目標
教師なしデータを使い、word2vecを学習させ、それをEmbedding層としてテキスト分類問題に応用する。
知識
word2vec
単語をベクトル化する。今回はpythonライブラリであるgensimを使用して、実装する。このライブラリは以下の論文を参考にしている。
・Efficient Estimation of Word Representations in Vector Space
・Distributed Representations of Words and Phrases and their Compositionality
転移学習
転移学習とは学習済みのモデルを利用して、新たなモデルを構築する手法である。
今回の場合でいうと、次のようである。
学習済みのモデル→gensimのword2vecモデル
新たなモデル→文書分類モデル
転移学習を利用した文書分類の論文
Convolutional Neural Networks for Sentence Classification
転移学習についての記事
https://qiita.com/icoxfog417/items/48cbf087dd22f1f8c6f4
http://www.yasuhisay.info/entry/2016/12/05/000000
また、転移学習と似たもので事前学習がある。事前学習にはAutoEncoderと制約付きボルツマンマシンがある。転移学習と事前学習の詳しい違いがわからない。
実装
データセット作成
今回は歌の歌詞を歌手ごとに分類することを目的とする。
docs = [text2doc(song['lyric']) for song in songs]
artists = [song['artist_name'] for song in songs]
・text2doc関数ではテキストを分かち書きして、自立語のみを取り出して、リストにして返している。
docs = [['わたし', '犬', 'なる'], ...]
artists = ['星野源', '福山雅治', ...]
学習済みのword2vecモデルの読み込み
from gensim.models import KeyedVectors
model_path = 'path/to/entity_vector.model.bin'
wv_model = KeyedVectors.load_word2vec_format(model_path, binary=True)
index2word = wv_model.wv.index2word
word2index = {word : i for i, word in enumerate(index2word)}
vocab = word2index.keys()
・KeyedVectorsでword2vecモデルを読み込んでいる。
・上のデータをid化する時に、index2wordやword2indexが必要なので、ここで読み込んでおく。
学習データの作成
上のデータはまだテキストが含まれているので、kerasで学習できるようなデータ型に変更する。テキストから数字に変更する際に上で作った辞書によりid化する。
x_bag_of_words = np.zeros((len(docs), len(vocab)))
for i, doc in enumerate(docs):
for word in doc:
if word in vocab:
x_bag_of_words[i][word2index[word]] += 1
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
label_ids = le.fit_transform(artists)
y = np.zeros((len(docs), len(le.classes_)))
for i, label_id in enumerate(label_ids):
y[i][label_id] = 1
・xもyもbag_of_wordsしているだけです。
・LabelEncoder便利
from sklearn.model_selection import train_test_split
x_train , x_test, y_train, y_test = train_test_split(x_bag_of_words, y, test_size=0.2)
最後にtrainデータとtestデータに分けて完成です。
モデル作成
kerasのmodel function APIを利用しています。Sequenceモデルを使わなかったのはmodel function APiの方が自由自在にかけると書いてあったからです。
from keras.layers import Dense, Activation, Input, Flatten
from keras.layers.convolutional import Conv1D
from keras.layers.recurrent import LSTM
from keras.models import Model
inputs = Input(shape=((x_train.shape[1],)))
embed = wv_model.get_keras_embedding(train_embeddings=True)(inputs)
embed = LSTM(100)(embed)
hiddened = Dense(50)(embed)
hiddened = Activation('relu')(hiddened)
pred = Dense(len(le.classes_))(hiddened)
pred = Activation('sigmoid')(pred)
model = Model(inputs=inputs, outputs=pred)
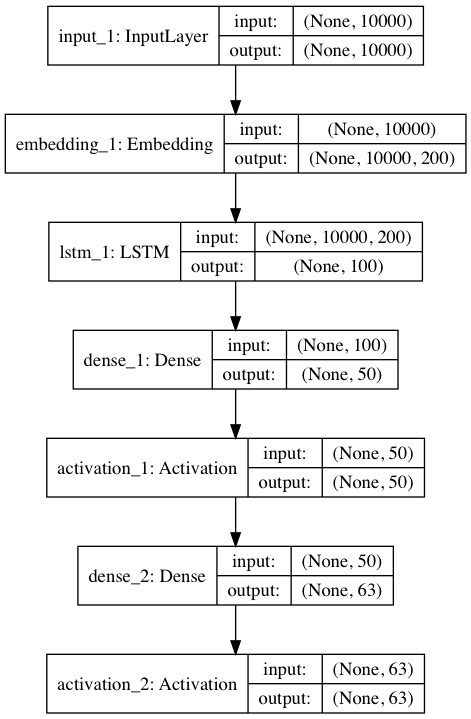
・特筆していうべきところはwv_model.get_keras_embedding()くらいです。これはgensimのword2vecに実装してある関数で、このようにkerasのEmbedding層を書き出します。
・あとはEmbedding層で、入力が二次元だったのが、出力が三次元になっています。ここはLSTMでうまく吸収しています。Conv層で吸収することもできそうですが、やってないです。ここは色々論文を見て、変える価値がありそうです。
学習
model.compile(optimizer='sgd', loss='categorical_crossentropy')
model.fit(x_train, y_train, epochs=1, batch_size=32, verbose=1)
評価
学習中
結果
学習中
疑問・課題
・転移学習と事前学習の違い
・Convolutional Neural Networks for Sentence Classificationを読む