この文書について
この文書は、株式会社primeNumberが提供するEmbulkのマネージドサービスtroccoをつかってみた体験記です。
そもそものきっかけ
私はEmbulkがリリースされた2015年1月の直後にEmbulkのまとめを作ってその動向をみてきました。そういう中でprimeNumberの方からtroccoを使ってみてと話をいただきました。Embulkのマネージドサービスということでtroccoには前々から興味があり是非使わせてくださいとお願いしました。今回の記事はその第一弾になります。
troccoとは
Embulk + αのサービスが利用できる株式会社primeNumber社のマネージドサービスです。
Embulkとは
2015年にfluendやなどのサービスを開発したトレジャーデータ社の古橋さんが開発したオープンソースソフトウェアです。詳しくは私がメンテナンスをしているFluentdのバッチ版Embulk(エンバルク)のまとめ
をみてください。
対象読者
なるべくこの資料をみると「troccoのイメージが掴めた」と思えるような文書にしたいと思っています。以下のような方にご覧いただけるページにしているつもりです。
- これからデータ基盤を作る予定だが、サーバの管理とかの経験がなくマネージドサービスを検討しているかた
- troccoに興味のあるかた
- Embulkを使ったことある人
troccoを利用する前の事前準備
troccoを利用する前に次のことを実行します。
- 連携サービスのアカウント作成: ex) Google Bigqueryのアカウントを取得
- BigQueryにはサンドボックスという無料で利用できるサービスがありますが、このサービスをtroccoで利用するとエラーになってしまうようです。(これはbigqueryのプラグインの問題です。)
- 無料トライアルを申し込み
troccoのアカウントができたら
次の作業を実行します。
- 連携サービスの認証情報の登録(今回割愛しますがBigQueryの接続設定をみてください。)
- 転送ジョブの登録(移行で説明)
転送ジョブの登録
転送元・転送先の設定
自分のデスクトップにあるファイルを、Bigqueryにアップロードするのをやってみます。サンプルに利用するファイルはEmbulkで例として使っているcsvファイルを利用します。このファイルはembulk exampleコマンドで生成することができます。またこちらでも同じファイルをダウンロードすることができますので、デスクトップに保存をしてください。
転送元のLocalFileは、デスクトップ上にあるサービスをtroccoのサーバに手動でアップロードして、troccoで利用できるようにするものです。
