はじめに
実験の全体像
なぜ分子毒性予測が重要か?
新薬開発において、候補化合物の毒性評価は最もコストと時間がかかるステップの一つです。動物実験やin vitro試験に先立ち、計算化学的なアプローチで毒性リスクを事前スクリーニングできれば、創薬プロセスの効率化に大きく貢献します。
本実験では以下を実現します:
- 200+ の化合物(既知の毒性・安全性データ付き)のキュレーションデータセット構築
- RDKit による分子記述子 19 種 + Morgan フィンガープリント 1024 bitの計算
- 4 種の ML モデルによる毒性二値分類と5-fold 交差検証
- Permutation Importance・部分依存プロットによる説明可能性の確保
- SMARTS パターンによる構造アラート(トキシコフォア)検出
環境
| 項目 | バージョン |
|---|---|
| OS | Ubuntu 24.04 (WSL2) |
| Python | 3.12 |
| RDKit | 2024.09 |
| scikit-learn | 1.8.0 |
| matplotlib | 3.10 |
| seaborn | 0.13 |
| NumPy | 2.3 |
| pandas | 2.3 |
| 実行環境 | Claude Code (claude-opus-4-6) |
pip install --break-system-packages rdkit scikit-learn matplotlib seaborn scipy
Step 1: データセット構築 -- 207 分子のキュレーション
化合物の選定方針
| カテゴリ | 例 | 件数 |
|---|---|---|
| 毒性化合物 (Toxic) | アフラトキシン B1, ベンゼン, ホルムアルデヒド, ダイオキシン, サリン, DDT, ストリキニーネ, ニコチン, テトロドトキシン 等 | 106 |
| 安全化合物 (Non-toxic) | カフェイン, アスピリン, ビタミン C, グルコース, 各種アミノ酸, フラボノイド類, テルペン類 等 | 101 |
