はじめに
TensorFlow(テンソルフロー)は、Googleが開発したディープラーニングのシステムでApache 2.0ライセンスで公開されています。
GPU対応、C++, Pythonに対応しています。
「GPUを使ってバリバリ動かしたぜ!」
といった投稿が多いので、あえて、AWS EC2 t2.micro(無料利用枠対象)にTensorFlow(Python版, Anaconda)をインストールし実行してみました。
AWS EC2 T2インスタンスのCPUクレジットについて理解の手助けになれば幸いです。
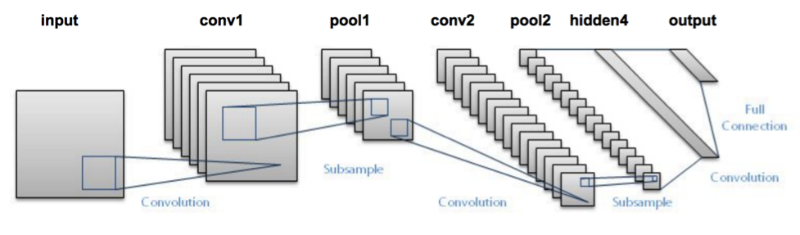
LeNet-5, MNIST
今回は、サンプルプログラム
tensorflow/models/image/mnist/convolutional.py
を動作させます。
モデルのLeNet-5はこんな感じです。(出典)
MNISTは、手書きの数字0~9のデータセットです。(MNIST DATABASE)
学習データが60000個、評価データが10000個あります。
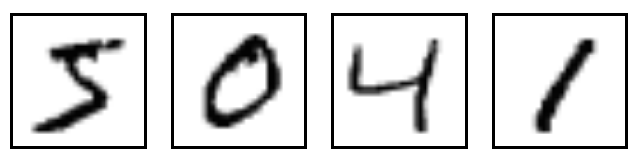
LeNet-5, MNISTともに、こちらの論文で発表されています。
[LeCun et al., 1998]
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, november 1998
今回のTensorFlowのサンプル(convolutional.py)を使うと、99.2%程度の正解率を達成することができます。
※ scikit-learnのsvmでMNISTの学習を行うと、正解率は97%程度です。ただし、ディープラーニングは学習時間が何十倍、何百倍かかります。
AWS EC2にTensorFlowをインストール
1. WS EC2
Ubuntu Server 16.04 LTS (HVM), SSD Volume Type ⇒ t2.micro
を選択します。
2. Puttyの設定(Windowsの人向け)
- Session > Host Name
ubuntu@[public_dns_name] - Connection > SSH > Auth > Authentication parameters > Private key file for authentication
[*.ppk file]
3. Anaconda + TensorFlow
後々、Pythonをバリバリ使う場合に備えて、Anaconda上にTensorFlowをインストールします。
-
Anacondaダウンロード
$ mkdir tensorflow $ cd tensorflow $ curl https://repo.continuum.io/archive/Anaconda3-4.2.0-Linux-x86_64.sh -o Anaconda3-4.2.0-Linux-x86_64.sh -
Anacondaインストール
ライセンスへの同意、インストールパス、.bashrcにPATHを設定するか聞かれます。$ bash Anaconda3-4.2.0-Linux-x86_64.sh >>> (ENTER) >>> yes [/home/ubuntu/anaconda3] >>> (ENTER) PATH in your /home/ubuntu/.bashrc ? [yes|no] [no] >>> yesインストールが終わったら、PATHを認識させるために、ログアウト&ログイン します。
Anacondaの動作確認をします。$ conda -V conda 4.2.9 -
