
前回の記事「小さなデータセットで良い分類器を学習させるとき」では、Kerasを使った実装で下記を紹介しました。
- 本の写真を使った小さなデータセットを作成。
- このデータセットをどうしたらよく学習させられるか、ImageNet学習済みモデルの転移学習、Augmentationを使った場合の比較。
- AutoMLとの簡単な比較。
今回は、実践的な講座で知られるfast.aiライブラリを利用して、講座のTutorialで紹介されるエンジニアリングが適用できるのかを試してみました。
結論から言うと、適用できましたがチューニングに苦労しました。この記事では、下記をご紹介します。
- fast.aiの極めて小さなデータセットへの適用例。
- 講座ではResNet34をCAMで可視化していますが、ここではVGG16を可視化。
- チューニングで経験した苦労。
1. fast.aiについて
fast.aiは現在PyTorchベースのライブラリになっています(2018年以前はKerasベース)。
今回のコードは、本質的にはたったのこれだけです。fast.aiの特徴として、極めて簡潔に書けるようになっています。
tfms = tfms_from_model(...) # Augmentationの定義
data = ImageClassifierData.from_csv(...) # データセットの定義
model = nn.Sequential(...) # モデルの定義
learn = ConvLearner.from_model_data(model, data) # 学習器の定義
learn.fit(lrs[-1], 5) # 学習
また、
- lr_find() 強力な学習率探索機能。
- Differential learning rate、モデルの層ごとに学習率を個別に設定できる!
- Augmentationの充実。
- TTA (Test Time Augmentation)が標準…
- CNN以外の機械学習も同じように書ける。
その他勝手にRandom cropしてくれたり、実践的に有効な機能が標準的に働いて、最適な状態で機械学習の仕事を進められるようになっています。もちろん場合に応じて何が最適か異なるため、カスタマイズの項目が実践者目線で、詳細に可能になっています。
これらはfast.ai以外で利用するのには手がかかるため、現時点でディープ・ラーニングのモデルを開発するのには、とても強力なライブラリの選択肢と言えると思います。
日本人には、アメリカ英語での情報がメインになることが辛いかもしれません。fast.aiのフォーラムで検索すれば疑問はたいてい解消できますが、Googleの検索結果で探しにくい時もありました。またライブラリの使い方は、基本的にgit cloneしてコードを見に行くほうが早いようです。ビデオは、質疑応答も含めてものすごく参考になりますが、ガチでネイティブです。
