初めまして、フルカイテンでフロントエンドを担当しておりますヒロシと申します。
テックブログを始めて2つ目の記事を書かせていただくことになりました。
フロントと言いつつ、今回はAWSの記事になります...!
思いのほかCognitoのログイン履歴をLambdaでCSV出力する情報が多くなかった?ので、今回記事にしてみようと思いました!
背景・動機
弊社ではサービス導入後、一部お客様で日常業務への利用定着や効果的な活用が進まない問題が発生しました。しかし、当初は定量的な指標がなかったため、各お客様がどの程度利用しているかはカスタマーサクセスチームの感覚ベースとなっていました。
利用定着が進まないまま放置しているとチャーンリスクが増加します。
そこでユーザーの活用状況を知る方法の一つとしてCognitoで保有しているユーザーのログイン履歴を参照することにしました。
本記事の主な対象
Cognitoを業務利用している人
やること
お客様の多くは主に1週間単位で売上を追い、そのサイクルに沿って弊社のシステムを使用するため、
・直近1週間の全ユーザーのログイン履歴
・各ユーザー単位(Email単位)でのログイン回数の出力
を出力することにしました。
大まかな流れは以下です。
- Cognitoの設定(アドバンスドキュリティ設定)
- S3の設定
- Lambdaの設定
- lambda_functionに実装
- ファイルの確認
- EventBridgeの設定
1. Cognitoの設定(アドバンスドキュリティ設定)
- 「高度なセキュリティ」を有効化します。

- 「高度なセキュリティ編集」でフル機能を選択します。(本設定は有料なのでそこは各自でご判断ください)
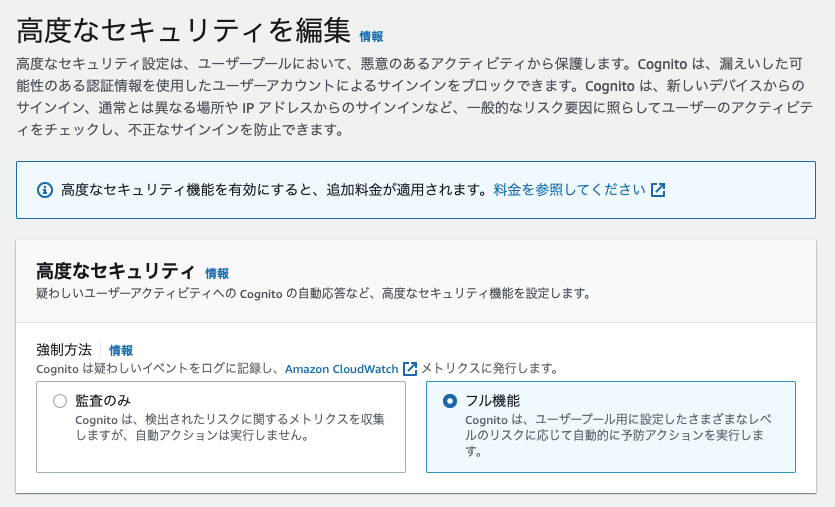
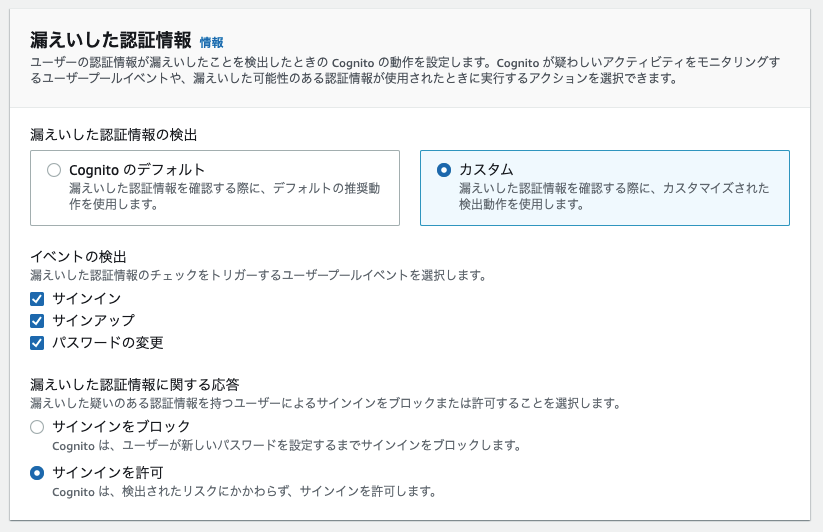
- 「漏えいした認証情報」を設定(デフォルトかカスタムを選択)
- 「アダプティブ認証」を設定(デフォルトorカスタムは任意)
- 「アダプティブ認証メッセージ」のSES設定
- SES、Cognitoメールのどちらを利用するかはメッセージタブの「Eメール」から変更できます。ただし、Cognitoメールは1日50通までという制限があるのでSESが推奨されています。
設定後、任意のユーザーでログインやPW変更を行うと下記のようにユーザーページで履歴が表示されます。
この情報をCSVに出力します。

3. S3の設定