- 入力元: 様々なサービスが出てくるのでLocalFileを選択します。
- 出力先: bigqueryを選択します。
- 「この内容で作成」を押し具体的な設定を行います。
概要設定

- 概要設定
- 名前: この転送の名前を指定します。(例: 初めてのtrocco)
- メモ: この転送の説明を記述することができます。
- 共有するグループ: グループを使っているとこの転送情報を設定するようです。(今回はスキップ)
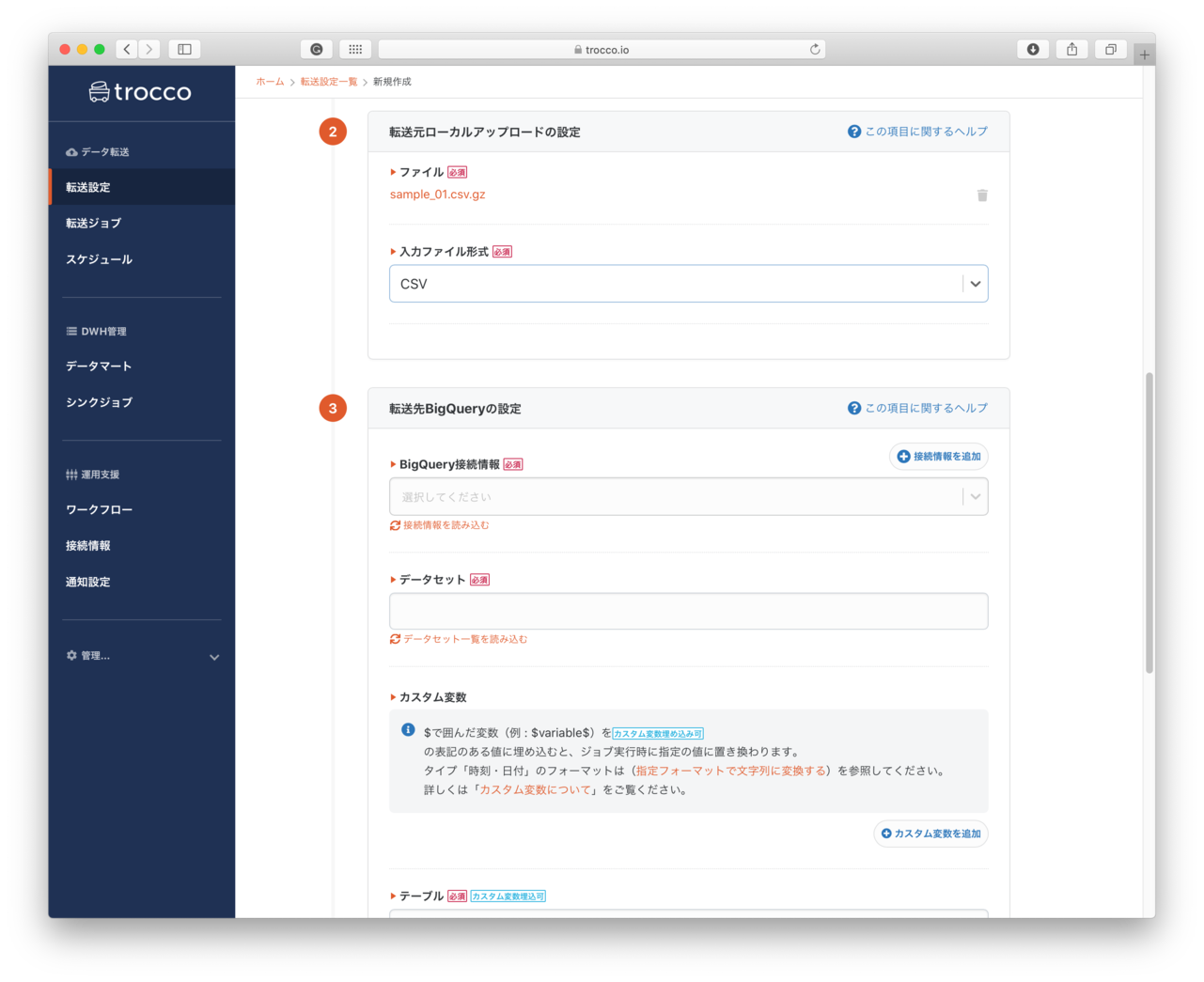
- 転送元ローカルアップロードの設定
- ファイル: アップロードするファイルを指定します。
- 入力ファイル形式:
CSV,JSONなどから - ファイル名には変数を利用することができるようです。日時で生成される売り上げファイルなどはこちらの変数を使うことができるようです(これは後日使ってみたいと思います。)
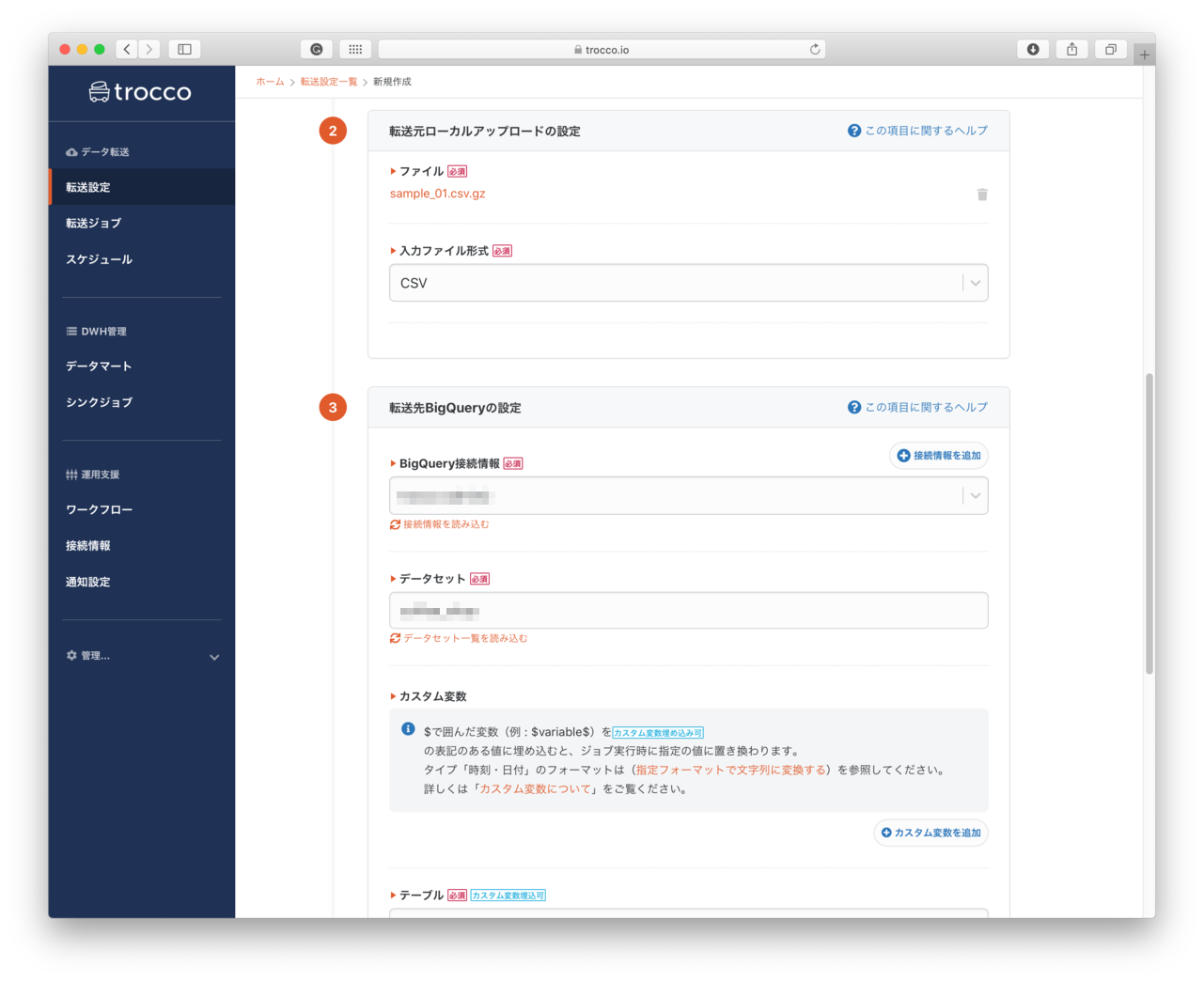
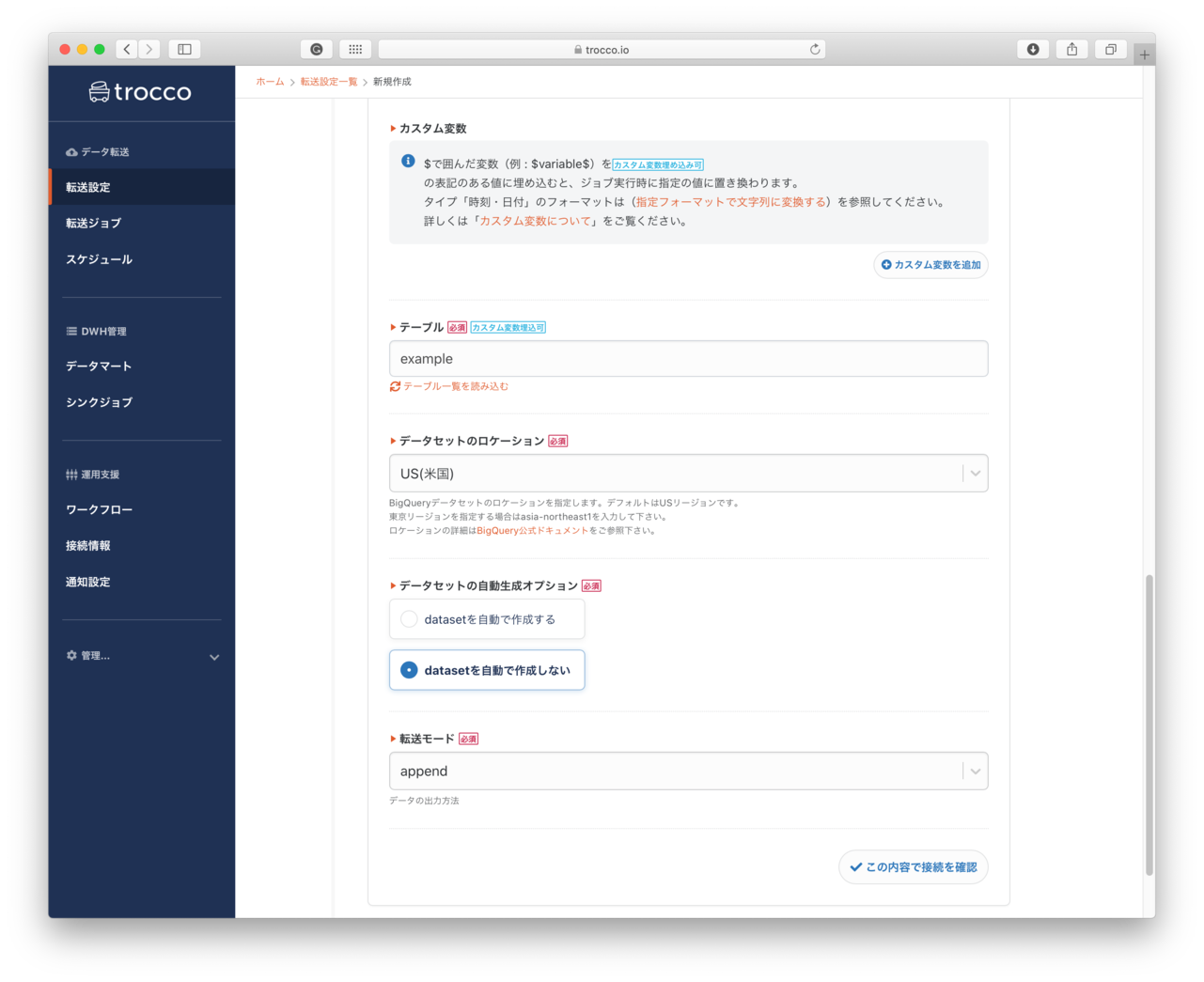
- Bigqueryの接続設定
- Bigqueryの接続情報: 事前に作成した接続情報が一覧表示されるので、利用する接続設定を選択します。