| 合計 | 207 |
毒性化合物には、IARC 発がん性リスト、急性毒性の高い化学兵器・天然毒素・マイコトキシン・工業化学物質を含みます。安全化合物には、食品添加物・必須アミノ酸・ビタミン・植物ポリフェノール等を選定しました。
分子記述子の計算
RDKit で以下 19 種の分子記述子を計算しました。
| 記述子 | 説明 | 毒性群 (mean) | 安全群 (mean) |
|---|---|---|---|
| MW | 分子量 | 188.95 | 200.17 |
| LogP | 脂溶性 (分配係数) | 0.79 | 0.23 |
| TPSA | 極性表面積 | 50.32 | 81.56 |
| HBD | 水素結合ドナー数 | 1.20 | 2.91 |
| HBA | 水素結合アクセプター数 | 2.62 | 3.80 |
| RotatableBonds | 回転可能結合数 | 2.08 | 3.42 |
| AromaticRings | 芳香環数 | 0.41 | 0.58 |
| FractionCSP3 | sp3 炭素比率 | 0.47 | 0.58 |
| NumHeteroatoms | ヘテロ原子数 | 4.15 | 4.61 |
| HeavyAtomCount | 重原子数 | 11.20 | 13.96 |
| LabuteASA | 可接近表面積 | 71.62 | 82.12 |
| BertzCT | Bertz 複雑度 | 306.54 | 311.53 |
| ... | (他 7 種) | ... | ... |
さらに Morgan フィンガープリント (radius=2, 1024 bits) を各分子について計算し、合計 1043 次元の特徴量ベクトルを構成しました。
記述子分布の比較
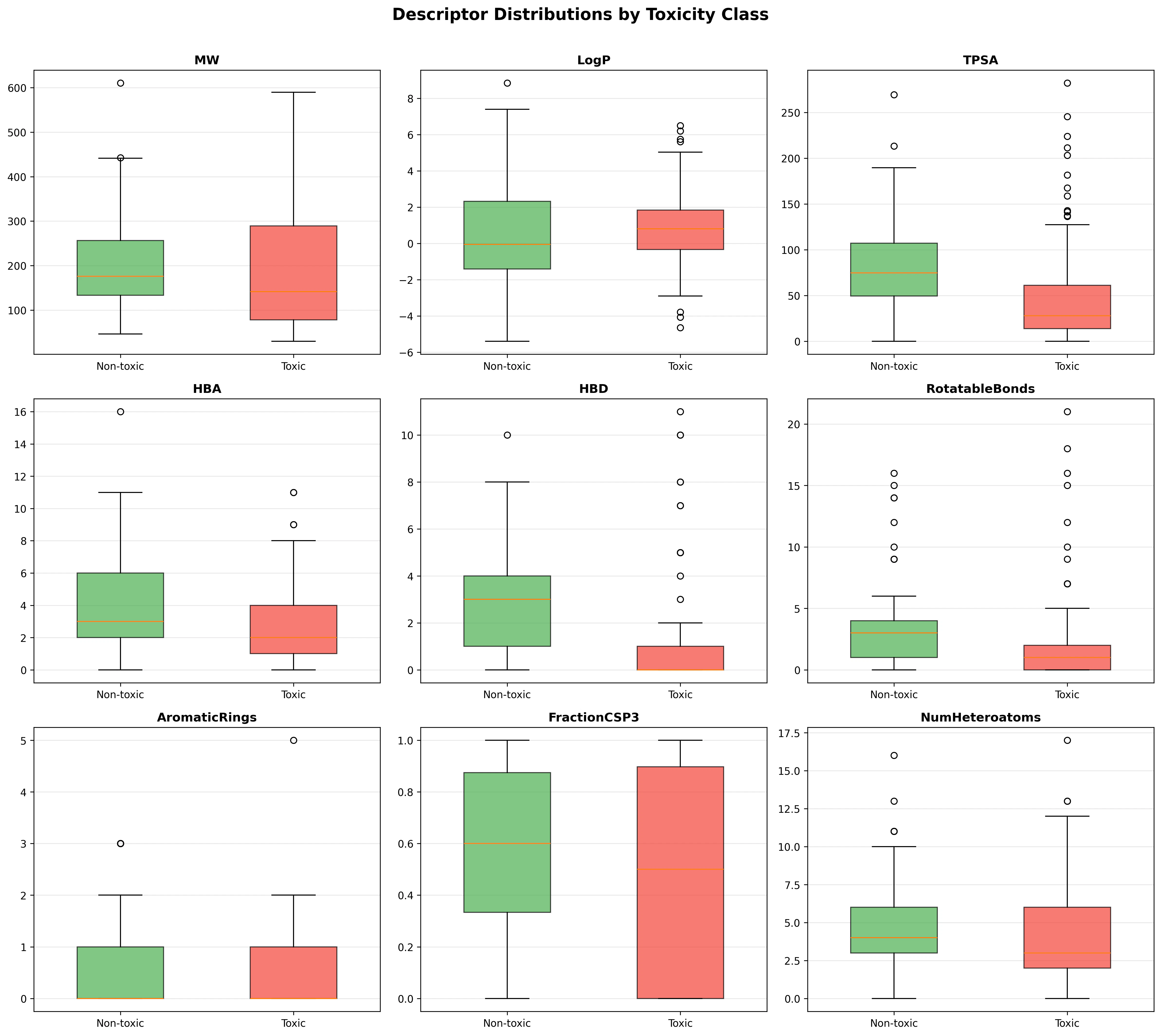
主な傾向:
- HBD(水素結合ドナー): 安全化合物の方が有意に高い。糖類・アミノ酸など親水性分子が多いため
- TPSA(極性表面積): 安全化合物で高い傾向。毒性化合物は脂溶性が高く膜透過性が高い