TensorFlowインストール
tensorflow環境をAnacondaに作成します。$ conda create -n tensorflow python=3.5 Proceed ([y]/n)? yAnacondaのtensorflow環境にTensorFlowをインストールします。
$ source activate tensorflow (tensorflow)$ conda install -c conda-forge tensorflow The following NEW packages will be INSTALLED: mkl: 11.3.3-0 mock: 2.0.0-py35_0 conda-forge numpy: 1.11.2-py35_0 pbr: 1.10.0-py35_0 conda-forge protobuf: 3.0.0b2-py35_0 conda-forge six: 1.10.0-py35_0 conda-forge tensorflow: 0.10.0-py35_0 conda-forge Proceed ([y]/n)? yちなみに、AnacondaのTensorFlow環境を終了させるコマンドはこちら。
(tensorflow)$ source deactivate次回以降、AnacondaのTensorFlow環境を開始するコマンドはこちら。
(tensorflow)$ source activate tensorflowTensorFlow環境に切り替えないと、TensorFlow実行時に下記エラーがでます。
>>> import tensorflow as tf Traceback (most recent call last): File "<stdin>", line 1, in <module> ImportError: No module named 'tensorflow'TensorFlowがインストールされたディレクトリの確認。
(tensorflow)$ python -c 'import os; import inspect; import tensorflow; print(os.path.dirname(inspect.getfile(tensorflow)))' /home/ubuntu/anaconda3/envs/tensorflow/lib/python3.5/site-packages/tensorflow -
TensorFlow動作確認
Hellow TensorFlow!とTensorFlowで計算をしてみます。$ source activate tensorflow (tensorflow)$ python ... >>> import tensorflow as tf >>> hello = tf.constant('Hello, TensorFlow!') >>> sess = tf.Session() >>> print(sess.run(hello)) Hello, TensorFlow! >>> a = tf.constant(10) >>> b = tf.constant(32) >>> print(sess.run(a + b)) 42 -
TMNIST動作確認
(tensorflow)$ python /home/ubuntu/anaconda3/envs/tensorflow/lib/python3.5/site-packages/tensorflow/models/image/mnist/convolutional.py --self_test Running self-test. Initialized! Step 0 (epoch 0.00), 6.7 ms Minibatch loss: 9.772, learning rate: 0.010000 Minibatch error: 92.2% Validation error: 0.0% Test error: 0.0% test_error 0.0以上で、準備は整いました。
