はじめに
Google CloudのDataprocはApache Hadoop/Apache Sparkのクラスターをホストするためのマネージドサービスです。
今回は、1つのDataprocクラスターを複数ユーザーで使用する場合にDataprocクラスター経由でのGoogle Cloud上のリソースへのアクセスをきめ細かく制御できる「Dataproc サービスアカウントベースの安全なマルチテナンシー」を紹介します。
課題
ユーザーAはCloud StorageのバケットAのデータのみ使用可能、ユーザーBはCloud StorageのバケットBのデータのみアクセス可能という要件があるとします。
このような場合、各ユーザーが直接バケットにアクセスするケースに関しては、下図のように各バケットに対してポリシーを設定することで容易にアクセス制御が可能です1。


しかし、データ分析のために1つのDataprocクラスターを複数ユーザーで共用するようなケースを考えてみましょう。
この場合、通常の方法ではユーザーAがクラスターを使用する場合も、ユーザーBがクラスターを使用する場合も、共通のサービスアカウントが使用され、これをもとにアクセス制御が行われます。そのため、ユーザーAとユーザーBでアクセス可能なリソースを分けるという制御ができません。
結果として、下図のようにユーザーAもユーザーBもバケットA、バケットB両方にアクセス可能という状態にせざるを得ません。
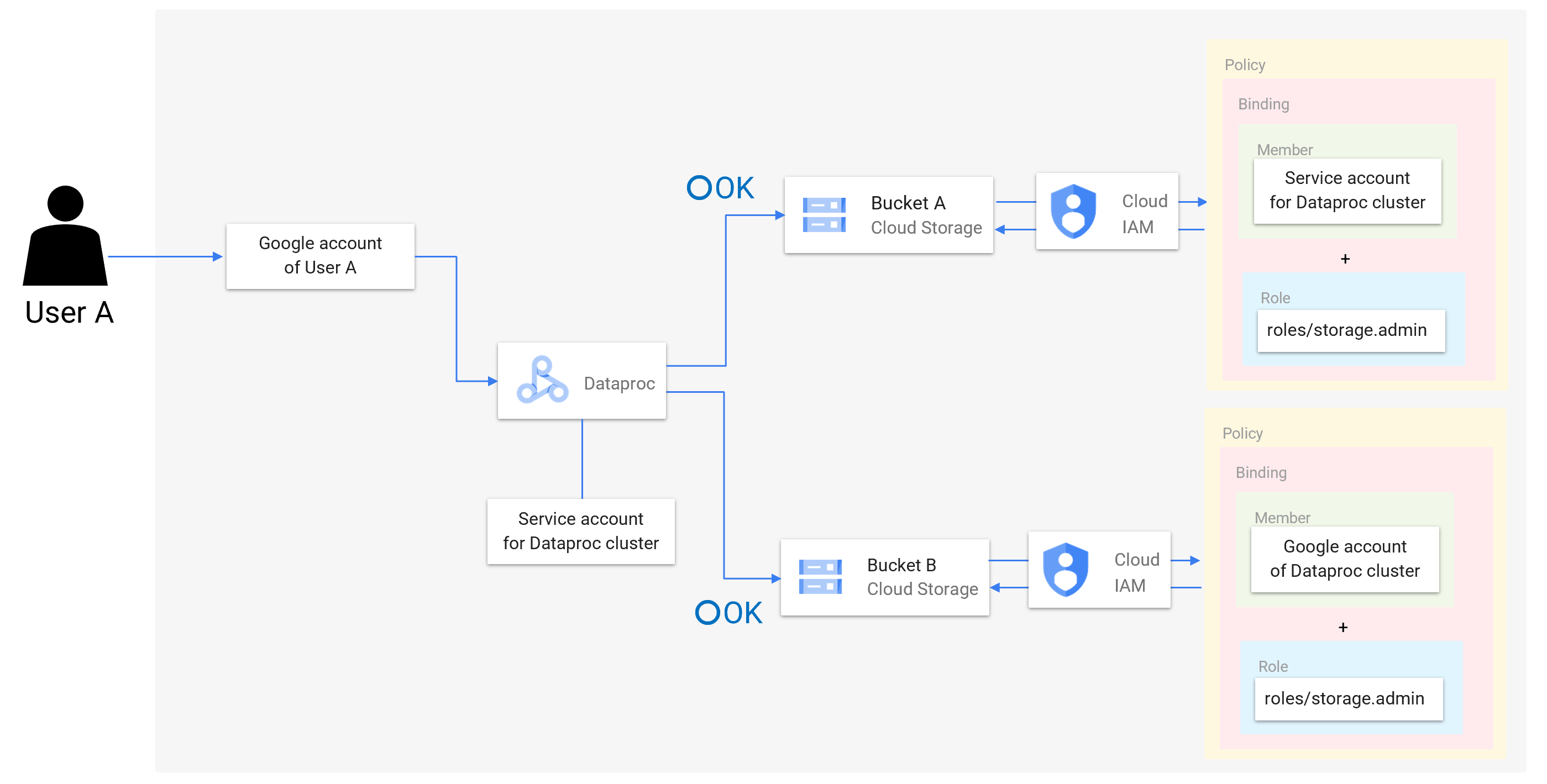

そこで登場するのが「Dataproc サービスアカウントベースの安全なマルチテナンシー」です。これを使用することによってユーザ毎に異なる権限を使用して、きめ細かなアクセス制御ができるようになります。
Dataproc サービスアカウントベースの安全なマルチテナンシー
概要
「Dataproc サービスアカウントベースの安全なマルチテナンシー」では、事前にユーザー毎にサービスアカウントを用意しておき、クラスターにアクセスするユーザーに対応したサービスアカウントを使用する(クラスターのサービスアカウントが各ユーザー用のサービスアカウントに成り代わるという挙動をとっているようです)ことでGoogle Cloudリソースへのアクセスを制御します。これによってDataprocを経由したGoogle Cloudリソースへのアクセスにおいても、下図のように、バケットAに対してユーザーA用のサービスアカウントにrole/storage.adminを付与するポリシーを設定し、バケットBに対してユーザーB用のサービスアカウントにrole/storage.adminを付与するポリシーを設定することで、ユーザーAはバケットAのデータのみ使用可能、ユーザーBはバケットBのデータのみアクセス可能といった要件を満たすことができます。


制限事項
Dataproc サービスアカウントベースの安全なマルチテナンシーでは、いくつか制限事項があり、公式ガイドの「考慮事項と制限事項」に記載されています。
特に気になるのは以下2点です。
・Dataproc のコンポーネント ゲートウェイが有効になっていません。
・クラスタ VM 上で起動スクリプトを実行するなど、クラスタと Compute Engine の機能への直接的な SSH アクセスはブロックされます。また、sudo 権限を使用してジョブを実行することはできません。
2点目のSSH アクセスがブロックされるというのはそのままの意味ですが、1点目の「コンポーネント ゲートウェイ」とは、Dataprocクラスタ上のコンポーネントのWebインターフェースにアクセスできる仕組みです。これを使用することで例えば以下のようにJupyter Notebook等を使えます。

すなわち、Dataproc サービスアカウントベースの安全なマルチテナンシーを使用する場合、ジョブはクラスタにSSHでアクセスして実行したりWebインターフェースから実行したりできず、gcloud dataproc jobs submit等で送信して実行する必要があるため用途によっては若干使いにくいかもしれません。
使ってみた
Google Cloud公式のブログ記事に従って「Dataproc サービスアカウントベースの安全なマルチテナンシー」を使ってみましたので、その手順を記載します。
ブログ記事では「Dataproc 協調型マルチテナンシー」となっていますが、「Dataproc サービスアカウントベースの安全なマルチテナンシー」と同じものです。ただし、GA前に投稿された記事のため、公式ガイドの記載と差異がある場合は公式ガイドを優先することにします。
なお、「Dataproc サービスアカウントベースの安全なマルチテナンシー」を有効にしたDataprocクラスターはコンソールからも作成できますが、今回はブログ記事に従って、CLIで行うことにします。