- LogP: 毒性化合物の方がやや高い。脂溶性の高い化合物は生体膜に蓄積しやすい
Step 2: 探索的データ分析(EDA)
特徴量間の相関
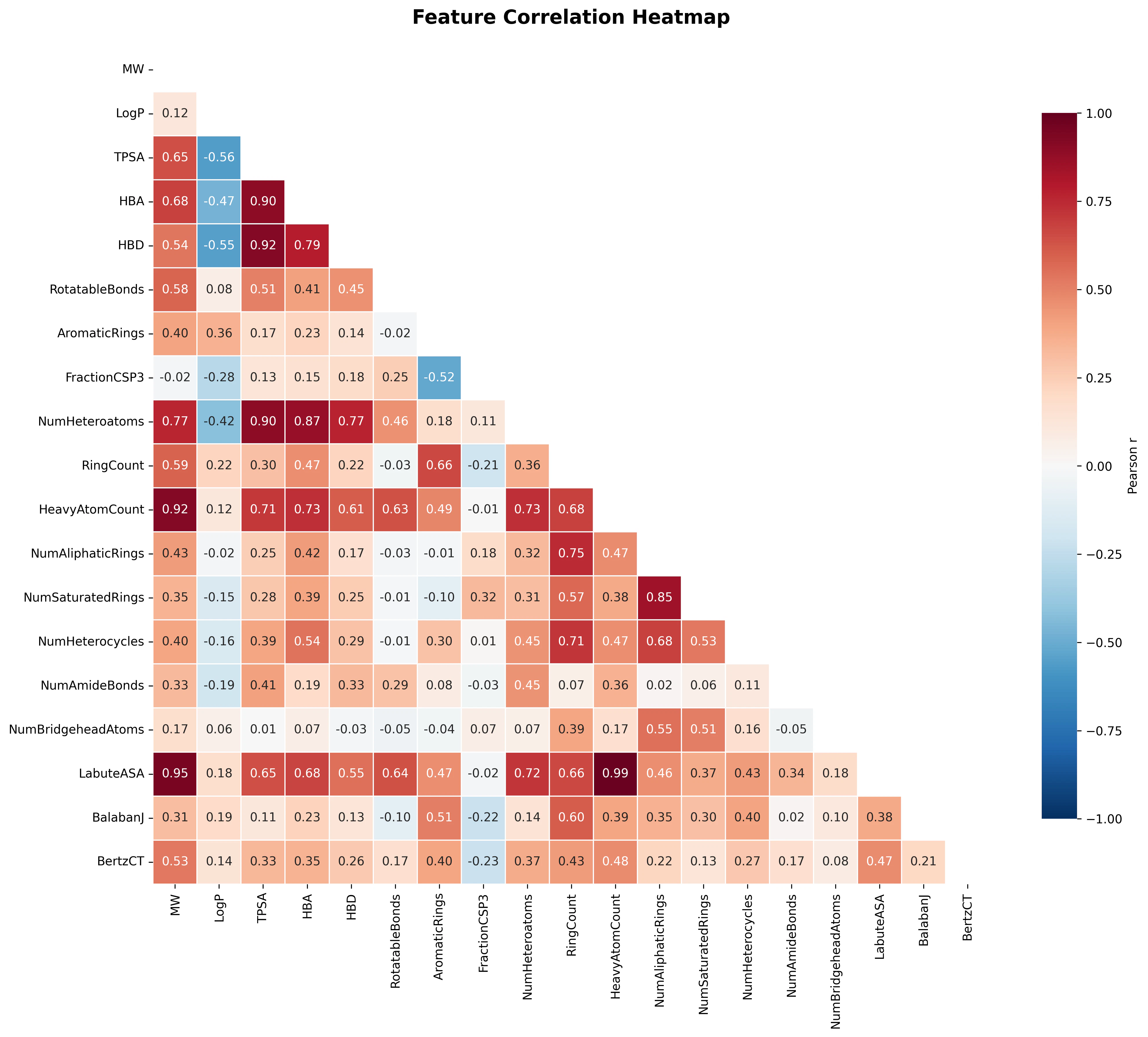
相関分析から得られた知見:
- MW と HeavyAtomCount: r ≈ 0.98(当然、重原子数が増えれば分子量も増える)
- MW と LabuteASA: r ≈ 0.96(分子が大きくなれば表面積も増大)
- TPSA と HBA/HBD: 中〜強い正の相関(極性官能基が多ければ極性表面積も大きい)
- LogP と FractionCSP3: 弱い負の相関(sp3 が多いと脂溶性は必ずしも高くない)
多重共線性の観点から、MW・HeavyAtomCount・LabuteASA は冗長性がありますが、Random Forest のような非線形モデルではこれが性能に大きく影響しないため、今回はすべて投入しています。
Step 3: 機械学習モデルの訓練と評価
実験設定
- Train/Test split: 80/20(stratified, random_state=42)
- 前処理: 記述子のみ StandardScaler で標準化、フィンガープリントは 0/1 のまま
- 交差検証: 5-fold StratifiedKFold
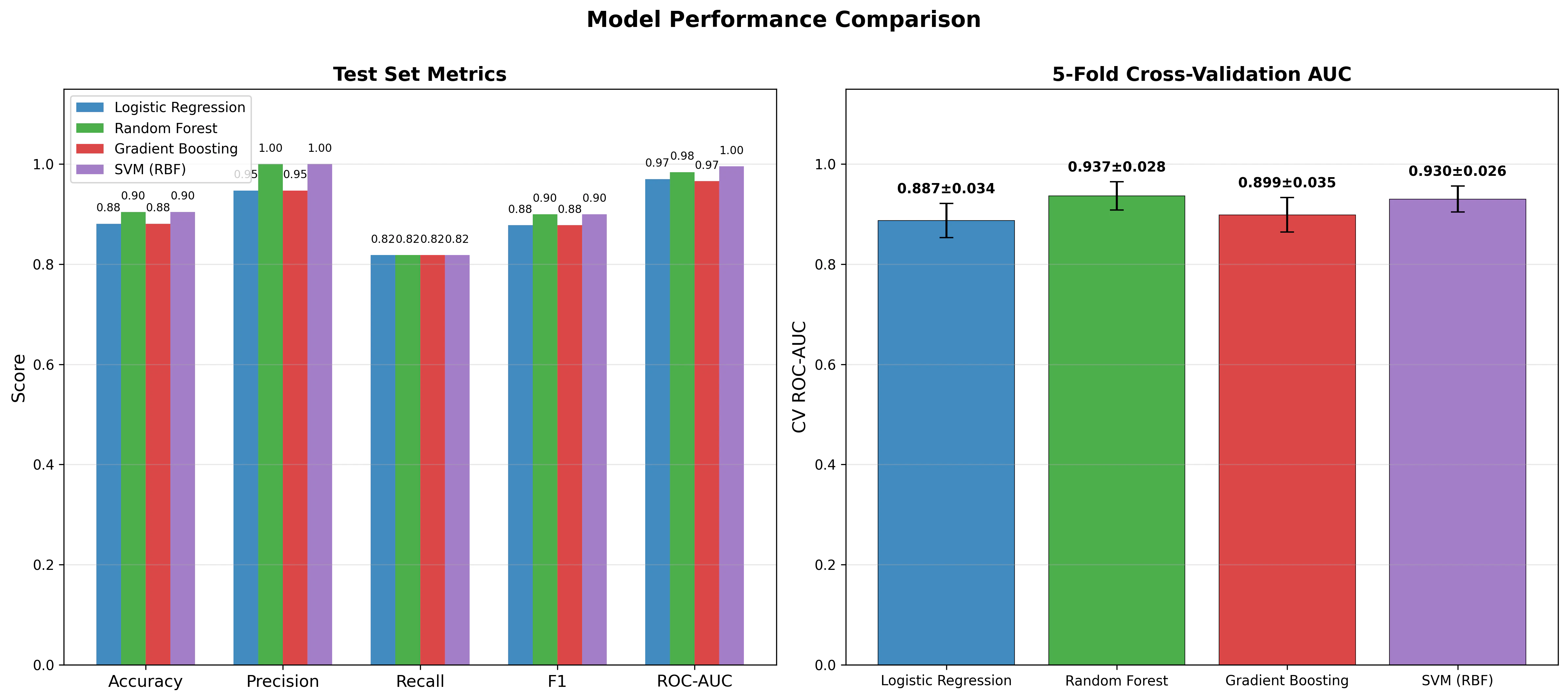
モデル性能一覧
| モデル | Accuracy | Precision | Recall | F1 | ROC-AUC | CV-AUC (mean±std) |
|---|---|---|---|---|---|---|
| Logistic Regression | 0.881 | 0.947 | 0.818 | 0.878 | 0.970 | 0.888 ± 0.034 |
| Random Forest | 0.905 | 1.000 | 0.818 | 0.900 | 0.984 | 0.937 ± 0.028 |
| Gradient Boosting | 0.881 | 0.947 | 0.818 | 0.878 | 0.966 | 0.899 ± 0.035 |
