この記事について
この記事は、Go言語でGraphQLサーバの開発をする方法を書きます。
この記事で書くこと
- GraphQLのスキーマ定義
- Go言語でGraphQLサーバの開発方法
- フレームワークとしてgqlgenを利用
- エラー処理
- 負荷対策
- N+1問題
- クエリの大きさ判定
この記事で書かないこと
- Go言語の説明
- GraphQLの概要について
- バックエンドのデータベース(MySQL等)への接続方法
ソースコード
この記事で紹介するコードはGithubに置いております。
https://github.com/hiroyky/go_graphql_server_sample
前提条件
- Go言語の基本的な知識があり、お使いのマシンでGo言語のビルドや実行ができる。
- GraphQLの概要について知識がある。
GraphQLの概要は公式が詳しく説明をしています。
また、2021年11月23日現在 Go-1.17で試験しております。
開発の開始
GraphQLのフレームワークgqlgenを使ってGraphQLサーバの構築を始めます。
初期化
新規リポジトリに描きコマンドを順に実行してGo言語プロジェクトの初期化、GraphQLのフレームワークgqlgenの導入を行います。
$ go mod init
$ go get github.com/99designs/gqlgen
$ go run github.com/99designs/gqlgen init
これによって下記のファイル群が作成されています。
├── gqlgen.yml: コード自動生成の設定ファイル
├── graph
│ ├── generated
│ │ └── generated.go // 編集しないファイル
│ ├── model
│ │ └── models_gen.go // GraphQLで使う型が定義されているファイル
│ ├── resolver.go // リゾルバの定義
│ ├── schema.graphqls // GraphQLのスキーマ定義ファイル
│ └── schema.resolvers.go // 実際の処理を書くファイル
└── server.go // HTTPサーバの起動プログラム
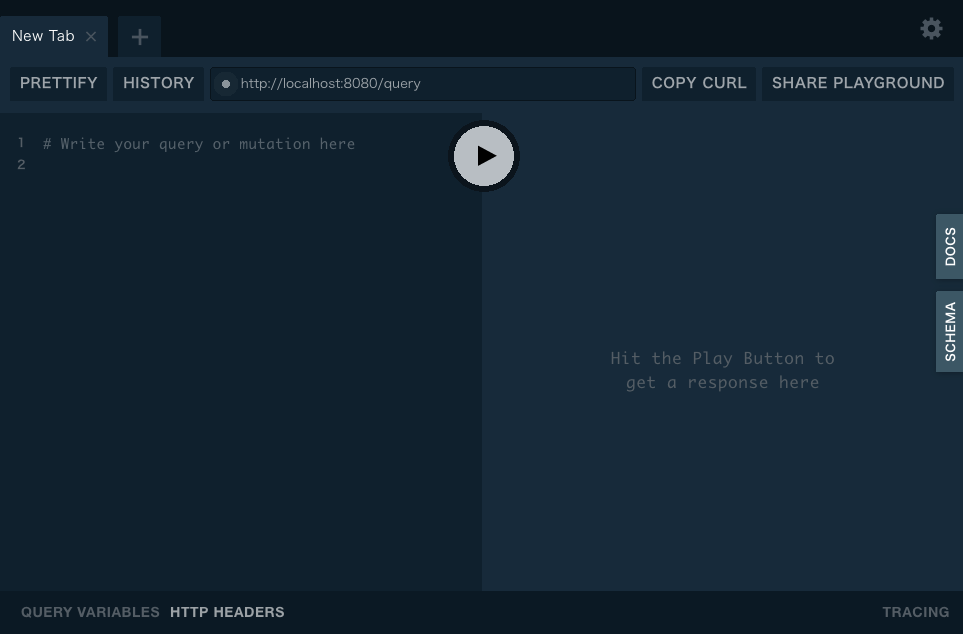
この段階でも下記を実行すれば、http://localhost:8080/ でプレイグラウンド画面を開くことができます。
$ go mod tidy
$ go run ./server.go
下図のプレイグラウンド画面でGraphQLを試すことができます。
ここまでの内容をこちらに設置しました。
https://github.com/hiroyky/go_graphql_server_sample/pull/1
GraphQLサーバ開発の流れ
先ほどの自動生成で、下記の3ファイルも実装され内容は以下のようになっています。
-
schema.graphqlsにTODOリストを模したスキーマが定義されています。 -
model/model_gen.goにGo言語でその型定義が記述されています。 -
schema.resolvers.goに処理を実装するための雛形が記載されています。
プログラムの作成手順は以下の流れになります。
-
*.graphqlsにGraphQLのスキーマ定義を書く。 - gqlgenの自動生成コマンド(
