はじめに
生成AIを業務プロセスに組み込む際、期待以上の効果が得られないと感じることはないでしょうか?
汎用的な生成AIは手軽に利用できるため、調査や情報整理といった用途では十分に有用です。
一方で、インターネット上に公開されている情報を主に参照する汎用AIだけでは、業務プロセスの中で十分に活用しきれないケースも少なくありません。
その背景には、個人が持つナレッジをもとに業務を進める場面が多く、インターネット上の情報だけでは業務を十分に遂行できない、という実情があるように思います。
また、こうした個人のナレッジは言語化やドキュメント化が難しく、暗黙知として個人に蓄積されがちです。
本記事では、Bedrock Knowledge Bases を用いて RAG を構築し、AWSサポートへの問い合わせ内容といった個人のナレッジをチーム全体で共有できる「ナレッジ共有システム」を作成してみます。
課題の整理
普段、AWSの構築や運用で行き詰まった際には、AWSサポートに問い合わせを行っています。
その中で、AWSサポートから得られた有益な知見をどのように活用・共有していくかという点について、現場では次のような課題を感じることがありました。
- 過去に誰かが似たような内容をAWSサポートに問い合わせていた気がするけど思い出せない...
- 公式ドキュメントには載っていない情報をAWSサポートから共有してもらったが、個人のナレッジにとどまり、チーム内での共有ができていない...
こうした課題を解消するため、個人がAWSサポートに問い合わせた内容をチーム全体のナレッジとして共有し、継続的に育てていけるナレッジ共有システムの仕組みをRAGで作ってみます!
動作確認のやり方
以前、IdC (IAM Identity Center) の仕様について調べていたとき、公式ドキュメントの内容を正確に読み取れず混乱したことがあります。
具体的には、「IdCを利用し、OIDCベースで外部(個別)アプリケーションへのSSOができるのか?」という点です。
こちらのドキュメント「IAM アイデンティティセンターの組織インスタンスとアカウントインスタンス」より、スタンドアロンのAWSアカウントでOIDCのカスタマーアプリケーションは「はい」になっていました。
なので、OIDCベースで外部アプリケーションへのSSOはできるものだと思いました。

しかし、これについてはAWSサポートに確認し、「できない」という回答をいただきました。
IdCを利用して外部アプリケーションへのSSOを実現したい場合、SAMLを使うしかないようです。
これについて、Bedrockのプレイグラウンドを開き、Nova 2 Liteに聞いてみます。
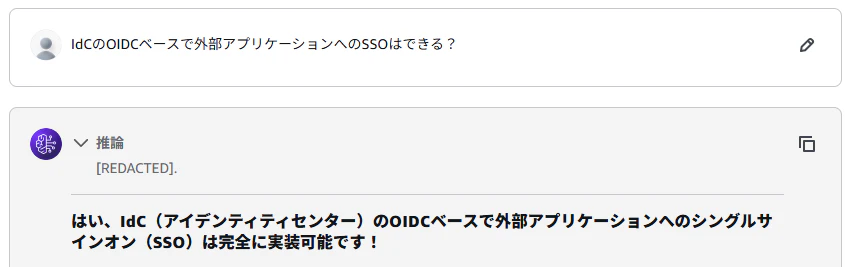
「できる」と返ってきました。つまり、回答を誤っています。
本記事におけるナレッジ共有システムの動作確認方法として、RAGに同じ質問を投げたときに「できない」と返ってきたらOKとします。
環境準備
構成イメージは以下の通りです。
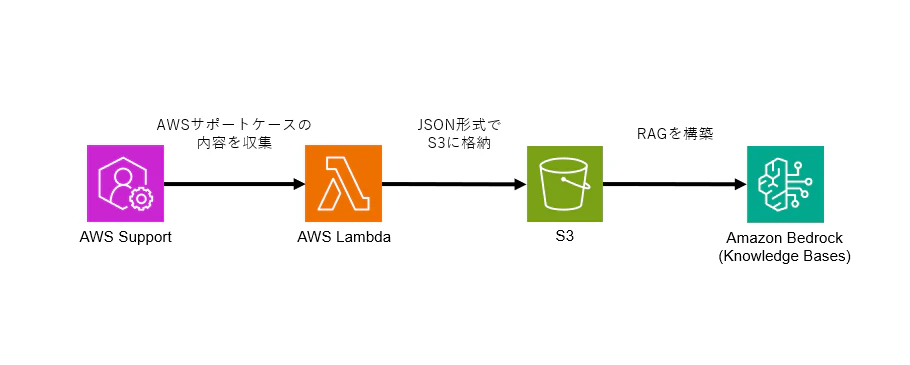
箇条書きになりますが、以下のとおりリソースを作成します。
【Lambda】
- ランタイムはPython3.14にする
- エラートレースのためCloudWatchLogsを作成する
- AWSサポート・S3バケット・CloudWatchLogsへのアクセス権限を付与するため、Lambda用のIAMロールを作成する
- 環境変数「S3_BUCKET_NAME」を作成し、S3バケット名を定義する
- タイムアウト時間を延長する (MAX15分)
【Bedrock Knowledge Bases】
- ベクトルストアとして作成する
- データソースはS3バケットにする
- モデルはNova 2 Liteにする
Bedrock Knowledge Basesの構築方法については、以下のドキュメントをご参考下さい。
Lambdaでは直近90日以内に起票したAWSサポートケースを収集します。
ソースコードは以下のとおりです。生成AIに作ってもらいました。
本記事に掲載するソースコードは検証・学習用のサンプルです。
内容の正確性や動作は保証していません。
import json
import boto3
from datetime import datetime, timedelta
from typing import Dict, List, Any
import os
# AWSクライアントの初期化
support_client = boto3.client('support', region_name='us-east-1')
s3_client = boto3.client('s3')
def lambda_handler(event, context):
"""
AWSサポートの問い合わせ内容を収集し、S3に保存するLambda関数
"""
try:
# 環境変数からS3バケット名を取得
bucket_name = os.environ.get('S3_BUCKET_NAME')
if not bucket_name:
raise ValueError("S3_BUCKET_NAME環境変数が設定されていません")
# 直近3か月のサポートケースを取得
print("サポートケースの取得を開始します...")
cases = get_recent_support_cases(days=90)
print(f"{len(cases)}件のサポートケースを取得しました")
# データを加工
print("データの加工を開始します...")