2. コードと学習結果
github/daisukelab/small_book_image_datasetリポジトリに格納した、この成功例のコードで説明していきます。
2-1. データの与え方
datasetフォルダ以下にtrain、testデータが保管されていて、trainはcsvで指定、testはフォルダで指定することで与えることにしました。
train、valid、testの3フォルダ構成だともっと簡単にフォルダを指定するだけでよかったものの、csvで指定できるとcross validationなど後々柔軟なため、そういったサンプルで作りました。
train_files = list(PATH.glob('train/*/*.jpg')) # --- (1)
y_train = [f.parent for f in train_files] # --- (2)
train_files = [f.parent.name+'/'+f.name for f in train_files] # (3)
df = pd.DataFrame()
df['fnames'] = train_files
df['target'] = y_train
df.to_csv(PATH/'labels.csv', index=False) # --- (4)
- ファイルのリストを作成、Pathlibを使えば簡潔です。
- 同様に正解yはフォルダ名なので、
f.parentで簡潔に作成。 - 学習データとして「相対フォルダ名/ファイル名」を作成。
- PandasでCSV化。
Validationサンプルはcsvのインデックスで与えます。いつも通りtrain_test_splitでクラスバランスを取って作成しています。
_, val_idxs, _, _ = train_test_split(list(range(len(train_files))), y_train, test_size=0.2, random_state=42)
データセットは、このようなクラスインスタンスでまとめて取り扱います。
data = ImageClassifierData.from_csv(PATH, 'train', PATH/'labels.csv', test_name='test',
val_idxs=val_idxs, tfms=tfms, bs=bs)
PATHには学習にまつわる様々なファイルを保持するためのベースとなるフォルダを、tfmsは「transforms」の略(次節で説明します)、bsはバッチサイズ。
trn = train, val = validation その他略語が多いのもこのライブラリの特徴でしょうか。
2-2. Augmentation