gqlgen)を実行する。 - 作成・更新された
model/model_go.goファイルを確認し、必要に応じて別ファイルに移して編集する。 -
*.resolvers.goファイルに処理本体を実装する。
*.graphqlsファイルと*.resolvers.goファイルは対になっています。
GraphQLのスキーマ定義(の復習)
GraphQLのスキーマ定義は、データの型定義と関数(メソッド)の定義で行います。どちらもGo言語やその他の言語の構造体・クラスの定義と同じ要領です。
型定義では、構造体名を決めて中身のフィールドを定義してきます。フィールドの型の基本形としてString, Int, Booleanが用意されています。他に、プライマリキーであることを示すID、列挙対、インターフェイス、独自型定義の仕組みが用意されています。
インターフェイスは共通するフィールドを定義します。インターフェイスを実装した型はかならずそのフィールドを持たなければイケません。プログラム言語にあるインターフェイスとほぼ等価と言えるでしょう。
関数(メソッド)の定義は2つに分かれています。取得系を定義するqueryと更新系を定義するmutationです。どちらも関数名、引数、戻り値を記述します。
スキーマ定義とコード生成
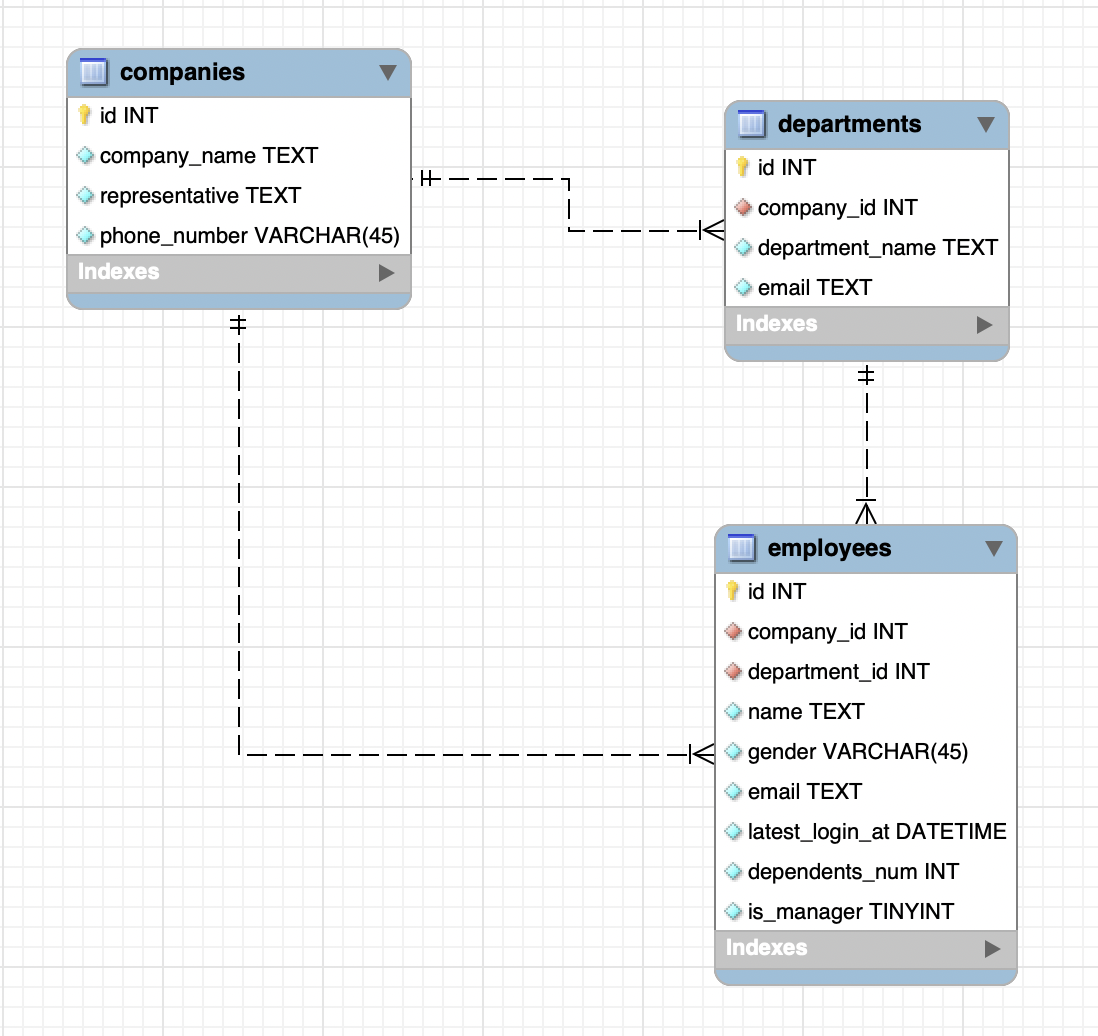
”会社と部署、会社員”という題材で設計
自動生成されたTODOリストのスキーマを題材に進めても良いのですが、ここでは会社(company)と部署(department),会社員(employee)というよくある題材で考えてみたいと思います。題材をMySQLのデータベーステーブルのER図で表すと下記のような構成です。本記事ではバックエンドのデータベースには触れませんがMySQLを使っている想定で話を進めます。
graph/model/schema.graphqlsとgraph/model/scheme.resolvers.goを削除して新規にスキーマ定義ファイルを作成しましょう。
$ rm ./graph/model/schema.graphqls
$ rm ./graph/model/schema.resovers.go
スキーマを定義する1[基本]
最初なので型定義の基本的な部分から順番に行いましょう。いずれもgraph/に設置します。
最初に全体で共用するインターフェイスNodeを定義します。プライマリキーidを持つ型にはNodeインターフェイスを実装するのがお作法のようです。また独自型としてTimestampを定義しています。型末尾の!は必須である(NULL値を許容しない)ことを示しています。
interface Node {
id: ID!
}
scalar Timestamp
それでは早速、インターフェイスNodeの実装としてCompany(会社), Department(部署),Employee(社員)の型を定義していきましょう。Employeeでは列挙対Genderも定義しています。(昨今では性別にMale, Female以外にも対応すべきと言う議論もありますが、ここでは無しで)
type Company implements Node {
id: ID!
companyName: String!
representative: String!
phoneNumber: String!
}
type Department implements Node {
