はじめに
watsonx.data 2.0.0 から CLI ("ibm-lh data-copy" コマンド) による Ingestion (データの取り込み) は Presto と Spark と Spark REST API の3つのモードをサポートするようになりました。
・Presto を使用するモードは、watsonx.data 1.1.x と同じ Prestoを使用するモードです。
・Spark を使用するモードは、watsonx.data 1.1.x と同じSparkを使用するモードです。
・Spark REST API を使用するモードは、watsonx.data 2.0.0 で追加された新しいモードです。
それぞれのモードでIngestionを実行するために ENABLED_INGEST_MODE 環境変数を設定します。
| ENABLED_INGEST_MODEの値 | モード |
|---|---|
| PRESTO | Prestoを使用するモード |
| SPARK_LEGACY | Sparkを使用するモード |
| SPARK | Spark REST APIを使用するモード |
今回は Spark REST API モードの CLI Ingestion の実行方法について ご紹介します。
前提
IBM Cloud Pak for Data (CP4D) 5.0.0/5.0.1上に「データ・ソース・サービス」の一つである watsonx.data 2.0.0/2.0.1 がインストールされている事。
CP4Dが5.0.0の場合はwatsonx.dataは2.0.0、CP4Dが5.0.1の場合はwatsonx.dataは2.0.1をインストールします。
本記事の検証は、CP4D 5.0.1 に watsonx.data 2.0.1 をインストールした環境を使用しています。
事前準備
1. ibm-lh-client のインストール
watsonx.data のクライアントツールである ibm-lh-client をクライアント・マシンにインストールします。本検証では Red Hat Enterprise Linux 8.6 に ibm-lh-client をインストールしています。
インストールは下記のマニュアルの手順に従って容易に実行する事ができます。
Installing ibm-lh-client
手順の中で、環境変数 LH_RELEASE_TAG にインストールする ibm-lh-client のバージョンを設定しますが、LH_RELEASE_TAG=latest に設定すると その時点での最新バージョンのパッケージがダウンロードされてインストールされます。2024年8月23日時点での最新バージョンは 2.0.1 となります。
2. Ingestionで取り込むデーター(ソース)、取り込み先(ターゲット)の表の準備
Ingestionで取り込むデーター、取り込み先の表を予め準備しておく必要があります。
本検証では取り込むデーターも取り込み先の表も、IBM Cloud Object Storage に作成したバケット内に用意しました。
取り込み先の表は、watsonx.data のWebコンソールのインフラストラクチャー・マネージャーでApache Iceberg タイプとして登録したターゲット用のカタログにスキーマを作成し、スキーマの下に表を作成しておきます。
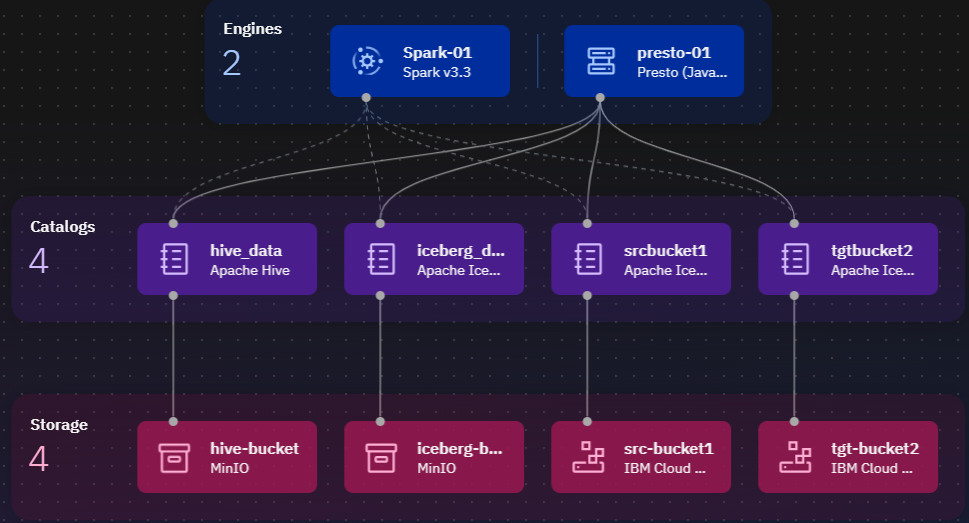
事前準備が完了した状態のインフラストラクチャー・マネージャーの表示は以下のようになります。watsonx.data ではバケットはストレージとして表示されます。
3. 環境変数の設定
Spark REST API を使用した CLI のIngestion を実行する場合、下記の環境変数を設定する必要があります。
| 環境変数名 | 環境変数の意味 |
|---|---|
| ENABLED_INGEST_MODE | Ingestionのモード |
| IBM_LH_SPARK_JOB_ENDPOINT | SparkアプリケーションV4のエンドポイント |
| SOURCE_S3_CREDS | ソースのバケットのS3資格情報 |
| TARGET_S3_CREDS | ターゲットのバケットのS3資格情報 |
| IBM_LH_SPARK_EXECUTOR_CORES | IngestionのExecutor ポッドのCPUコア数 (オプション)。デフォルトは1。 |
| IBM_LH_SPARK_EXECUTOR_MEMORY | IngestionのExecutor ポッドのメモリー (オプション)。デフォルトは1G。 |
| IBM_LH_SPARK_EXECUTOR_COUNT | IngestionのExecutor ポッドの数 (オプション)。デフォルトは1。 |
| IBM_LH_SPARK_DRIVER_CORES | IngestionのDriver ポッドのCPUコア数 (オプション)。デフォルトは1。 |
| IBM_LH_SPARK_DRIVER_MEMORY | IngestionのDriver ポッドのメモリー (オプション)。デフォルトは1G。 |
必須の環境変数の設定方法について説明していきます。
予め OCPクラスターにログインし、watsonx.data がインストールされているプロジェクトに変更しておきます。
例)
$ oc project cpd-operands
Now using project "cpd-operands" on server "https://api.66820424808b98001eb03c88.cloud.techzone.ibm.com:6443".
