
ディープ・ラーニングの進化で、画像の分類はもはやコモディティに近い状態になりました。画像分類を作るためのチュートリアルやブログはいくらでもありますし、AutoMLのように、もはや分類器は自動生成するもの、という見方もあります。
多くの人がディープ・ラーニングの画像分類器を作ろうとしたとき、チュートリアルやブログを参考にすればすぐにできます。
その後自分の身の回りに応用しようとするとき、画像サンプルを作るのに苦労して、結局あまり多くないサンプルでトライすることもあると思います。そのとき、あまりうまく認識率が上がらないことに悩むことがあるかと思います。かなり以前の個人的な経験では、クラスあたり1,000~2,000枚用意してもその時はそれほどうまく行きませんでした。
Google’s Cloud AutoMLも使ってみました。少ないデータでもうまく学習してくれるのではないか、そう期待して試してみたのですが、それ以前に出力は全てのクラスの確率ではなく、確率の高いクラスのみで、これでは使いにくいことがわかりました。さらに言えば、動作を確認するためにactivationを知りたいのですが、おそらくそれは今後も無理でしょう。
この記事では、少ないデータセットに対してのモデルの作成、またその動作に自信の持てるようにすることについて書きます。
- 小さなデータセットで学習させるには何が必要か。
- なぜImageNet学習済みモデルが必要か。
- なぜAugmentationが必要か。
- AutoMLとの比較。
またこの記事では、下記を使います。
- KerasをML frameworkとして (またtensorflowをbackendとして使いました)
- VGG16をモデルとして、単純にKerasからimportして利用
- Accuracyを評価基準に
2018/10/7追記
「fast.aiで小さなデータセットを学習させたとき」 を別の記事にまとめました。
1. 小さなデータセットの作成
大きなデータセットは豊富になってきましたが(さらに言えば巨大すぎて扱いにくいものまで)、小さくて実用に近いデータが見当たらなかったので、作ることにしました。この記事で利用しているコードも全て載せました。
このデータセットは、ギークな本のカバー写真(※表のみ)で構成しました。5つの本と背景、合わせて6つのラベルになります。
一つのクラスは9個か8個の画像データを持ち、背景画像は29枚あります。全部で73枚の小さな教師データセットになります。

(全クラスから一枚ずつ)
テストセットについては、2種類のセットを用意しました。一つは「Easy」、教師データと似た分布で作成した6枚の画像セットです。本の帯を上下させたりして、少し変化をつけています。

もう一つは「Difficult」、こちらは未知の本、複数の本、重なりなど難しい画像で構成され、20枚から成ります。

最後にAutoML学習用の画像がありますが、これは今後使います。
2. スクラッチで学習させよう、だめ?
(もはや定石ではありませんが) スクラッチで学習させるとどうなるでしょうか。
しかも、全くAugmentationなしでやってみます。
| Test Results (accuracy) | Easy | Difficult |
|---|---|---|
| No augmentation | 0.33 | 0.10 |
ものすごい惨憺たる結果です。全然使えない分類器になりました。
小さな数のデータしか無いとき、こんなやり方では参考にもなりません。Augmentationを使いましょう。
3. Augmentationの必要性
Augmentationを使って見かけ上のデータ数を増やすことは、データセットが大きくても依然有効ですらあるようです。ここでは4つに段階を付けて適用したときの結果を見てみます。
- Augmentationなし - 上記で実行した通りで、無策に学習を進めた場合
- 通常のAugmentation利用 - 水平/垂直反転、回転、ズームとランダム消去を使いました
- mixupを利用
- 全て利用
mixup[1] は、2つのサンプルを合成する手法で、強力な手法です(詳しくは論文をご覧ください)
ランダム消去(random erasing)[3]またはcutout[2]は、画像の一部を塗りつぶす方法で、これも有効です。([3]または[2]をご覧ください。)
結果です。
| Test Results (accuracy) | Easy | Difficult |
|---|---|---|
| No augmentation | 0.33 | 0.10 |
| Using mixup | 0.33 | 0.25 |
| Using usual augmentations | 0.83 | 0.60 |
| Using all above | 1.00 | 0.65 |
- Augmentationはやはり有効に働きました。
- mixupで更に精度が上がります。
- とはいえ、mixupだけでは精度は上がりませんでした。
Augmentationをすべて使えば、Easyなテストセットは全て正解…
しかし、Difficultなものはどうでしょうか。
この分類器はホビーユースならばある程度使い物になるでしょう、でもビジネスでは使えませんよね。
65%正解しても35%間違えるということで、例えばこんな間違え方をしています。