id: ID!
departmentName: String!
email: String!
}
type Employee implements Node {
id: ID!
name: String!
gender: Gender!
email: String!
latestLoginAt: Timestamp!
""" 扶養家族の人数 """
dependentsNum: Int!
""" 管理職かどうか """
isManager: Boolean!
}
enum Gender {
Male
Female
}
Go言語や他の言語の構造体・クラスでのメンバ変数の定義とほぼ同じですね。
スキーマを定義する2 [他の型と紐付け]
それでは、更に型同士の紐付けも定義に組み込んでいきましょう。GraphQLの型定義ではリレーショナルデータベースでのリレーション(関係性)を持たせることができます。
まずはEmployeeから編集します。departmentとcompanyフィールドを追記します。こうすることでEmployeeから所属しているDepartmentやCompanyをたどれるようになります。そういえばデータベースのER図にはdepartment_idやcompany_idがありましたね。
type Employee implements Node {
id: ID!
name: String!
gender: Gender!
email: String!
latestLoginAt: Timestamp!
""" 扶養家族の人数 """
dependentsNum: Int!
""" 管理職かどうか """
isManager: Boolean!
department: Department! # 追記
company: Company! # 追記
}
enum Gender {
Male
Female
}
スキーマを定義する3 [ページネーション]
続いてDepartmentやCompanyにも同様に関連テーブルへの紐付けを追加していこうと思います。CompanyからDepartment、Employeeは1対多の関係です。従って配列で値を返すことになります。しかしながらAPIとして全件を毎回一括で返すわけにもいかないので、ページネーションを定義しましょう。(全件を一括返すような設計では、データベースが負荷で落ちますからね。)
また今回はLimit,Offsetによる一般的なページネーションを採用します。多くのリレーショナルデータベースではlimit,offsetで取得件数・取得位置を指定しますが、それと同じです。GraphQLではカーソル式のページネーションを採用する場合も多いようですが、今回は見送ります。
個人的な意見として、カーソル式のページネーションは、ツイッターやフェイスブックのタイムラインのように時々刻々とレコードが挿入されるデータには適していると思いますが、そうでないデータであれば、無理矢理カーソル式のページネーションを採用するのではなくLimit,Offsetによるページネーションの採用も検討すべきと思います。今回は会社と社員一覧と時々刻々と変化するデータでは無いのでLimit,Offsetによるページネーションが適していると考えます。
ページネーション定義の準備としてcommon.graphqlsに下記を追記します。
interface Pagination {
pageInfo: PaginationInfo!