前提
- 操作はCloud Shellから実行します。
- 操作にはプロジェクトのオーナー権限を持つユーザのアカウントを使用します(権限の付与等、一部の操作は編集者権限では不可のため)。
- ブログ記事ではユーザーAはCloud Storageバケットにアクセス可、ユーザーBはCloud Storageバケットにアクセス不可の場合を示していますが、今回は上記に示した、ユーザーAはバケットAのデータのみ使用可能、ユーザーBはバケットBのデータのみ使用可能という条件で試してみます。
準備
-
現在アクティブになっているアカウントの取得
USER_A=$(gcloud auth list --filter=status:ACTIVE --format="value(account)") -
カレントプロジェクトの設定
PROJECT_ID=<プロジェクトID> gcloud config set project ${PROJECT_ID}
ユーザーBをシミュレートするサービスアカウントの作成
ユーザーAは自分のGoogleアカウントを使用するとして、ユーザーBに相当するものを作成する必要があります。この際、単純にGoogleアカウントを作成しても良いのですが、ブログ記事にはサービスアカウントを作成することで2番目のユーザーをシミュレートできるとあるので、これに従って試してみます。
-
サービスアカウントの作成
USER_B_SA_NAME=user-b gcloud iam service-accounts create ${USER_B_SA_NAME} USER_B=${USER_B_SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com -
作成したサービスアカウントでDataprocクラスタへのジョブ送信を行えるように、Dataproc 編集者ロールを付与する
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member serviceAccount:${USER_B} \ --role roles/dataproc.editor -
サービスアカウントのキーを作成してサービスアカウントをアクティベートする
gcloud iam service-accounts keys create ./key.json --iam-account ${USER_B} gcloud auth activate-service-account ${USER_B} --key-file ./key.json rm ./key.json -
アカウントが切り替わっているので元に戻す
以下のコマンドを実行すると、アクティブアカウントが作成したサービスアカウントに切り替わっていることが分かります。$ gcloud auth list --filter=status:ACTIVE --format="value(account)" user-b@<プロジェクトID>.iam.gserviceaccount.comそのため、元のアカウントがアクティブになるようにします。
gcloud config set account ${USER_A}
Dataproc用サービスアカウントの作成
-
以下3つのサービスアカウントを作成する
-
VM_SA_NAME=vm-service-account gcloud iam service-accounts create ${VM_SA_NAME} VM_SA=${VM_SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com -
ユーザーA用のサービスアカウント
USER_A_SA_NAME=user-a-service-account gcloud iam service-accounts create ${USER_A_SA_NAME} USER_A_SA=${USER_A_SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com -
ユーザーB用のサービスアカウント
USER_B_SA_NAME=user-b-service-account gcloud iam service-accounts create ${USER_B_SA_NAME} USER_B_SA=${USER_B_SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
-
-
VMサービスアカウントに対し、ユーザーA用のサービスアカウントに成り代わる権限を付与する
gcloud iam service-accounts add-iam-policy-binding \ ${USER_A_SA} \ --member serviceAccount:${VM_SA} \ --role roles/iam.serviceAccountTokenCreator -