AWS EC2 t2.microでLeNet-5 MNISTを実行
それでは、実行してみます。
(tensorflow) $ python /home/ubuntu/anaconda3/envs/tensorflow/lib/python3.5/site-packages/tensorflow/models/image/mnist/convolutional.py
Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes.
Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes.
Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes.
Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes.
Extracting data/train-images-idx3-ubyte.gz
Extracting data/train-labels-idx1-ubyte.gz
Extracting data/t10k-images-idx3-ubyte.gz
Extracting data/t10k-labels-idx1-ubyte.gz
Initialized!
Step 0 (epoch 0.00), 6.8 ms
Minibatch loss: 12.053, learning rate: 0.010000
Minibatch error: 90.6%
Validation error: 84.6%
Step 100 (epoch 0.12), 432.6 ms
Minibatch loss: 3.276, learning rate: 0.010000
Minibatch error: 6.2%
Validation error: 7.2%
Step 200 (epoch 0.23), 435.2 ms
Minibatch loss: 3.457, learning rate: 0.010000
Minibatch error: 14.1%
Validation error: 3.9%
Step 300 (epoch 0.35), 430.3 ms
Minibatch loss: 3.204, learning rate: 0.010000
Minibatch error: 6.2%
Validation error: 3.1%
Step 400 (epoch 0.47), 431.9 ms
Minibatch loss: 3.211, learning rate: 0.010000
Minibatch error: 9.4%
Validation error: 2.5%
順調に学習が進んでいきます。
100ステップごとに状況を表示しています。
| 項目 | 意味 |
|---|---|
| Step | 学習回数 |
| epoch | 学習データ全部を使った回数 |
| ms | 1回の学習にかかった平均時間 |
| Minibatch loss | 学習データを間引いた数 |
| learning rate | 学習をどのくらい慎重に進めるかのパラメータ |
| Minibatch error | 学習データのエラー率 |
