"], \"relationships\": {\"1\": {\"node_id\": \"c29a6201-5921-4a01-bf6c-5cbf13f246dd\", \"node_type\": \"4\", \"metadata\": {\"file_path\": \"/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt\", \"file_name\": \"example_ja.txt\", \"file_type\": \"text/plain\", \"file_size\": 44432, \"creation_date\": \"2025-05-22\", \"last_modified_date\": \"2025-05-22\"}, \"hash\": \"44a04b6b70fe1d8384ccf4c44b97b181d41c98e4677a3a669239937e1a7b0dcd\", \"class_name\": \"RelatedNodeInfo\"}, \"2\": {\"node_id\": \"74b585c0-6889-46eb-9c3c-75d4e68dae78\", \"node_type\": \"1\", \"metadata\": {\"file_path\": \"/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt\", \"file_name\": \"example_ja.txt\", \"file_type\": \"text/plain\", \"file_size\": 44432, \"creation_date\": \"2025-05-22\", \"last_modified_date\": \"2025-05-22\"}, \"hash\": \"325d368920a2cfea3de2303f8d9967dc0ebe06f64a670b5c152528a09790e617\", \"class_name\": \"RelatedNodeInfo\"}, \"3\": {\"node_id\": \"d5580129-a61c-41db-8003-25187e473c0b\", \"node_type\": \"1\", \"metadata\": {}, \"hash\": \"397084032cfb5e6c9f64e3db8b540e749f4550df1dcd8f516e884173b601f8a7\", \"class_name\": \"RelatedNodeInfo\"}}, \"metadata_template\": \"{key}: {value}\", \"metadata_separator\": \"\\n\", \"text\": \"\", \"mimetype\": \"text/plain\", \"start_char_idx\": 772, \"end_char_idx\": 1779, \"metadata_seperator\": \"\\n\", \"text_template\": \"{metadata_str}\\n\\n{content}\", \"class_name\": \"TextNode\"}", "creation_date": "2025-05-22", "last_modified_date": "2025-05-22"}
embedding_exists | t
created_at | 2025-06-21 13:47:09.835153
updated_at | 2025-06-21 13:47:09.84427
文書チャンク(text)とその埋め込みベクトル(embedding)を持ちます。
名前(name)は持ちません。
エッジ行の内訳
内訳を見てみます。
postgres=# SELECT COUNT(*) FROM pg_relations;
count
-------
253
(1 row)
postgres=# SELECT label, COUNT(label) FROM pg_relations WHERE label IN('SOURCE', 'PREVIOUS', 'NEXT') GROUP BY label ORDER BY label;
label | count
----------+-------