processed_data = process_cases_for_ai(cases)
# S3に保存
print("S3への保存を開始します...")
s3_key = save_to_s3(bucket_name, processed_data)
return {
'statusCode': 200,
'body': json.dumps({
'message': '処理が正常に完了しました',
'cases_count': len(cases),
's3_bucket': bucket_name,
's3_key': s3_key
}, ensure_ascii=False)
}
except Exception as e:
print(f"エラーが発生しました: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps({
'error': str(e)
}, ensure_ascii=False)
}
def get_recent_support_cases(days: int = 90) -> List[Dict[str, Any]]:
"""
直近N日間のサポートケースを取得
Args:
days: 取得する日数(デフォルト: 90日)
Returns:
サポートケースのリスト
"""
cases = []
after_time = (datetime.now() - timedelta(days=days)).isoformat()
# ケースIDのリストを取得
paginator = support_client.get_paginator('describe_cases')
page_iterator = paginator.paginate(
includeResolvedCases=True,
includeCommunications=False,
afterTime=after_time,
language='ja' # 日本語のケースを取得
)
for page in page_iterator:
for case in page['cases']:
# 各ケースの詳細情報(コミュニケーション履歴含む)を取得
case_details = get_case_with_communications(case['caseId'])
cases.append(case_details)
return cases
def get_case_with_communications(case_id: str) -> Dict[str, Any]:
"""
ケースIDからケースの詳細とコミュニケーション履歴を取得
Args:
case_id: サポートケースID
Returns:
ケースの詳細情報(コミュニケーション履歴含む)
"""
# ケースの詳細を取得
response = support_client.describe_cases(
caseIdList=[case_id],
includeCommunications=True,
language='ja'
)
if response['cases']:
return response['cases'][0]
return {}
def process_cases_for_ai(cases: List[Dict[str, Any]]) -> Dict[str, Any]:
"""
サポートケースを加工
Args:
cases: サポートケースのリスト
Returns:
加工されたデータ
"""
processed_cases = []
for case in cases:
# 各ケースを構造化
processed_case = {
'case_id': case.get('caseId', ''),
'subject': case.get('subject', ''),
'status': case.get('status', ''),
'service_code': case.get('serviceCode', ''),
'category_code': case.get('categoryCode', ''),
'severity_code': case.get('severityCode', ''),
'submitted_by': case.get('submittedBy', ''),
'time_created': case.get('timeCreated', ''),
'recent_communications': []
}
# コミュニケーション履歴を整理
communications = case.get('recentCommunications', {}).get('communications', [])
for comm in communications:
processed_comm = {
'submitted_by': comm.get('submittedBy', ''),
'time_created': comm.get('timeCreated', ''),
'body': comm.get('body', ''),
'attachment_count': len(comm.get('attachmentSet', []))
}
processed_case['recent_communications'].append(processed_comm)
# サマリーテキストを生成
processed_case['summary_text'] = generate_summary_text(processed_case)
