目的
xlsx や csv 形式で保存した多クラス分類の予測値を pandas で読み込んで ROC 曲線を書くときの備忘録。
あとは、Qiita の記事作成練習も兼ねています。
ROC 曲線について
基本的な話に関しては、本稿では触れません。
ROC 曲線の話については こちら の記事が判りやすいです。
ラベルの形式変更
まずは、データ形式を確認。

- GT は 0, 1, 2 の数値を持っており、各ラベルに対応している。
- C1, C2, C3: 各ラベル C1 = 0.0, C2 = 1.0, C3 = 2.0
- M1, M2, M3: 各モデル
ROC 曲線は 0, 1 のバイナリに変換する必要があるため、
from sklearn.preprocessing import label_binarize
y_test = label_binarize(df.iloc[:, 0], classes=[0,1,2])
sklearn の label_binarize を使い、バイナリ変換します。
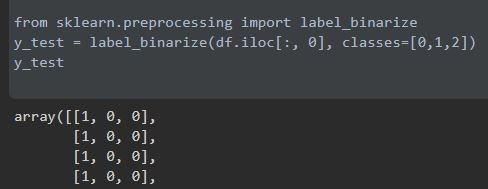
ちょっと長いので、上の部分のみ。
バイナリ変換した結果、C1 = [1, 0, 0], C2 = [0, 1, 0], C3 = [0, 0, 1] になりました。
予測値のリスト化
ラベルをバイナリ化した後は、各モデルの予測値も対応するリストに変換する必要があります。
M1_y_score = []
M2_y_score = []
M3_y_score = []
for i in df.index:
M1_y_score.append(([df.iloc[i, 1], df.iloc[i, 2], df.iloc[i, 3]]))
M2_y_score.append(([df.iloc[i, 4], df.iloc[i, 5], df.iloc[i, 6]]))
M3_y_score.append(([df.iloc[i, 7], df.iloc[i, 8], df.iloc[i, 9]]))
M1_y_score = M1_y_score
M2_y_score = M2_y_score
M3_y_score = M3_y_score
こんな感じで、ループ処理を実行し、予測値を格納しました。
一応この時点で、
from sklearn.metrics import roc_auc_score
auc_m1 = roc_auc_score(y_test, M1_y_score, multi_class="ovo")
print(auc_m1)
と打つと、多クラスの AUC を求めることができます。
引数 multi_class は "ovo" か "ovr" のどちらかを設定しないとエラーを吐くようです。
詳しくは sklearn のドキュメント に記載されています。
FPR, TPR の計算
この部分が少し躓いたところです。
M1_fpr = dict()
M1_tpr = dict()
M1_roc_auc = dict()
M2_fpr = dict()
M2_tpr = dict()
M2_roc_auc = dict()
M3_fpr = dict()
M3_tpr = dict()
M3_roc_auc = dict()
データを格納する空の辞書を作成した後、
n_class = 3
from sklearn.metrics import roc_curve, auc
for i in range(n_classes):
M1_fpr[i], M1_tpr[i], _ = roc_curve(y_test[:, i], M1_y_score[:, i])
M1_roc_auc[i] = auc(M1_fpr[i], M1_tpr[i])
M2_fpr[i], M2_tpr[i], _ = roc_curve(y_test[:, i], M2_y_score[:, i])
M2_roc_auc[i] = auc(M2_fpr[i], M2_tpr[i])
M3_fpr[i], M3_tpr[i], _ = roc_curve(y_test[:, i], M3_y_score[:, i])
M3_roc_auc[i] = auc(M3_fpr[i], M3_tpr[i])
ラベルの数だけループして、各モデルの fpr と tpr を格納するのですが、
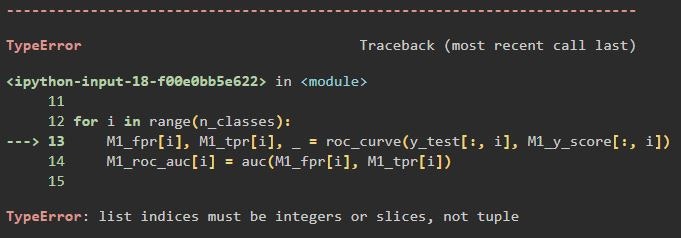
何故かエラーが出てしまう!
予測値を格納する際に、ndarray にしていなかったのが原因でした。
なので、上記のコードを少し変えて…
M1_y_score = np.array(M1_y_score)
M2_y_score = np.array(M2_y_score)
M3_y_score = np.array(M3_y_score)
ndarray 型にすることで、辞書にデータを格納できるようになりました。
あとは、公式ドキュメント通りにコーディングすれば OK!