- S3に出力先となるバケットを作成します(仮に
login_history_outputとします) - 作成したバケットの中に、全履歴を格納する
historyディレクトリと、直近1週間のログイン回数を格納するper_week_login_frequencyディレクトリを作成します(もちろん命名は任意です。後述のソースと一致すればOKです)
2. Lambdaの設定
-
関数を作成します。関数名は任意で、今回言語はpythonを選択します。

-
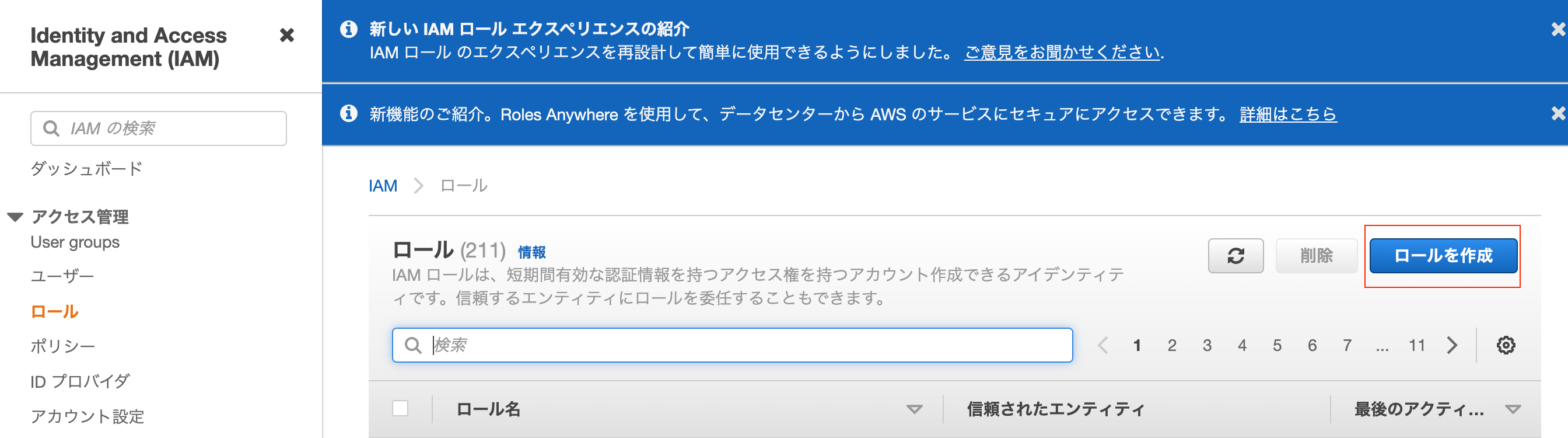
次に作成したLambda関数からS3へファイルを出力できるように、ロールを作成します(既に設定したいロールがあれば不要です)
-
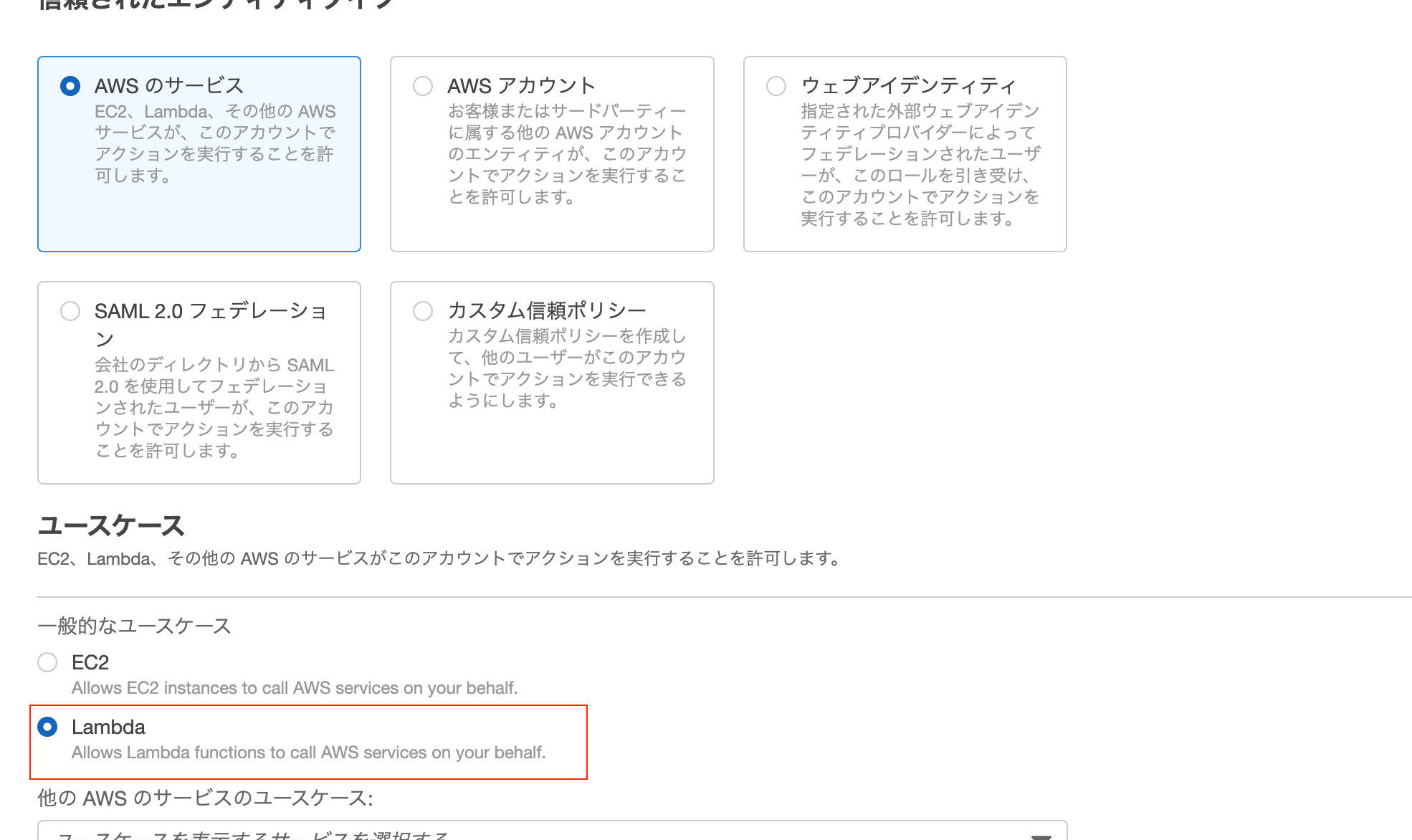
ユースケースはLambdaを選択します
-
アタッチしたいポリシーがあればそれを選択。なければポリシーを作成します。
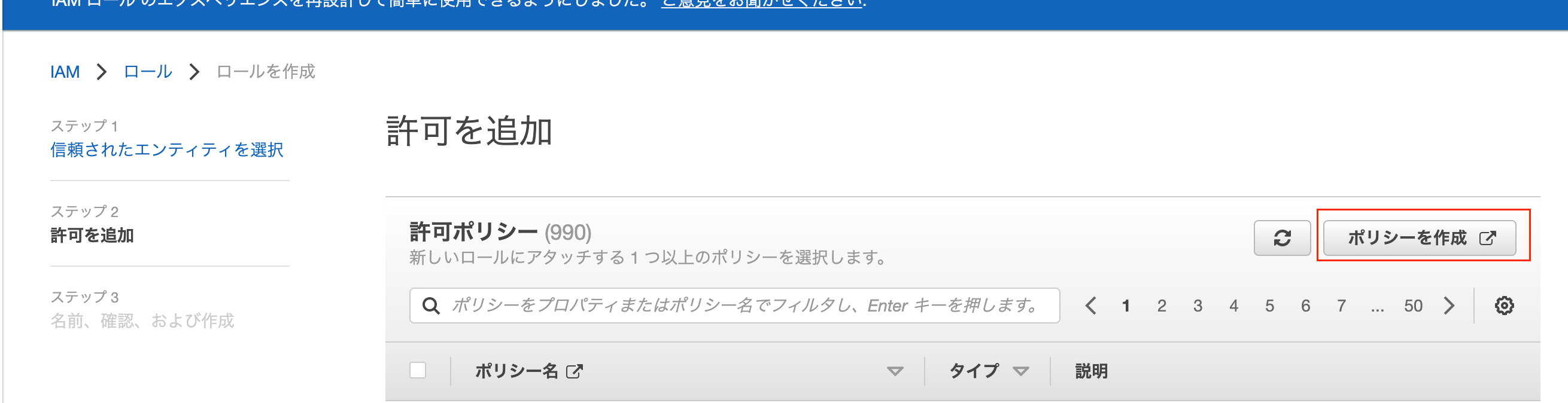
-
ポリシーを新規作成する場合は、サービスにS3を選択し、アクセスレベルにListBucketとPutObjectを選択します。(ここはS3に対してやりたい操作に合わせて選択してください)
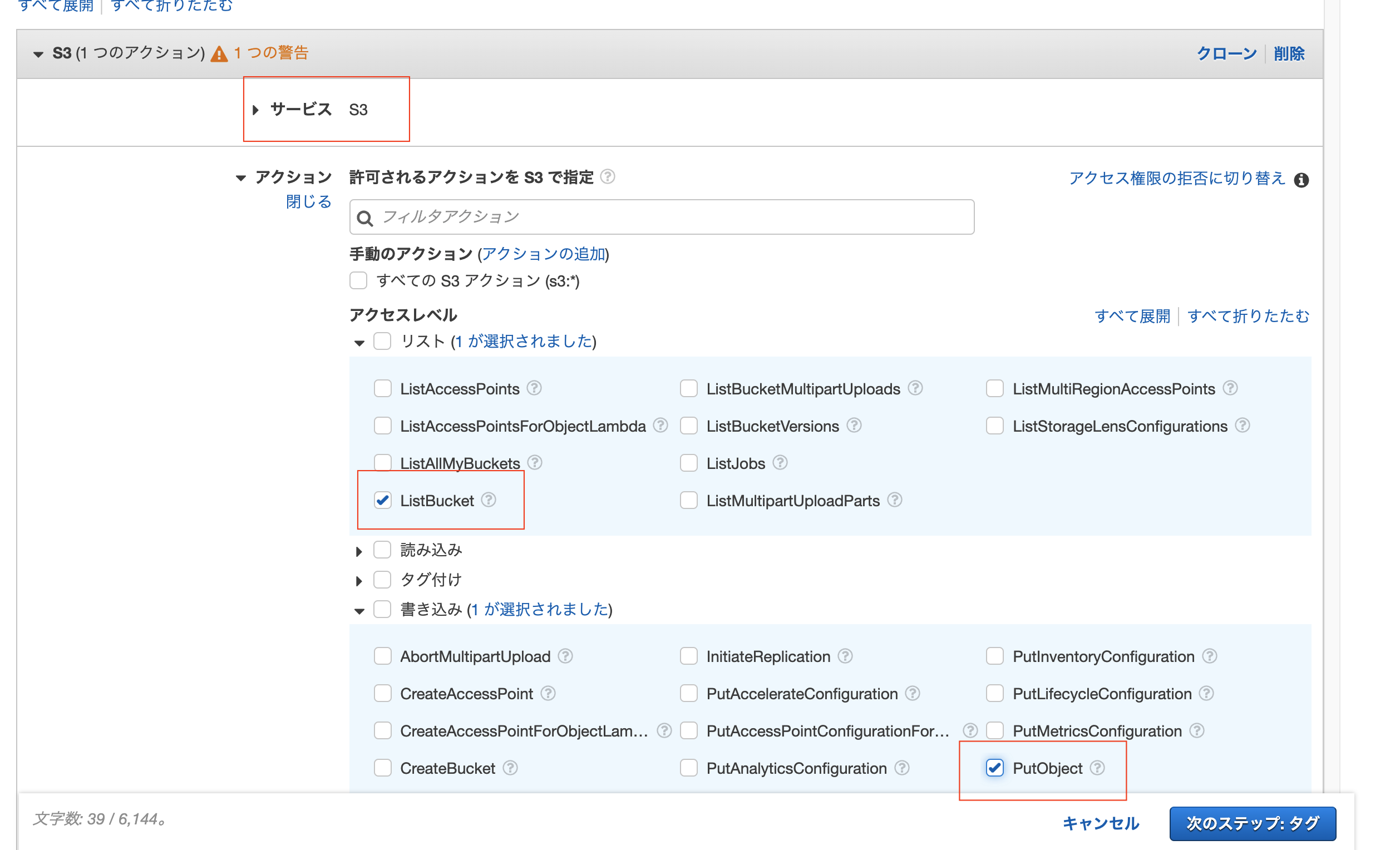
-
ポリシーができたら、2で作成したロールを選択して、下記からアタッチします。
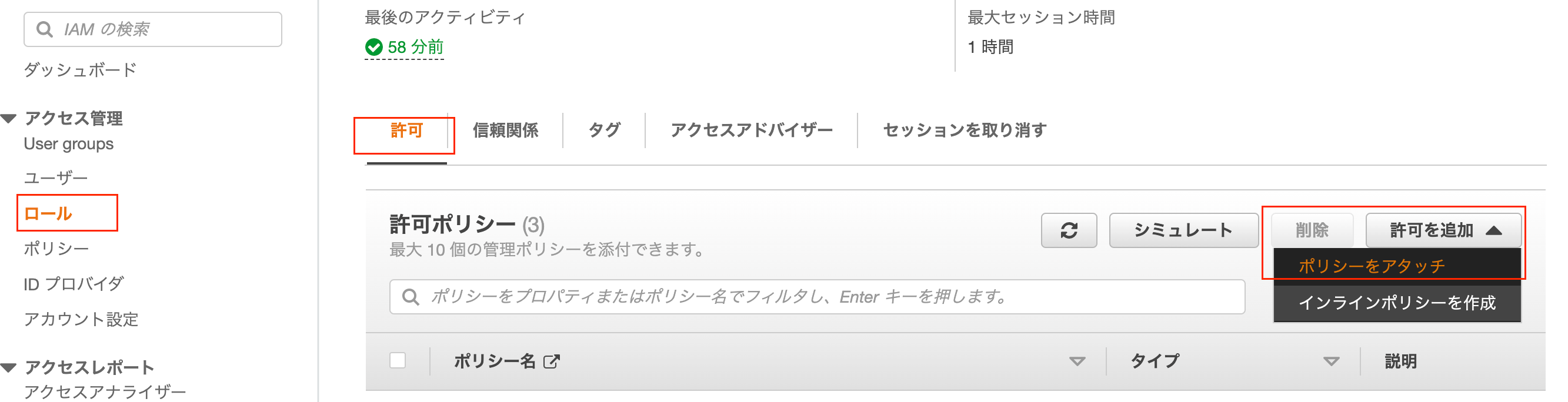
-
ロールの作成ができたらLambdaに戻って、関数に適用します。
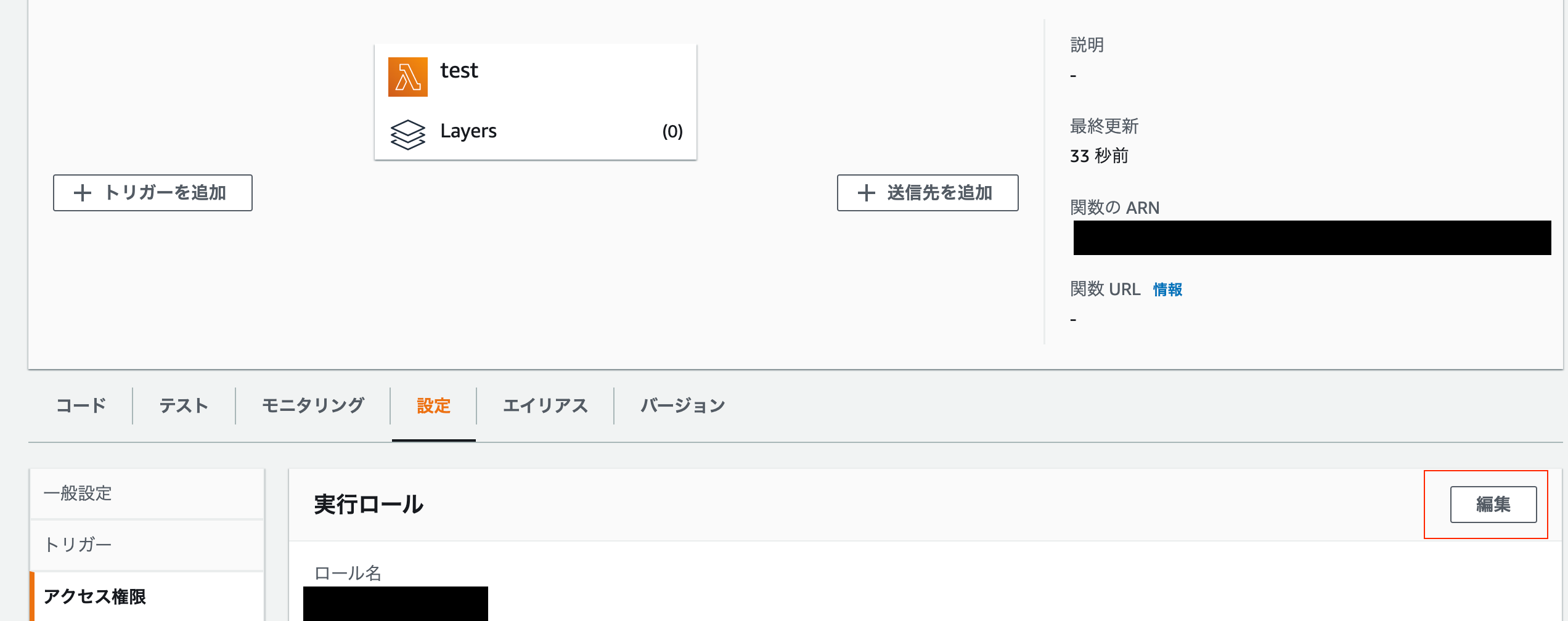
4. lambda_functionに実装
下記ソースコードをlambda_functionに実装し、ユーザープールや命名など必要に応じて変更して下さい。
変更したら[Deploy]、実行は[Test]です。
実行後はS3の該当バケットにファイルが出力されるのでご確認下さい。
※ユーザープールIDは書き換えて下さい
※get_dates()で取得期間を設定していますので、取得したい期間に合わせて書き換えて下さい
※admin_list_user_auth_eventsで取得したい項目は公式ドキュメントを参考にして下さい
import json
import boto3
import collections