NEXT | 19
PREVIOUS | 19
SOURCE | 20
(3 rows)
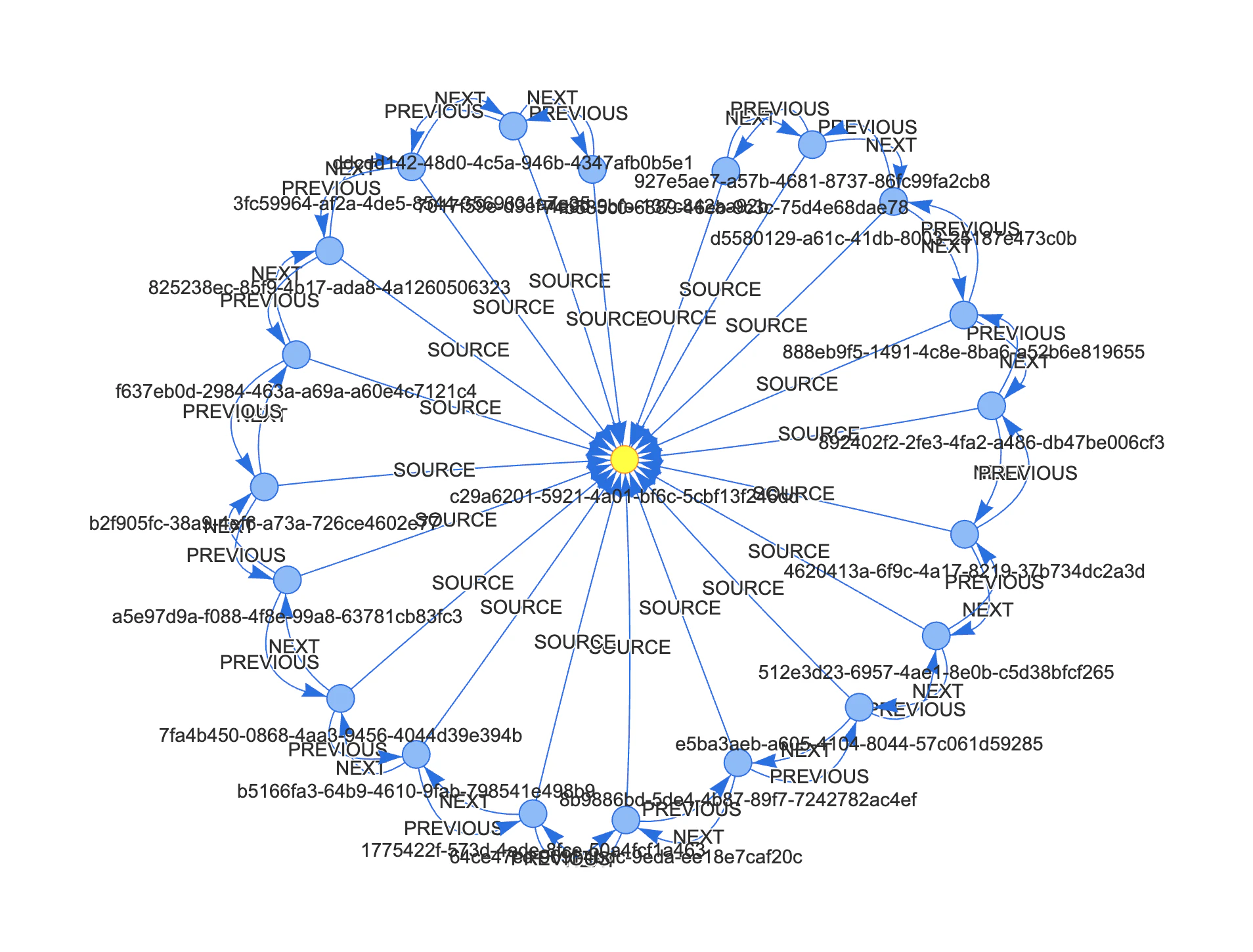
エッジ行が合計 253 行あるうちの 58 行が文書チャンク関連で、文書関連の前後関係と親を示しています。
文章チャンク関連のエッジ行
-
SOURCE(親)
postgres=# SELECT id, label, source_id, target_id, properties, created_at, updated_at FROM pg_relations WHERE label = 'SOURCE' ORDER BY created_at LIMIT 2;
-[ RECORD 1 ]--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
id | 11
label | SOURCE
source_id | 74b585c0-6889-46eb-9c3c-75d4e68dae78
target_id | c29a6201-5921-4a01-bf6c-5cbf13f246dd
properties | {"file_name": "example_ja.txt", "file_path": "/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt", "file_size": 44432, "file_type": "text/plain", "creation_date": "2025-05-22", "triplet_source_id": "74b585c0-6889-46eb-9c3c-75d4e68dae78", "last_modified_date": "2025-05-22"}
created_at | 2025-06-21 13:47:11.329644
updated_at | 2025-06-21 13:47:11.331238
-[ RECORD 2 ]--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
id | 22
label | SOURCE
source_id | 927e5ae7-a57b-4681-8737-86fc99fa2cb8
target_id | c29a6201-5921-4a01-bf6c-5cbf13f246dd
properties | {"file_name": "example_ja.txt", "file_path": "/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt", "file_size": 44432, "file_type": "text/plain", "creation_date": "2025-05-22", "triplet_source_id": "927e5ae7-a57b-4681-8737-86fc99fa2cb8", "last_modified_date": "2025-05-22"}
created_at | 2025-06-21 13:47:11.403122
updated_at | 2025-06-21 13:47:11.407789
-
PREVIOUS(前)
postgres=# SELECT id, label, source_id, target_id, properties, created_at, updated_at FROM pg_relations WHERE label = 'PREVIOUS' ORDER BY created_at LIMIT 2;
-[ RECORD 1 ]--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
id | 23
label | PREVIOUS
source_id | 927e5ae7-a57b-4681-8737-86fc99fa2cb8
target_id | 74b585c0-6889-46eb-9c3c-75d4e68dae78