| SVM (RBF) | 0.905 | 1.000 | 0.818 | 0.900 | 0.995 | 0.930 ± 0.026 |
ROC 曲線
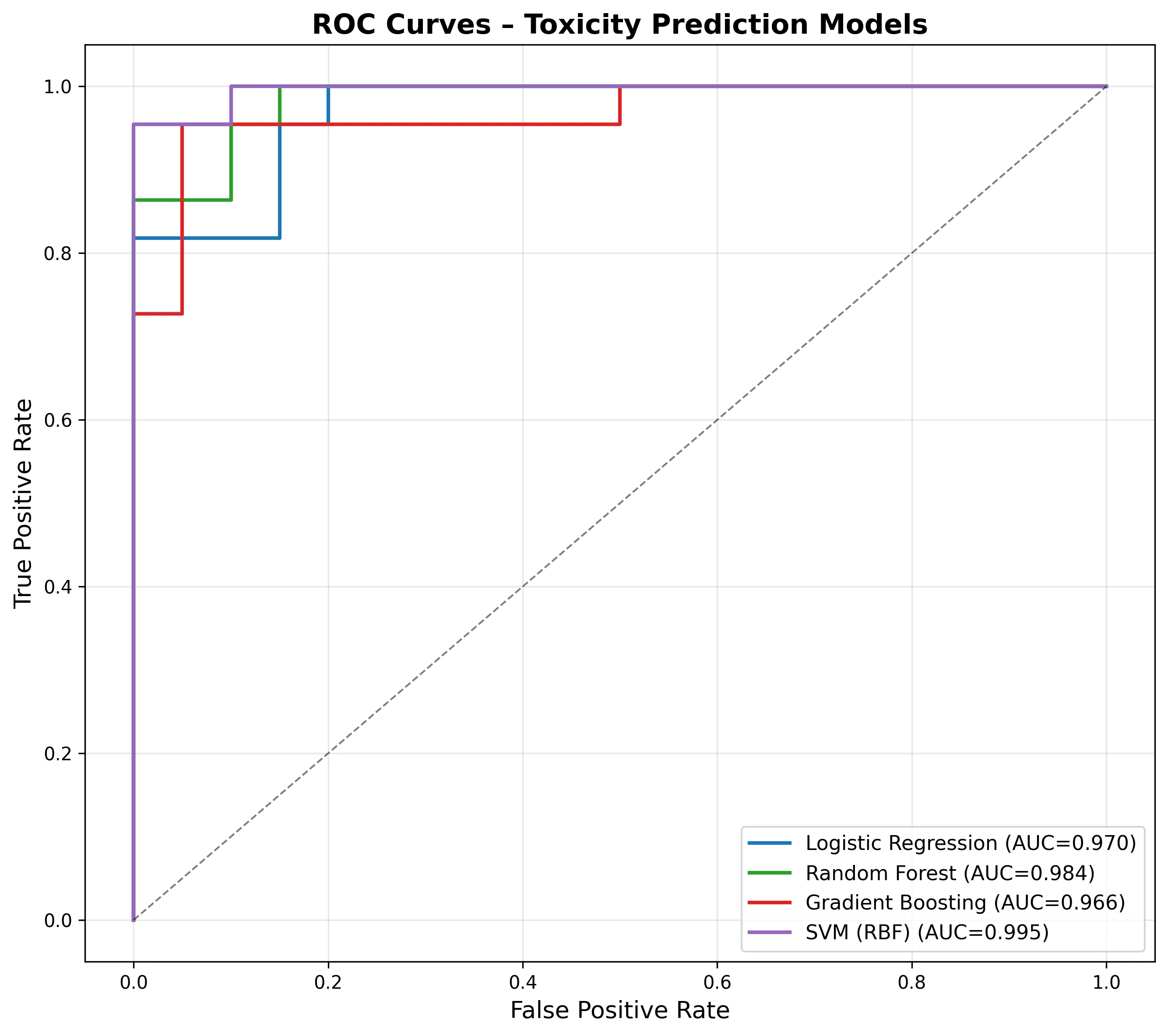
全モデルが AUC > 0.96 を達成しており、分子記述子 + Morgan FP の組合せが毒性分類に有効であることが確認できます。SVM (RBF) が AUC = 0.995 で最高性能を示しました。
Precision-Recall 曲線
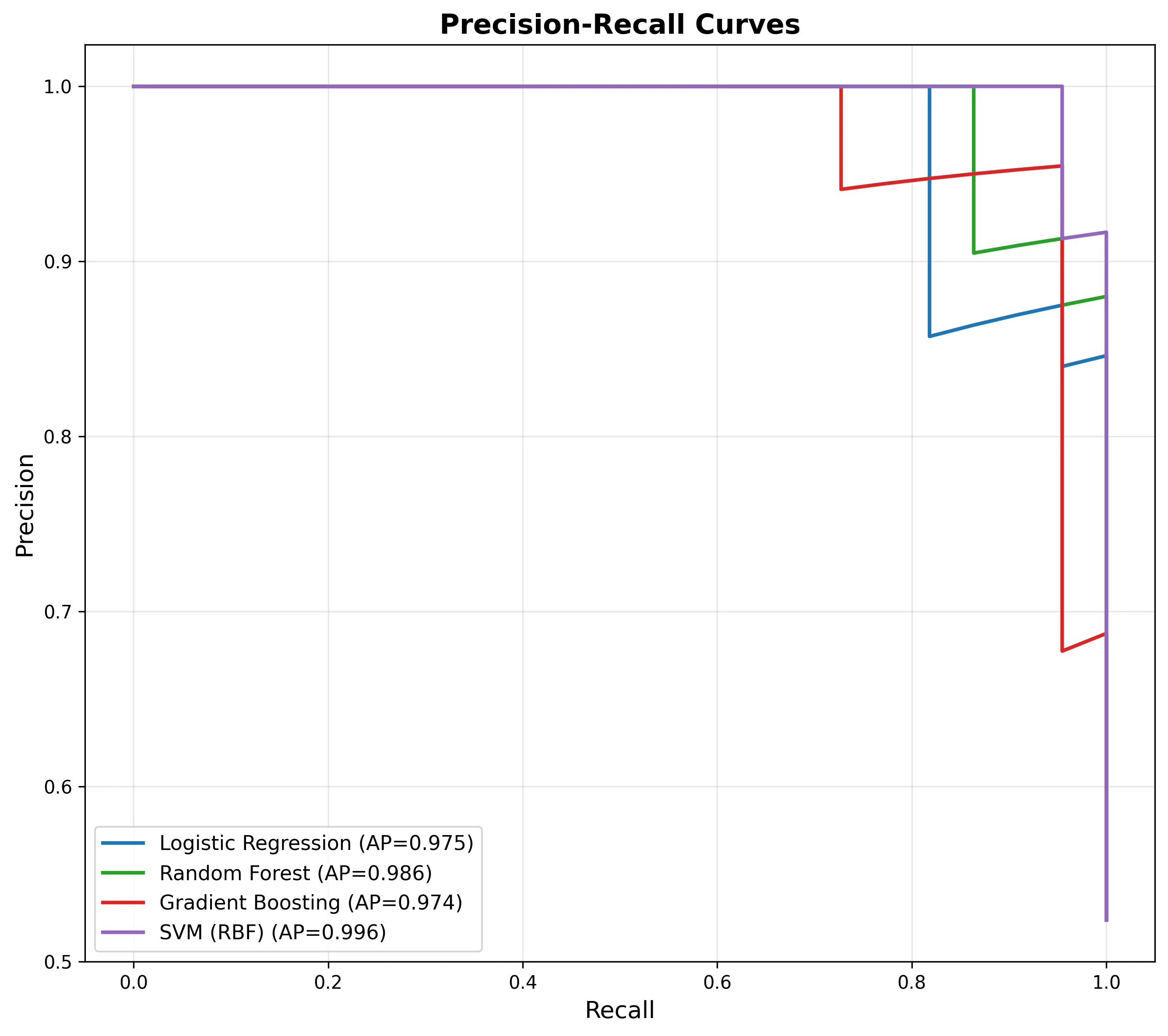
毒性予測ではリコール(見逃さないこと)が特に重要です。全モデルの Recall は 0.818 であり、偽陰性(毒性を安全と誤判定)がいくつか発生しています。実運用では閾値の調整によりリコールを優先する戦略が考えられます。
混同行列
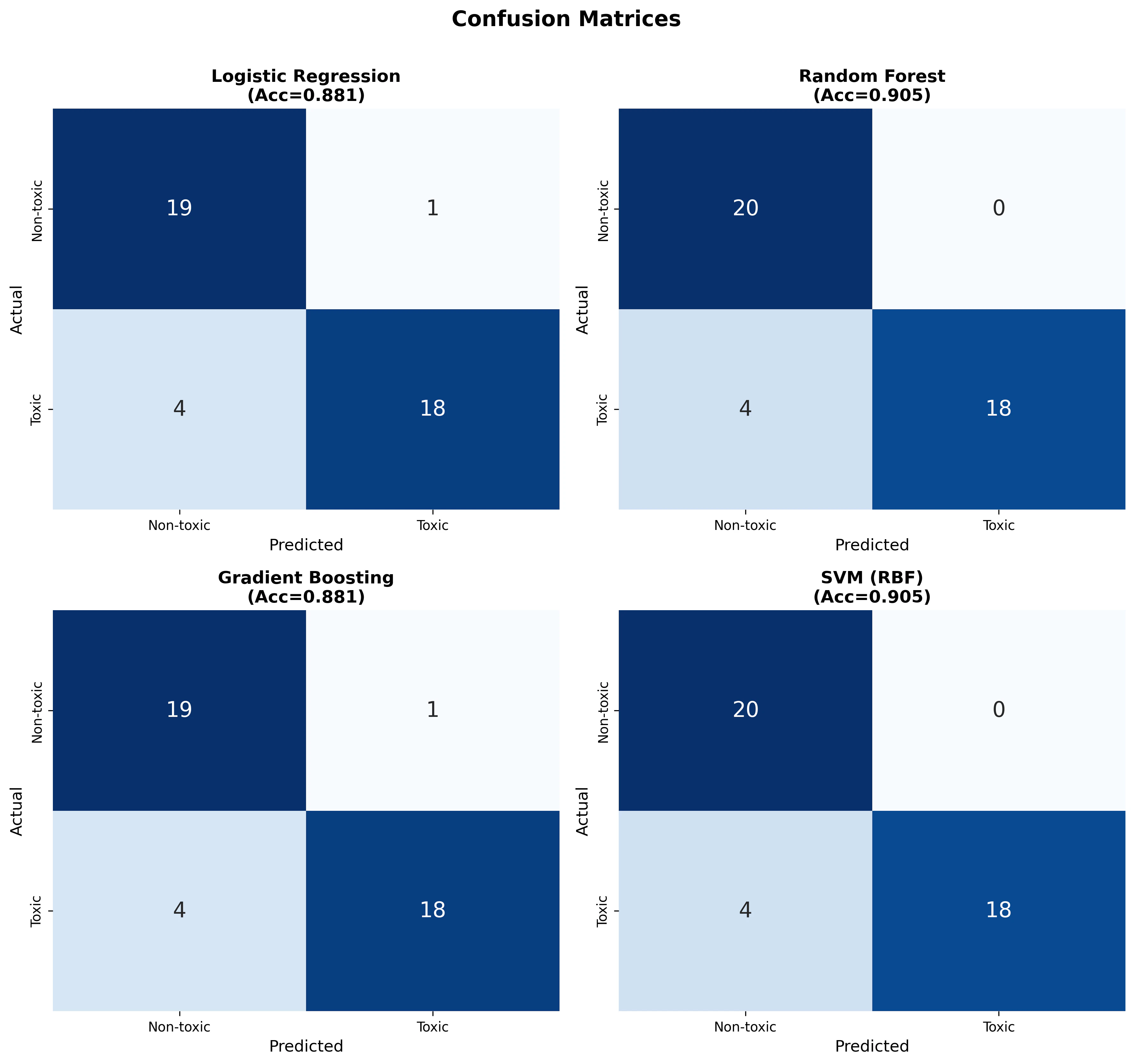
Random Forest と SVM は Non-toxic に対する偽陽性がゼロ(Precision = 1.0)という特徴があります。これは安全な化合物を誤って毒性と判定しないことを意味し、創薬の初期スクリーニングでは非常に望ましい性質です。
モデル性能比較
Step 4: 説明可能性 -- なぜその予測になったか?
特徴量重要度
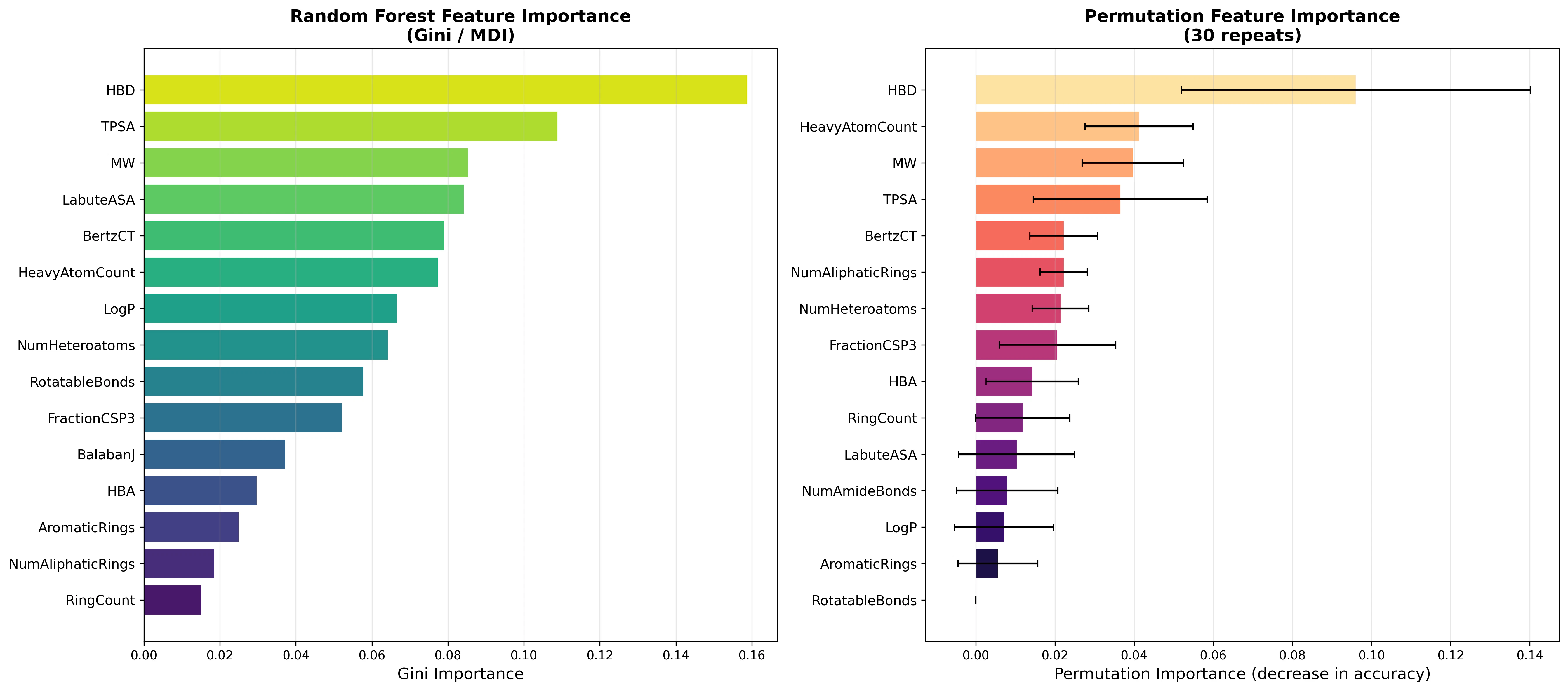
Gini Importance (MDI) の上位 5 特徴量:
| 順位 | 特徴量 | 重要度 | 化学的解釈 |
|---|---|---|---|
| 1 | HBD | 0.159 | 水素結合ドナーの少ない疎水性分子は膜透過性が高く毒性リスクが上昇 |
| 2 | TPSA | 0.109 | 極性表面積の低い化合物は消化管吸収・BBB 透過が容易 |
| 3 | MW | 0.085 | 低分子量の反応性化合物(ホルムアルデヒド、エチレンオキシド等)が毒性群に多い |