- データセット: BigQueryで指定するデータセットの名前を指定します。選択した接続情報で利用可能なデータセットが一覧表示されます。まだBigQueryにデータセットがない場合は、作成したいデータセットの名前を入力します。これをしないとエラーになります
- テーブル: アップロードするデータを登録するテーブル名を指定します。このテーブルも既存のテーブルは一覧表示されて選択をすることができます。データ登録時にテーブルを一緒に作成する場合は、作成するテーブル名を入力します。
- データセットのリージョン: テーブルを登録する先のリージョンを指定します。
- データセットの自動作成オプション: データセットが未作成の場合は、datasetを自動で作成するを選択します。重要
- 転送モード: データを追加登録する場合は、append、既存のデータを入れ替えする場合: replaceを選択します
- 保存して自動設定・プレビューへボタンを押します。
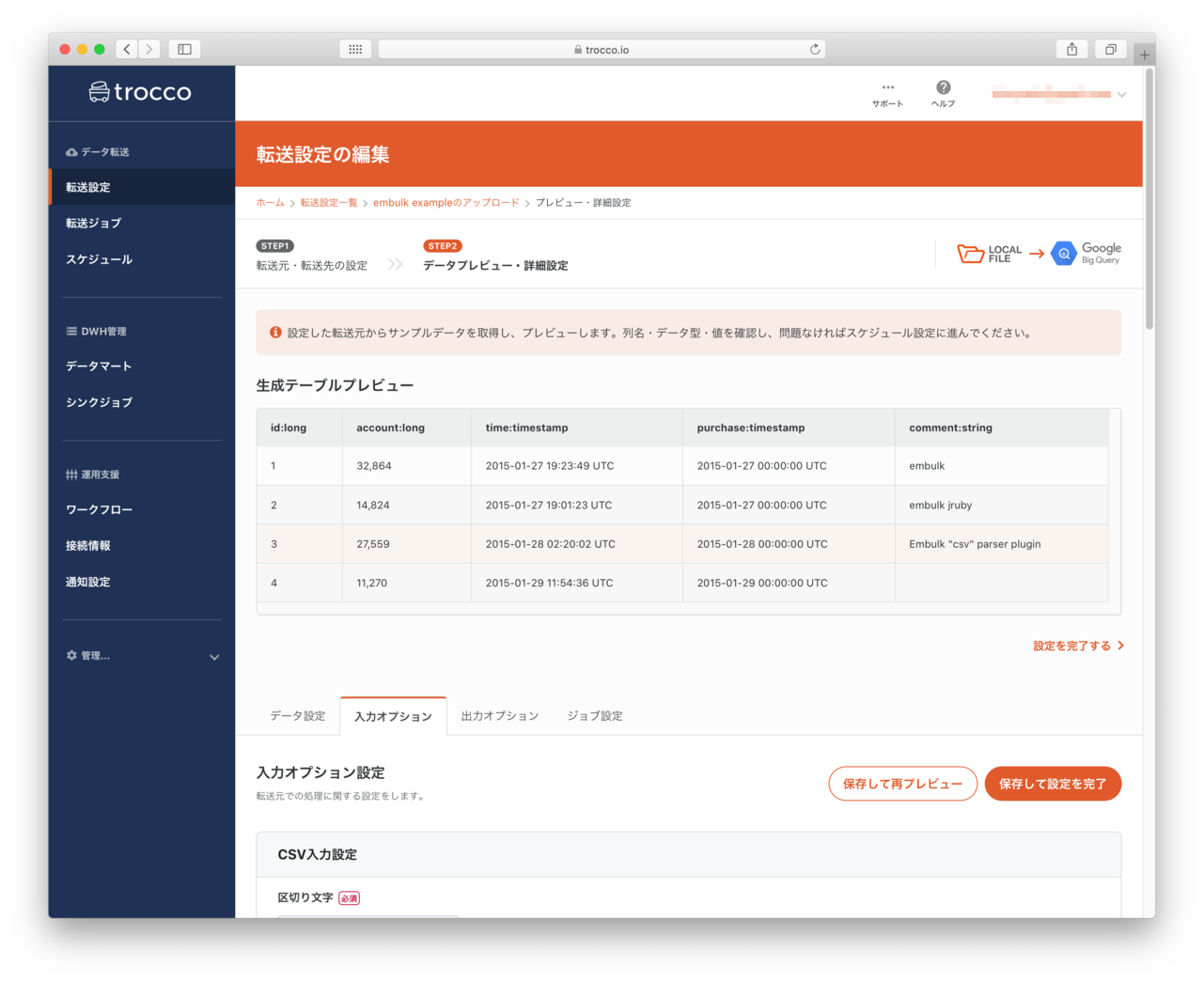
データプレビュー・詳細設定
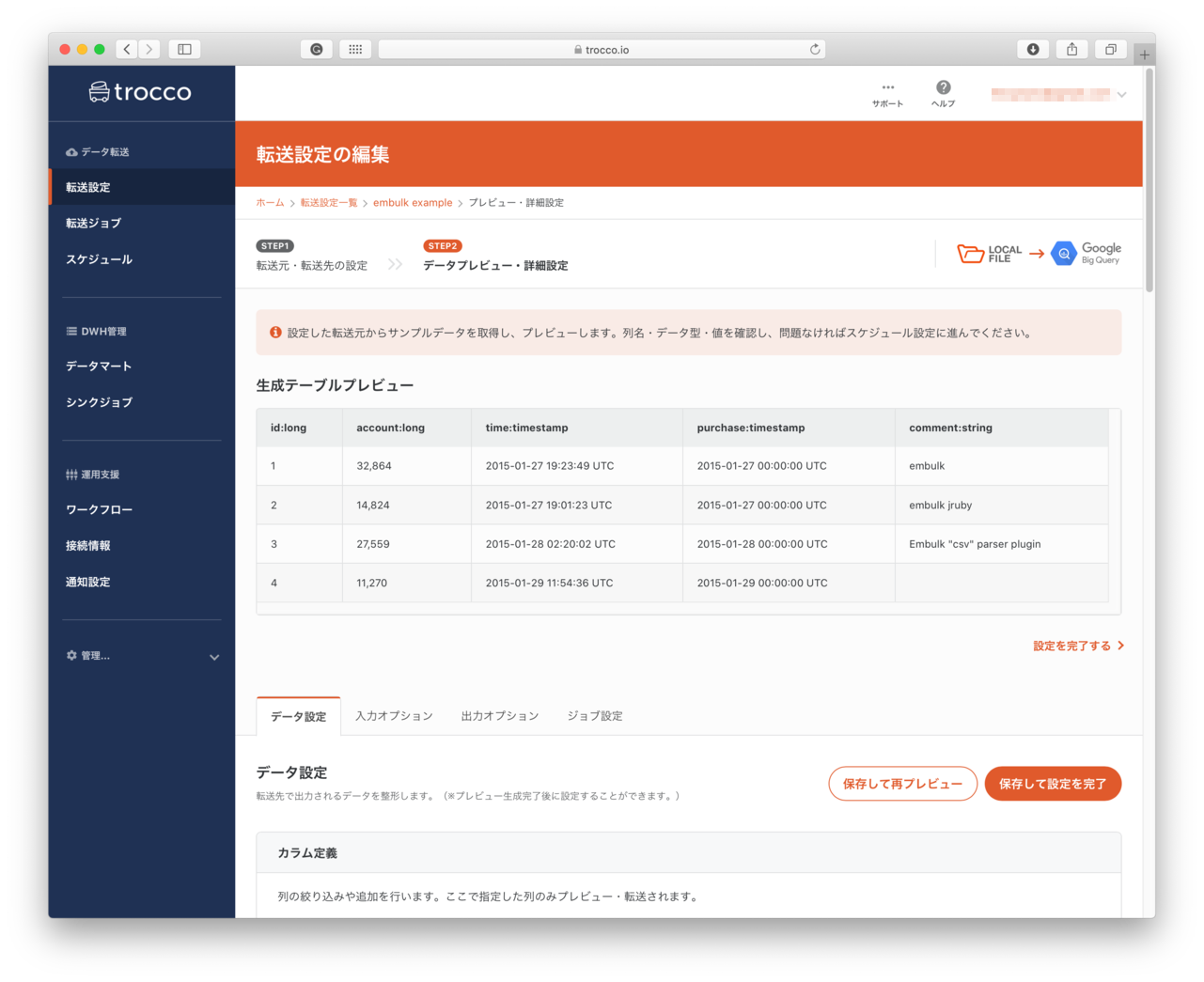
- 前画面で指定したファイルの中身を類推して、カラム情報を自動作成します。(背後で