左の結果は良さそうに見えます。しかし中央と右は悲惨です。こんなにあからさまなのに背景という結果。これでは実際には役に立たないでしょう。
品質保証的チェック - CAM
ところで、なにか新しい技術をビジネスで導入する、そんなときにはそれがちゃんと動いていることを確認する必要があります。
「ちゃんと動く」ことを証明するには、どのようにどれだけ確かに動いているか説明できることが必要ですが、ディープ・ラーニングはよく言われるように動作の説明をすることが困難です。
説明可能な解として検討できるものの一つに CAM (Class Activation Map)という手法があり、これを使って調べてみましょう。なお、CAMはKerasの本にとてもわかり易く説明されています。

(左: activation map, 中央: 左右の合成, 右: テスト画像)
一見良さそうですが、'keras'と判定しているにもかかわらず、その根拠で強く反応しているのは右下の端の部分、'nlp'本の部分です。

(左: activation map, 中央: 左右の合成, 右: テスト画像)
これは明らかに駄目です。'geeks'本と判断しているものの、色んな部分に反応していて、とても信頼の置けるものではありません。

(左: activation map, 中央: 左右の合成, 右: テスト画像)
これが一番悲惨です。'background'と判定しているのは、学習したはずの'technium'本。著者のケビン・ケリーさん、ごめんなさい…
これらの例で確認できたように、このモデルは当てずっぽうに推論していることがわかりました。学習では「本」を学んでほしいと期待しましたが、実際には別の基準で判断するものになっていました。
スクラッチで小さなデータセットを学習させるのは、例え強力なAugmentationを使ってもほとんど無理です。
少なくとも、一見良さそうな数値の結果が出ても、せめてCAMや類似する可視化方法で確認すべきです。
4. 定石: ImageNet学習済みモデルの転移学習
ImageNet学習済みモデルを転移学習するのが、小さなデータセットに対する定石です。CNNがうまく動作するのは、畳み込み層で良い表現ができるように学習されていることが必要ですが、これはImageNetのような大量のデータを学習することで得られると考えられます。
ImageNet学習済みモデルは、Kerasではweightsパラメーターをセットすることで簡単に利用できます。
base_model = VGG16(weights='imagenet', include_top=False, input_shape=input_shape)
学習済みモデルを使って、ここではまたAugmentationなしで試してみます。(なしは普通ではありませんね…)
| Test Results (accuracy) | Easy | Difficult |
|---|---|---|
| No augmentation | 0.83 | 0.35 |
Easyテストはやや良いですが…
(普通のチュートリアルはこういう結果で終わっていることが多いと思います)
Difficultの結果は全然だめで、35%という使えないものです。Augmentation使いましょう。
5. 転移学習でも、強力なAugmentationが必要
これまで同様に試した結果です。
| Test Results (accuracy) | Easy | Difficult |
|---|---|---|
| No augmentation | 0.83 | 0.35 |
| Using mixup | 1.00 | 0.35 |
| Using usual augmentations | 1.00 | 0.85 |
| Using all above | 1.00 | 0.95 |
通常のAugmentationは必要で、mixupでは85%に対する95%、__重要な10%__の性能向上が見られます。
この差の大きさを、再びCAMで見てみましょう。最後の2つの結果を比較します。

