目的
PythonでExcel作業を自動化した際に、openpyxlのsaveメソッドで既存のフォーマットが崩れてしまうことがわかりました。そのため、代替手段を探していました。
解決策
xlsx/xlsmの実態はzipなので、元ファイルを丸ごとコピーしてxl/worksheets/sheetX.xmlの該当セルだけをXMLレベルで書き換える方法に変更。
実践
1. フォーマットしたExcelの用意
B5セルにハイパーリンクを設定しており、セル全体を太字で、Google部分のみ青字&下線ありのフォーマットにしています。
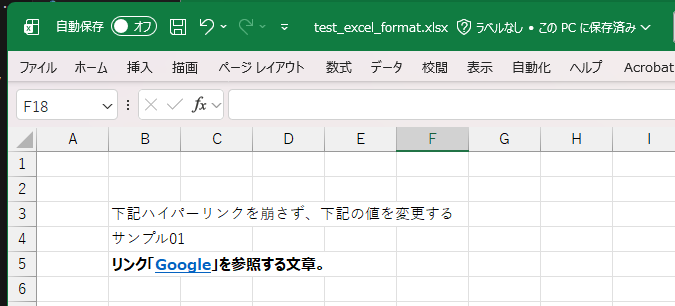
3. openpyxlを使った編集
B4セルのみをopenpyxlを使って書き換えたが、B5セルのフォーマットが崩れている。
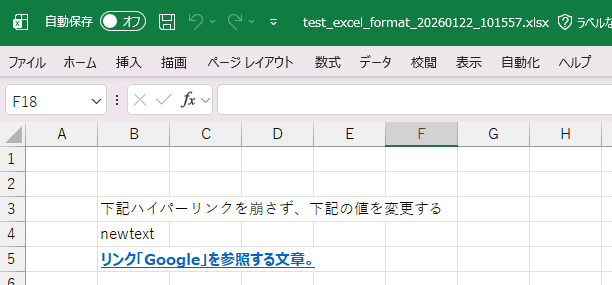
4. zipファイル直接編集
B4を書き換えても、B5のフォーマットは崩れていない。

5. サンプルコード
zipファイル直接編集時のコード(生成AIを使って作成しています)
import os
import re
import shutil
import zipfile
import xml.etree.ElementTree as ET
from pathlib import Path
from datetime import datetime, timedelta, timezone
from typing import Any, Dict, List, Tuple
_XML_NS_MAIN = "http://schemas.openxmlformats.org/spreadsheetml/2006/main"
_XML_NS_R = "http://schemas.openxmlformats.org/officeDocument/2006/relationships"
_XML_NS_RELS = "http://schemas.openxmlformats.org/package/2006/relationships"
_XML_NS_XML = "http://www.w3.org/XML/1998/namespace"
ET.register_namespace("", _XML_NS_MAIN)
ET.register_namespace("r", _XML_NS_R)
_CELL_REF_RE = re.compile(r"^([A-Z]+)([0-9]+)$")
def _timestamped_new_filename(original_path: Path) -> str:
# JST (UTC+9) でタイムスタンプを生成
jst = timezone(timedelta(hours=9), 'JST')
timestamp = datetime.now(jst).strftime('%Y%m%d_%H%M%S')
root, ext = os.path.splitext(original_path.name)
return f"{root}_{timestamp}{ext}"
def _normalize_cell_addr(addr: str) -> str:
a = str(addr).strip().replace("$", "")
if "!" in a:
a = a.split("!", 1)[1]
return a.upper()
def _col_letters_to_index(col_letters: str) -> int:
n = 0
for ch in col_letters:
if not ("A" <= ch <= "Z"):
raise ValueError(f"invalid column letters: {col_letters}")
n = n * 26 + (ord(ch) - ord("A") + 1)
return n
def _parse_cell_ref(addr: str) -> Tuple[str, int, int]:
m = _CELL_REF_RE.match(addr)
if not m:
raise ValueError(f"invalid cell address: {addr}")
col_letters = m.group(1)
row_num = int(m.group(2))
return col_letters, row_num, _col_letters_to_index(col_letters)
def _sanitize_xml_text(s: str) -> str:
# XML 1.0 で禁止される制御文字を除去(タブ/改行/CR は許可)
out_chars = []
for ch in s:
code = ord(ch)
if code in (0x9, 0xA, 0xD) or code >= 0x20:
out_chars.append(ch)
return "".join(out_chars)
def _sheet_xml_path_from_name(z: zipfile.ZipFile, sheet_name: str) -> str:
sheet_name = str(sheet_name).strip()
# workbook.xml から sheet -> r:id を引く
wb_xml = z.read("xl/workbook.xml")
wb_root = ET.fromstring(wb_xml)
rid_attr = f"{{{_XML_NS_R}}}id"
sheets = wb_root.findall(f".//{{{_XML_NS_MAIN}}}sheet")
r_id = None
for sh in sheets:
if (sh.get("name") or "").strip() == sheet_name:
r_id = sh.get(rid_attr)
break
if not r_id:
raise ValueError(f"sheet '{sheet_name}' not found in workbook.xml")
# workbook.xml.rels から rId -> Target を引く
rels_xml = z.read("xl/_rels/workbook.xml.rels")
rels_root = ET.fromstring(rels_xml)