embulk guessを実行した結果を表示します。)- 実行した結果はマネージドサービスらしく、Webインタフェースでみやすくなっています。(カラムが多いとどうなるか気になるところ
-Gと同じ機能は利用できるのでしょうか?)
- 実行した結果はマネージドサービスらしく、Webインタフェースでみやすくなっています。(カラムが多いとどうなるか気になるところ
- プレビュー画面の下には、次のタブが表示されており入出力データ・ジョブの設定ができるようになっているようです
- データ設定
- 入力オプション(LocalFileの設定をおこないます)
- 出力オプション(BigQueryの設定をおこないます。)
- ジョブ設定(並列度などの設定をおこなうことができまる)
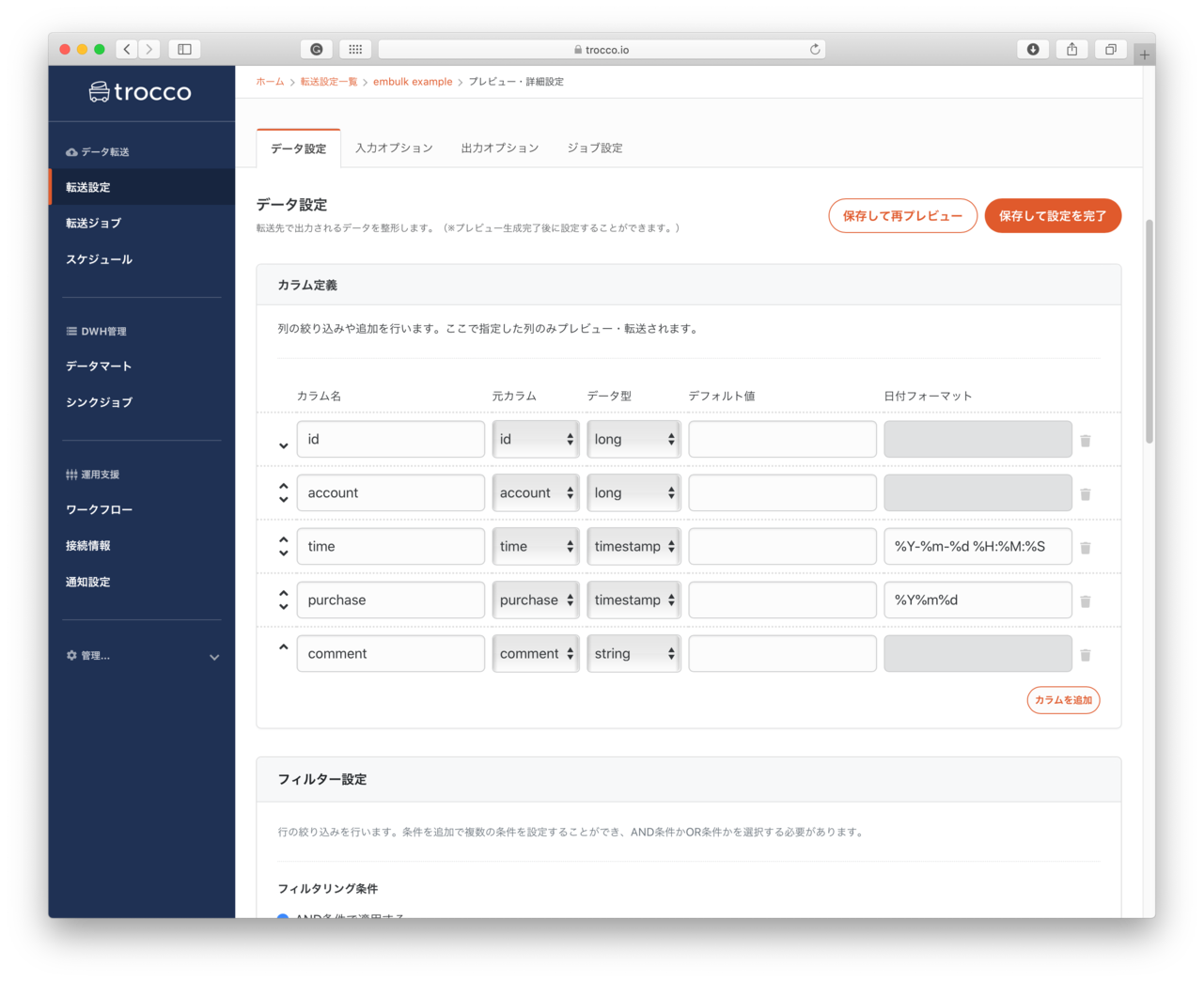
- カラム定義
- もし自動類推されたカラム情報が期待するカラムと異なる場合、カラムの情報を指定します。
- カラム名: 指定したカラム名がBigQueryに登録した際のカラム名になります。
- 元カラム名: csvファイルの先頭行に記載されてるカラム名が表示されます。
- データ型: 利用するデータ型を一覧から選択します
- 日付フォーマット: 入力データが例えば2020年8月30日 14時3分05秒で、2020-08-30 14:03:05のようになっている場合、