from datetime import datetime, timedelta, timezone
cognito_client = boto3.client('cognito-idp')
s3 = boto3.resource('s3')
JST = timezone(timedelta(hours=9), "JST")
PROD_USER_POOL_ID = 'xxxxxxxxxxxxxxxxxxxxx'
BUCKET_NAME='login_history_output'
# 全履歴
HISTORY_DIR='history/'
# 1週間単位のログイン頻度
PER_WEEK_DIR='per_week_login_frequency/'
def lambda_handler(event, context):
# ユーザープール内のユーザー一覧取得
users_data = get_users_data()
# イベント全取得
auth_evs = get_auth_events_per_user(users_data)
# エラーチェック
if(len(auth_evs) <= 0):
print('イベントを取得出来ていません')
print(auth_evs)
return
# 「今日の日付」「1週間前の日付」を取得 ※取得したい期間に合わせて書き換えて下さい
week_ago_jst, yesterday_jst = get_dates()
#CSVヘッダーを最初に
csv_header_keys = auth_evs[0].keys()
csv_header = ",".join(list(csv_header_keys)) + str('\n')
csv = ""
# 直近1週間の履歴を取得
login_freq_list = []
login_freq_obj = {}
for ev in auth_evs:
if ev != {}:
isPastOneWeek = week_ago_jst <= ev['CreationDate'] and ev['CreationDate'] <= yesterday_jst
if(isPastOneWeek):
# ログイン履歴一覧作成
csv_header + '\n'.join(ev)
if 'Username' in ev:
csv=csv+ev['Username']+str(',')
if 'Website' in ev:
csv=csv+ev['Website']+str(',')
if 'Email' in ev:
csv=csv+ev['Email']+str(',')
if 'EventType' in ev:
csv=csv+ev['EventType']+str(',')
if 'CreationDate' in ev:
csv=csv+ev['CreationDate'].strftime('%Y-%m-%d %H:%M:%S')+str(',')
if 'ChallengeName' in ev:
csv=csv+ev['ChallengeName']+str(',')
if 'ChallengeResponse' in ev:
csv=csv+ev['ChallengeResponse']+str(',')
if 'IpAddress' in ev:
csv=csv+ev['IpAddress']+str(',')
if 'DeviceName' in ev:
csv=csv+ev['DeviceName'].replace(',', '', 5)+str(',')
if 'City' in ev:
csv=csv+ev['City'].replace(',', ' ', 5)+str(',')
if 'Country' in ev:
csv=csv+ev['Country']+str('\n')
# 直近1週間のログイン頻度作成
login_freq_list.append(ev['Website'] + ':' + ev['Email'])
csv_file = csv_header + csv
# S3にアップロード
current_time = datetime.now(JST).strftime('%Y%m%d%H%M%S')
# 全一覧格納
file_name = current_time + '_login_history.csv'
obj1 = s3.Bucket(BUCKET_NAME).Object(HISTORY_DIR + file_name)
r = obj1.put(Body = json.dumps(csv_file), ContentType='text/csv')
# 直近1週間のログイン頻度格納
file_name = current_time + '_per_week_login_frequency.csv'
obj1 = s3.Bucket(BUCKET_NAME).Object(PER_WEEK_DIR + file_name)
login_freq = collections.Counter(login_freq_list)