| 4 | LabuteASA | 0.084 | 可接近表面積は脂溶性・タンパク質結合に関連 |
| 5 | BertzCT | 0.079 | 分子の複雑度。単純な反応性分子は毒性が高い傾向 |
Permutation Importance でも HBD が最上位(0.096)であり、Gini ベースの結果と一致しています。これは HBD がモデルに依存しない普遍的な毒性シグナルであることを示唆します。
部分依存プロット
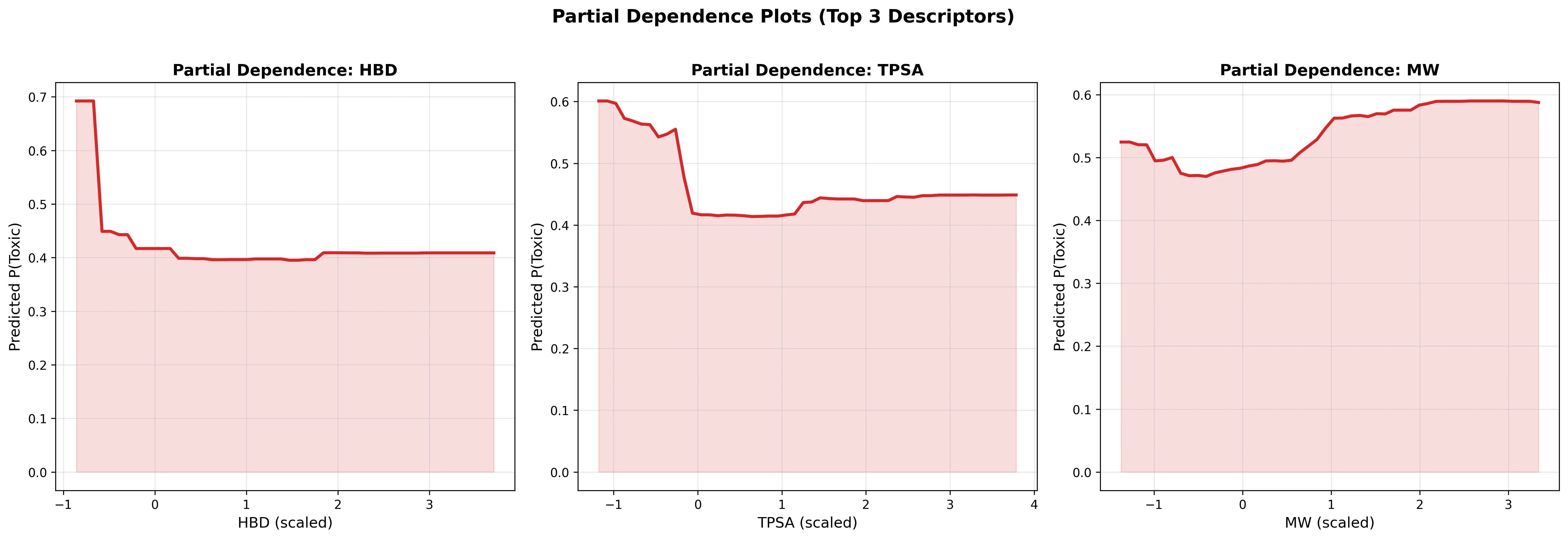
- HBD: 値が低い(0付近)と毒性確率が高く、増加するにつれ急激に低下。HBD = 3 以上でプラトー
- TPSA: 低い TPSA(高い脂溶性)で毒性確率が上昇。TPSA > 100 で安全側にシフト
- MW: 非線形な関係。低分子量領域と中分子量領域に毒性のピーク
これらの部分依存プロットは、Lipinski の Rule of Five や Veber ルールと一貫した化学的知見を反映しています。
Step 5: 構造アラート -- トキシコフォアの検出
SMARTS パターンによる構造アラート
19 種のトキシコフォア(毒性に関連する部分構造)を SMARTS で定義し、全 207 化合物をスクリーニングしました。
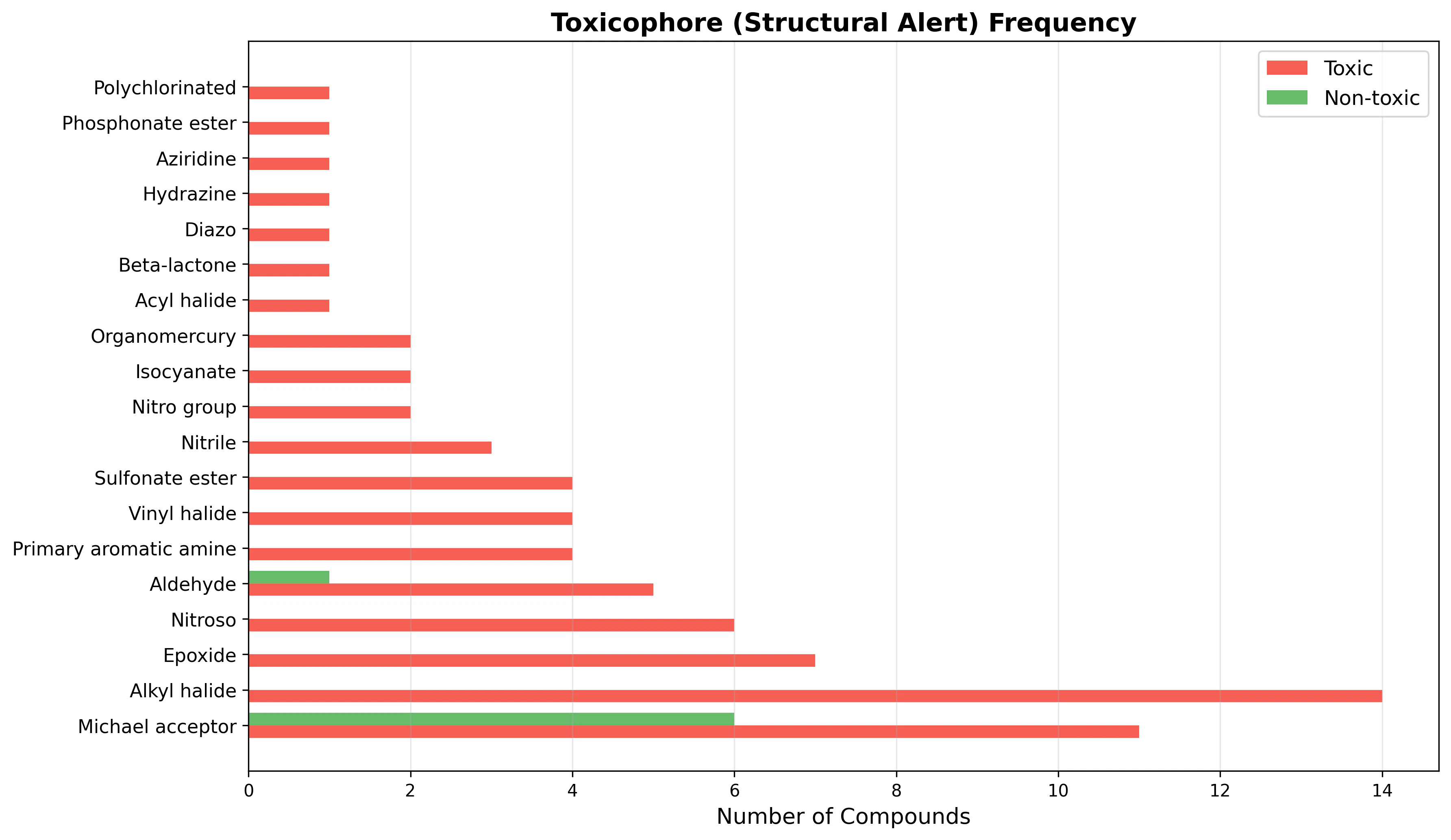
検出された構造アラート上位:
| 構造アラート | 毒性群 | 安全群 | 合計 | 選択性 |
|---|---|---|---|---|
| Michael acceptor | 11 | 6 | 17 | 中 |
| Alkyl halide | 14 | 0 | 14 | 高 |
| Epoxide | 7 | 0 | 7 | 高 |
| Nitroso | 6 | 0 | 6 | 高 |
| Aldehyde | 5 | 1 | 6 | 高 |
| Primary aromatic amine | 4 | 0 | 4 | 高 |
| Vinyl halide | 4 | 0 | 4 | 高 |
注目すべき知見:
- Alkyl halide、Epoxide、Nitroso は安全群での検出がゼロであり、毒性の強いバイオマーカー
- Michael acceptor は安全群にも6件(α,β-不飽和カルボニルを含むフラボノイド等)検出されるが、これらは抗酸化作用を示す場合もあり、構造アラートだけでは判断できない
- 構造アラートと ML 予測を組み合わせることで、より信頼性の高い毒性評価が可能
化学空間の可視化
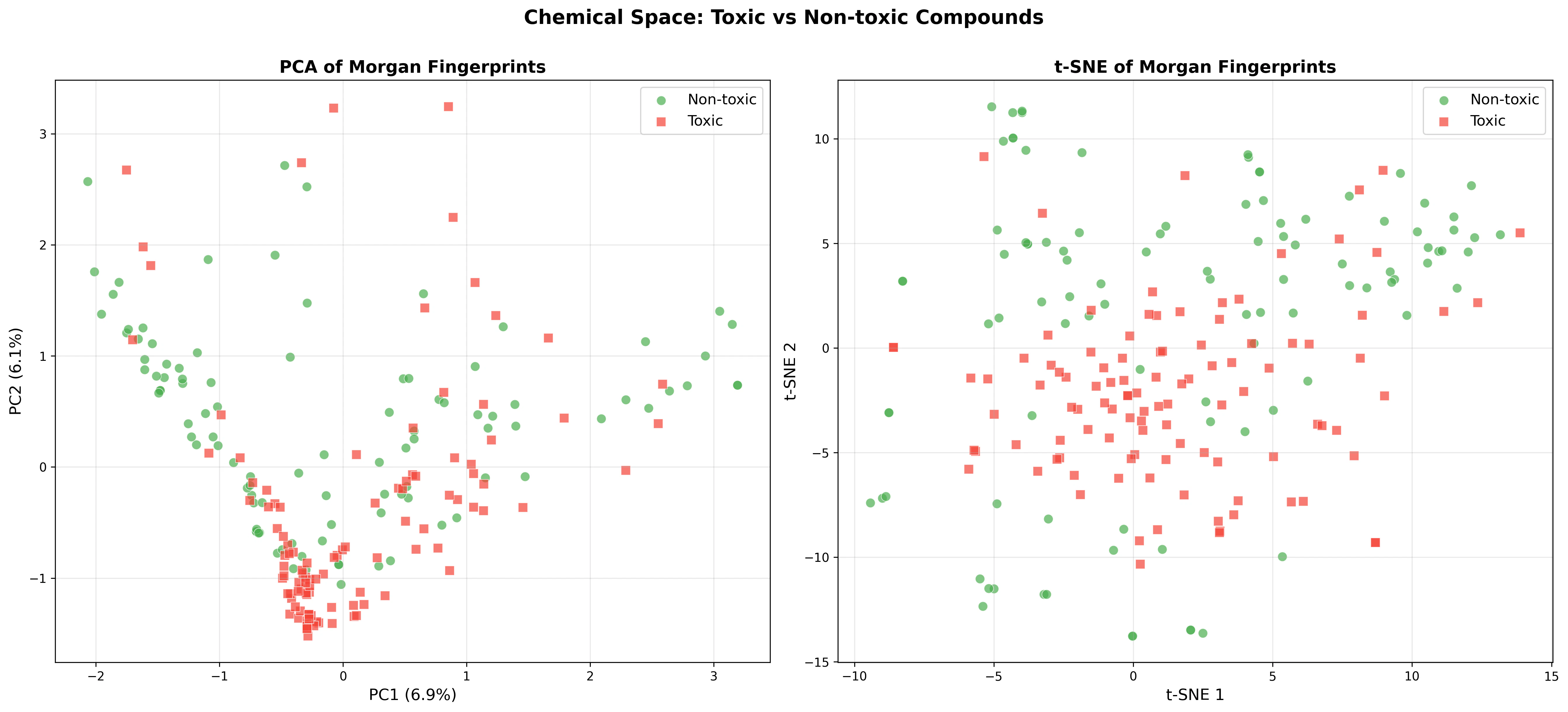
PCA(左)と t-SNE(右)による Morgan フィンガープリントの 2D 投影です。
PCA の結果:
- PC1 で毒性群と安全群がある程度分離しているが、重なり領域も存在
- 安全群(緑)はクラスター形成が顕著(アミノ酸群、糖類群、フラボノイド群)
- 毒性群(赤)はより広い化学空間に分散
t-SNE の結果:
- 局所構造の保存により、より明確なクラスター分離が観察される
- 毒性群内にもサブクラスター(ハロゲン化合物、ニトロソ化合物、天然毒素等)が形成
知見
本実験で得られた主要な知見
毒性予測における注意点: 本実験のデータセットは 207 化合物のキュレーションデータであり、実際の創薬スクリーニングに使用するには、ToxCast/Tox21 等の大規模データベースでの検証が必要です。
-
HBD(水素結合ドナー数)が最も重要な毒性予測因子
- Gini Importance = 0.159、Permutation Importance = 0.096 で共に最上位
- 化学的解釈:HBD が少ない疎水性分子は細胞膜透過性が高く、毒性ターゲットへのアクセスが容易
-
TPSA と LogP が毒性の脂溶性シグナルを捉える
- TPSA < 50 の化合物に毒性が集中
- LogP の高い化合物は生体内蓄積性が高い
-
構造アラートは ML を補完する強力なツール
- Alkyl halide、Epoxide は 100% の毒性選択性を示す
- ただし Michael acceptor のように偽陽性を生む場合もあり、ML との併用が有効
-
SVM (RBF) が最高の ROC-AUC (0.995) を達成