properties | {"file_name": "example_ja.txt", "file_path": "/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt", "file_size": 44432, "file_type": "text/plain", "creation_date": "2025-05-22", "triplet_source_id": "927e5ae7-a57b-4681-8737-86fc99fa2cb8", "last_modified_date": "2025-05-22"}
created_at | 2025-06-21 13:47:11.409412
updated_at | 2025-06-21 13:47:11.413127
-[ RECORD 2 ]--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
id | 36
label | PREVIOUS
source_id | d5580129-a61c-41db-8003-25187e473c0b
target_id | 927e5ae7-a57b-4681-8737-86fc99fa2cb8
properties | {"file_name": "example_ja.txt", "file_path": "/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt", "file_size": 44432, "file_type": "text/plain", "creation_date": "2025-05-22", "triplet_source_id": "d5580129-a61c-41db-8003-25187e473c0b", "last_modified_date": "2025-05-22"}
created_at | 2025-06-21 13:47:11.488719
updated_at | 2025-06-21 13:47:11.493809
-
NEXT(後)
postgres=# SELECT id, label, source_id, target_id, properties, created_at, updated_at FROM pg_relations WHERE label = 'NEXT' ORDER BY created_at LIMIT 2;
-[ RECORD 1 ]--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
id | 12
label | NEXT
source_id | 74b585c0-6889-46eb-9c3c-75d4e68dae78
target_id | 927e5ae7-a57b-4681-8737-86fc99fa2cb8
properties | {"file_name": "example_ja.txt", "file_path": "/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt", "file_size": 44432, "file_type": "text/plain", "creation_date": "2025-05-22", "triplet_source_id": "74b585c0-6889-46eb-9c3c-75d4e68dae78", "last_modified_date": "2025-05-22"}
created_at | 2025-06-21 13:47:11.332575
updated_at | 2025-06-21 13:47:11.337006
-[ RECORD 2 ]--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
id | 24
label | NEXT
source_id | 927e5ae7-a57b-4681-8737-86fc99fa2cb8
target_id | d5580129-a61c-41db-8003-25187e473c0b
properties | {"file_name": "example_ja.txt", "file_path": "/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt", "file_size": 44432, "file_type": "text/plain", "creation_date": "2025-05-22", "triplet_source_id": "927e5ae7-a57b-4681-8737-86fc99fa2cb8", "last_modified_date": "2025-05-22"}