r = obj1.put(Body = json.dumps(login_freq), ContentType='text/csv')
return {
'statusCode': 200,
'body': json.dumps({"output": "succeed"})
}
# ユーザープール内のユーザー一覧取得
def get_users_data():
# 1週目(1回のリクエストで取得できる上限はMAX60件)
res = cognito_client.list_users(
UserPoolId=STG_USER_POOL_ID
)
users_data = []
append_user_dict(res, users_data)
# 2週目以降はPaginationTokenで取得してusers_dataに追加
while True:
# PaginationTokenがレスポンスに含まれなくなったらループ終了
if 'PaginationToken' not in res:
break
# 前回のレスポンスに含まれるPaginationTokenを渡す
res = cognito_client.list_users(
UserPoolId=STG_USER_POOL_ID,
PaginationToken=res['PaginationToken']
)
append_user_dict(res, users_data)
return users_data
# ユーザー名を辞書型で取得しlistに追加
def append_user_dict(res, users_data):
for user in res['Users']:
user_props = {}
# 正常な情報数を持つユーザーのみ取得対象
if (len(user['Attributes']) >= 4):
user_props['Username'] = user['Username']
user_props['Website'] = user['Attributes'][1]['Value']
user_props['Email'] = user['Attributes'][3]['Value']
users_data.append(user_props)
# ユーザー毎のイベント取得
def get_auth_events_per_user(users_data):
auth_evs = []