| Validation error | 検証データのエラー率 |
最終的には、Vaildation errorを小さくすることを目標にしています。
プログラムのパラメータは次のようになっています。
| 項目 | 設定 |
|---|---|
| 終了条件 | エポック>10 |
| バッチサイズ | 64 |
| 活性化関数 | ReLU |
しばらくの間は順調に学習が進んでいきますが、途中で学習速度が10分の1にスローダウンしていきます。
Step 5000 (epoch 5.82), 434.0 ms
Step 5100 (epoch 5.93), 431.1 ms
Step 5200 (epoch 6.05), 430.0 ms
Step 5300 (epoch 6.17), 434.3 ms
Step 5400 (epoch 6.28), 533.1 ms
Step 5500 (epoch 6.40), 581.7 ms
Step 5600 (epoch 6.52), 581.4 ms
Step 5700 (epoch 6.63), 580.6 ms
Step 5800 (epoch 6.75), 582.4 ms
Step 5900 (epoch 6.87), 785.4 ms
Step 6000 (epoch 6.98), 975.2 ms
Step 6100 (epoch 7.10), 969.0 ms
Step 6200 (epoch 7.21), 2485.7 ms
Step 6300 (epoch 7.33), 4477.5 ms
Step 6400 (epoch 7.45), 4492.2 ms
Step 6500 (epoch 7.56), 3791.0 ms
Step 6600 (epoch 7.68), 4414.7 ms
Step 6700 (epoch 7.80), 4485.0 ms
Step 6800 (epoch 7.91), 4259.3 ms
Step 6900 (epoch 8.03), 3942.3 ms
モニタリングを見てみると、CPU使用率が最初は100%使っていましたが、途中から10%に制限されています。
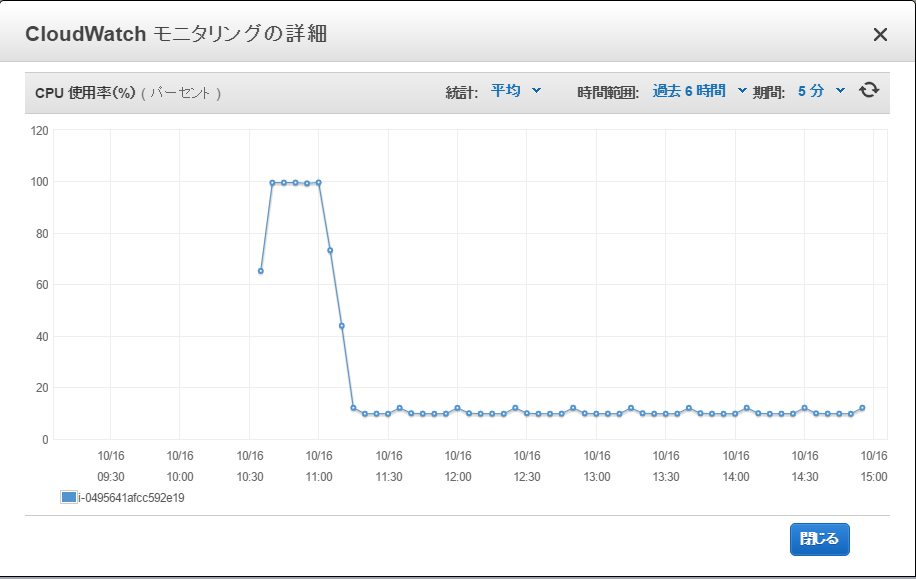
t2.microインスタンスのメモリには余裕があります。
$ free -h
total used free shared buff/cache available
Mem: 990M 374M 372M 4.4M 243M 574M
Swap: 0B 0B 0B
CPUクレジット
CPUクレジットの制限事項
CPUクレジット残高を確認してみると最初にチャージされていた30カウントを使い切ってしまったことが分かります。
CPUクレジット残高
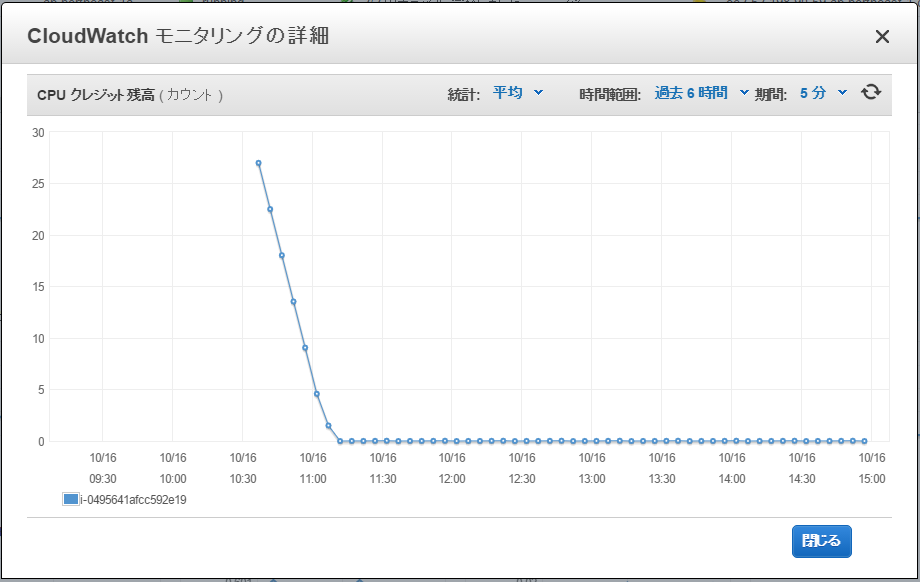
CPUクレジット使用状況
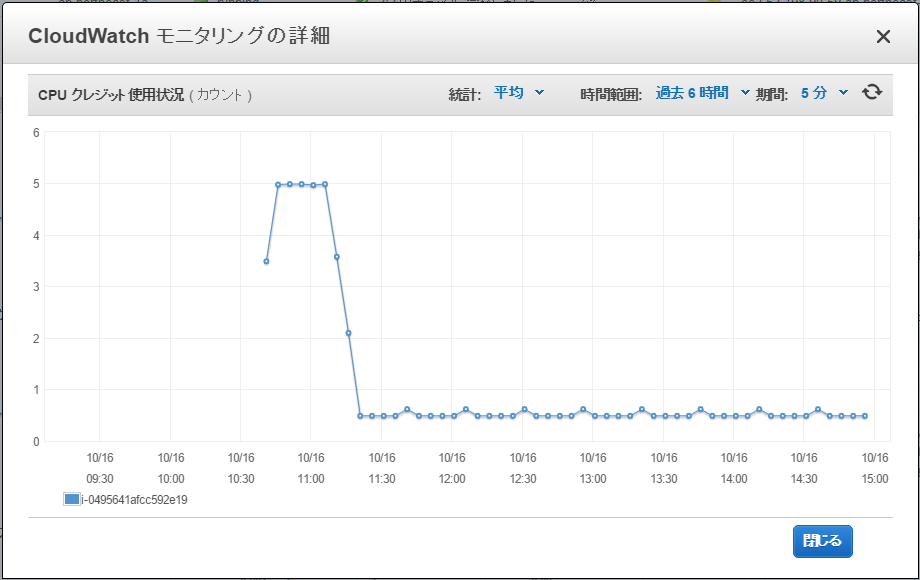
さて、CPUクレジットの値は、何を意味しているのでしょうか。
実は、この値は、CPUを何分間100%使えるかの貯金を表しています。
なので、CPUクレジットがチャージされている間は、CPUクレジット使用状況のグラフを見ると、5分間に5カウントづつ消費しています。
t2.microで使っているCPUは「Intel(R) Xeon(R) CPU E5-2676 v3 @ 2.40GHz」になります。
$ cat /proc/cpuinfo | grep "model name"
model name : Intel(R) Xeon(R) CPU E5-2676 v3 @ 2.40GHz