created_at | 2025-06-21 13:47:11.41462
updated_at | 2025-06-21 13:47:11.41833
のように入っています。
文章チャンクのグラフ構造を表すと、このようになります。
エンティティ行
今度はノードに含まれるエンティティ(entity)行です。
postgres=# SELECT id, length(text) AS text_length, name, label, properties, (embedding IS NOT NULL) AS embedding_exists, created_at, updated_at FROM pg_nodes WHERE label = 'entity' ORDER BY created_at LIMIT 2;
-[ RECORD 1 ]----+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
id | 私
text_length |
name | 私
label | entity
properties | {"file_name": "example_ja.txt", "file_path": "/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt", "file_size": 44432, "file_type": "text/plain", "creation_date": "2025-05-22", "triplet_source_id": "64ce47cd-969f-4bdc-9eda-ee18e7caf20c", "last_modified_date": "2025-05-22"}
embedding_exists | t
created_at | 2025-06-21 13:47:09.913373
updated_at | 2025-06-21 13:47:10.518213
-[ RECORD 2 ]----+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
id | 文章を書くこと
text_length |
name | 文章を書くこと
label | entity
properties | {"file_name": "example_ja.txt", "file_path": "/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt", "file_size": 44432, "file_type": "text/plain", "creation_date": "2025-05-22", "triplet_source_id": "1775422f-573d-4ade-8fce-50a4fcf1a463", "last_modified_date": "2025-05-22"}
embedding_exists | t
created_at | 2025-06-21 13:47:09.916022
updated_at | 2025-06-21 13:47:10.570029
こちらは主キー(id)に単語(主語・目的語)が入るので、同じ単語が複数登録されることはありません。
主キーと同じ単語が名前(name)に入ります。そして主キーの単語が埋め込みベクトル化されてembeddingに入ります。
エンティティ関連のエッジ行
postgres=# SELECT id, label, source_id, target_id, properties, created_at, updated_at FROM pg_relations ORDER BY created_at LIMIT 2;
-[ RECORD 1 ]--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
id | 1
label | 取り組んできた
source_id | 私
target_id | 文章を書くこと