for user in users_data:
if('Username' in user):
# 1週目(1回のリクエストで取得できる上限はMAX60件)
auth_event = cognito_client.admin_list_user_auth_events(
UserPoolId=PROD_USER_POOL_ID,
Username=user['Username']
)
append_event_dict(auth_event, auth_evs, user)
if (len(auth_event['AuthEvents']) > 0):
# 2週目以降はNextTokenで取得
while True:
# NextTokenがレスポンスに含まれなくなったらループ終了
if 'NextToken' not in auth_event:
break
# 前回のレスポンスに含まれるNextTokenを渡す
auth_event = cognito_client.admin_list_user_auth_events(
UserPoolId=PROD_USER_POOL_ID,
Username=user['Username'],
NextToken=auth_event['NextToken']
)
append_event_dict(auth_event, auth_evs, user)
return auth_evs
# イベントを辞書型で取得しlistに追加
def append_event_dict(auth_event, auth_evs, user):
if (len(auth_event['AuthEvents']) > 0):
for event in auth_event['AuthEvents']:
user_auth_ev = {}
user_auth_ev['Username']=user['Username']
user_auth_ev['Website']=user['Website']
user_auth_ev['Email']=user['Email']
if 'EventType' in event:
user_auth_ev['EventType']=event['EventType']
if 'CreationDate' in event:
user_auth_ev['CreationDate']=event['CreationDate']
challange_res = {}
