はじめに
この記事はSRA Advent Calendar 2018 の23日目の記事です。
やったこと
下準備
前編記事のとおりです。
128x128サイズ(足りない部分は黒でパディング済み)のペンギン6種(エンペラーペンギン、キングペンギン、アデリーペンギン、ヒゲペンギン、ジェンツーペンギン、イワトビペンギン)各500枚の写真を用意しています。これをトレーニングデータ、検証用データにして、Keras(backendはtensorflow)で学習させます。
さらに、各60枚のテストデータで、作成した学習モデルの正解率を計算します。
ディレクトリ構成は下記の通り
|
|- penguin_classfications_class.ipynb : jupyter notebook (4層CNN)
|- penguin_classfications_class_imagenetbased.ipynb : jupyter notebook(VGG16 ImageNet based)
|- train (train+validation用画像 各500枚)
|- adelie_penguin : アデリーペンギン
|- chinstrap_penguin : ヒゲペンギン
|- emperor_penguin : エンペラーペンギン
|- gentoo_penguin : ジェンツーペンギン
|- king_penguin : キングペンギン
|- rockhopper_penguin : イワトビペンギン
|- test (test用画像 各60枚)
|- adelie_penguin
|- chinstrap_penguin
|- emperor_penguin
|- gentoo_penguin
|- king_penguin
|- rockhopper_penguin
コード(jupyter notebook)はgithubにあげました。
作成したモデル
今回のモデル作成はおもに「PythonとKerasによるディープラーニング」 の第5章を参考にしています。
あと、コード実装では 小さなデータセットで良い分類器を学習させるとき を参考にさせていただきました。
データの読み込みはImageDataGenerator.flow_from_directory() を使っています。ImageDataGeneratorのvalidation_splitを指定することで、トレーニングデータと検証用データにわけています。validation_split=0.2としました。
flow_from_directoryメソッドでsubset='training' を指定するとトレーニング用のサブセット、subset='validation'を指定すると検証用サブセットがとれるようなので、これを使いました。本家のドキュメントには書いてあるんですが 、 日本語版のドキュメントに入ってないのでわりと新しいオプションなんでしょうか。
4層CNN、データ拡張なし
以下のような単純な畳み込み層とプーリング層が交互に4層重ねたネットワークを使いました。
def network(input_shape, num_classes):
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=input_shape))
model.add(layers.MaxPooling2D(2, 2))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D(2, 2))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D(2, 2))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D(2, 2))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(num_classes, activation='softmax'))
return model
手始めにデータ拡張なしで試したところ、
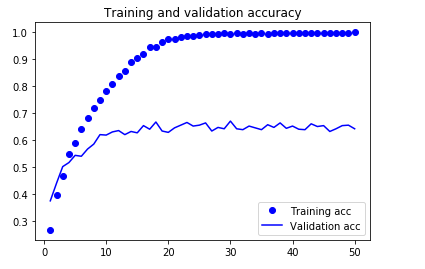
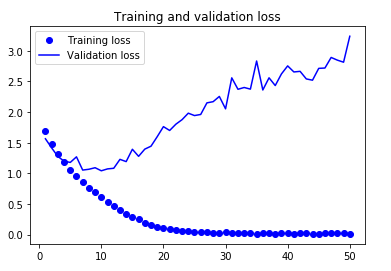
15epoch くらいでもう過学習に突入しているようです。validation accも63くらい。
テスト用検証データで確認したところ、正解率は63.6%でした。
CAMで可視化
CAM(Class Activation Map)で4層目の畳み込み層出力特徴マップと入力画像を重ねて、画像のどこが判断の決め手になったのかを確認します。
これはキングペンギンなのですが、エンペラーペンギンと判定しています。しかも特徴として強く効いているのが、サイズ合わせの上下のパディング部分。これはおかしい。

こちらはキングペンギンをキングペンギンと判定しています。正解はしていますが、どうも強く効いた部分がペンギン本体からはみ出して背景の雪の部分に入っています。

結構当てずっぽうのようです。trainデータが各500枚(x0.8)しかないので無理もないです。
4層CNN、データ拡張あり
データが少ないときはデータ拡張をすると効くはず。そこでKerasのImageDataGeneratorの機能でデータ拡張して同じ4層CNNで学習させました。
今度は良い感じにval accが上がっていったので200epoch回しています。
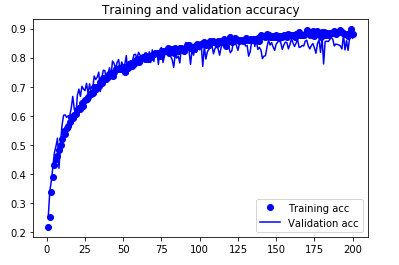
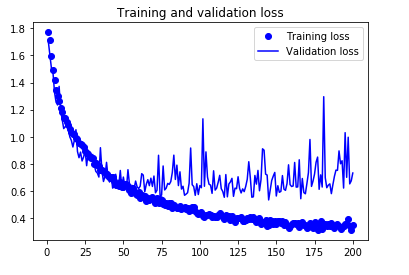
テストデータに対しての正解率は87.5%までいきました。
CAM
まずは失敗したほうからです。
キングペンギンをエンペラーペンギンと誤認識していますが、判定に使ったのはペンギンの頭の下部のところでまあ、悪くはないです。