aug_tfmsに設定しているリストがAugmentationの内容です。
tfms = tfms_from_model(arch, sz,
aug_tfms=transforms_side_on+[Cutout(n_holes=3, length=40), RandomBlur()],
max_zoom=1.5)
-
transforms_side_onは横方向から取った写真に適した変換用の基本指定で、10度程度の回転、少しの画像の明暗、ランダムフリップ。 - Cutoutはランダムな画像の切り取り、これはKeras実装でも利用しました。
- RandomBlurはランダムなぼかし。
今回はこれだけ利用しましたが、ここはほとんど試行錯誤しないでモデルや学習パラメーターを調整しました。
Kerasのときに使ったmixupは残念ながら利用できません。
2-3. モデルと学習器
この部分、fast.ai標準ではもっと簡単に書けます。しかし、Activationを可視化したいので、従ってConv2d層が必要になるため、PyTorchネイティブな書き方でモデルを作成している例です。fast.aiの講座のノートブックに可視化のサンプルがあり、 その例に従っています。
model = nn.Sequential(*children(arch(pre=True))[:-2],
nn.Dropout2d(0.05),
nn.Conv2d(512, len(data.classes), 3, padding=1),
nn.Dropout2d(0.1),
nn.AdaptiveAvgPool2d(1), Flatten(),
nn.Dropout2d(0.3),
nn.LogSoftmax())
learn = ConvLearner.from_model_data(model, data)
-
archには、vgg16がセットされているのでarch(pre=True)はVGG16の学習済みモデルを使う、という意味になります。 - DropOutを適宜追加しています。これが今回重要な変更点です。
-
learnに学習を進めるためのインスタンスがまとまっています。
2-4. 学習の実施
fast.aiコースの標準的なやり方に従っています。そのうち、①まず全結合層を大まかに学習し、②全体をfine tuneしています。
lrs = np.array([0.0]*34 + [1e-5]*6 + [1e-4]*3 + [1e-3] *6)
learn.fit(lrs[-1], 5)
-
lrsに学習率を定義していますが、レイヤー一つ一つに個別の学習率を設定しています。先頭から34層は学習なし、次の6層は1e-5、次の3層は1e-4、最後の全結合層付近は1e-3。 - 実は、fast.aiの重要な機能「lr_find()」での学習率検索は、このデータセットに使えません。データ数が少なすぎるのです。学習率は試行錯誤で決めました。