そしてt2.microは、CPU性能の10%を利用する権利を持っています。
10%をどのように割り当てられているかというと、1時間に6カウントのCPUクレジットが割り当てられます。1カウントで1分間CPUを100%利用する権利が得られるので、1時間(60分)で6カウントというのがちょうど10%に相当します。
CPUクレジット残高は、最大24時間分貯めることができます。t2.microであれば144カウント(6カウント/時間×24時間)まで貯めることができます。
また、t2.microインスタンスを作成した直後は、約30カウント割り当てられています。
インスタンスを停止させるとCPUクレジットは0にクリアされてしまいます。
t2.microでTensorFlowのLeNet-5 MINISTを実行し完走するには、CPUを100%使い続けて60分ほどかかります。
インスタンスを作成し、そのままTensorFlowのLeNet-5 MINISTを実行すると、30カウント分のCPUクレジットが不足していることになります。
停止させてCPUクレジットが0にクリアされてしまったt2.microでは、60カウント分のCPUクレジットが不足していることになります。
インスタンス作成直後、30カウント分足りないからといって、30カウントたまるのを5時間待ってから実行するのも、30カウント不足している状態でスローで走らせつづけるのも、どちらも約6時間かかり、終了時刻、インスタンス起動時間に差はありません。
CPUクレジットを効率的に使う方法について検討してみる
CPUクレジットの制限事項を考慮したうえで、CPUを効率よく利用する方法について考え見ます。
インスタンスを新規作成する
CPUクレジットを稼ぐということだけを考えるのであれば、AMIにバックアップを取って毎回AMIをベースにインスタンスを作り直せば、スタート時の30カウント分が得です。
-
スローダウン時間(15分)を利用する
プログラムをあまり変えずにCPUカウントを稼ぐ方法として、15分間かけてスローダウンしていくことを利用することが考えられます。
CPU利用率が100%の状態でCPUクレジットが0になった場合、15分間かけてCPU利用率が10%になるように制限がかかっていきます。
CPUクレジットが0になった時点で、次に、CPUクレジットがある程度付与されるまでプログラムを一旦ストップさせると、CPUクレジットが0の状態で、15分間は10%以上のCPU性能を使うことができるので、少しは計算が進みます。
ところが、この方法には裏面があります。
まず、CPU利用率100%の期間が短いと、短時間で100%から10%へのスローダウンしてしまいます。
また、CPU利用率は、CPUクレジットがあっても、いきなり0%から100%にはならず、0%から100%になるには、6分程度かかってしまいます。
CPU利用率の制限は、定常的に100%だった状態から10%になるのは15分かかりますが、瞬間的に40%だったものが10%になるのは5分しかかかりません。
CPU利用率が100%になるためには、6分間分のCPUクレジットを貯める必要があり、60分間計算を停止させておく必要があります。
60分間、低速で計算を続ければCPU100%換算で6分間分の計算が進みますが、CPUを停止させてしまうと、この分の計算が進みません。
計算の停止と開始を繰り返す方法は、CPU利用率のスローダウンのスピードが速いのと、CPU利用率の立ち上がりにそれなりの時間がかかるため、「あまり効果があるとは言えない」ようです。
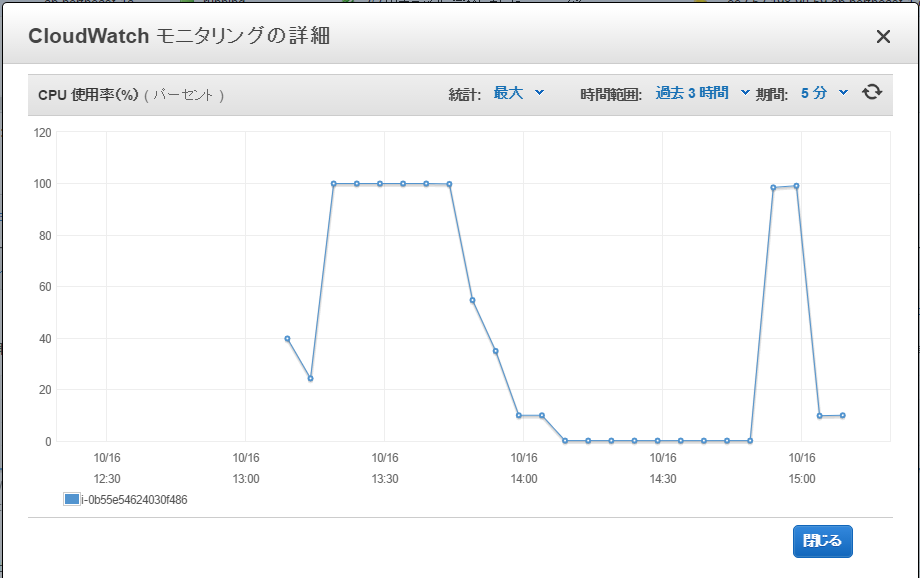
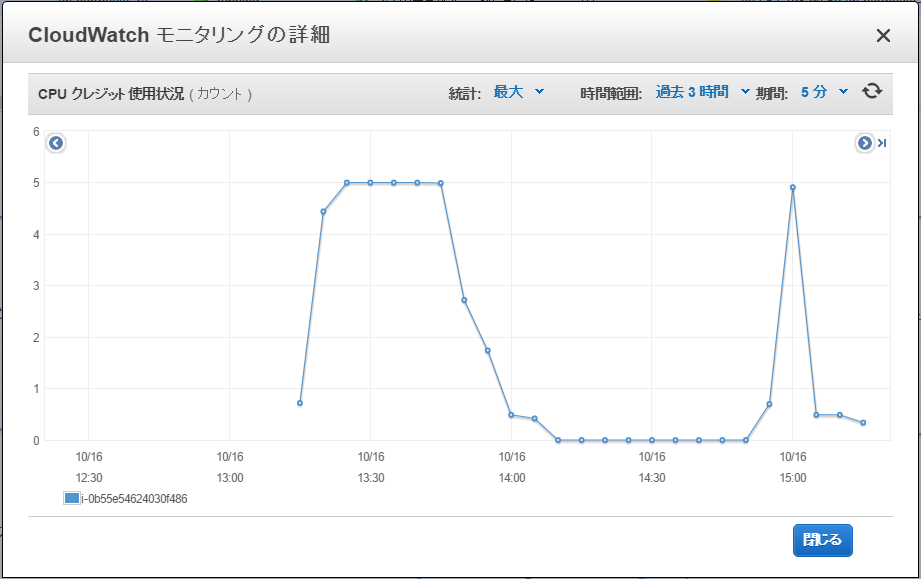