if (len(event['ChallengeResponses']) > 0):
challange_res = event['ChallengeResponses'][0]
if 'ChallengeName' in challange_res:
user_auth_ev['ChallengeName']=challange_res['ChallengeName']
if 'ChallengeResponse' in challange_res:
user_auth_ev['ChallengeResponse']=challange_res['ChallengeResponse']
ev_context_data = event['EventContextData']
if 'IpAddress' in ev_context_data:
user_auth_ev['IpAddress']=ev_context_data['IpAddress']
if 'DeviceName' in ev_context_data:
user_auth_ev['DeviceName']=ev_context_data['DeviceName']
if 'City' in ev_context_data:
user_auth_ev['City']=ev_context_data['City']
if 'Country' in ev_context_data:
user_auth_ev['Country']=ev_context_data['Country']
auth_evs.append(user_auth_ev)
# 集計したい期間に合わせて変更
def get_dates():
now = datetime.now(JST)
week_ago = now + timedelta(days=-7)
week_ago_jst = datetime(week_ago.year, week_ago.month, week_ago.day, 0, 0, 0, 0, JST)
yesterday = now + timedelta(days=-1)
yesterday_jst = datetime(yesterday.year, yesterday.month, yesterday.day, 23, 59, 59, 0, JST)
return week_ago_jst, yesterday_jst
5. ファイル
下記のようにCSV出力されます。改行コードを取るなどして、ちょっと整えてから活用してます。
