はじめに
今回は、Retrieval-Augmented Generation (RAG) に代わる新しいアプローチ「Cache-Augmented Generation (CAG)」を提案する論文 Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks を紹介します。
参考文献:
B. J. Chan, C.-T. Chen, J.-H. Cheng & H.-H. Huang. "Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks" arXiv:2412.15605 (2024).
1 論文の概要
この論文では、RAG の課題であるリアルタイムの取得遅延、関連文書選択のエラー、システムの複雑性を解消するために、長い文脈を扱える LLM を活用した CAG を提案しています。CAG はすべての関連リソースを事前に LLM にロードし、キャッシュされたコンテキストを利用して推論を実施し、リアルタイムの取得を不要にします。
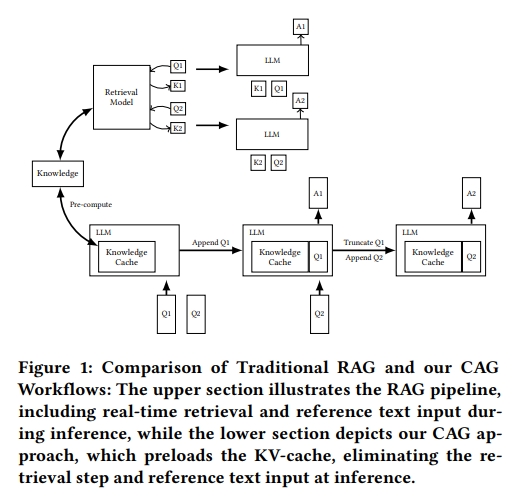
図 1: RAG と CAG のワークフロー比較(参考文献 Figure 1 参照)
上段は RAG のワークフローを示しており、リアルタイムで文書を検索(Retrieval)し、参照テキストを入力して推論します。一方、下段は CAG のワークフローを示しており、文書情報を事前に KV キャッシュとして保存することで、検索や参照テキストの入力を不要にしています。また、推論結果を KV として保存することで効率性を大幅に上げています。
以下は本論文を読む際に役立つ用語の簡単な説明です
| 用語 | 説明 |
|---|---|
| RAG | Retrieval-Augmented Generation。外部知識をリアルタイムで取得して生成に利用する手法 |
| CAG | Cache-Augmented Generation。外部知識を事前にロードし、キャッシュを利用して生成する手法 |
| LLM | Large Language Model。大規模言語モデル |
| KV キャッシュ | Key-Value キャッシュ。モデルの推論状態を保存したもの |
2 関連研究
従来の RAG システムは外部情報を動的に取得することで性能を高めてきましたが、本論文では Lu et al. (2024) や Gao et al. (2023) などの研究を引用し、長文脈 LLM の発展によりリアルタイム取得の必要性が低下していることを示唆しています。これにより、事前ロード型のアプローチが注目されています。
復習: Transformer における Attention
この論文を読むためには Transformer の Attention 理解が必須となりますので、ちょっと復習してみましょう。詳しく知りたい方はこちらの解説をご確認下さい。
論文紹介:Attention Is All You Need
Transformer の Attention 構造
Attention の基本的な計算式は次の通りです
\text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V
ここで
- $Q$: Query。必要な情報を示すベクトル
- $K$: Key。どんな情報があるかを示すベクトル
- $V$: Value。実際の情報の中身
- $d_k$: スケーリングファクター
🐣 イメージしやすい例
Q (質問): 「冷蔵庫にあるものは何?」
K (インデックス): 「冷蔵庫内のセクション(野菜、飲み物など)」
V (情報そのもの): 冷蔵庫に実際に入っている「トマト」「牛乳」など。
セルフアテンション (Self-Attention)
入力と計算
セルフアテンションは、入力系列内のトークン同士の関係を学習します
意義
- 各トークンが他のトークンとどの程度関連しているかを学習
- 系列内での文脈理解が向上
クロスアテンション (Cross-Attention)
入力と計算
クロスアテンションは、異なる系列間の情報を結びつけるために使用されます。Transformer のエンコーダ・デコーダ構造では、以下のように使用されます
- Query ($Q$): デコーダ側の生成状態
- Key ($K$), Value ($V$): エンコーダ側の出力
処理の流れ
- エンコーダが入力系列を変換して $K, V$ を生成
- デコーダがクエリ $Q$ を生成
- $Q$ がエンコーダの $K, V$ と結合し、関連情報を参照
🐣 この $K, V$ を事前に計算しておくことが CAG の本質的なアイディアです
デコーダでの処理順序
Transformer のデコーダでは、次のような順序で処理が進みます
- マスクド・セルフアテンション
- デコーダ自身のトークン間の依存関係をモデル化
- 未来のトークンを参照しないようマスク
- クロスアテンション
- エンコーダからの情報を結合
- $K, V$ はエンコーダの出力、$Q$ はセルフアテンションの結果
復習: RAG とは?