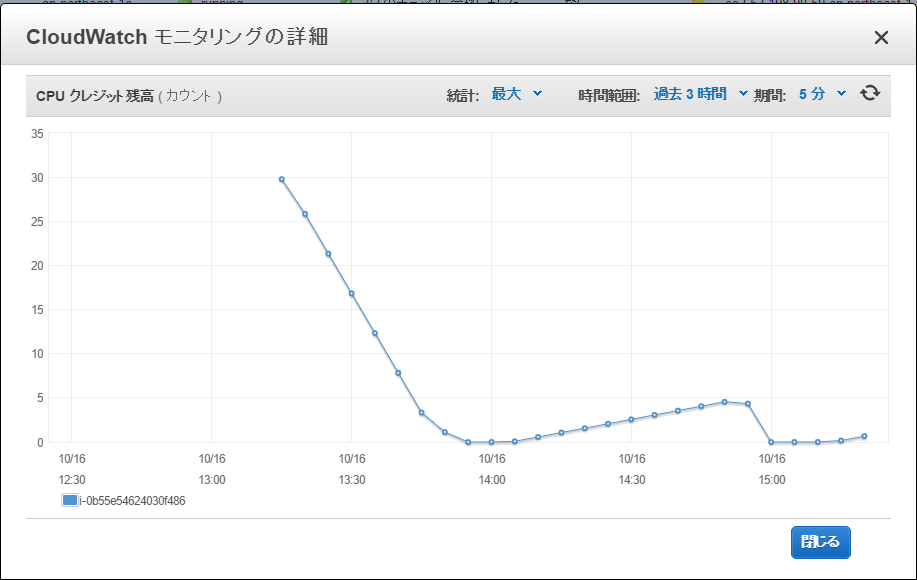
以下のようなスリープ処理を追加して試してみます。cpustop.pystart_time = time.time() ... cpu_start_time = time.time() # ★開始時刻 for step in xrange(int(num_epochs * train_size) // BATCH_SIZE): ... if step % EVAL_FREQUENCY == 0: elapsed_time = time.time() - start_time avrg_time = 1000 * elapsed_time / EVAL_FREQUENCY ... # ★平均計算時間が3000msec以上になったら50分間スリープする if avrg_time > 3000: print("sleep t2.micro cpu. passed time=%d" % (time.time() - cpu_start_time)) time.sleep(3000) print("run t2.micro cpu. passed time=%d" % (time.time() - cpu_start_time)) start_time = time.time()グラフはこんな感じになります。10%づつスローに計算する代わりに、100%の計算を瞬間的に行っています。
CPU使用率
CPUクレジット使用状況
CPUクレジット残高
複数台のインスタンスをリレーさせる
システムとしては複雑になりますが、AWSのアラーム機能を利用してtc2.microを生成/削除しながら切り替えて、途中経過をS3に保存するような仕組みが効果がありそうです。ただ、そんなシステムを作るぐらいだったら、高性能なインスタンスをお金を払って借りたほうがよいという声も聞こえてきそうです。
事前にインスタンスを生成しておく
t2.microは、24時間立ち上げて何もしなければ、CPUクレジットが144カウントまで蓄積されます。
144分以内に収まる計算であれば、前日にインスタンスを作成して放置しておくのも手です。
AWS Lambda
リクエストを300秒以内に抑える必要がありますが、これがうまくできるようであれば、選択肢になりそうです。
EC2 t2.microと同じCPUでLambdaを実行するのであれば、500ステップ毎に区切って計算することができれば利用できそうです。
計算時間が約230秒、計算の途中経過の読み込みと保存に60秒、予備を10秒で割り当てる計算になります。
今回の計算は、メモリ512MBあればOKなので、Lambdaの無料枠で9日間の連続計算が可能です。
ところが、Lambdaの料金計算は、EC2とは考え方が異なります。
Lambdaの場合は、メモリが増えればCPUのスピードが向上していきます。
300秒ごとにスイッチする回数をできだけ減らしたいですね。そうすると、メモリは上限の1536MB使ったほうが、スイッチする回数が減ります。メモリを1536MB使った場合の1か月の無料枠は3日(266,667秒)になります。
AWS Lambdaのマシンスペックの調査結果はこちら(リンク)。
AlexNet MNIST
続いては、AlexNet MNISTのベンチマークをEC2 t2.micro(無料利用枠対象)で実行し、GPUと比較してみます。
プログラムは、tensorflowのインストールディレクトリ配下の下記になります。
tensorflow/models/image/alexnet/alexnet_benchmark.py