こちらが正解したほう。イワトビペンギンを正しく判定しました。イワトビペンギンの特徴である頭部分が効いています。

他のCAMを見てみても、このモデルがかなりよくペンギンの特徴を捉えて判定しているのが見て取れました。
VGG16 ImageNetのファインチューニング(データ拡張なし)
小さなデータセットを用いたディープラーニングの効果的アプローチは、学習済みネットワークを使用すること、とKeras本にありましたので、ImageNetで訓練したVGG16の最後の畳み込みブロック5のみ解凍して再学習したモデルを作ってみます。
まずはデータ拡張なしでやったところ、
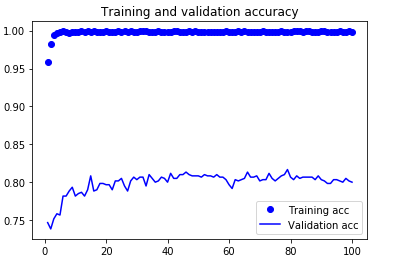
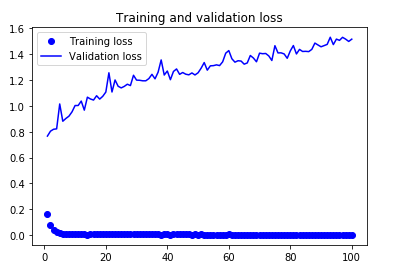
この前に30epochsのVGG16ベースネットワーク凍結での学習をしていますが、正解率は0.8を少し上回っていました。データ拡張なしの4層ネットワークと比べると、かなり上がりました。
テストデータに対する正解率は82.2%でした。
CAM
これは正解の例です。イワトビペンギンと認識したのですが、判定に使っているのが、ペンギンの背中や足元の部分、背景の雪の部分で当てずっぽう感が拭えません。

VGG16 ImageNetのファインチューニング(データ拡張あり)
では、データ拡張ありでファインチューニングをやってみたらどうでしょう。
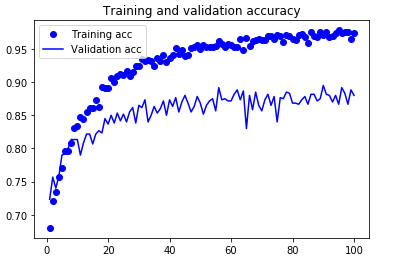
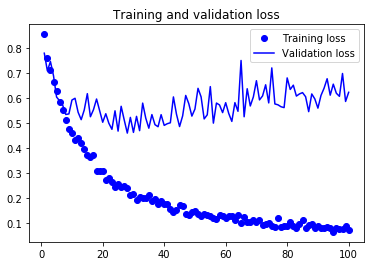
やはり、この前に30epochsのVGG16ベースネットワーク凍結での学習をしています。
検証データの正解率は当然データ拡張なしよりは良いですが、単純な4層データ拡張ありとそれほど変わりません。
テストデータに対しての正解率は86.9%で残念ながら4層+データ拡張に及びませんでした。
CAM
このようなキングペンギンの正解はいい感じに特徴である首の下を見ていますが、

ジェンツーペンギンを足元だけで判断していたりします。わたしだって足を見ただけでペンギン判断できませんが。。。

一般的には転移学習したほうが性能向上が見られるはずなので、この結果はどこかが間違っているのではないかなあと思っています。しかし、間違っている箇所が現状不明。。。
できなかったこと
- MixUpもやりたかったのですがまたの機会に。
- 画像検索でキングペンギンをエンペラーペンギンと間違えている例が多かったので、学習モデルはキングペンギンとエンペラーペンギンをどれくらい間違えるのか調べたかったのですが時間切れ。
おわりに
画像を集めるところからはじめて分類器を作成しました。
- モデル作成の前のラベルづけは人力だから大変。
- KerasでCNNを用いた画像分類器は、サンプルコード見よう見まねで簡単につくれる。
- 正解率をあげたければ、画像の水増しは必須。
- CAMで可視化してどこが効いているかをチェックし、モデルの正当性検証したほうがよい。