target = None
for rel in rels_root.findall(f".//{{{_XML_NS_RELS}}}Relationship"):
if rel.get("Id") == r_id:
target = rel.get("Target")
break
if not target:
raise ValueError(f"relationship '{r_id}' not found in workbook.xml.rels")
target = target.lstrip("/")
return target if target.startswith("xl/") else ("xl/" + target)
def _insert_before_extlst(cell_elem: ET.Element, new_child: ET.Element) -> None:
ext = cell_elem.find(f"{{{_XML_NS_MAIN}}}extLst")
if ext is None:
cell_elem.append(new_child)
return
children = list(cell_elem)
idx = children.index(ext)
cell_elem.insert(idx, new_child)
def _set_cell_value(cell_elem: ET.Element, value: Any) -> bool:
"""セルに値を設定します。式セルの場合は更新せず False を返します。"""
# 式が入っているセルは壊すリスクがあるので触らない
if cell_elem.find(f"{{{_XML_NS_MAIN}}}f") is not None:
return False
# 既存の値要素を削除
for child in list(cell_elem):
if child.tag in (f"{{{_XML_NS_MAIN}}}v", f"{{{_XML_NS_MAIN}}}is"):
cell_elem.remove(child)
# None/空は値無しにする(書式は保持)
if value is None:
cell_elem.attrib.pop("t", None)
return True
# bool
if isinstance(value, bool):
cell_elem.set("t", "b")
v = ET.Element(f"{{{_XML_NS_MAIN}}}v")
v.text = "1" if value else "0"
_insert_before_extlst(cell_elem, v)
return True
# number (int/float)
if isinstance(value, (int, float)) and not isinstance(value, bool):
# Excel が受け付けない NaN/Inf は文字列扱いにフォールバック
if isinstance(value, float) and (value != value or value in (float("inf"), float("-inf"))):
value = str(value)
else:
cell_elem.attrib.pop("t", None)
v = ET.Element(f"{{{_XML_NS_MAIN}}}v")
v.text = str(value)
_insert_before_extlst(cell_elem, v)
return True
# その他は文字列(inlineStr)で書く
cell_elem.set("t", "inlineStr")
is_elem = ET.Element(f"{{{_XML_NS_MAIN}}}is")
t = ET.SubElement(is_elem, f"{{{_XML_NS_MAIN}}}t")
text = _sanitize_xml_text(str(value))
t.text = text
# 先頭/末尾の空白を保持する必要がある場合は xml:space="preserve"
if text != text.strip() or "\n" in text or "\t" in text:
t.set(f"{{{_XML_NS_XML}}}space", "preserve")
_insert_before_extlst(cell_elem, is_elem)
return True
def _patch_sheet_xml(sheet_bytes: bytes, updates: Dict[str, Any]) -> Tuple[bytes, List[str]]:
"""sheet XML のうち sheetData(セル値)だけを更新して bytes を返します。
重要: 余計な差分を避けるため、worksheet 全体を再シリアライズせず、
元 XML 文字列の <sheetData>...</sheetData> 内部だけ差し替えます。
これにより名前空間宣言や mc:Ignorable などを壊しにくくします。
"""
root = ET.fromstring(sheet_bytes)
sheet_data = root.find(f".//{{{_XML_NS_MAIN}}}sheetData")
if sheet_data is None:
raise ValueError("sheetData not found")
missing: List[str] = []
skipped_formula: List[str] = []
for raw_addr, val in updates.items():
addr = _normalize_cell_addr(raw_addr)
_, row_num, _ = _parse_cell_ref(addr)
row_elem = None
for r in sheet_data.findall(f"{{{_XML_NS_MAIN}}}row"):
if r.get("r") == str(row_num):
row_elem = r
break
if row_elem is None:
missing.append(addr)
continue
cell_elem = None