ENABLED_INGEST_MODE
「はじめに」に記述したとおり、ENABLED_INGEST_MODE には SPARK を設定します。
SPARKがデフォルトのモードで、ENABLED_INGEST_MODE 環境変数が設定されていない場合 SPARK モードとして実行されます。
例)
export ENABLED_INGEST_MODE=SPARK
SOURCE_S3_CREDS
Ingestionのソースファイルが含まれているバケットの資格情報を、下記のフォーマットで設定します。設定する値は使用するオブジェクト・ストレージのコンソール等から入手します。
AWS_ACCESS_KEY_ID=<access_key>,AWS_SECRET_ACCESS_KEY=<secret_key>,ENDPOINT_URL=<endpoint_url>,AWS_REGION=<region>,BUCKET_NAME=<bucket_name>
例)
export SOURCE_S3_CREDS="AWS_ACCESS_KEY_ID=XXXXXXXXXX,AWS_SECRET_ACCESS_KEY=YYYYYYYYYY,ENDPOINT_URL=https://s3.jp-tok.cloud-object-storage.appdomain.cloud,AWS_REGION=jp-tok,BUCKET_NAME=src-bucket1"
TARGET_S3_CREDS
Ingestionのターゲット側のバケットの資格情報を、SOURCE_S3_CREDSと同じフォーマットで設定します。設定する値は使用するオブジェクト・ストレージのコンソール等から入手します。
例)
export TARGET_S3_CREDS="AWS_ACCESS_KEY_ID=XXXXXXXXXX,AWS_SECRET_ACCESS_KEY=YYYYYYYYYY,ENDPOINT_URL=https://s3.jp-tok.cloud-object-storage.appdomain.cloud,AWS_REGION=jp-tok,BUCKET_NAME=tgt-bucket1"
IBM_LH_SPARK_ で始まる環境変数は、オプションのIngestionのエンジンの構成に関する環境変数です。Ingestionのパフォーマンスに影響を与えるため設定した方が良いでしょう。デフォルトでは最小のリソースしか確保されません。今回は下記の値を設定します。お客様の本番環境に設定する場合は事前に検証して最適な値を設定する必要があります。
export IBM_LH_SPARK_EXECUTOR_CORES=2
export IBM_LH_SPARK_EXECUTOR_MEMORY=4G
export IBM_LH_SPARK_EXECUTOR_COUNT=2
export IBM_LH_SPARK_DRIVER_CORES=2
export IBM_LH_SPARK_DRIVER_MEMORY=4G
4. "ibm-lh data-copy" コマンドに指定するパラメーターの決定
"ibm-lh data-copy" コマンドに指定するパラメーターを決定します。本記事では、ソースファイルとして S3 バケット内の Parquet ファイルを指定する場合に必要なパラメーターについてのみ説明します。
| パラメーター | パラメーターの意味 |
|---|---|
| source-data-files | S3 バケット内の Paquet ファイルか CSV ファイル、又はフォルダーへのパス。フォルダーのパスの場合は最後が"/"である必要があります。 |
| target-tables | <カタログ名>.<スキーマ名>.<テーブル名> の形式のターゲット表。 |
| user | Ingestionを実行するCP4Dのユーザー名 |
| password | Ingestionを実行するCP4Dのユーザーのパスワード |
| url | watsonx.dataのベースのURL |
| engine-id | SparkエンジンのID |
| instance-id | CP4DのインスタンスID |
| sync-status | Ingestionを同期モードで実行する (オプション) |
各パラメーターの設定ついて説明します。
source-data-files
"s3://<バケット名>/<フォルダー名>/<ファイル名>" 又は "s3://<バケット名>/<フォルダー名>/" の形式でソースファイルを指定します。
1個のファイルを指定する例)
--source-data-files s3://src-bucket1/folder1/test1.parquet
フォルダー名を指定する例)
--source-data-files s3://src-bucket1/folder1/
target-tables
"s3://<ターゲットのカタログ名>/<スキーマ名>/<ターゲット表名>" の形式でターゲット表を指定します。
例)
--target-tables tgtbucket1.target1.gvt_data_v
ingestion-engine-endpoint
hostname と port には何も指定しません。type=spark を指定します。
例)
--ingestion-engine-endpoint "hostname='',port='',type=spark"
user
CP4Dのインスタンスに接続するためのCP4Dのユーザーを指定します。
例)