(通常のAugmentation + mixup)
この推論は中央の絵の部分に着目しているようなので、予測の判断は妥当だろうと確認できます。

(通常のAugmentationのみ)
しかしこの推論結果では本の部分というより、周り全体から本を判断しています。つまり、本の見た目から判断しておらず、このサンプルに関して信頼のある推論ができていないことがわかります。この結果の差がこの10%の差をよく表しています。
次のサンプルを見てみましょう。

(通常のAugmentation + mixup)

(通常のAugmentationのみ)
面白い結果になっています。両方共に、Keras本の女性の絵を捉えて分類している事がわかります。ImageNetでは人間も多くの画像に含まれるためか、元々含まれていたラベルの物体を検出するような重みに収束する傾向があるのかもしれません。特徴抽出の部分は人物も含めImageNetのクラスを表現するために学習された重みが固定されているので、そうなるインセンティブがありますよね。また、上の結果が上半身に着目しているのに対して、下の結果では全身を捉えて判断しているのも興味深いです。
Transfer learning: どのレイヤーまで学習するのか
今回のケースでは本の画像の分類でした。これは元のImageNetの対象クラスと似ていますので、モデルの重みはほとんどすべて固定して、最終的にクラスを分類するレイヤーだけを学習すれば良さそうです。しかし、このあたりの指針をどうすればよいか、方法論を書籍等で見つけることが出来ませんでした。