%Y-%m-%d %H:%M:%Sのように記述します。詳細 - カラム追加: 追加するカラムがある場合こちらのボタンで設定をおこなうようです。
- フィルター設定
- 行の絞り込みを行えるようです。(今回は未設定)
- 画面はembulk-filter-rowを使って、条件式に合致するデータのみ抽出することができるようです。
- 例えば、2020年度9月のデータのみ抽出等
- その他のフィルタも利用できるようです。
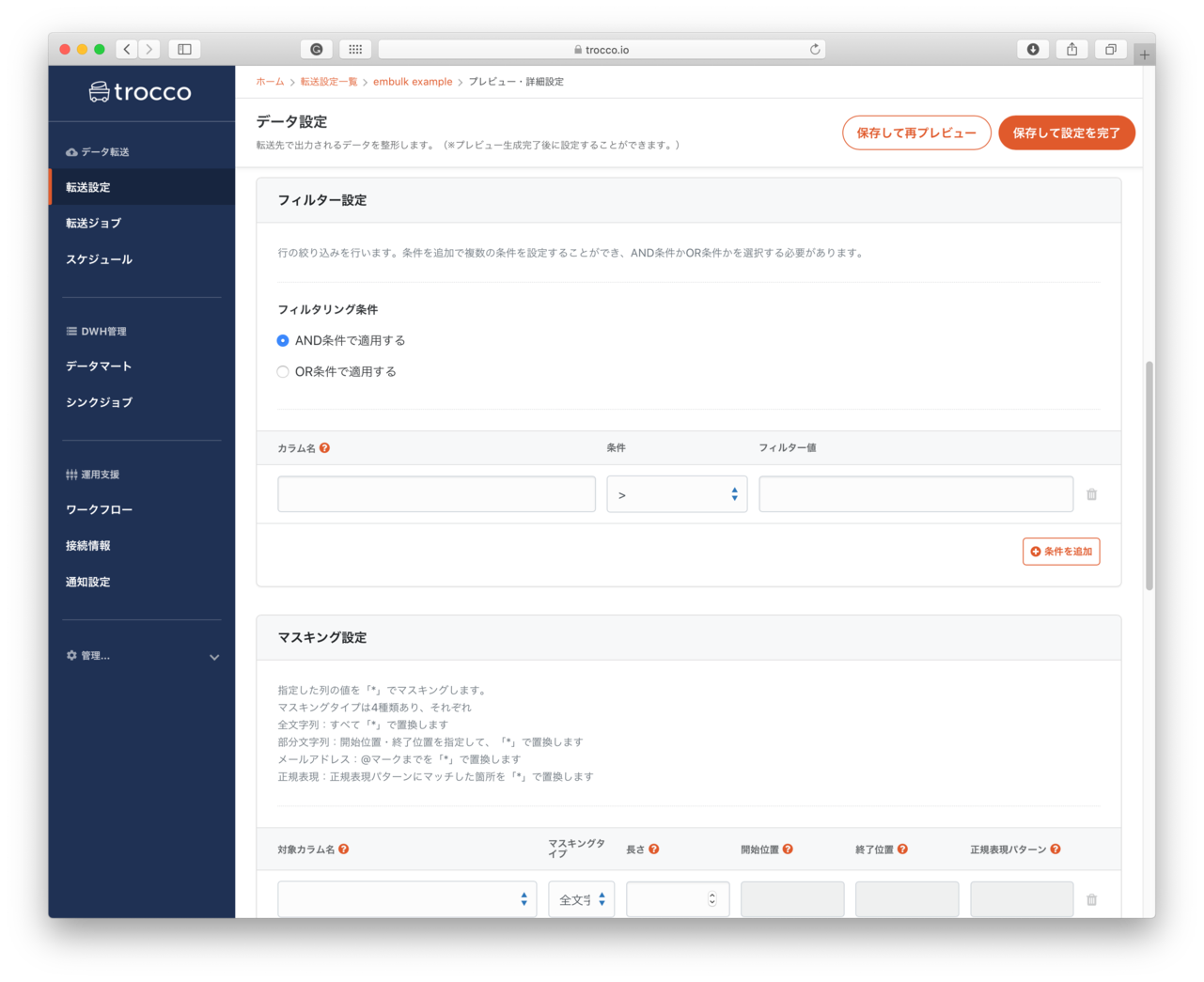
- マスキング設定
- メールアドレスを
bob@example.comを***@****.comのようにマスクできるようです。
- メールアドレスを
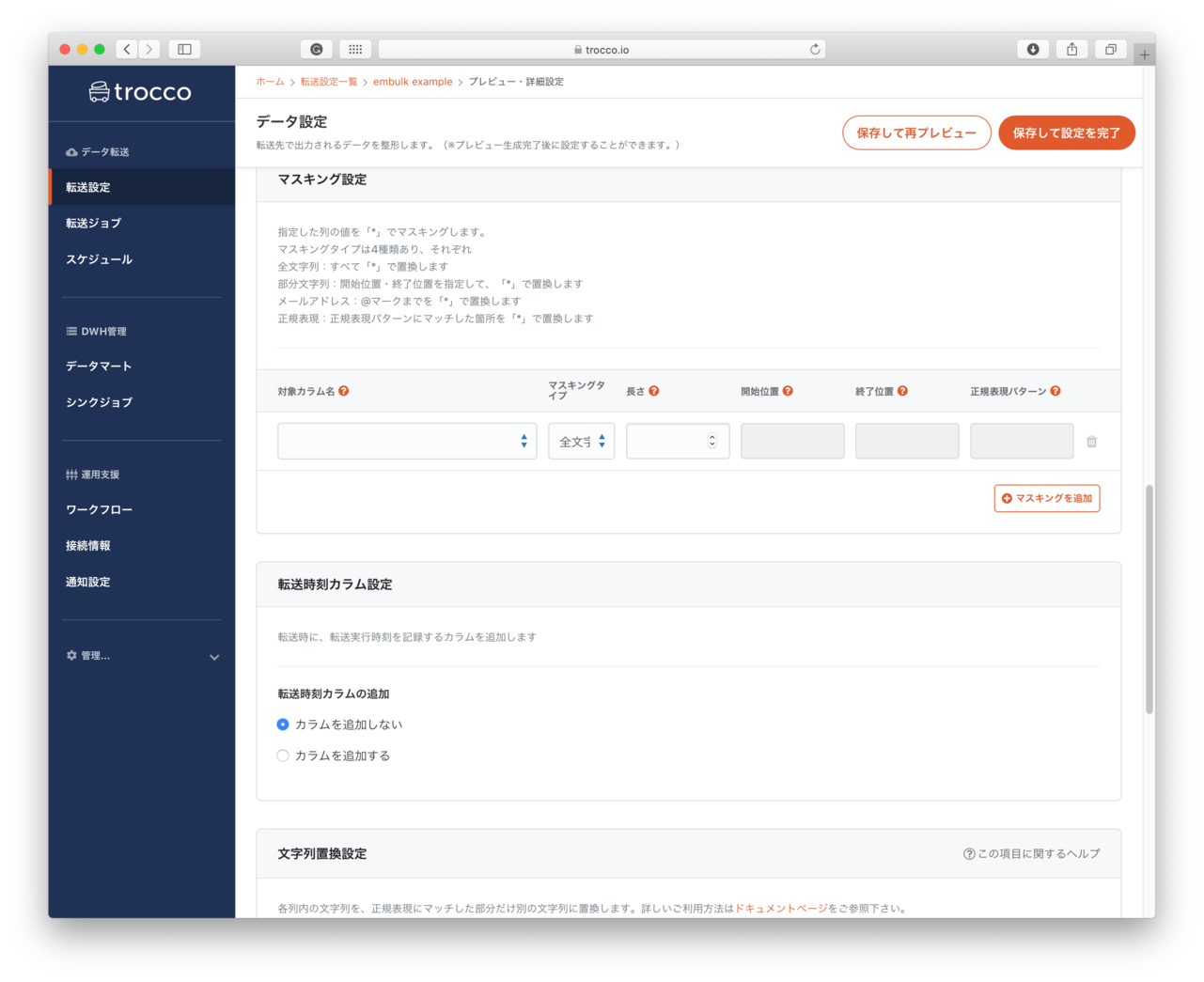
- 転送時刻カラム設定
- データを登録した時刻を記録するカラムを追加できるようです。
- 多分
embulk-filter-add_timeを利用しているようです
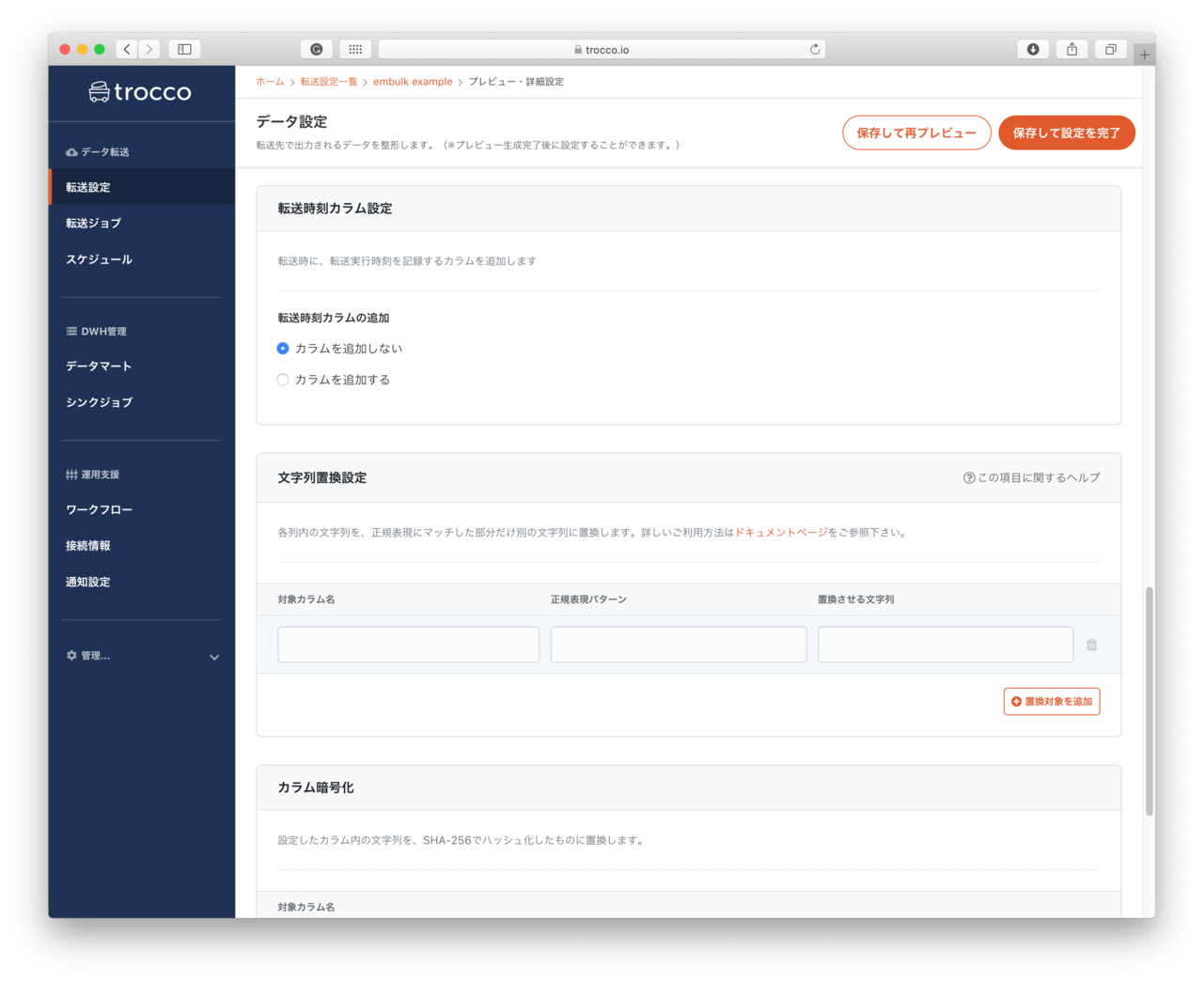
- 文字列置き換え
- 正規表現を使って文字列の置き換えをすることができるようです。
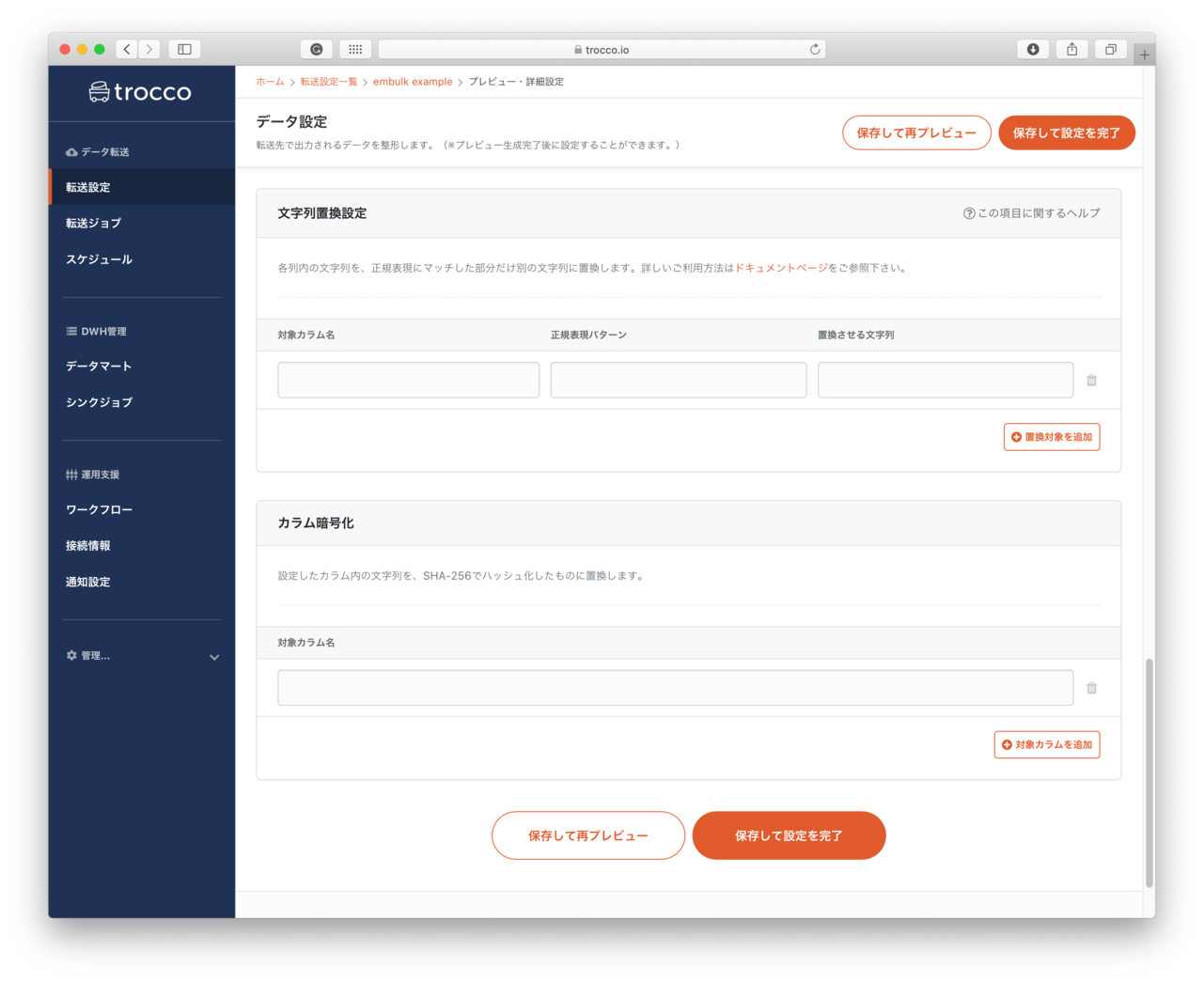