nodes: [Node!]! # Node型の配列という意味
}
type PaginationInfo {
page: Int!
paginationLength: Int!
hasNextPage: Boolean!
hasPreviousPage: Boolean!
count: Int!
totalCount: Int!
}
それではDepartmentに紐付けを追加します。EmployeePaginationでページ位置情報とEmployeeの配列をフィールド名nodesで定義しています。
# 下記を追記
type EmployeePagination implements Pagination {
pageInfo: PaginationInfo!
nodes: [Employee!]!
}
type Department implements Node {
id: ID!
departmentName: String!
email: String!
company: Company! # 追記
employees: EmployeePagination! # 追記
}
同様にCompanyにも紐付けを追加します。
# 下記を追記
type DepartmentPagination implements Pagination {
pageInfo: PaginationInfo!
nodes: [Department!]!
}
type Company implements Node {
id: ID!
companyName: String!
representative: String!
phoneNumber: String!
departments: DepartmentPagination! # 追記
employees: EmployeePagination! # 追記
}
# 後ほど使うので併せて定義
type CompanyPagination implements Pagination{
pageInfo: PaginationInfo!
nodes: [Company!]!
}
スキーマを定義する4 [queryとmutation]
ここまでは型定義でしたが、関数(メソッド)の定義を行います。取得系のqueryと更新系のmutationを定義します。これらをラップする型名はそれぞれQuery, Mutationである必要があります。
関数の定義方法は一般的なプログラミング言語のそれと似ているので直感的に分かると思います。!が引数に付いていれば必須項目となり、戻り値についていればレスポンスがNULLで無いことが保証されているという意味になります。
関数名(引数1: 引数の型1!, 引数2: 引数の型2..): 戻り値の型
queryでは各型に対して単数形と複数形で取得関数を定義しています。いずれもlimit,offsetで取得件数と取得位置を指定できるようにしています。なおlimitは必須になっています。employeesではそれ以外にも絞り込み項目を定義しました。
type Query {
company(id: ID!): Company
companies(limit: Int!, offset: Int): CompanyPagination!
department(id: ID!): Department
departments(limit: Int!, offset: Int): DepartmentPagination!
employee(id: ID!): Employee
employees(
limit: Int!,
offset: Int,
email: String
gender: Gender,
isManager: Boolean,
hasDependent: Boolean
): EmployeePagination!
}
更新系のミュテーションをmutation.graphqlsに定義します。ミュテーションの引数はinputとしてまとめています。引数の型定義はtypeではなくinput Xxxx {}で記述します。戻り値は、作成・更新した場合には新しい値を、削除の場合はいったんtrueを固定で返す定義です。
type Mutation {
createCompany(input: CreateCompanyInput!): Company!
updateCompany(input: UpdateCompanyInput!): Company!
deleteCompany(id: ID!): Boolean!
createDepartment(input: CreateDepartmentInput!): Department!
updateDepartment(input: UpdateDepartmentInput!): Department!
deleteDepartment(id: ID!): Boolean!
createEmployee(input: CreateEmployeeInput!): Employee!
updateEmployee(input: UpdateEmployeeInput!): Employee!
deleteEmployee(id: ID!): Boolean!
}
input CreateCompanyInput {
companyName: String!
representative: String!
phoneNumber: String!
}
input UpdateCompanyInput {
id: ID!
companyName: String
representative: String
phoneNumber: String
}
input CreateDepartmentInput {
departmentName: String!
email: String!
}
input UpdateDepartmentInput {
id: ID!
departmentName: String
email: String
}
input CreateEmployeeInput {
name: String!
gender: Gender!
email: String!
dependentsNum: Int!
isManager: Boolean!