RAG(Retrieval-Augmented Generation)は、大規模言語モデル(LLM)の推論を外部知識で補強する技術です。RAG は単に文書をプロンプトに付与するだけの手法ではなく、「文書をどう検索し、どのように活用するか」の両方を包括的に設計するアプローチです。
RAG の 2 つの重要な構成要素
-
Retriever(検索部分)
質問に関連する文書を検索する役割を持つコンポーネントです。「どの文書を」「どのように」探すかが RAG の品質を大きく左右します。以下のような手法が使われます。- 単純な文字列マッチング
- ベクトル検索を用いた意味的な類似度検索
注意: Retriever 部分だけが重要と思われがちですが、Generator との連携があって初めてRAGの性能が発揮されます。
-
Generator(生成部分)
検索された文書を基に回答を生成する部分です。この段階では「文書をどのように統合して回答を生成するか」が重要です。- よく見る「検索された文書を単純にプロンプトに付与する方法」は RAG の一形態ですが、すべてではありません
- 本論文ではクロスアテンションを用いる高度なアプローチを中心に議論されています
補足: よくある誤解と正しい理解
- 誤解: RAG は Retriever 部分が重要で、Generator は単に検索結果をプロンプトに付与するだけである。
- 正しい理解: RAG は Retriever と Generator の両方が重要です。特に Generator では「検索結果をどのように統合し、回答を生成するか」が性能を大きく左右します。本質的には「生成モデルと検索結果の深い連携」が必要です。
例えば FiD(Fusion-in-Decoder)はクロスアテンションを用いる RAG の実装アプローチの一つで、複数の検索結果をエンコーダで個別に処理し、その出力をデコーダで統合しています。
検索フェーズ(Retrieval Step)
以下では本論文で対象としているクロスアテンションベースの RAG について説明します。
RAG は、ユーザーの質問 $X$ に基づいて外部知識ベース $D = {D_1, D_2, \dots, D_n}$ から関連文書を検索します。
- ユーザーの質問 $X$ をベクトル化
- 知識ベース $D$ から上位 $k$ 件の関連文書 $D_{\text{retrieved}} = {D'_1, D'_2, \dots, D'_k}$ を取得
🐣 $Q$ と紛らわしいのでユーザーの質問は $X$ にします。
エンコーダによる文書のエンコード
クロスアテンションベースの RAG では、取得された文書 $D_{\text{retrieved}}$ は単にプロンプトに付与されるのではなく、Transformerのエンコーダに入力され、Key ($K$) と Value ($V$) にエンコードされます。
K, V = \text{Encoder}(D_{\text{retrieved}})
- $K$: 文書の要約や特徴を表現するベクトル
- $V$: 文書そのものを符号化した内容
デコーダによる質問の処理とクロスアテンション
デコーダは、ユーザーの質問 $X$ をトークン化してセルフアテンションを計算後、エンコーダが提供した $K, V$ を使用してクロスアテンションを計算します。
\text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V
- Query ($Q$): デコーダが質問 $X$ から生成
- Key ($K$), Value ($V$): エンコーダが文書 $D_{\text{retrieved}}$ から生成
提案手法
3.1 Cache-Augmented Generation の概要
CAG (Cache-Augmented Generation) は、RAG の課題を解決する拡張手法で、外部知識を事前にキャッシュすることで効率的な生成を目指します。
3.1.1 手法の特徴
- 検索フェーズの省略
- KV キャッシュの事前計算
- 文書全体の一括処理
3.1.2 システムの構成要素
基本構成は以下の 3 つのコンポーネントです
- 外部知識のプリロードモジュール
- KV キャッシュの事前計算モジュール
- キャッシュを用いた推論モジュール
3.2 数学的フォーミュレーション
3.2.1 外部知識のプリロード
文書集合 $D = {D_1, D_2, \dots, D_n}$ に対して
C_{\text{KV}} = \text{KV-Encode}(D)
$C_{\text{KV}}$ は事前計算された KV キャッシュを表します。
3.2.2 推論フェーズ
ユーザーの質問 $X$ に対して、事前計算キャッシュを用いて応答 $Y$ を生成
Y = M(X \mid C_{\text{KV}})
3.2.3 キャッシュのリセット
新しく生成されたトークン $t_1, t_2, \dots, t_k$ に対して
C_{\text{KV}}^{\text{reset}} = \text{Truncate}(C_{\text{KV}}, t_1, t_2, \dots, t_k)
3.3 アルゴリズムの詳細
-
初期化フェーズ
- 文書集合 $D$ の KV キャッシュを計算し、$C_{\text{KV}}$ を保存
-
応答生成フェーズ
- 質問 $X$ と $C_{\text{KV}}$ を与え、応答を生成
- 必要に応じてキャッシュをリセット
🐣 レイテンシ削減と文脈考慮を両立するのが利点です
補足: CAG に Retriever はないの?