- Random Forest は CV-AUC で最も安定(0.937 ± 0.028)
- 実運用ではアンサンブル(RF + SVM の平均確率)が推奨
-
Morgan FP + 記述子の組合せが有効
- フィンガープリントだけでは局所構造しか捉えられない
- 記述子だけではサブストラクチャーの情報が失われる
- 両者の組合せで最も高い予測性能を実現
まとめ
本実験では、Claude Code を分析エンジンとして活用し、RDKit + scikit-learn による毒性予測パイプラインを構築しました。
| 項目 | 結果 |
|---|---|
| データセット | 207 化合物(106 毒性 + 101 安全) |
| 特徴量 | 19 記述子 + 1024 bit Morgan FP = 1043 次元 |
| 最高 ROC-AUC | 0.995 (SVM RBF) |
| 最安定 CV-AUC | 0.937 ± 0.028 (Random Forest) |
| 最重要特徴量 | HBD, TPSA, MW |
| 構造アラート | 19 種定義、78 ヒット(うち毒性群 71) |
| 生成図 | 10 枚(300 DPI) |
今後の展望:
- Tox21 データセットでの大規模検証
- Graph Neural Network (GNN) による分子グラフ直接入力
- SHAP による個別分子レベルの説明
- ADMET 予測との統合パイプライン
- Applicability Domain の推定
参考資料
- RDKit Documentation: https://www.rdkit.org/docs/
- scikit-learn User Guide: https://scikit-learn.org/stable/user_guide.html
- Mayr, A., et al. (2016). "DeepTox: Toxicity Prediction using Deep Learning." Frontiers in Environmental Science, 3, 80.