そこで、固定するレイヤーを変えて、それぞれの学習ごとのパフォーマンスを比較してみることにしました。本当は毎回十分に学習したいところですが、時間の関係上100エポックまでの学習結果をそれぞれ5回取りました。
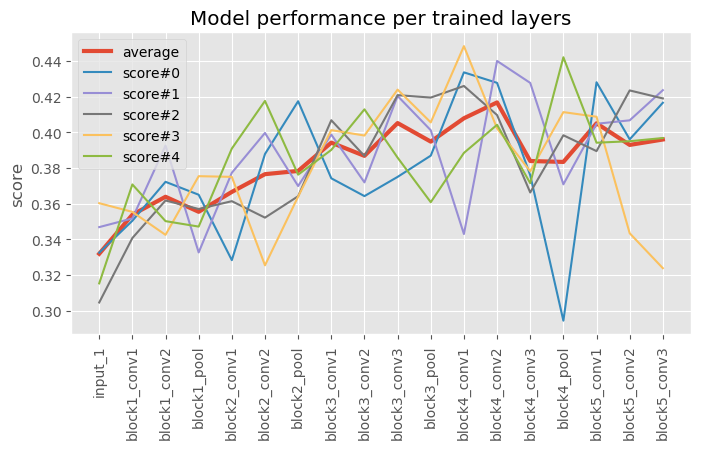
赤い平均値を見ると、block4の先頭(使用モデルはVGG16)くらいで一番良いパフォーマンスとなりそうです。そのため、この記事のImageNet学習済みモデルを転移させるときには、block4_conv1以降を学習して結果を得ました。
いくつかの本、特に「PythonとKerasによるディープラーニング」ではblock5の先頭まで固定してあり、その設定でも似たパフォーマンスにはなっています。
追記1. Google CloudのAutoMLの場合
GoogleのAutoMLでは、データセットをアップロードし、学習を開始するUIを操作するだけでモデルが作成されました。学習時間は15分程度で終わりました。
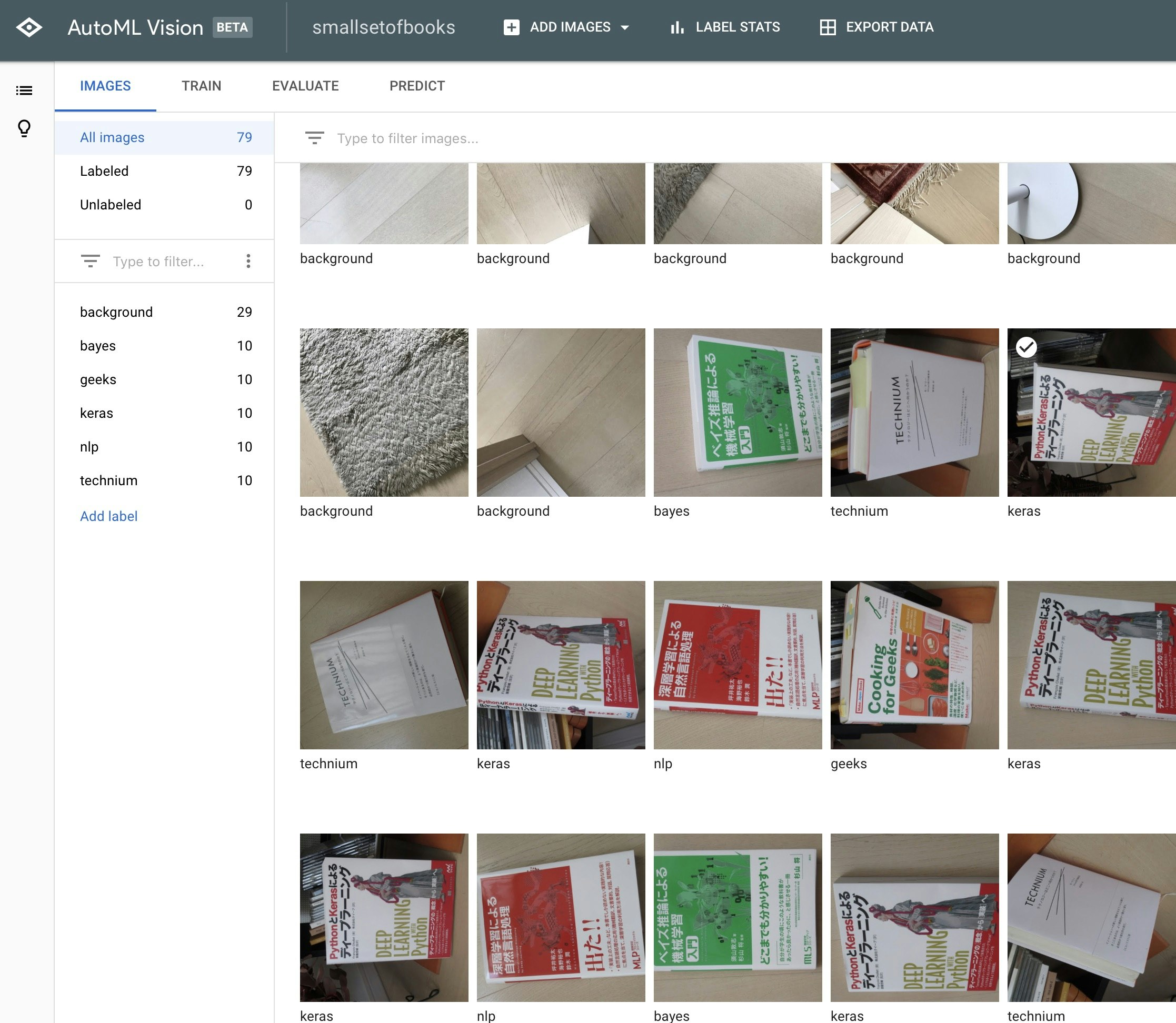
ただし、1クラスあたり最低10枚の画像が必要になりました。枚数を揃えるために用意したものが、「dataset/automl_train_extra」フォルダの追加画像になります。これまで自前での学習は、Augmentationで結果的に回転など水増しされた画像が使われました。そこでAutoMLでの条件を揃えるため、回転したり、単に再圧縮して画像自体に本質的な変更は加えないよう配慮しました。枚数は揃えるものの、学習に使う情報は増えないようになったはずです。