- 1つめ(シンプルに該当期間の各ユーザー毎のログイン履歴を出力)
"Username,Website,Email,EventType,CreationDate,ChallengeName,ChallengeResponse,IpAddress,DeviceName,City,Country\n00000000-0000-0000-0000-000000000000,hoge,hoge@hoge.com,SignIn,2022-07-08 01:04:28,Password,Success,XXXX:XXXX:XXXX:XXXX:XXXX:XXXX:XXXX:XXXX,Chrome 103 Mac OS X 10.15.7,Hirakata,.....
- 2つめ(Email: ログイン回数)
{"hoge:hoge@hoge:hoge.com": 8, "fuga:fuga@fuga.com": 4, "foo:foo@foo.com": 1}
6. EventBridgeで定期実行
- ファイルに無事履歴が出力されていたら定期実行の設定をします
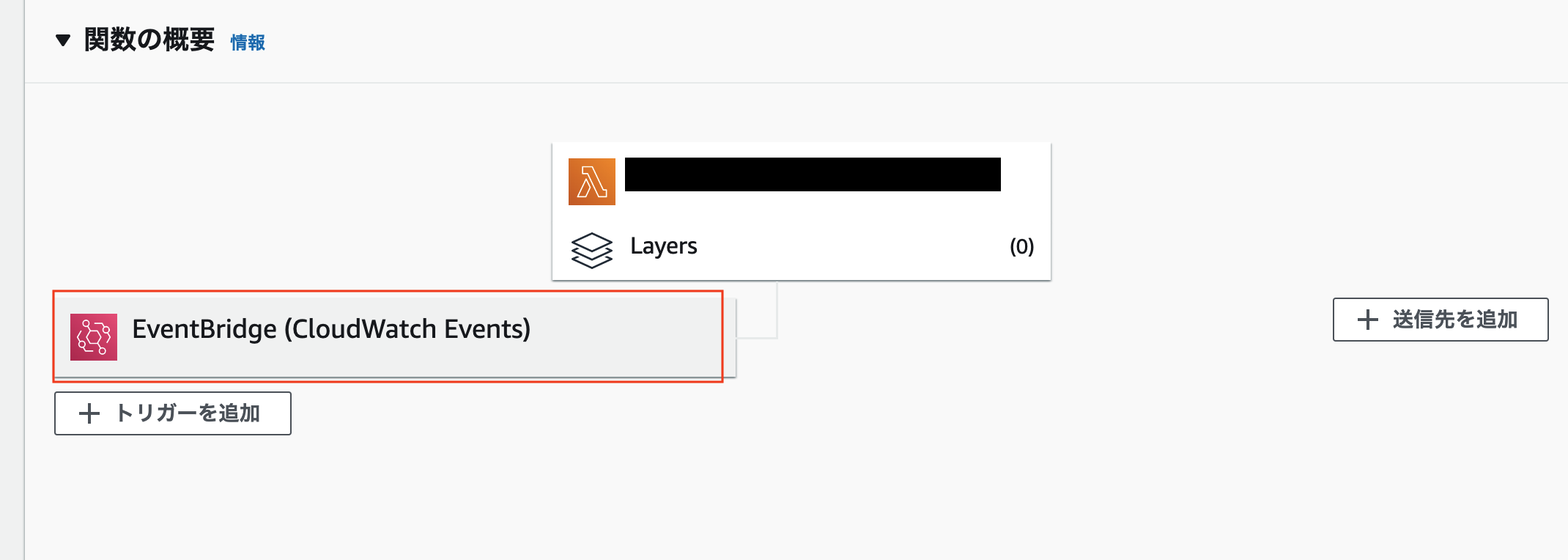
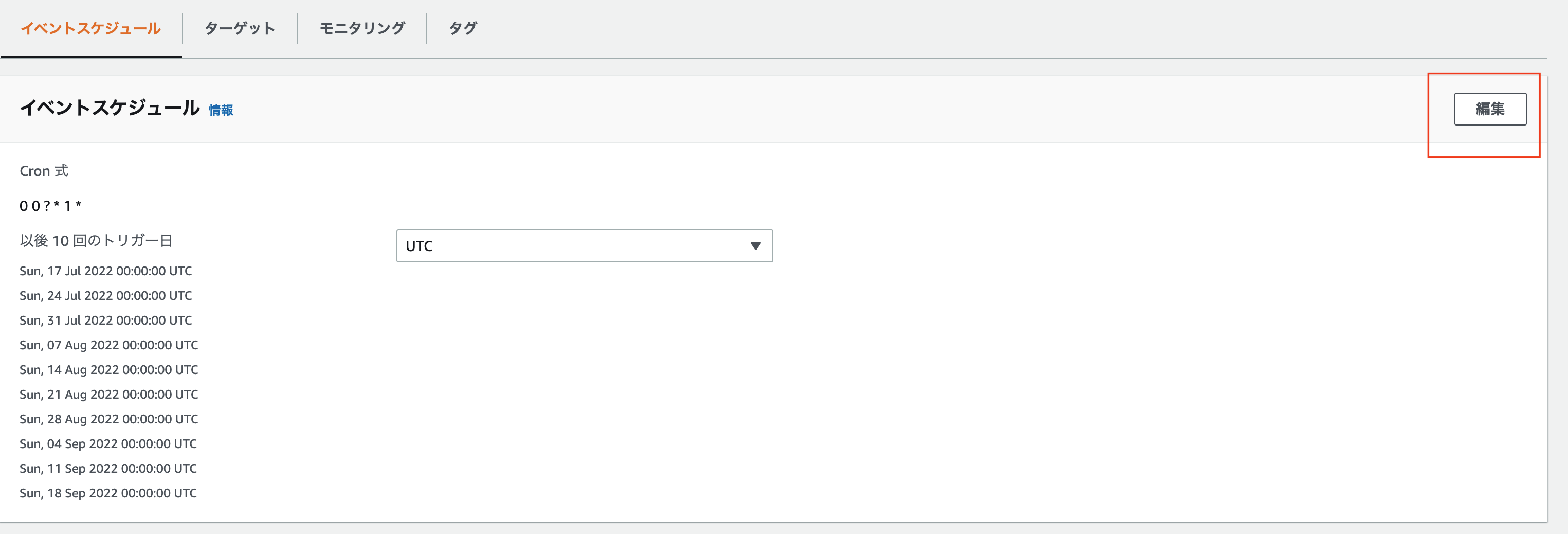
- 以下は毎週日曜日のAM9:00(JST)に出力する設定です
公式ドキュメントにcronの設定方法書いていますが、最初に上手くいかなかった点は下記でした。
- cron式の日フィールドと曜日フィールドを同時に指定することができない。一方のフィールドに値または * (アスタリスク) を指定する場合、もう一方のフィールドで ? (疑問符) を使用する必要がある。
- 日曜日は0ではなく1はじまり。(つまり月曜は2、火曜は3...)
結果
活用状況を定量的に参照することで、
・利用状況を俯瞰できるようになった
・定着が芳しくないお客様には弊社から積極的にお声がけをする
・一部のお客様しか利用がない場合は、それ以外の利用が少ないお客様に向けた提案を考える
など、弊社側から先んじてアクションを起こせるようになり、お客様の痒い部分に手を伸ばせるきっかけを少しは作れたかな?という感じです。
終わりに
本記事の内容以外にも「FULL KAITEN V3」の開発で工夫した点、改善点、苦労した部分などまだまだあります。
また、Rust、Athena、PySparkでビッグデータ処理に関わりたいエンジニアも募集しています。