概要
インターリービング/マルチリービングによるランキング学習を勉強しています。
@mpkato先生による記事およびinterleavingモジュールが非常に参考になります。
interleavingモジュールにはsimulation用実装も含まれているのですが、特にドキュメント等が無いようなので、その使い方の共有を兼ねてシミュレーション方法を残しておきます。
- 単純ランカーの優劣判定
- 複合ランカーの最適化
の2つを行いました。
参考資料
interleaving全般について:
https://qiita.com/mpkato/items/99bd55cc17387844fd62
新手法PPM(Pairwise Preference multileaving)について:
https://qiita.com/mpkato/items/cc7fc36d74268af130d5
PPMの現論文 [2017 Oosterhuis & de Rijke]
https://arxiv.org/pdf/1711.09454.pdf
この論文の、
Algorithm 1 General pipeline for multileaved comparisons
が、interleavingを含んだ全体アルゴリズムになっていてわかりやすい。
(1)単純ランカーの優劣判定
理解のためのポイント
「interleavingのアルゴリズム≠interleavingを使ったランキング学習のアルゴリズム」
であることに注意すること。
後者の流れを、
- 比較対象のランキング(複数)から混合ランキングを作成してユーザに提示
- ユーザの応答(クリック)を収集
- 比較対象のランキングの優劣を評価
- モデルパラメータを更新
とすると、interleavingは1と3で使うロジックという位置づけ。
また、interleaving自体が何か学習パラメータを持っているのではなく、それは呼び出し側が持っている(=ランキングモデル)。
パラメータとしては、例えばランキング間の優劣マトリックス。
[Oosterhuis & de Rijke]では「Pij」=ランキング i => jに対する優劣スコア。
pypi「interleaving」モジュール
@mapkato先生作のinterleavingにより、interleavingの実装およびシミュレーションができる。
ただしsimulationの方は、ソースのみで説明資料はない。
参考コード:
- MQ2007データセットを使って10000インプレッションを試行
- 100インプレッション終了毎にエラー率を測定
- "informative"ユーザの行動パラメータは原論文のTable 2に基づく
- MQ2007にはHITS情報はないので代わりに(適当に)DIR smoothingを加えて5ランキングとした
- 変数「il_result」がランキング優劣マトリックスに相当
from interleaving import TeamDraft, PairwisePreference
from interleaving.simulation import Simulator, User, Ranker
filePath = "MQ2007/Fold1/train.txt"
simulator = Simulator([filePath], 20) # 第2引数はクエリ提示数
# create "informative" user
user = User(click_probs=[0.4, 0.7, 0.9], stop_probs=[0.1, 0.3, 0.5])
# refs: https://arxiv.org/ftp/arxiv/papers/1306/1306.2597.pdf
rankers = [
Ranker(lambda dic: dic[25]), # BM25
Ranker(lambda dic: dic[40]), # JM smoothing
Ranker(lambda dic: dic[41]), # PageRank
Ranker(lambda dic: dic[15]), # TF/IDF
Ranker(lambda dic: dic[35]) # DIR smoothing
]
# method = TeamDraft
method = PairwisePreference
ndcg_result = simulator.ndcg(rankers, 30) # 第2引数は第何位までみるか
il_result = []
for i in range(10000):
res = simulator.evaluate(rankers, user, method)
il_result += res
if i > 0 and i % 100 == 0:
error = simulator.measure_error(il_result, ndcg_result)
print(error)
シミュレーション結果
- MQ2007の5分割データセットの各々を対象に、上記コード(10000回インプレッション)を3回実行した
※ Simulator()の第2引数を20にしたので、20 * 10000インプレッション? - 100回毎にエラー率を計測
- 各「100回毎のエラー率」データが、5 * 3 = 15個できるので、その平均を取った
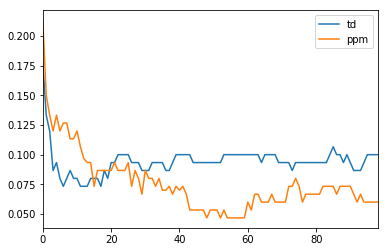
- 平均する母数が少ないので揺らぎが大きいが、おおむね納得できる結果となっている?