}
input UpdateEmployeeInput {
id: ID!
name: String
gender: Gender
email: String
dependentsNum: Int
isManager: Boolean
}
ここまでの更新をGithubのプルリクにまとめました。ブランチはfeat2です。
https://github.com/hiroyky/go_graphql_server_sample/pull/2/files
コード生成
コード生成1 [gqlgenを実行]
スキーマ定義ができたらgqlgenコマンドでスキーマ定義を元にGo言語のプログラムを自動生成します。
$ go run github.com/99designs/gqlgen
下記のような構成でGo言語のファイルが生成されていると思います。
./graph
├── generated
│ └── generated.go
├── model
│ └── models_gen.go
├── mutations.resolvers.go
├── query.resolvers.go
└── resolver.go
query.resolvers.goとmutations.resolvers.goには、先ほど定義した関数がGo言語の関数で定義されています。
引数の定義で!を付けて必須化した引数は値ですが、必須で無い引数はポインタ型になっています。未指定の場合はNULLが入ります。
// ・・・・
func (r *queryResolver) Employee(ctx context.Context, id string) (*model.Employee, error) {
panic(fmt.Errorf("not implemented"))
}
func (r *queryResolver) Employees(ctx context.Context, limit int, offset *int, email *string, gender *model.Gender, isManager *bool, hasDependent *bool) (*model.EmployeePagination, error) {
panic(fmt.Errorf("not implemented"))
}
// ・・・・
コード生成2 [構造体を編集して再生成]
ところで、model/models_gen.goで定義した型を確認しましょう。Employeeは次のように定義されています。スキーマ定義に書いたコメントも反映されていますね。
type Employee struct {
ID string `json:"id"`
Name string `json:"name"`
Gender Gender `json:"gender"`
Email string `json:"email"`
LatestLoginAt string `json:"latestLoginAt"`
// 扶養家族の人数
DependentsNum int `json:"dependentsNum"`
// 管理職かどうか
IsManager bool `json:"isManager"`
Department *Department `json:"department"`
Company *Company `json:"company"`
}
さて、ここで着目しなければいけないのはDepartmentとCompanyです。一見問題ないように見えますが、問題があるのです。
バックエンドのデータベースにMySQL等のリレーショナルデータベースを使ってる場合、データベースのテーブルとしてはDepartmentとCompanyが直接入るのではなくdepartment_id,company_idといった外部キーのIDになると思います。そしてCompanyやDepartmentの中身が欲しいときは、別途SQLを実行するか結合を含んだSQLを実行する必要があります。GraphQLではリクエストのクエリにDepartmentやCompanyの指定があったときだけ別途SQLを実行するような柔軟な仕様にできます。つまづきポイントの1つだと思うのでまずは一緒にやってみましょう。
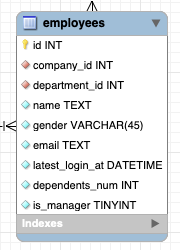
自動生成のモデル型を変更します。ただmodels/models_gen.goは自動生成の度に再生成されるのでこのファイルを直接編集はしません。代わりに同じディレクトリ(パッケージ)にmodels/models.goを新規作成して下記のように記述します。その際にmodels_gen.goのEmployee構造体を削除します。
着目して欲しいのは Department *DepartmentやCompany *Companyを削除して代わりにDepartmentID stringとCompanyID stringを定義しています。これでデータベースのテーブル定義に近づきました。IDはint型では?という声が聞こえてきそうですがstring型にします。理由は後述します。
package model
type Employee struct {
ID string `json:"id"`
Name string `json:"name"`
Gender Gender `json:"gender"`
Email string `json:"email"`
LatestLoginAt string `json:"latestLoginAt"`
// 扶養家族の人数
DependentsNum int `json:"dependentsNum"`
// 管理職かどうか
IsManager bool `json:"isManager"`
DepartmentID string `json:"department"` // Departmentを削除して、代わりにDepartmentIDを記述