- カラム暗号化
- 設定したカラムの文字列を、SHA-256でハッシュ化できるようです。
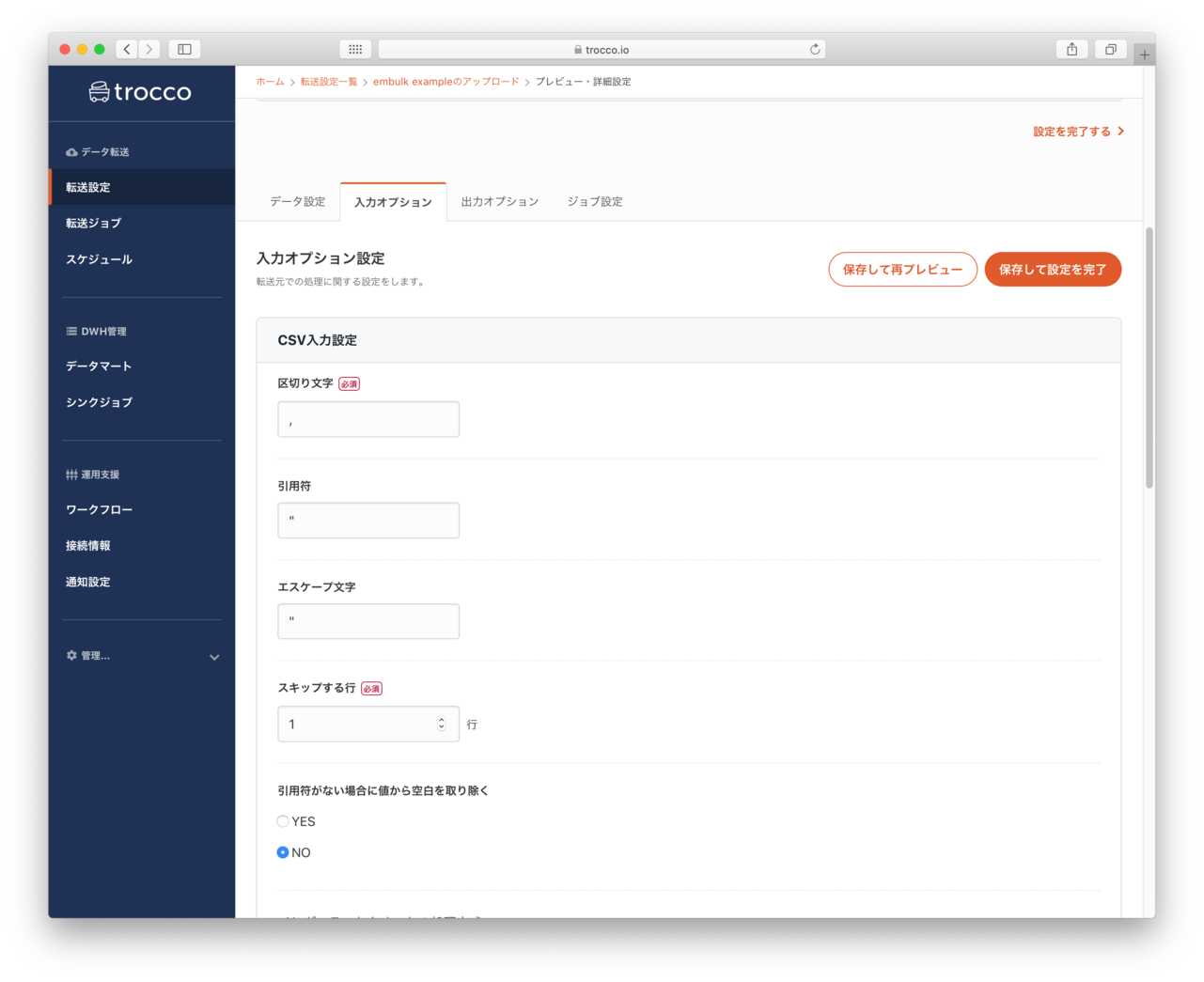
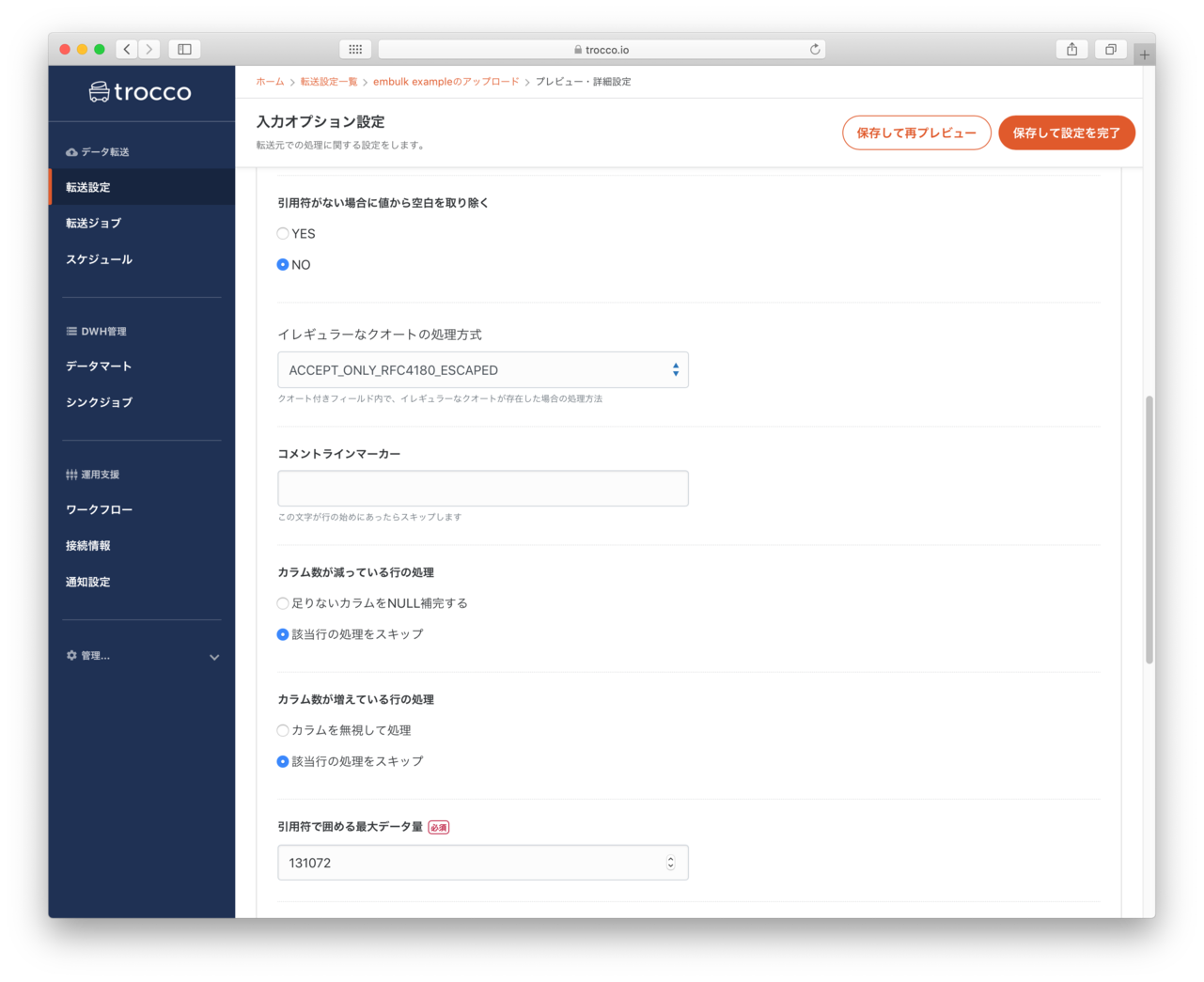
データプレビュー・入力オプション
- LocalFileで指定したCSVファイル区切り文字などが指定できるようです。(今回はデフォルトのまま)
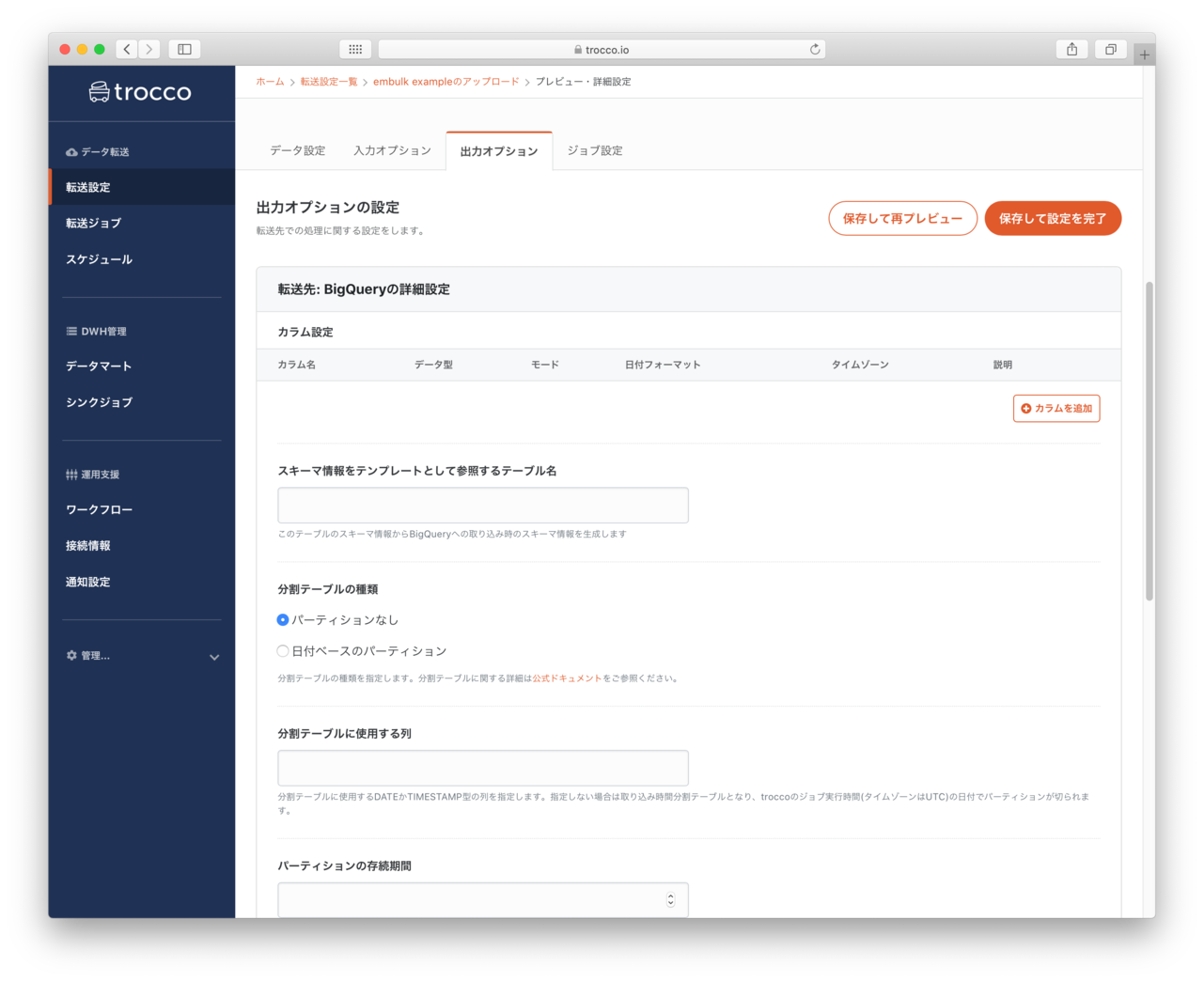
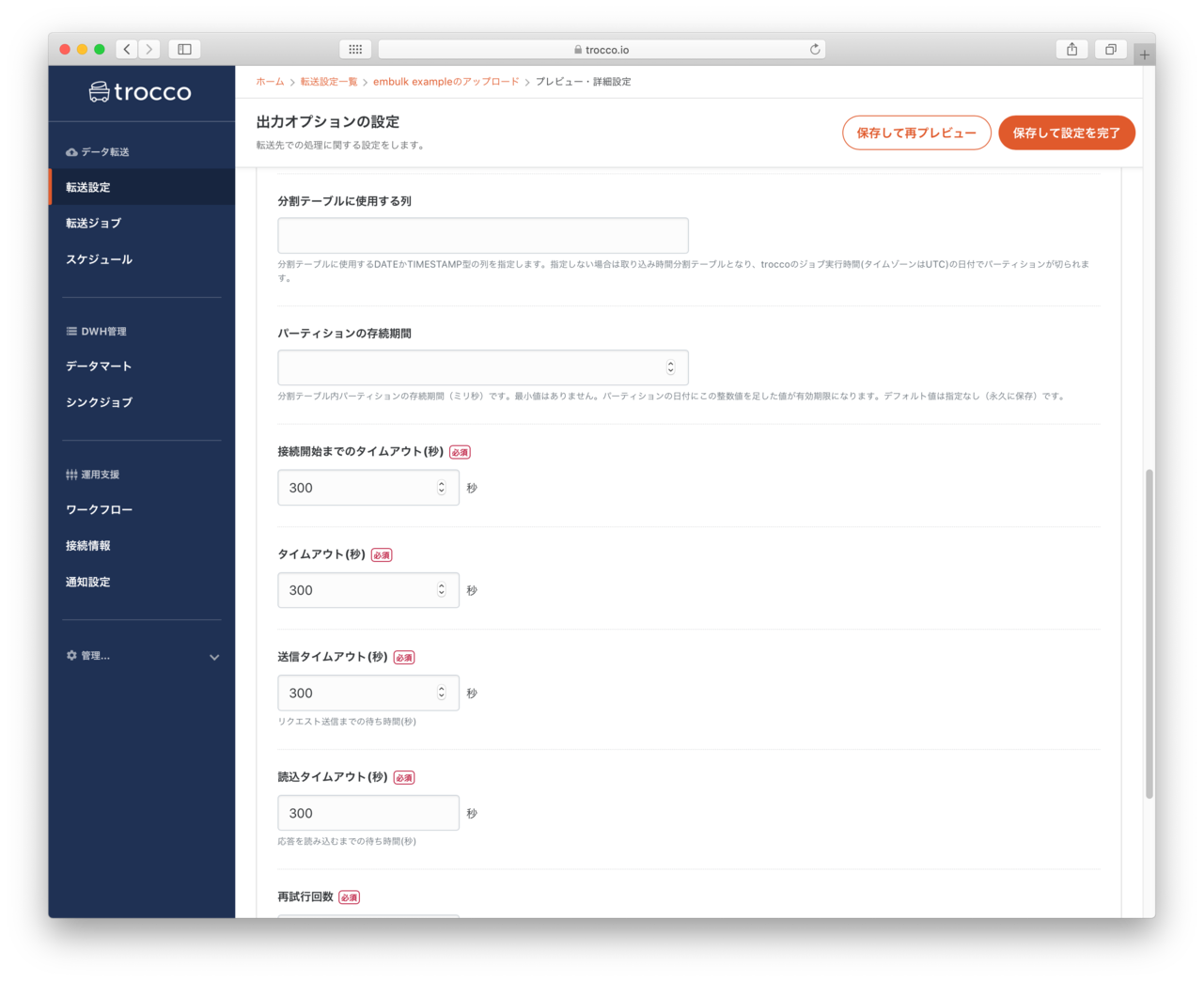
データプレビュー・出力オプション
- 転送先のBigQueryの設定を指定できるようです。(今回はデフォルト)
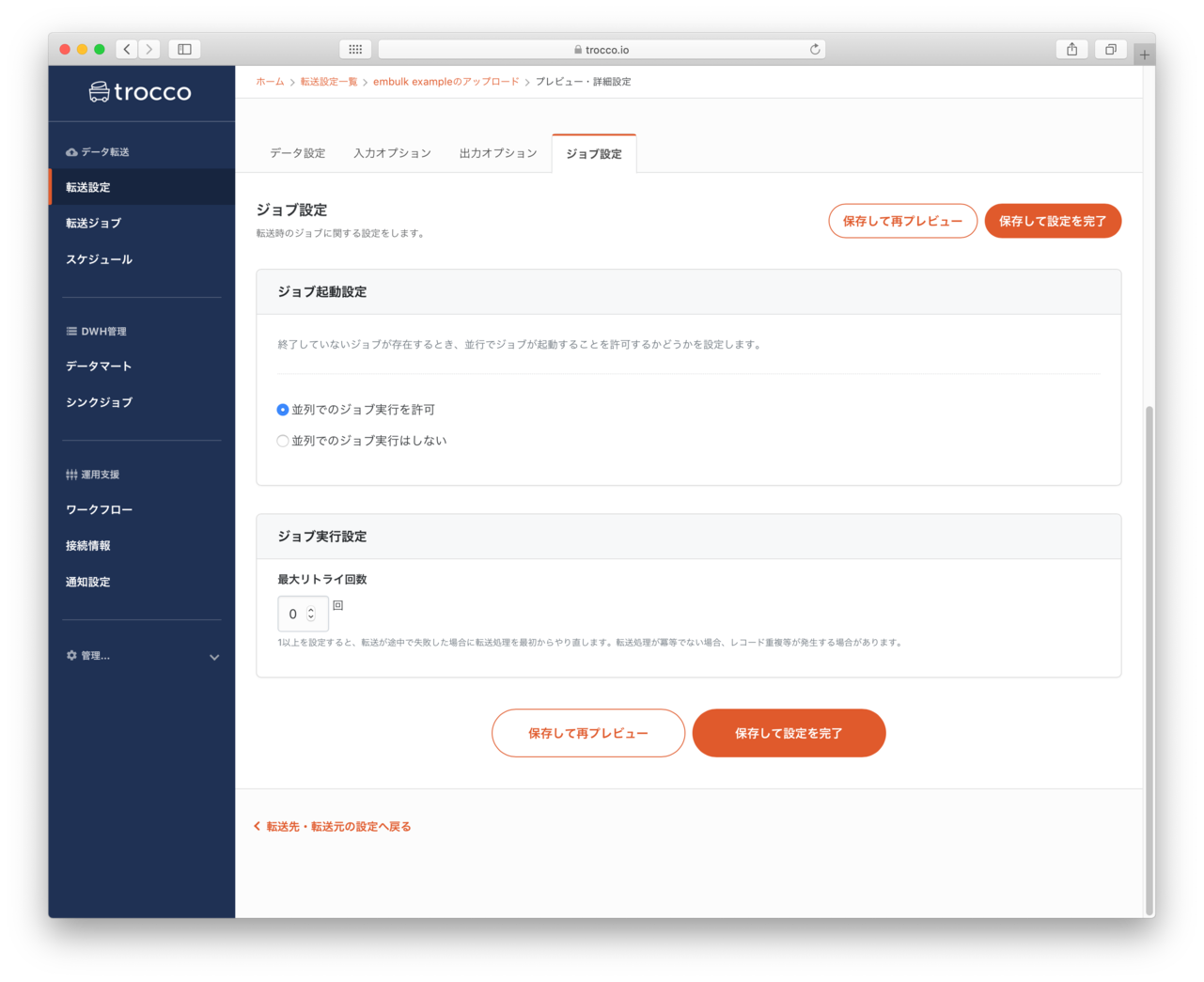
データプレビュー・ジョブ設定
- 転送時の並列数を指定して転送速度を速くしたり、エラーが発生した際に再実行する回数を指定できるようです(今回はデフォルト)
データプレビュー・ジョブ設定
- 保存して実行を完了するといよいよデータを実行の段階になるようです。
- ジョブの実行は次の二つがあるようです。
- 現在時刻で展開: 今すぐ登録したジョブを実行する
- 指定時刻で展開: 日時を指定してジョブを実行