プログラムのコメントによると、GPUではこのような性能がでるようです。
Forward pass:
Run on Tesla K40c: 145 +/- 1.5 ms / batch
Run on Titan X: 70 +/- 0.1 ms / batch
Forward-backward pass:
Run on Tesla K40c: 480 +/- 48 ms / batch
Run on Titan X: 244 +/- 30 ms / batch
一方、EC2 t2.microを実行したコンソールログはこのようになります。
EC2 t2.microがCPU 100%で動作していても、GPUとEC2 t2.microは約100倍の差があります。
conv1 [128, 56, 56, 64]
pool1 [128, 27, 27, 64]
conv2 [128, 27, 27, 192]
pool2 [128, 13, 13, 192]
conv3 [128, 13, 13, 384]
conv4 [128, 13, 13, 256]
conv5 [128, 13, 13, 256]
pool5 [128, 6, 6, 256]
2016-10-24 16:18:03.743222: step 10, duration = 9.735
2016-10-24 16:19:40.927811: step 20, duration = 9.675
2016-10-24 16:21:17.593104: step 30, duration = 9.664
2016-10-24 16:22:53.894240: step 40, duration = 9.684
2016-10-24 16:24:29.968737: step 50, duration = 9.597
2016-10-24 16:26:06.527066: step 60, duration = 9.686
2016-10-24 16:27:43.229298: step 70, duration = 9.689
2016-10-24 16:29:19.643403: step 80, duration = 9.679
2016-10-24 16:30:56.202710: step 90, duration = 9.588
2016-10-24 16:32:22.877673: Forward across 100 steps, 9.553 +/- 0.962 sec / batch
2016-10-24 16:42:27.229588: step 10, duration = 28.700
2016-10-24 16:49:33.216683: step 20, duration = 72.885
...
そして、Forward-backwardのstep 20あたりで、CPUクレジット30を使い切ります。
あとは徐々にスローダウンし、CPU 10%での動作になり、GPUの1000分の1のスピードで延々と計算が続きます。
う~ん。全く勝負になりません。
おわりに
ちょっと、視点を変えてみます。
AWS EC2 t2.micro(無料利用枠)でTensorFlowのLeNet-5 MNIST(convolutional.py)を実行して達成感を得るためにはどうしたらよういでしょうか。
インスタンス生成直後は、CPUクレジットが30あるわけですから、30~40分でそれなりに計算が終わるように設定してみます。
NUM_EPOCHS = 6
そうです。変更は1か所だけです。学習回数をCPUクレジット内におさまるように設定してあげればOKです。
それでは、TensorFlowで、楽しいDeepLearning生活を!!