- 平均ではなく個別の10000回試行同士をみると、エラー率がTD < PPMとなる場合もかなりある
(2)複合ランカーを最適化
上記ではインターリービングにより、静的な単純ranker(=アイテムの単一属性(例:BM25)によるranker)同士の優劣を学習するシミュレーションを(論文追試的に)行った。
実務的には、複数属性を重みづけして最適なランカーを探る話になる。
例:[2016 Schuth]
http://www.anneschuth.nl/wp-content/uploads/wsdm2016-multileave-gradient-descent.pdf
この場合には、各属性を線形結合する「重みベクトル」が学習対象になる。
学習がうまく進めば、結果的に、その重みで生成したランキングは徐々に「良い」ランキング=nDCG値が高くなっていくはず。
今回はそれをシミュレーションで確認する。
参考コード:
- MQ2007データセット(Fold1)を使った
- "informative"ユーザの行動パラメータはこの論文のTable 2に基づく
- MQ2007にはHITS情報はないので代わりに(適当に)DIR smoothingを加えて5つの素性を使う
- アルゴリズムやパラメータはほぼ[2016 Schuth]の通り
- 試行回数と重み更新タイミングは2通り試した
- long実験:10000回試行で、100試行ごとに重み更新
- short実験:1000回試行で、10試行ごとに重み更新
アルゴリズムの説明:
各々のランカーがランキングに使うのはアイテムの単一素性ではなく、複数素性を重みづけ加算したもの。その重みを学習するのが目的。
「現在の重み」を保持するメインランカーに対し、その重みをランダムに微変化させた4つのランカーを用意し、それら5ランカーをマルチリービングで競わせる。
所定回数インプレッションを行ったら、優劣マトリックスをみて、「メインランカー」に勝ったランカーを判定し、それらの重みの平均的な「方向」に近づくように、「現在の重み」を更新する。これを繰り返す。
# -*- encoding: utf-8 -*-
"""
複数指標重みづけランキングの最適化シミュレーション
線形和の重みWが学習されるにつれて、複数指標重みづけランキングのnDCGが上がっていくはず
"""
from collections import defaultdict
from interleaving import TeamDraft, PairwisePreference
from interleaving.simulation import Simulator, User, Ranker
import os
import csv
import numpy as np
# BM25(25)、言語モデル(JMスムージング)(40)、PageRank(41)、HITS、TF-IDF(15)
# refs: https://arxiv.org/ftp/arxiv/papers/1306/1306.2597.pdf
alpha = 0.03
delta = 1
ranker_size = 5
target_keys = [15, 25, 35, 40, 41] # 注目する素性のIDリスト
target_keys_count = len(target_keys)
def gen_rand(size):
m = np.random.uniform(low=-1.0, high=1.0, size=size)
m /= (np.linalg.norm(m))
return m
class Ranker2(object):
def __init__(self, keys, w):
self.keys = keys # ex [15,25,35,40,41]
self.w = w
def rank(self, documents):
result = sorted(
documents,
key=lambda x: np.array([x.features[k] for k in self.keys]) @ self.w.T,
reverse=True
)
return result
def create_rankers(w, size):
unit_vecs = np.array([np.zeros(target_keys_count)] + [gen_rand(target_keys_count) for i in range(size - 1)])
weight_vecs = [w + delta * u for u in unit_vecs]
rankers = [Ranker2(target_keys, _w) for _w in weight_vecs]
return (unit_vecs, rankers)
def get_superior_rankers(il_result):
prefs = defaultdict(int)
for res in il_result:
for r in res:
prefs[r] += 1
winner_indexes = []
for i in range(1, ranker_size):
wins = prefs[(i, 0)] - prefs[(0, i)]
if wins > 0:
winner_indexes.append(i)
return winner_indexes
def main(filePath, method):
csvfile = open("%s.csv" % method.__name__, 'w', encoding="utf8", newline='')
writer = csv.writer(csvfile, quoting=csv.QUOTE_ALL)
writer.writerow(["iteration", "ndcg"])
simulator = Simulator([filePath], 10)
# refs: "Sensitive and Scalable Online Evaluation with Theoretical Guarantees"[Oosterhuis 2017]
user = User(click_probs=[0.4, 0.7, 0.9], stop_probs=[0.1, 0.3, 0.5])
# 初期重みはとりあえずランダムで
w = np.random.uniform(low=0, high=1.0, size=target_keys_count)
w /= (np.linalg.norm(w))
unit_vecs, rankers = create_rankers(w, ranker_size)
il_result = []
for i in range(10001):
res = simulator.evaluate(rankers, user, method)
il_result += res
if i > 0 and i % 100 == 0:
ndcg_result = simulator.ndcg(rankers, 20)
writer.writerow([i, ndcg_result[0]])
print(ndcg_result[0])
# 勝者ランカーを決定
winner_indexes = get_superior_rankers(il_result)
# 重み更新(勝者ランキングに用いた単位ベクトルの平均値を加算)
if winner_indexes:
w += alpha * np.average(unit_vecs[winner_indexes], axis=0)
il_result = []
unit_vecs, rankers = create_rankers(w, ranker_size)
csvfile.close()
if __name__ == "__main__":
method = TeamDraft
# method = PairwisePreference
main(os.path.join(os.path.dirname(__file__), "MQ2007/Fold1/train.txt").replace("\\","/"), method)
シミュレーション結果
※ pp*=Pairwise Preference Multileaving
※ td*=Team Draft Multileaving
※ 縦軸はnDCG(初期重みをランダムに決定しているため初期値はバラバラ)
short実験

long実験

振り返り
- ちゃんと学習することを確認できた
- PPMの方がTDより学習速度が速い?
- 初期重みを共有したうえで「PPM VS TD」をすべきだった・・・そうすればグラフも説得力が出てきたのに。