同様に、VMサービスアカウントに対し、ユーザーB用のサービスアカウントに成り代わる権限も付与する
gcloud iam service-accounts add-iam-policy-binding \ ${USER_B_SA} \ --member serviceAccount:${VM_SA} \ --role roles/iam.serviceAccountTokenCreator -
クラスタでジョブを実行するためにVMサービスアカウントに、
dataproc.workerロールを付与するgcloud projects add-iam-policy-binding \ ${PROJECT_ID} \ --member serviceAccount:${VM_SA} \ --role roles/dataproc.worker
Cloud Storageバケットおよびオブジェクトの作成
-
バケットの作成
BUCKET_A=<ユーザーA用バケットのバケット名> gsutil mb gs://${BUCKET_A} BUCKET_B=<ユーザーB用バケットのバケット名> gsutil mb gs://${BUCKET_B} -
オブジェクトの作成
echo "This is a simple file" | gsutil cp - gs://${BUCKET_A}/file echo "This is a file for User B" | gsutil cp - gs://${BUCKET_B}/file -
ユーザーA用のサービスアカウントへの
${BUCKET_A}に対する権限付与gsutil iam ch serviceAccount:${USER_A_SA}:admin gs://${BUCKET_A} -
ユーザーB用のサービスアカウントへの
${BUCKET_B}に対する権限付与gsutil iam ch serviceAccount:${USER_B_SA}:admin gs://${BUCKET_B}
Dataprocクラスタの作成
-
クラスタ作成
--scopesについては公式ガイドの以下記載に従ってhttps://www.googleapis.com/auth/iamを指定することにします。クラスタ
--scopesには少なくともhttps://www.googleapis.com/auth/iamが含まれている必要があります。これは、クラスタ サービス アカウントが権限借用を実行するために必要なものです。また、
--image-versionはブログ記事では1.5-debian10ですが、最新のものを指定します。CLUSTER_NAME=test-cluster REGION=asia-northeast1 gcloud dataproc clusters create ${CLUSTER_NAME} \ --region ${REGION} \ --image-version=2.0-debian10 \ --scopes=https://www.googleapis.com/auth/iam \ --service-account=${VM_SA} \ --properties="^#^dataproc:dataproc.cooperative.multi-tenancy.user.mapping=${USER_A}:${USER_A_SA},${USER_B}:${USER_B_SA}" -
ジョブの送信のため、実行するためクラスタのステージングバケットへのアクセス権が必要であるため、ユーザーBをシミュレートするサービスアカウントに付与2
configBucket=$(gcloud dataproc clusters describe ${CLUSTER_NAME} --region ${REGION} \ --format="value(config.configBucket)") gsutil iam ch serviceAccount:${USER_B}:admin gs://${configBucket} -
SparkとMapReduceの履歴ファイルをクラスタの一時バケットに送信するための権限を、ユーザーA用のサービスアカウントおよびユーザーB用のサービスアカウントに付与3
tempBucket=$(gcloud dataproc clusters describe ${CLUSTER_NAME} --region ${REGION} \ --format="value(config.tempBucket)") gsutil iam ch serviceAccount:${USER_A_SA}:admin gs://${tempBucket} gsutil iam ch serviceAccount:${USER_B_SA}:admin gs://${tempBucket}