--user cpadmin
password
CP4Dのインスタンスに接続するためのCP4Dのユーザーのパスワードを指定します
例)
--password zzzzzzzz
url
watsonx.dataのベースのURLを指定します。
"https://" + oc get route | grep "cpd " を実行した結果の HOSTの値 (結果の2列目) を指定します。"cpd " (cpdの後にブランクを指定) で grep してください。
例)
$ oc get route | grep "cpd "
cpd cpd-cpd-operands.apps.66820424808b98001eb03c88.cloud.techzone.ibm.com ibm-nginx-svc ibm-nginx-https-port reencrypt/Redirect None
--url https://cpd-cpd-operands.apps.66820424808b98001eb03c88.cloud.techzone.ibm.com
engine-id
Ingestionに使用するSparkのエンジンIDを指定します。
watsonx.data のWebコンソールからインフラストラクチャー・マネージャーを表示し、Ingestionに使用するSparkエンジンを選択して「詳細」に表示される エンジンID を指定します。
例)
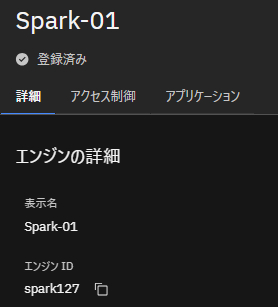
--engine-id spark127
instance-id
watsonx.dataのインスタンスIDを指定します。インスタンスIDは下記の2つの方法で取得できます。
① watsonx.dataのWebコンソールのURLから入手
例)
https://cpd-cpd-operands.apps.66820424808b98001eb03c88.cloud.techzone.ibm.com/watsonx-data/#/home?instanceId=1719823250083405
に含まれる instanceId=1719823250083405
② watsonx.dataのWebコンソールの左下にある「インスタンスの詳細」アイコン

を押すと表示されるインスタンスID

--instance-id 1719823250083405
sync-status
Spark REST API モードでは、"ibm-lh data-copy"コマンドを実行すると、"Ingest job submitted" が表示されてすぐに"Complete migration"が表示されて コマンドは終了しますが、実際の Ingestion はサブミットされたジョブから生成された Ingestion のポッドで非同期に実行されるため Ingestion の終了を検知する事ができません。
syn-status を指定すると Ingestion が完了してから"ibm-lh data-copy"コマンドが終了するため Ingestion の終了が明確になります。
例)
--sync-status
バッチモード Ingestion の実行
スクリプト・ファイルの作成
これまで説明した環境変数の設定と "ibm-lh data-copy" コマンドへのパラメーターを元にバッチモード Ingestion 用のスクリプト・ファイルを作成し、実行権限を付けます。
例)
$ cat spark-rest-batch-ingestion-parq-single_qiita.sh
export ENABLED_INGEST_MODE=SPARK
export IBM_LH_SPARK_JOB_ENDPOINT=https://cpd-cpd-operands.apps.66820424808b98001eb03c88.cloud.techzone.ibm.com/v2/spark/v3/instances/3f209068-3ba1-4cca-9df1-18ad655f3c8e/spark/applications
export SOURCE_S3_CREDS="AWS_ACCESS_KEY_ID=XXXXXXXXXX,AWS_SECRET_ACCESS_KEY=YYYYYYYYYY,ENDPOINT_URL=https://s3.jp-tok.cloud-object-storage.appdomain.cloud,AWS_REGION=jp-tok,BUCKET_NAME=src-bucket1"
export TARGET_S3_CREDS="AWS_ACCESS_KEY_ID=XXXXXXXXXX,AWS_SECRET_ACCESS_KEY=YYYYYYYYYY,ENDPOINT_URL=https://s3.jp-tok.cloud-object-storage.appdomain.cloud,AWS_REGION=jp-tok,BUCKET_NAME=tgt-bucket1"
export IBM_LH_SPARK_EXECUTOR_CORES=2
export IBM_LH_SPARK_EXECUTOR_MEMORY=4G
export IBM_LH_SPARK_EXECUTOR_COUNT=2
export IBM_LH_SPARK_DRIVER_CORES=2
export IBM_LH_SPARK_DRIVER_MEMORY=4G
./ibm-lh data-copy \
--source-data-files s3://src-bucket1/parquet_folder/test1.parquet \