CAG の最大の特徴は、Retriever を完全に排除している点です。すべての文書の情報を事前にモデルの KV キャッシュとして保存し、推論時にモデルがアテンション機構を通じて関連情報を選択します。
RAG と CAG の比較
RAG の処理フロー
- ユーザークエリ $X$ を受け取り
- Retriever がクエリに関連する文書を検索
- 検索した文書 $D_{\text{retrieved}}$ をエンコーダで $K, V$ に変換
- デコーダがクエリ $X$ に基づき応答を生成
CAG の処理フロー
-
すべての文書 $D_{\text{all}}$ を事前に KV キャッシュへ変換
C_{\text{KV}} = \text{KV-Encode}(D_{\text{all}}) -
推論時、クエリ $X$ を受け取り、キャッシュ内の $K, V$ を直接参照
Y = M(X \mid C_{\text{KV}})
CAG は、すべての文書 $D_{\text{all}}$ を事前にキャッシュするといっても、均等に利用するわけではありません。アテンション機構を通じて 必要な情報を動的に選ぶ という仕組みになっています。
アテンションの仕組み
-
関連性スコアの計算
クエリ $X$ をモデルがエンコードしたベクトル $Q$ とし、キャッシュ内の $K$ との関連度を計算\text{Score}(Q, K) = \frac{Q K^\top}{\sqrt{d_k}} -
重み付けと情報抽出
スコアを Softmax で正規化し、関連性の高い $V$ を加重平均で抽出\text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{Q K^\top}{\sqrt{d_k}}\right)V
4 数値実験と結果
本論文では、SQuAD や HotPotQA を用いて RAG と CAG を比較しました。代表的な成果は以下の通りです
- 高い精度: CAG は従来の RAG に比べて一貫して高精度を示す (例: SQuAD で BERTScore 0.8265)
- 短い推論時間: プリロードされたコンテキストを活用し、大幅なレイテンシ削減 (例: HotPotQA で 94 秒 → 2 秒)
- シンプルな設計: Retriever が不要なため実装が容易
以下に代表的な数値例を示します
| Dataset | System | Top-k | BERT-Score |
|---|---|---|---|
| SQuAD (Small) | Sparse RAG | 10 | 0.8191 |
| SQuAD (Small) | Dense RAG | 10 | 0.8035 |
| SQuAD (Small) | CAG | - | 0.8265 |
5 まとめ
CAG は、長文脈 LLM の能力を最大限に活かし、RAG の複雑性や遅延を排除できる効率的な代替手段として注目されています。特に知識ベースを一括管理できる場合に大きな効果が期待できます。
おわりに
CAG の提案は、長文脈 LLM の可能性をさらに拡大するもので、Retriever を介さなくても十分に高精度な知識応答が実現できる点が魅力です。🐣私としては、この研究を通じて、生成 AI の効率とシンプルさを追求する重要性をあらためて感じました。今後は CAG を活用した具体的な事例が増えれば、より多様なユースケースでの有用性が実証されると考えています。
🐣 どんどん新技術が出てくるので付いていくのも大変ですね…