ジョブの実行
以下の順でクラスターにジョブを送信するユーザーとアクセスするバケットの組み合わせを変えてSparkのサンプルプログラム「JavaWordCount」を実行してみます。これは、入力ファイルに出現した各単語について、出現回数をカウントするプログラムです。
-
ユーザーAとして
${BUCKET_A}のファイルに対して「JavaWordCount」を実行gcloud config set account ${USER_A} gcloud dataproc jobs submit spark --region=${REGION} --cluster=${CLUSTER_NAME} \ --class=org.apache.spark.examples.JavaWordCount \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar -- gs://${BUCKET_A}/file以下の出力が確認でき、正常に
${BUCKET_A}にアクセスできていることが分かります。is: 1 a: 1 simple: 1 This: 1 file: 1 -
ユーザーAとして
${BUCKET_B}のファイルに対して「JavaWordCount」を実行gcloud dataproc jobs submit spark --region=${REGION} --cluster=${CLUSTER_NAME} \ --class=org.apache.spark.examples.JavaWordCount \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar -- gs://${BUCKET_B}/file以下のようなエラーメッセージが出力され、バケットBへのアクセス権が無くてエラーとなっていることが分かります。
GET https://storage.googleapis.com/storage/v1/b/<バケットBのバケット名>/o/file?fields=bucket,name,timeCreated,updated,generation,metageneration,size,contentType,contentEncoding,md5Hash,crc32c,metadata { "code" : 403, "errors" : [ { "domain" : "global", "message" : "user-a-service-account@<プロジェクトID>.iam.gserviceaccount.com does not have storage.objects.get access to the Google Cloud Storage object.", "reason" : "forbidden" } ], "message" : "user-a-service-account@<プロジェクトID>.iam.gserviceaccount.com does not have storage.objects.get access to the Google Cloud Storage object." } -
ユーザーBとして
${BUCKET_A}のファイルに対して「JavaWordCount」を実行gcloud config set account ${USER_B} gcloud dataproc jobs submit spark --region=${REGION} --cluster=${CLUSTER_NAME} \ --class=org.apache.spark.examples.JavaWordCount \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar -- gs://${BUCKET_A}/file以下のようなエラーメッセージが出力され、バケットAへのアクセス権が無くてエラーとなっていることが分かります。
GET https://storage.googleapis.com/storage/v1/b/<バケットAのバケット名>/o/file?fields=bucket,name,timeCreated,updated,generation,metageneration,size,contentType,contentEncoding,md5Hash,crc32c,metadata { "code" : 403, "errors" : [ { "domain" : "global", "message" : "user-b-service-account@<プロジェクトID>.iam.gserviceaccount.com does not have storage.objects.get access to the Google Cloud Storage object.", "reason" : "forbidden" } ], "message" : "user-b-service-account@<プロジェクトID>.iam.gserviceaccount.com does not have storage.objects.get access to the Google Cloud Storage object." } -