--target-table tgtbucket1.target1.gvt_data_v \
--user cpadmin \
--password zzzzzzzz \
--url https://cpd-cpd-operands.apps.66820424808b98001eb03c88.cloud.techzone.ibm.com \
--engine-id spark127 \
--instance-id 1719823250083405 \
--sync-status
スクリプト・ファイルを実行します。
例)
$ ./spark-rest-batch-ingestion-parq-single_qiita.sh
Start data migration
Ingesting SECTION: cmdline
{'create_if_not_exist': False, 'csv_property': {'encoding': 'utf-8', 'escape_character': '\\', 'field_delimiter': ',', 'header': True, 'line_delimiter': '\n'}, 'engine_id': 'spark127', 'engine_name': 'Spark-01', 'execute_config': {'driver_cores': 2, 'driver_memory': '4G', 'executor_cores': 2, 'executor_memory': '4G', 'num_executors': 2}, 'instance_id': '1719823250083405', 'job_id': 'ingestion-cli-1724726777-6-b1fffc11ff34', 'source_data_files': 's3://src-bucket1/parquet_folder/test1.parquet', 'source_file_type': 'csv', 'start_timestamp': '1724726780490088348', 'status': 'starting', 'target_table': 'tgtbucket1.target1.gvt_data_v', 'username': 'cpadmin'}
Ingestion job status:starting
Ingestion job completed
Complete migration
最後に "Complete migration" が表示されれば Ingestion は成功です。
Ingestion ジョブが失敗した場合は、下記の手順で Ingestionのポッドの標準出力のログ を入手して、原因を調査します。
1.watsonx.data ではなく CP4D のWebコンソールに戻り、左上のナビゲーション・メニューの「管理」の中の「ストレージ・ボリューム」を選択します。

2.Sparkのストレージ・ボリュームを選択します。Sparkのストレージ・ボリューム名は、"<watsonx.dataがインストールされた名前スペース>::<Sparkのインスタンスを作成した時に指定したボリューム名>" となります。

3.「ファイル・ブラウザ」のタブを選択し、Sparkのボリュームの下に表示されている項目を展開します。この項目番号は Sparkのジョブの履歴を保管するSpark履歴サーバーのポッド ( spark-history-deployment-<ID> ) のIDのようですが詳細は不明です。
4.項目を展開すると、過去に実行したSparkのIngestionジョブのIDの一覧が表示されますので、Ingestionを実行した時に標準出力に表示された "Spark ingestion job <ジョブID> submitted." メッセージに表示されたジョブIDを探してクリックして展開します。ジョブIDは時系列順ではなく、ランダムに生成されると思われるジョブIDの数字の順に表示されます。

5.さらにジョブIDの下に表示される logs ファルダーをクリックすると右側に logs フォルダーに含まれるログの一覧が表示されますので、通常一番下に表示される spark-driver-<ジョブID>-stdou ファイルをチェックし、「ダウンロード」をクリックします。

6.ブラウザによりダウンロードされたファイルが表示されますので「開く」か「名前を付けて保存」を選択し、テキスト・エディターで開きます。
このログは Ingestion の Driver ポッドの標準出力のログで、Ingestionの実行状況が最も詳細に記録されるログですので、これを調査してIngestionの失敗の原因を特定します。
以上で、watsonx.data 2.0.1 で Spark REST API を使用した CLI によるバッチモード ingestion の実行方法の紹介を終わります。
Presto を使用した watsonx.data 2.0.1 でのCLI によるバッチモード ingestion の実行方法については以下の記事をご参照ください。
watsonx.data 2.0.1 で Presto を使用した CLI によるバッチモード ingestion を実行してみた
Sparkを使用した(SPARK LEGACY モード) watsonx.data 2.0.1 でのCLI によるバッチモード ingestion の実行方法については以下の記事をご参照ください。
watsonx.data 2.0.1 で Spark を使用した CLI によるバッチモード ingestion を実行してみた