CompanyID string `json:"company"` // Companyを削除して、代わりにCompanyIDを記述
}
func (Employee) IsNode() {}
ここまで編集したら改めてgqlgenコマンドを実行します。
$ go run github.com/99designs/gqlgen
するとどうなるでしょうか?新たにemployee.resolvers.goが生成されました。これには2つの関数が定義されています。第二引数でEmployeeを受け取り、DepartmentやCompanyを返す関数です。
これは、先ほど自身で定義し直したEmployeeについてgqlgenがDepartmentとCompanyが不足していたことを検知して、不足分を取得するための関数を定義したのです。関数の第2引数では親であるEmployeeが渡されるのでそれを手がかりに子のCompanyやDepartmentを取得する処理を実装します。
func (r *employeeResolver) Department(ctx context.Context, obj *model.Employee) (*model.Department, error) {
panic(fmt.Errorf("not implemented"))
}
func (r *employeeResolver) Company(ctx context.Context, obj *model.Employee) (*model.Company, error) {
panic(fmt.Errorf("not implemented"))
}
これらの関数はクライアントがEmployeeのクエリでdepartmentやcompanyを指定したときのみ実行されます。必要でなければ呼び出されません。たとえば以下のリクエストクエリではdepartment()は呼び出されますがcompany()は指定していないので呼び出されません。
query {
employee(id:"RW1wbG95ZWU6MQ==") {
id
name
department {
id
departmentName
}
}
}
さて、それでは他のCompanyやDepertmentの構造体も同様に編集していきます。models_gen.goからmodels.goに移動して追加削除をします。
type Company struct {
ID string `json:"id"`
CompanyName string `json:"companyName"`
Representative string `json:"representative"`
PhoneNumber string `json:"phoneNumber"`
// Departmentsのフィールド自体を削除
// Employeesのフィールド自体を削除
}
func (Company) IsNode() {}
type Department struct {
ID string `json:"id"`
DepartmentName string `json:"departmentName"`
Email string `json:"email"`
CompanyID string `json:"company"` // Companiesを削除して、CompanyIDを追記
// Employeesのフィールド自体を削除
}
func (Department) IsNode() {}
ここまで編集したら改めてgqlgenコマンドを実行します。
$ go run github.com/99designs/gqlgen
先ほどと同様に構造体とGraphQLのスキーマ定義で乖離している部分をgqlgenが検知して不足部分を補うための関数が生成されました。例えば新規作成されたcompanies.resolvers.goは以下のように親であるCompanyを第二引数に受けてDepartmentPagination, EmployeePaginationを返す関数が定義されています。
func (r *companyResolver) Departments(ctx context.Context, obj *model.Company) (*model.DepartmentPagination, error) {
panic(fmt.Errorf("not implemented"))
}
func (r *companyResolver) Employees(ctx context.Context, obj *model.Company) (*model.EmployeePagination, error) {
panic(fmt.Errorf("not implemented"))
}
ここまでの編集をプルリクにまとめました。ブランチはfeat3です。
https://github.com/hiroyky/go_graphql_server_sample/pull/3
中身の実装とプライマリキーの注意点
さて、ここからは自動生成されたリゾルバ関数の中身の実装を行います。バックエンドのデータベースに接続したり、別のREST APIにリクエストしたりなどです。本記事ではデータベースやREST APIとの通信は趣旨からずれるので記述しません。ぜひご自身で中身の実装をすすめてください。
ただ、1点注意事項があります。それはプライマリキーIDを型を横断してグローバルでユニークにするということです。つまり、Employeeのidが1,2,3...と連番でDepartmentのidも1,2,3..と連番ではIDはグローバルでユニークではありません。そこでプライマリキーを次のように型名とセットで記述します。
- Employee:1
- Employee:2
- Employee:3
- ...
- Department:1
- Department:2
- Department:3
- ...