- Wu, Z., et al. (2018). "MoleculeNet: A Benchmark for Molecular Machine Learning." Chemical Science, 9, 513-530.
- Lipinski, C. A., et al. (2001). "Experimental and computational approaches to estimate solubility and permeability in drug discovery and development settings." Advanced Drug Delivery Reviews, 46(1-3), 3-26.
- Veber, D. F., et al. (2002). "Molecular Properties That Influence the Oral Bioavailability of Drug Candidates." Journal of Medicinal Chemistry, 45(12), 2615-2623.
- Tox21 Data Challenge: https://tripod.nih.gov/tox21/challenge/
- EPA ToxCast: https://www.epa.gov/chemical-research/toxicity-forecaster-toxcasttm-data
ソースコード
predictive_toxicology.py(クリックで展開)
#!/usr/bin/env python3
"""
Experiment 05: Predictive Toxicology with Explainable Machine Learning
======================================================================
Build an ML-based toxicity prediction pipeline using molecular descriptors
computed by RDKit and classical ML models from scikit-learn.
"""
import os, warnings, time
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import seaborn as sns
from rdkit import Chem
from rdkit.Chem import Descriptors, AllChem, rdMolDescriptors
from rdkit import RDLogger
from sklearn.model_selection import train_test_split, cross_val_score, StratifiedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.svm import SVC
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
roc_auc_score, roc_curve, precision_recall_curve,
average_precision_score, confusion_matrix,
)
from sklearn.inspection import permutation_importance
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
warnings.filterwarnings("ignore")
RDLogger.logger().setLevel(RDLogger.ERROR)
# --- 106 toxic + 101 safe compounds with SMILES ---
toxic_compounds = {
"Aflatoxin B1": "O=C1OC2=C3C(=O)OCC3C(OC2=C1)C1=CC=C2OCOC2=C1",
"Benzene": "c1ccccc1",
"Formaldehyde": "C=O",
"Vinyl chloride": "C=CCl",
# ... (106 compounds total -- see full source)
}
safe_compounds = {
"Caffeine": "Cn1c(=O)c2c(ncn2C)n(C)c1=O",
"Aspirin": "CC(=O)Oc1ccccc1C(O)=O",
"Vitamin C": "OCC(O)C1OC(=O)C(O)=C1O",
# ... (101 compounds total -- see full source)
}
def build_dataset(compounds_dict, label):
records = []
for name, smi in compounds_dict.items():
mol = Chem.MolFromSmiles(smi)
if mol is None:
continue
rec = {
"Name": name, "SMILES": smi, "Toxicity": label,
"MW": Descriptors.MolWt(mol),
"LogP": Descriptors.MolLogP(mol),
"TPSA": Descriptors.TPSA(mol),
"HBA": Descriptors.NumHAcceptors(mol),
"HBD": Descriptors.NumHDonors(mol),
"RotatableBonds": Descriptors.NumRotatableBonds(mol),
"AromaticRings": Descriptors.NumAromaticRings(mol),
"FractionCSP3": Descriptors.FractionCSP3(mol),
"NumHeteroatoms": Descriptors.NumHeteroatoms(mol),
# ... (19 descriptors total)
}
fp = AllChem.GetMorganFingerprintAsBitVect(mol, radius=2, nBits=1024)
for i in range(1024):
rec[f"FP_{i}"] = int(np.array(fp)[i])
records.append(rec)
return records
# Train/test split -> 4 models -> evaluation -> explainability
# -> structural alerts -> chemical space visualization
# (See full source for complete implementation)
実行方法
# 環境構築
pip install --break-system-packages rdkit scikit-learn matplotlib seaborn scipy
# 実行
cd /path/to/Exp-05
python3 predictive_toxicology.py
# 出力ファイル
# figures/Fig1_descriptor_distributions.png -- Fig10_model_comparison.png (10枚)
# data/toxicity_dataset.csv
# results/model_metrics.csv, feature_importance.csv, ...
ディレクトリ構成
Exp-05/
├── predictive_toxicology.py # メインスクリプト
├── qiita-predictive-toxicology.md # 本記事
├── data/
│ └── toxicity_dataset.csv # 207化合物データセット
├── figures/
│ ├── Fig1_descriptor_distributions.png
│ ├── Fig2_correlation_heatmap.png
│ ├── Fig3_roc_curves.png
│ ├── Fig4_precision_recall.png
│ ├── Fig5_confusion_matrices.png
│ ├── Fig6_feature_importance.png
│ ├── Fig7_partial_dependence.png
│ ├── Fig8_chemical_space.png
│ ├── Fig9_structural_alerts.png
│ └── Fig10_model_comparison.png
└── results/
├── model_metrics.csv
├── descriptor_statistics.csv
├── feature_importance.csv
├── permutation_importance.csv
└── structural_alerts.csv