processed_cases.append(processed_case)
# メタデータを追加
result = {
'metadata': {
'generated_at': datetime.now().isoformat(),
'total_cases': len(processed_cases),
'data_source': 'AWS Support API',
'purpose': 'Bedrock Knowledge Base'
},
'cases': processed_cases
}
return result
def generate_summary_text(case: Dict[str, Any]) -> str:
"""
ケースのサマリーテキストを生成
Args:
case: 処理済みケース情報
Returns:
サマリーテキスト
"""
summary_parts = [
f"【ケースID】{case['case_id']}",
f"【件名】{case['subject']}",
f"【サービス】{case['service_code']}",
f"【カテゴリ】{case['category_code']}",
f"【重要度】{case['severity_code']}",
f"【ステータス】{case['status']}",
f"【作成日時】{case['time_created']}",
f"【コミュニケーション数】{len(case['recent_communications'])}件"
]
# コミュニケーション内容の要約
if case['recent_communications']:
summary_parts.append("\n【コミュニケーション履歴】")
for i, comm in enumerate(case['recent_communications'][:5], 1): # 最初の5件
summary_parts.append(f"\n{i}. {comm['time_created']} - {comm['submitted_by']}")
# 本文の最初の200文字を抽出
body_preview = comm['body'][:200] + ('...' if len(comm['body']) > 200 else '')
summary_parts.append(f" {body_preview}")
return "\n".join(summary_parts)
def save_to_s3(bucket_name: str, data: Dict[str, Any]) -> str:
"""
加工したデータをS3に保存
Args:
bucket_name: S3バケット名
data: 保存するデータ
Returns:
S3オブジェクトキー
"""
# ファイル名にタイムスタンプを含める
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
s3_key = f"support_knowledge/{timestamp}_support_cases.json"
# JSON形式で保存
json_data = json.dumps(data, ensure_ascii=False, indent=2)
# S3にアップロード
s3_client.put_object(
Bucket=bucket_name,
Key=s3_key,
Body=json_data.encode('utf-8'),
ContentType='application/json',
Metadata={
'generated_at': data['metadata']['generated_at'],
'total_cases': str(data['metadata']['total_cases'])
}
)
print(f"データをS3に保存しました: s3://{bucket_name}/{s3_key}")
return s3_key
ソースコードについて、要点をまとめます。
- Support API はバージニア北部リージョンでの固定運用が基本なので、us-east-1 を指定
- ケース情報を日本語で取得
- describe_cases を paginator で回すことでケース件数が多くても全件取得可能
- AI検索用に summary_text を別途生成し、検索・理解を補助
RAGを動かしてみる
プレイグラウンドに投げたプロンプトと同じプロンプトを用いて、Bedrock Knowledge Basesに聞いてみます。
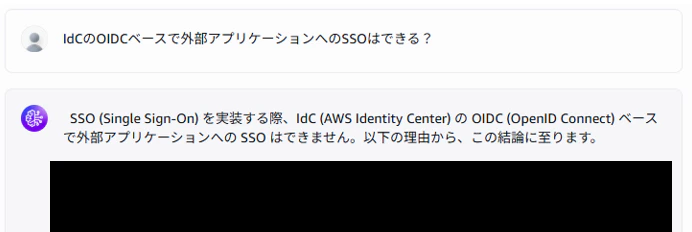
「できない」と返ってきました!
S3バケットに格納されたAWSサポートの問い合わせ内容を正しく読み取り、RAGとして機能していることが分かります。
以上より、Bedrock Knowledge Basesを活用し、ナレッジ共有システムを作成することができました。
所感
Bedrock Knowledge Basesを利用してみて思ったことは、動作が早く、正確だということです。
一般的な汎用AIだと推論に時間がかかってしまう印象ですが、RAGにすると推論時間がかなり短くなりました。
ほしい情報も正しく出力してくれたので、非常に有効だと感じました。
また、汎用AIを用いて同様のRAGを作りましたが、動作が遅く、回答が安定しないのでBedrock Knowledge Basesの方が実務向きだと感じました。
おわりに
ご一読いただき、誠にありがとうございました!
少しでも役に立つ情報を共有できていれば幸いです。