GraphQLでは更にこれをBase64エンコードした物をプライマリキーとして扱うのが一般的です。
- base64(Employee:1) = "RW1wbG95ZWU6MQ=="
- base64(Department:1) = "RGVwYXJ0bWVudDox
これを実現するために構造体のidをint型ではなくstring型にしました。バックエンドデータベースのMySQL等ではintの連番でプライマリキーを管理していても、GraphQLのレスポンスやリクエスト引数では型名とセットにした文字列(型名:番号)のbase64文字列に変換すべきです。理由は、GraphQLでは、型関係なくID自体でキャッシュ等を管理するので、IDの重複を避けるためです。従って、プライマリキーにUUIDなどのそれ自体が唯一無二な形式を用いているのであれば変換をする必要はありません。
Global Object Identificationに解説があります。
エラー処理
リゾルバでエラーを生成して、エラーレスポンスを返す必要な場面があります。gqlgenフレームワークはその機能も備えています。
GraphQLのレスポンスJSONは正常系であればでdataのみを返しますが、エラーレスポンスではerrors配列を返します。エラーには次の項目を含めます。
- message: エラーの内容を簡潔に伝えるメッセージ
- path: エラーが起こった場所(クエリの位置)
- extensions: それ以外にクライアントに伝えたい内容があれば
key:value形式で記述
{
"data": {},
"errors": [
{
"message": "Error: hoge fuga",
"path": [ "employee" ],
"extensions": {"key1": "value1"}
},
{ "message": "Error: foo bar", "path": [ "department" ] },
]
}
これを実現するために server.goのgraphqlサーバを編集します。サーバインスタンスのSetErrorPresenterの引数にエラーレスポンスを生成する関数を書きます。引数のerrorにリゾルバ等で投げられたエラーが入るのでそれを元にエラーレスポンスを生成します。gqlerror.Error型をこの関数で返します。
srv := handler.NewDefaultServer(generated.NewExecutableSchema(generated.Config{Resolvers: &graph.Resolver{}}))
// エラー処理を書く
srv.SetErrorPresenter(func(ctx context.Context, e error) *gqlerror.Error {
err := graphql.DefaultErrorPresenter(ctx, e)
err.Message = e.Error()
err.Extensions = map[string]interface{}{
"key1": "value1",
"key2": "value2",
}
return err
})
この内容をプルリクにしています。ブランチはfeat4
https://github.com/hiroyky/go_graphql_server_sample/pull/4
公式の文献は https://gqlgen.com/reference/errors/
負荷対策
N+1問題対策
概要
GraphQLあるあるの問題としてN+1問題があります。クエリで子要素を参照したときに、都度リゾルバが実行されるため、バックエンドのデータベースやAPIに大量のリクエストが発生する現象です。
例えば、下記のようにEmployeeの配列から所属Companyを参照するクエリを書いた場合です。この時、company()リゾルバが都度実行されます(最大100回)。従ってバックエンドのデータベース等へもリクエストが都度発生するためデータベースへの負荷が大きくなります。
query {
employees(limit:100) {
nodes {
name
company {
companyName
}
}
}
}
SELECT * FROM companies WHERE company_id=1;
SELECT * FROM companies WHERE company_id=1;
SELECT * FROM companies WHERE company_id=2;
SELECT * FROM companies WHERE company_id=3;
-- ・・・
この「N+1問題」の解決策としてdataloaderを用いた手段があります。これは毎回バックエンドへリクエストを発生するのではなく、ある一定期間処理を溜めてからバックエンドにリクエストをまとめて送るようにするものです。これにより下記のように1クエリにまとめられます。
SELECT * FROM companies WHERE company_id IN (1,2,3);
導入・実装
実現するために dataloadenを利用します。
$ go get github.com/vektah/dataloaden
他の言語のdataloaderではジェネリクス型等で対応するようですが、Go言語のdataloaderはコード生成します。
$ mkdir dataloader
$ cd dataloader
$ echo "package dataloader" > gen.go
$ go run github.com/vektah/dataloaden CompanyLoader string "*github.com/hiroyky/go_graphql_server_sample/graph/model.Company"
dataloader/companyloader_gen.goが生成されました。Companyの取得では、このCompanyLoaderを使うように編集してみましょう。
まずは各リゾルバから参照できるようにresolver.goにフィールドを設けます。
type Resolver struct{
CompanyLoader *dataloader.CompanyLoader // 追記
}
server.goでGraphQLサーバ起動時にCompanyLoaderを生成して、渡すようにします。(main関数に書くべき内容ではないと思いますが、簡略化のためにmain関数に書きます。)
Fetchにデータをまとめて取得する処理を書きます。引数のkeysには、呼び出し時に溜めた引数がまとめて渡されます。keysの順番通りに値を返します。
func main() {
// ・・・省略・・・
companyLoader := dataloader.NewCompanyLoader(dataloader.CompanyLoaderConfig{
MaxBatch: 100, // 溜める最大数、0を指定すると制限無し
Wait: 2 * time.Millisecond, // 溜める時間
Fetch: func(keys []string) ([]*model.Company, []error) {
companies := make([]*model.Company, len(keys))
errors := make([]error, len(keys))
// 取得処理を書く SELECT * FROM company WHERE company_id IN (...)