- 今回は、現在時刻で実行を選択します。設定を終えたらジョブを実行ボタンを押します
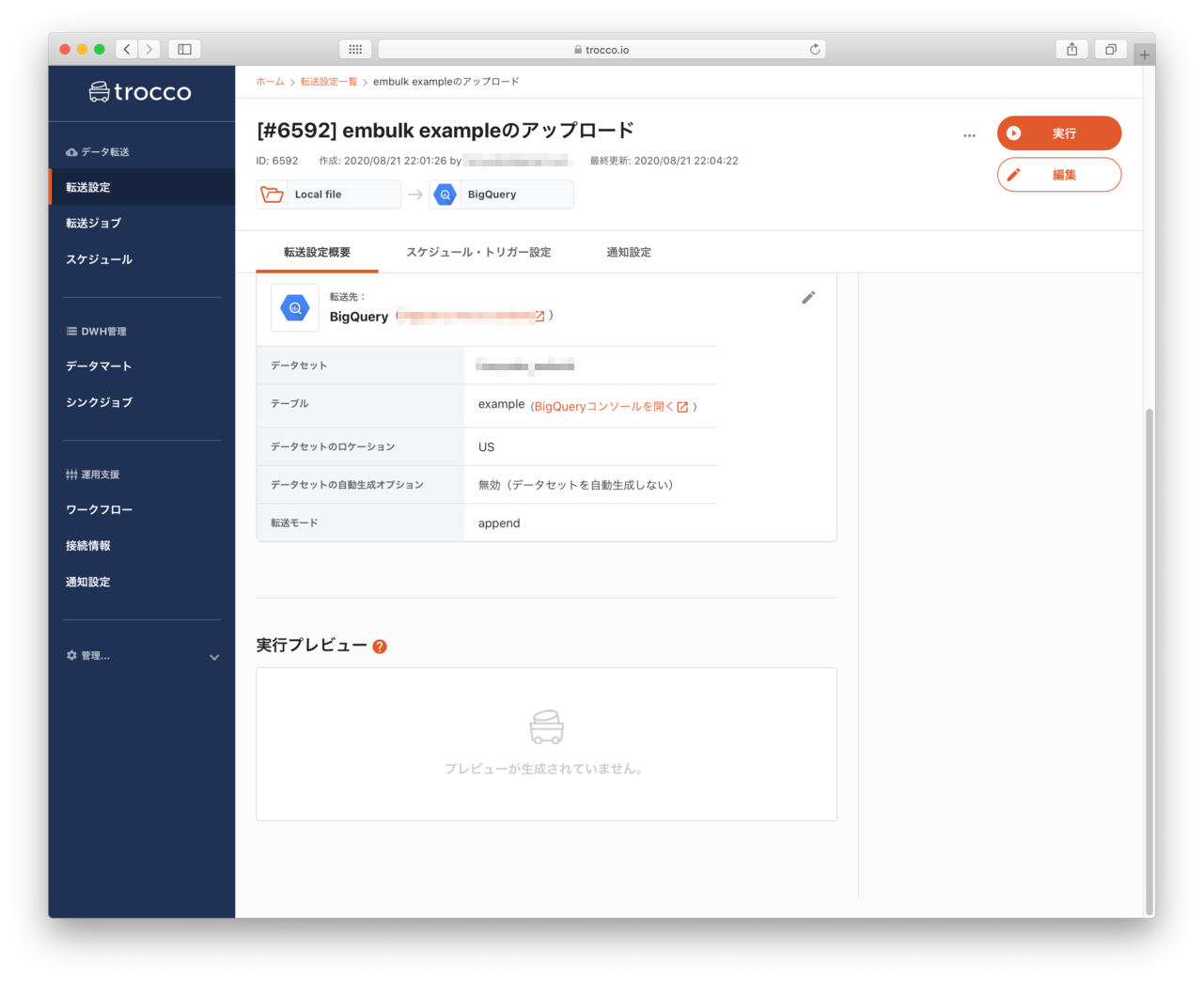

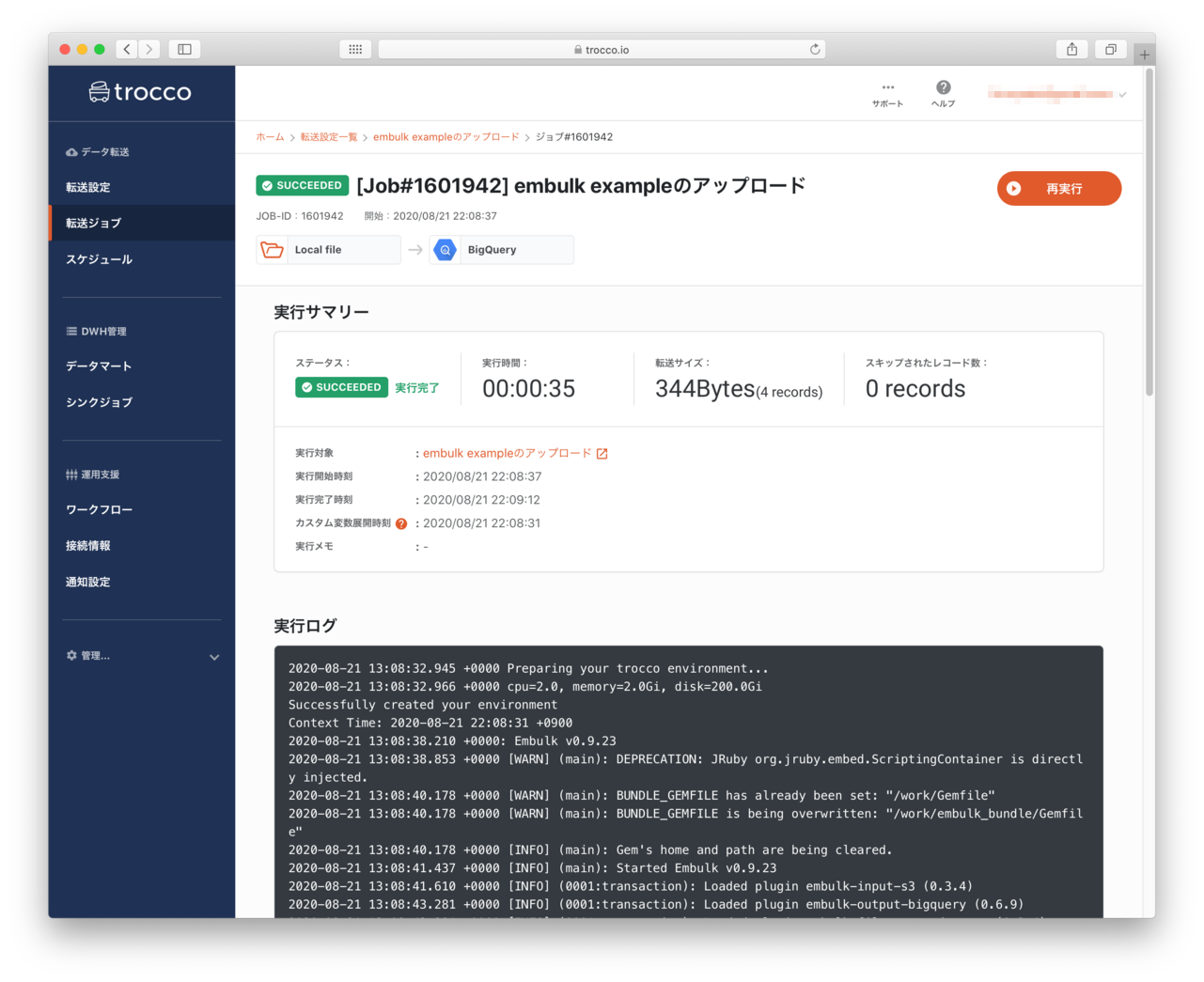
- ステータスが実行完了になりました
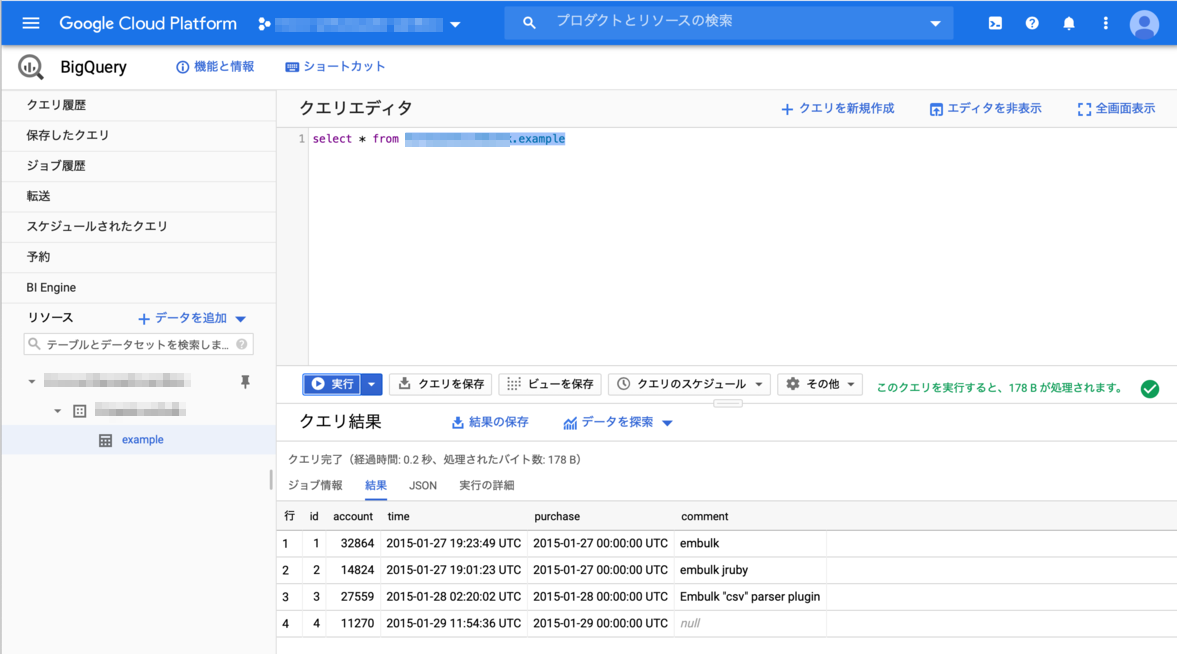
登録データの確認
- BigQueryのコンソールで、データが登録されているか確認をすると、指定したデータが登録されていることが確認できました。
感想
- Embulkの環境を用意することもなく、ファイルをアップロードして、GUIで設定をするだけで簡単にBigQueryにデータを登録することができました。
- 様々な入出力先に対応しているので、同様の操作で他社のサービスにも簡単にデータ登録をすることができそうです。
- Embulk本体にはない、時刻指定のアップロードや、再実行(プラグインのリトライではなく)機能も搭載されているようで、ネットワークのトラブルなどにも強いサービスのようです。(後日いろいろ試してみようと思います。)
最後に
- 今回は、embulkのサンプルデータをtroccoに登録してみました。
- 次回は、もう少しちゃんとしたデータを登録していろいろ確認をしてみたいと思います。