properties | {"file_name": "example_ja.txt", "file_path": "/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt", "file_size": 44432, "file_type": "text/plain", "creation_date": "2025-05-22", "triplet_source_id": "74b585c0-6889-46eb-9c3c-75d4e68dae78", "last_modified_date": "2025-05-22"}
created_at | 2025-06-21 13:47:11.275447
updated_at | 2025-06-21 13:47:11.282648
-[ RECORD 2 ]--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
id | 2
label | 取り組んできた
source_id | 私
target_id | プログラミング
properties | {"file_name": "example_ja.txt", "file_path": "/Users/hmatsu47/llama_index_property_graph_test/data/example_ja.txt", "file_size": 44432, "file_type": "text/plain", "creation_date": "2025-05-22", "triplet_source_id": "74b585c0-6889-46eb-9c3c-75d4e68dae78", "last_modified_date": "2025-05-22"}
created_at | 2025-06-21 13:47:11.284701
updated_at | 2025-06-21 13:47:11.287974
こちらは主キー(id)がシーケンス値なので、同じ組み合わせのトリプレットが複数存在しても問題ありません。
エンティティのグラフ構造を表すと、このようになります(一部分のみ表示)。
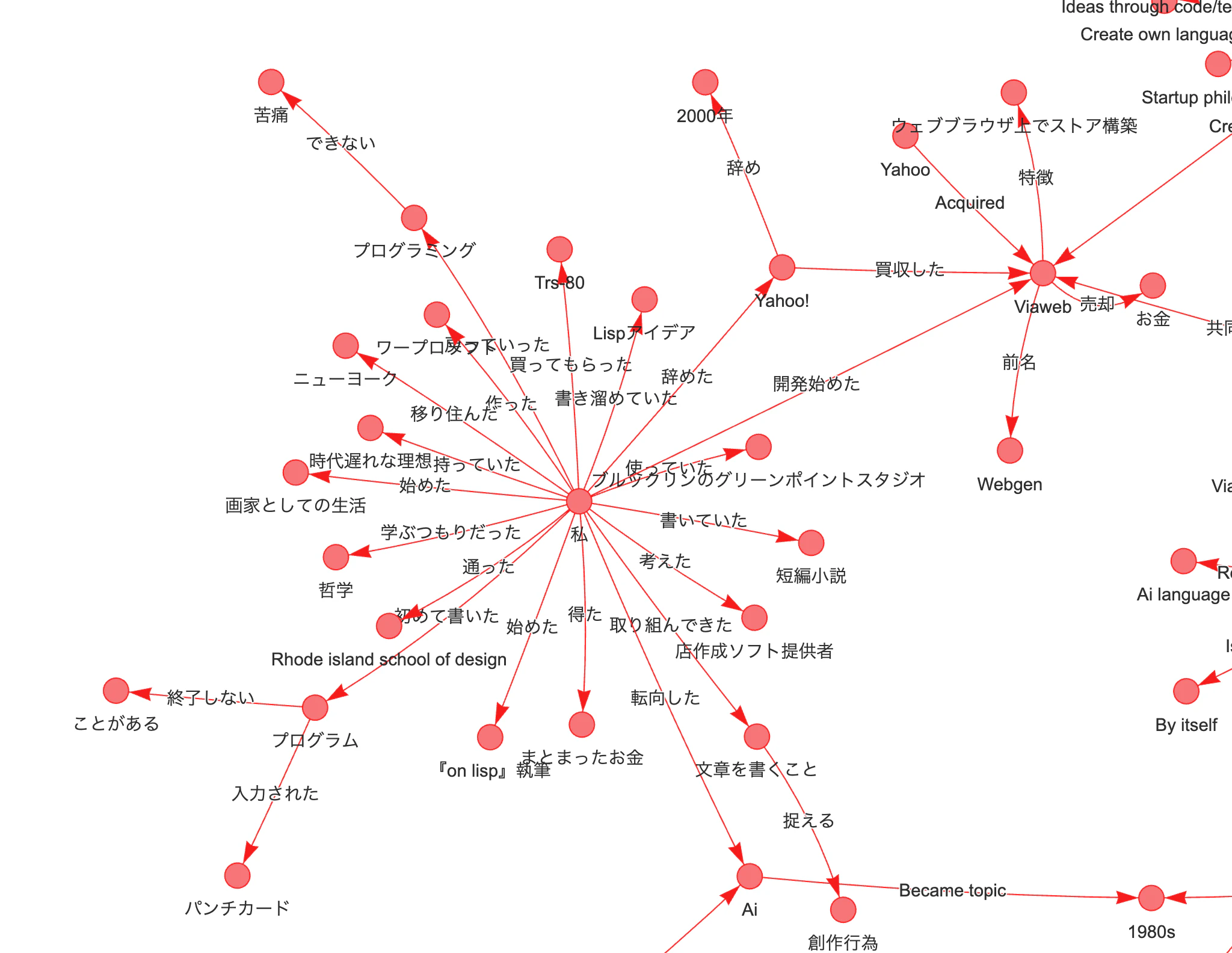
「私」を中心に見てみると、一部、複数階層の接続が抽出されているのがわかります。
- 私→初めて書いた→プログラム→終了しない→ことがある
- プログラム→終了しない→ことがある
- プログラム→入力された→パンチカード
検索
Streamlit で単答チャットアプリ化してありますが、その中でグラフストアを検索しています。
streamlit run simple_chat.py --server.port 8080
検索処理の流れ
デフォルトの Retriever 構成を使っている場合、以下のような流れになります。
- LLM に渡すコンテキストをグラフストアで検索・取得
-
VectorContextRetrieverでentityノードをベクトル検索- ベクトル類似度の高い
entityノードの単語を含むトリプレットを取得 - あわせてトリプレット抽出元の
text_chunkノードを取得
- ベクトル類似度の高い
-
LLMSynonymRetrieverで類義語を複数(デフォルト 10 個)生成し、それらを使ってentityノードを主キー検索- 同じ主キー値を持つ
entityノードの単語を含むトリプレットを取得 - あわせてトリプレット抽出元の
text_chunkノードを取得
- 同じ主キー値を持つ
-
コードの関連部分を示します。
with Session(self._engine) as session:
result = (
session.query(
self._node_model,
self._node_model.embedding.cosine_distance(
query.query_embedding
).label("embedding_distance"),
)
.filter(self._node_model.name.is_not(None))
.order_by(sql.asc("embedding_distance"))
.limit(query.similarity_top_k)
.all()
)
.filterでnameがNone(null)ではないノードに絞り込んでいますが、これはentityノードに限定してベクトル検索するためのフィルタ処理です。