学習後の検証結果がこの通りで、完全に学習できています。※学習データセットなので。
さて、その後Difficultテストセットを与えて結果を得ました。そして比較したいところなのですが…、見送らざるを得ないことになりました。半分くらい、結果が出力されないのです。検出の確率が悪いものは間引かれてしまうようで、明らかなものだけしか出力されませんでした。
- Keras本の検出が目立つ。
- Technium本がよく検出できている。
- 複数の本が写っているときでも、単一の本の検出結果が出力される様子。そのように用途がそもそも限定されているのか?
画像のキャプションの左が独自に学習したモデルの結果、右がAutoMLの結果です(小さくすいません)。確率が0.0000になっているAutoMLの結果は、結果そのものが得られなかったものです。

結果を取得するには、下記のようにPythonコードでクラウドとやり取りできました。事前に認証の設定などが必要ですが、一度行えば後は取得した鍵を使うだけでした。
for f in dataset/test_difficult/*.jpg; do
python automl_predict.py ${f} モデル名 認証情報
done
結果はこのように得られます。
dataset/test_difficult/img_5491.jpg
payload {
classification {
score: 0.5125643610954285
}
display_name: "geeks"
}
追記2. 今回の実装でその他工夫している点
今回のような小さなデータセット向けに限らないのですが、性能を出し、維持・改善していくため、下記に配慮して実装しましたので、特に書いておきます。
クラス間のデータ量不均衡の解消
本を読んでも目立たない印象なのですが、機械学習の基本のうち、データ量をクラスごとに揃えることは不可欠ではないでしょうか。
小さなデータセットでプロトタイピングを急ぎたいときでも、データの分布が一様になることに気を使うことが、モデルの性能が安定する大きな要素ではないかと思われます。
今回の実装では、imbalanced-learnのRandomOverSamplerを使って、データ数が少ないクラスは単純にランダムに水増しして数が合わせてあります。
具体的には、本のクラスはそれぞれ9枚程度なのに対して、背景クラスは30枚近くあります。このままでは背景ばかりを学習してしまい、思った性能が出ないかもしれません。そこで学習を始める前に、背景クラスの枚数に合わせて、その他のクラスのデータを水増ししています。
適切なソフトエンジニアリング
少し前までTwitterや勉強会のレポートで散見しましたが、ちゃんと再利用性のあるソフトとして実装しようということが言われています。
当たり前の話なのですが、クラス化、関数化、設定のパラメーター化をしっかり行うことで進捗が大きく変わります。機械学習では試行錯誤をたくさん行うので、
- クラス化・関数化すると、次の試行で使いまわしやすい。
- ハイパーパラメーターなどだけでなく、動作の設定も全てパラメーター化すると、試行錯誤で何をやったかしっかり管理できるようになる。
- 重要: 実験の間違い・勘違いで時間を失うことが少なくなる。
まとめ
これまで様々な条件で学習させた結果を見てきました。
小さなデータセットで学習させた場合の結果を見てきたわけですが、大きなデータセットであれ、確実に画像分類器を学習させたいのであれば、
- ImageNet(または類似の)学習済みモデルを使い、汎化のポテンシャルを利用する。
- Augmentationを最大限利用し、学習時の汎化を十分促す。
これらが必要ではないかと思います。
以上の結果を得るためのコードはこちらにまとめてありますので、どうぞ試してみてください。
リファレンス
- [1] Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, David Lopez-Paz, "mixup: Beyond Empirical Risk Minimization," in arXiv:1710.09412, 2017
- [2] T. DeVries and G. W. Taylor, "Improved Regularization of Convolutional Neural Networks with Cutout," in arXiv:1708.04552, 2017
- [3] Z. Zhong, L. Zheng, G. Kang, S. Li, and Y. Yang, "Random Erasing Data Augmentation," in arXiv:1708.04896, 2017