for c in row_elem.findall(f"{{{_XML_NS_MAIN}}}c"):
if c.get("r") == addr:
cell_elem = c
break
if cell_elem is None:
missing.append(addr)
continue
ok = _set_cell_value(cell_elem, val)
if not ok:
skipped_formula.append(addr)
if missing:
raise ValueError(f"target cell(s) not found in sheet XML: {missing}")
# 元 XML を文字列として扱い、sheetData の「中身だけ」置換する
try:
xml_text = sheet_bytes.decode("utf-8")
encoding = "utf-8"
except UnicodeDecodeError:
# 念のため(ほぼ UTF-8 のはず)
xml_text = sheet_bytes.decode("utf-8-sig")
encoding = "utf-8"
start = xml_text.find("<sheetData")
if start < 0:
raise ValueError("sheetData tag not found in raw XML")
start_tag_end = xml_text.find(">", start)
if start_tag_end < 0:
raise ValueError("sheetData start tag not closed")
end_tag_start = xml_text.find("</sheetData>", start_tag_end)
if end_tag_start < 0:
raise ValueError("sheetData end tag not found")
inner = (sheet_data.text or "") + "".join(
ET.tostring(child, encoding="unicode") for child in list(sheet_data)
)
new_text = xml_text[: start_tag_end + 1] + inner + xml_text[end_tag_start:]
return new_text.encode(encoding), skipped_formula
def _save_as_new_patching_sheet(original_path: Path, sheet_name: str, updates: Dict[str, Any]) -> Tuple[str, List[str]]:
"""元ファイルをコピーし、指定シートの指定セルだけを更新して別名保存します。"""
new_filename = _timestamped_new_filename(original_path)
new_path = original_path.parent / new_filename
if not updates:
shutil.copyfile(original_path, new_path)
return new_filename, []
with zipfile.ZipFile(original_path, "r") as zin:
sheet_xml_path = _sheet_xml_path_from_name(zin, sheet_name)
sheet_bytes = zin.read(sheet_xml_path)
patched_sheet_bytes, skipped_formula = _patch_sheet_xml(sheet_bytes, updates)
with zipfile.ZipFile(new_path, "w") as zout:
zout.comment = zin.comment
for item in zin.infolist():
data = zin.read(item.filename)
if item.filename == sheet_xml_path:
data = patched_sheet_bytes
zout.writestr(item, data)
return new_filename, skipped_formula
def _parse_value(s: str) -> Any:
"""文字列から適切な型に変換"""
if s.lower() == "true":
return True
if s.lower() == "false":
return False
if s.lower() in ("none", "null", ""):
return None
try:
if "." in s:
return float(s)
return int(s)
except ValueError:
return s
if __name__ == "__main__":
import sys
if len(sys.argv) < 3:
print("Usage: python edit_excel.py <file> <sheet> [cell value ...]")
print("Example: python edit_excel.py sample.xlsx Sheet1 A1 Hello B2 123 C3 true")
sys.exit(1)
file_path = Path(sys.argv[1])
sheet_name = sys.argv[2]
updates = {}
for i in range(3, len(sys.argv), 2):
if i + 1 < len(sys.argv):
updates[sys.argv[i]] = _parse_value(sys.argv[i + 1])
new_file, skipped = _save_as_new_patching_sheet(file_path, sheet_name, updates)
print(f"Created: {new_file}")
if skipped:
print(f"Skipped formula cells: {skipped}")
まとめ
コードが煩雑になってしまいますが、openpyxlでフォーマットが崩れてしまう場合の代替の保存方法を検証することができました。