ユーザーBとして
${BUCKET_B}のファイルに対して「JavaWordCount」を実行gcloud config set account ${USER_B} gcloud dataproc jobs submit spark --region=${REGION} --cluster=${CLUSTER_NAME} \ --class=org.apache.spark.examples.JavaWordCount \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar -- gs://${BUCKET_B}/file以下の出力が得られ、正常に
${BUCKET_B}にアクセスできていることが分かります。is: 1 User: 1 B: 1 a: 1 This: 1 for: 1 file: 1
以上より、「Dataproc サービスアカウントベースの安全なマルチテナンシー」を使用することによりユーザーAはバケットAのデータのみ使用可能、ユーザーBはバケットBのデータのみ使用可能という要件を満たせることが確認できました。
リソースの削除
最後に、使用したリソースを削除しておきます。
gcloud dataproc clusters delete ${CLUSTER_NAME} --region ${REGION} --quiet
gsutil rm -r gs://${BUCKET_A}
gsutil rm -r gs://${BUCKET_B}
gcloud auth revoke ${USER_B}
gcloud iam service-accounts delete ${USER_B} --quiet
gcloud iam service-accounts delete ${VM_SA} --quiet
gcloud iam service-accounts delete ${USER_A_SA} --quiet
gcloud iam service-accounts delete ${USER_B_SA} --quiet
まとめ
「Dataproc サービスアカウントベースの安全なマルチテナンシー」の機能および、使い方を説明しました。少しややこしいですが、Dataprocできめ細かなアクセス制御を実現したい場合に使ってみてください。
-
ブログ記事には記載されていませんが、公式ガイドのDataproc の権限と IAM の役割において"ユーザーが Storage Object Creator(ストレージ オブジェクト作成者)役割を与えられていない場合またはプロジェクトのステージング バケットへの書き込みアクセス権が付与されていない場合は、アップロードするファイルを含むジョブを送信できません"という記載があるためユーザーBをシミュレートするサービスアカウントに対してステージングバケットの管理者権限を付与しています。なお、ブログ記事では、ステージングバケット(ブログ記事の記載では「構成バケット」)へのアクセス権はユーザー サービス アカウント(本記事で言うところの「ユーザーA用のサービスアカウント」および「ユーザーB用のサービスアカウント」)に付与する必要があると記載されていますが、実験してみたところ、ユーザー サービス アカウントには当該権限が無くても今回試した範囲では正常に動作しました。「Dataproc サービス アカウント ベースの安全なマルチテナンシー」のドキュメントにおいて、configBucketへのアクセス権がユーザー サービス アカウントに対して必要という記載はないので本手順ではユーザー サービス アカウントに対してはステージングバケットへのアクセス権を付与していません。 ↩
-
公式ガイドには記載が無いですが、ブログ記事には"1.5+ のイメージを含む Dataproc クラスタでは、デフォルトで、Spark と MapReduce の履歴ファイルがクラスタに関連付けられた一時バケットに送信されるため、ユーザー サービス アカウントにこのバケットへのアクセスを付与しておくとよいでしょう。"と記載されており、実際に一時バケットのアクセス許可が無い場合は権限エラーが発生しました。 ↩