// 引数のkeysに対応する順番の配列で返す。
return companies, errors
},
})
srv := handler.NewDefaultServer(generated.NewExecutableSchema(generated.Config{Resolvers: &graph.Resolver{
CompanyLoader: companyLoader,
}}))
// ・・・省略・・・
}
呼び出しは以下のように行います。Company.Loadを呼び出すことで、先ほどFetchに定義した関数が実行されます。即時都度実行されるわけではなく、溜めてからまとめて実行されます。
func (r *employeeResolver) Company(ctx context.Context, obj *model.Employee) (*model.Company, error) {
return r.CompanyLoader.Load(obj.CompanyID)
}
dataloaderの生成コマンドについて改めてまとめます。
$ cd dataloader
$ echo "package dataloader" > gen.go
■int型を引数に取る関数でロードしたい場合
先ほどはコマンドの第二引数に`string`を指定しました。これは`Fetch関数`の引数の型に対応します。従って`CompanyLoader.Load()`関数の引数を`int`型にしたい場合は`int`を指定します。
$ go run github.com/vektah/dataloaden CompanyLoader int "*github.com/hiroyky/go_graphql_server_sample/graph/model.Company"
■配列を戻り値のロード関数を生成したい場合
`Load()`関数で配列を戻り値にすることもできます。`Fetch`関数の配列処理の実装が少し複雑になるので注意してください。おそらく二重のforループが発生するため。
$ go run github.com/vektah/dataloaden CompaniesLoader int "[]*github.com/hiroyky/go_graphql_server_sample/graph/model.Company"
以上、N+1問題を解決するためにdatalodaerを導入しました。
ここまでをプルリクにまとめました。ブランチはfeat5
https://github.com/hiroyky/go_graphql_server_sample/pull/5
公式文献:
クエリの重さ制限
概要
GraphQLのAPIでは、クライアント側が自由にクエリを作成してリクエストすることができます。一方で、負荷が重いクエリも簡単にリクエストできてしまう問題があります。そこでクエリを実行する前に、クエリの重さを計算して一定以上であれば実行せずにエラーレスポンスを返すという機能があります。
GraphQLのAPI自体をグローバルに公開する場合には導入が必須かとは思いますが、アクセス元が社内サーバに限定されるなどの場合には、アクセス元のシステムを開発しているチームとクエリ内容を事前に相談するという解決策でも良いかと思います。
導入・実装
導入の仕方自体は簡単で、端的に言えば下記一行をserver.goに足すだけです。引数に重さの上限を指定します。1項目辺り1として計算され、この値を超えたらエラーレスポンスを返します。
srv.Use(extension.FixedComplexityLimit(10)) // 重さが10を超えたらエラーにする
しかしながら、全ての項目が等しい負荷であるわけがありません。例えば配列を返す項目や、更新系のミュテーションは通常よりも重いクエリのはずです。そこで、スキーマの項目毎に計算関数を定義できます。
これまではサーバのNew関数に直接渡していた引数である設定を編集します。
srv := handler.NewDefaultServer(generated.NewExecutableSchema(generated.Config{Resolvers: &graph.Resolver{CompanyLoader: companyLoader}}))
上記を下記のようにします。c.Complexity以下で重さを計算する関数を定義します。関数の第一引数にはリクエストで要求されたレスポンスの項目数、第二引数にはリクエストの引数が与えられます。それらを元に重さを計算して数値で返します。
c := generated.Config{Resolvers: &graph.Resolver{CompanyLoader: companyLoader}}
c.Complexity.Mutation.CreateCompany = func(childComplexity int, input model.CreateCompanyInput) int {
return 5
}
srv := handler.NewDefaultServer(generated.NewExecutableSchema(c))
以上、クエリの重さ計算の処理でした。
といいつつも、アクセス元が社内サーバだけに限定してアクセス元の開発チームとクエリ内容を事前相談しておくということが可能であれば、そうしたほうが良い気もしますが..
まとめ
gqlgenを使ったGO言語でのGraphQLサーバの実装について記述しました。
gqlgenでの開発手順は下記の手順でした。これの繰り返しです。
- スキーマ定義
- コード生成
- 生成されたコードの調整
- コード生成
- リゾルバに処理を書く
他に、エラー処理や負荷対策を記述しました。
拝読ありがとうございました。お疲れ様でした。