次に、グラフ構造を辿る SQL 文のテンプレートを示します。
WITH RECURSIVE PATH AS
(SELECT 1 AS depth,
r.source_id,
r.target_id,
r.label,
r.properties
FROM {relation_table} r
WHERE r.source_id = ANY(:ids)
UNION ALL SELECT p.depth + 1,
r.source_id,
r.target_id,
r.label,
r.properties
FROM PATH p
JOIN {relation_table} r ON p.target_id = r.source_id
WHERE p.depth < :depth )
SELECT e1.id AS e1_id,
e1.name AS e1_name,
e1.label AS e1_label,
e1.properties AS e1_properties,
p.label AS rel_label,
p.properties AS rel_properties,
e2.id AS e2_id,
e2.name AS e2_name,
e2.label AS e2_label,
e2.properties AS e2_properties
FROM PATH p
JOIN {node_table} e1 ON p.source_id = e1.id
JOIN {node_table} e2 ON p.target_id = e2.id
ORDER BY p.depth
LIMIT :limit;
再帰 CTE(共通テーブル式)が使われています。
トリプレットと文章チャンクを取得したら、それらをコンテキストとして付加して質問文を LLM に送信します。
ここから先は通常の RAG と同じです。
検索時には文章チャンクのグラフ構造は使用していないようです。
実際の送信プロンプト例(コンテキストと質問文)を示します。
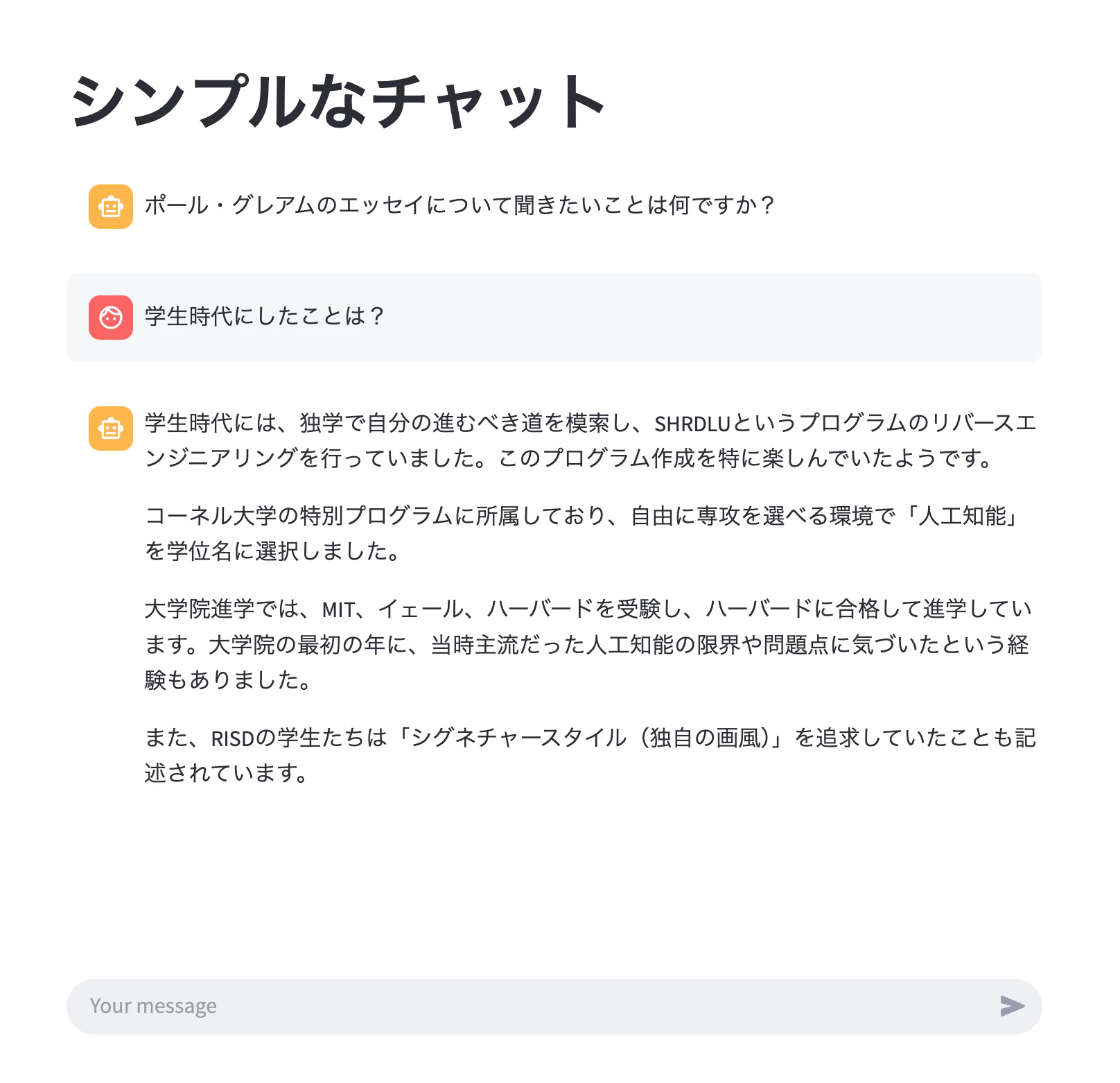
「学生時代にしたことは?」という質問文を入力したときの例です。
Context information is below.
---------------------
file_path: (略)
Here are some facts extracted from the provided text:
卒業証書 -> 記載 -> Artificial intelligence
学生 -> 独学 -> 問題なかった
学生 -> 意識 -> 進むべき道
(略)
授業の中でではなく、独学という形ではあったが、それでも問題なかった。この数年間、私は自分が進むべき道をはっきりと意識していた。
学部の卒業論文では、SHRDLUをリバースエンジニアリングした。私はこのプログラムを作ることが本当に好きだった。
(略)
---------------------
Given the context information and not prior knowledge, answer the query.
Query: 学生時代にしたことは?
Answer:
(長いので一部省略)
途中、「->」で単語を接続したトリプレットが表現されています。
その下に関連する文章チャンクが入り、Query:に質問文が入ります。
試してみた感想など
通常の、ベクトルストアだけを利用する Naive RAG(純粋な RAG)と比べると、応答内容が絞り込まれている印象です。
言い換えると、ハルシネーションが軽減される代わりに少しそっけない回答になっているような感じでした。
ただし、結果はプロンプトとパラメータのチューニング次第のような気もします。取得トリプレット数や辿るグラフ階層の数、取得チャンク数などを調整すれば結果が変わりそうです。
また、応答が少し遅い印象です。
LLMSynonymRetrieverで類義語抽出を LLM にさせている部分の待ち時間が余分にかかっているように見えました。
必要に応じてLLMSynonymRetrieverを外しても良いかもしれません。
そして、条件次第で RDBMS もグラフストアとして使用可能な印象も受けました。
辿るグラフ階層数が 1(デフォルト)であれば通常の JOIN で十分な気がします(階層が増えると厳しいかも)。