M1_all_fpr = np.unique(np.concatenate([M1_fpr[i] for i in range(n_classes)]))
M2_all_fpr = np.unique(np.concatenate([M2_fpr[i] for i in range(n_classes)]))
M3_all_fpr = np.unique(np.concatenate([M3_fpr[i] for i in range(n_classes)]))
M1_mean_tpr = np.zeros_like(M1_all_fpr)
M2_mean_tpr = np.zeros_like(M2_all_fpr)
M3_mean_tpr = np.zeros_like(M3_all_fpr)
for i in range(n_classes):
M1_mean_tpr += np.interp(M1_all_fpr, M1_fpr[i], M1_tpr[i])
M2_mean_tpr += np.interp(M2_all_fpr, M2_fpr[i], M2_tpr[i])
M3_mean_tpr += np.interp(M3_all_fpr, M3_fpr[i], M3_tpr[i])
M1_mean_tpr /= n_classes
M2_mean_tpr /= n_classes
M3_mean_tpr /= n_classes
M1_fpr["macro"] = M1_all_fpr
M1_tpr["macro"] = M1_mean_tpr
M1_roc_auc["macro"] = auc(M1_fpr["macro"], M1_tpr["macro"])
M2_fpr["macro"] = M2_all_fpr
M2_tpr["macro"] = M2_mean_tpr
M2_roc_auc["macro"] = auc(M2_fpr["macro"], M2_tpr["macro"])
M3_fpr["macro"] = M3_all_fpr
M3_tpr["macro"] = M3_mean_tpr
M3_roc_auc["macro"] = auc(M3_fpr["macro"], M3_tpr["macro"])
ROC 曲線の描写
ここまでできたら後は、matplotlib を使ってグラフ化するだけです。
import matplotlib.pyplot as plt
from matplotlib import cm
lw=1
colors = [cm.gist_ncar(190), cm.gist_ncar(30), cm.gist_ncar(10)]
sns.color_palette(colors)
sns.set_palette(colors, desat=1.0)
plt.figure(figsize=(6, 6))
plt.plot(M1_fpr["macro"], M1_tpr["macro"],
label='M1',
color=colors[0],
linestyle='-',
linewidth=2)
plt.plot(M2_fpr["macro"], M2_tpr["macro"],
label='M2',
color=colors[1],
linestyle='-',
linewidth=2)
plt.plot(M3_fpr["macro"], M3_tpr["macro"],
label='M3',
color=colors[2],
linestyle='-',
linewidth=2)
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend(loc="lower right")
plt.show()
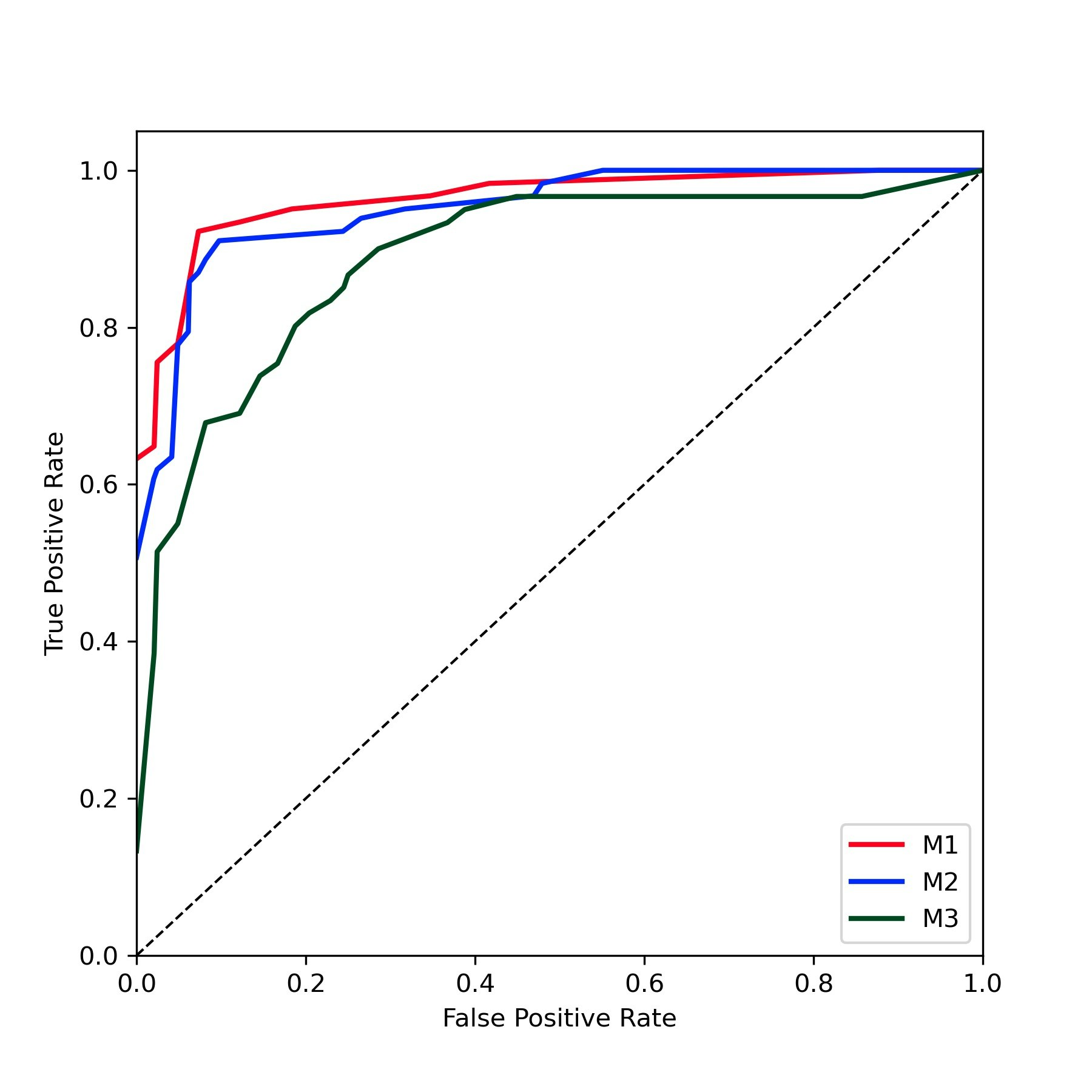
マクロ平均を使った多クラス分類の ROC 曲線が描写できました。