- この学習では、まだ学習済みモデルの重みは固定されたままです。上記
model = nn.Sequential(...)のchildren以下の層のみ学習されます。
learn.unfreeze()
learn.fit(lrs, n_cycle=3, cycle_len=9, cycle_mult=2)
-
unfreezeすると、すべての層が学習されるようになります。 -
lrsで学習率をセットしているので、それぞれ指定の率が適用されます。先頭の層は係数が0.0なので学習されず、ImageNetで得られた表現を保持します。
これで様子を見たものの、val_lossがもっと下がらないか試すため、ダメ押しで学習させました。
learn.fit(lrs, n_cycle=3, cycle_len=2, cycle_mult=2)
最終的に、val_lossとval_accuracyはこのようになりました。
[0.15595930814743042, 1.0]
3. 評価
学習結果は、2つのテストセットで行ったのは前回同様です。5枚の簡単な「test」セット、20枚の難しい「test_difficult」セット。
- どちらも、数字上はKerasの結果と大差ありませんでした。
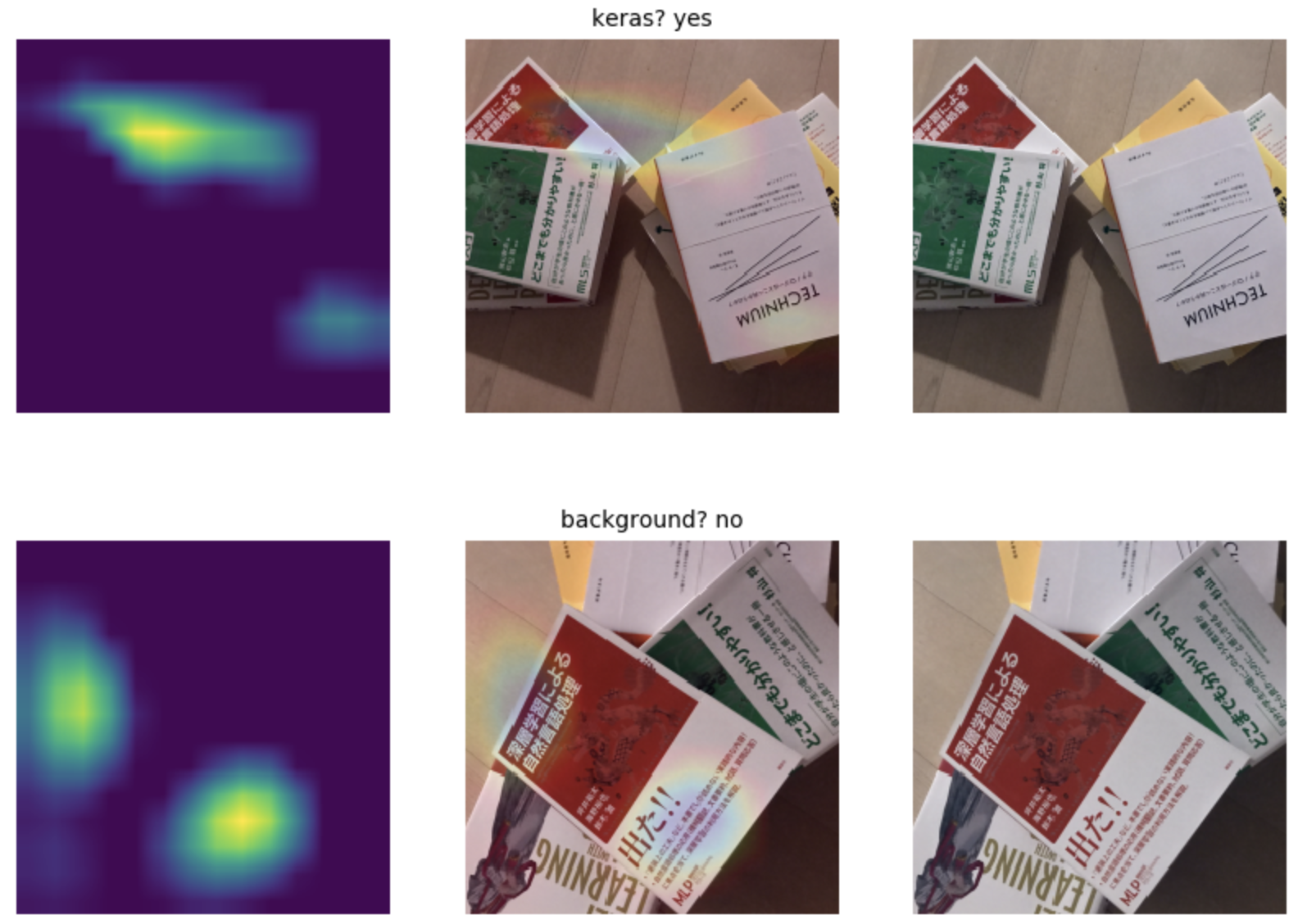
- 強いて言えば、特徴が少ない「テクニウム」本もよく拾えています。

例) PRML本はクラス外(background扱いが正しい)、少ししか見えていないテクニウム本が検出された。
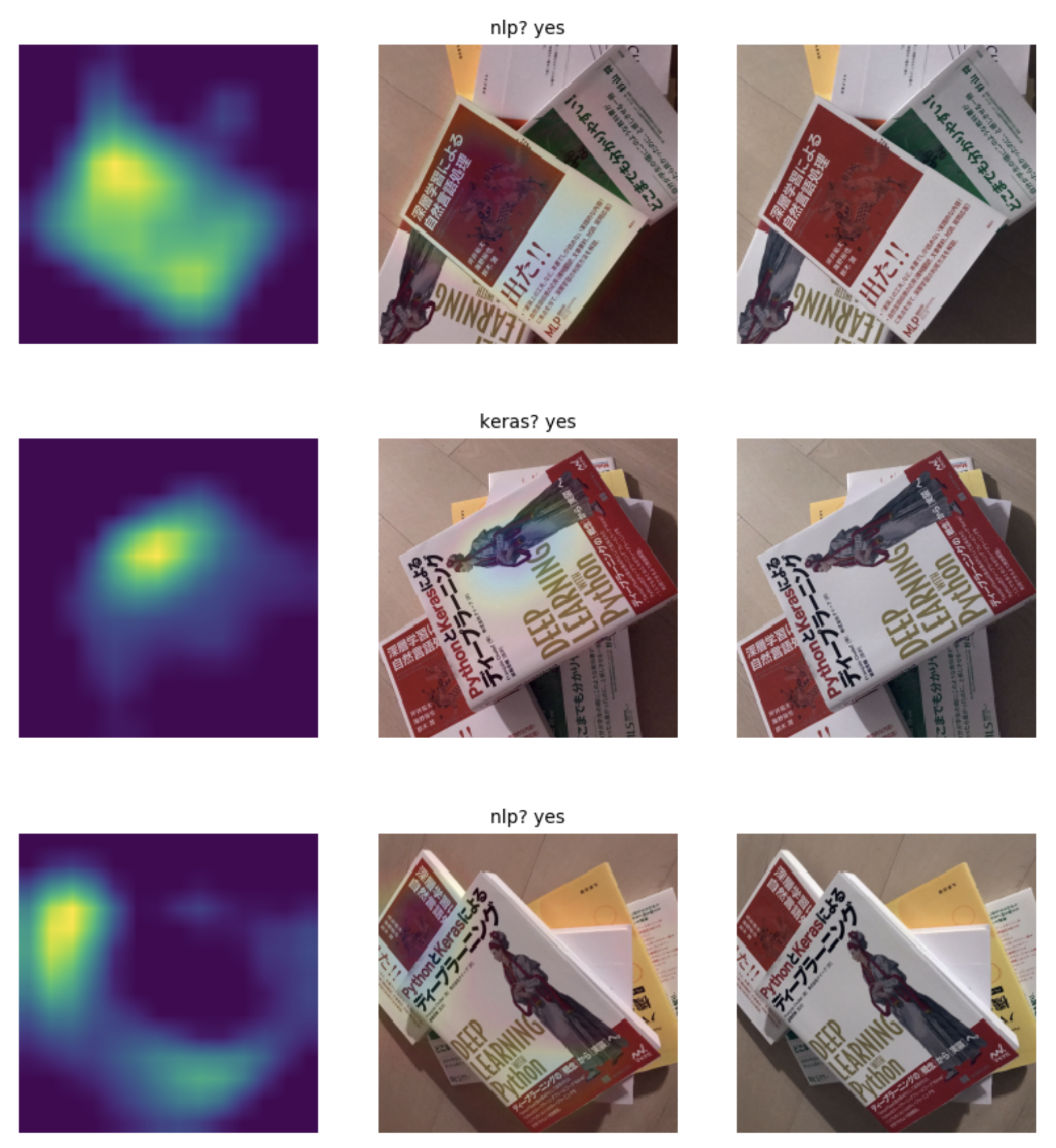
3-1. 可視化結果
この3つが特徴的かもしれません。(上)NLP本はよく捉えられています。(中)Keras本はやはり人物をよく捉えています。(下)大きく写っているKeras本ではなく、NLP本の方が予測確率が高いものの、その本の上でよく反応しています。
Keras本の人物での検出について特に見てみると、このように違いました。こちらは今回のfast.aiを使った結果。

Kerasで学習させた結果。

どちらがいいか悪いかは評価できませんが、どちらも本の特徴的な部分に反応しているので、安心材料と言えそうです。
4. チューニングで経験したこと
fast.aiのtutorialは、Kaggleのコンペティションを実際に解く強力な内容です。一番はじめのCat&Dogの二値分類の例ではいきなり98%のaccuracy (※データに偏りはほぼ無い)、コードは極めてシンプル、こんなに簡単に適用できるのか? という点を確かめたい意味もありました。
今回のデータセットで試してみて、いくつかこのケースに合わせた工夫が必要でした。まずデータ数が圧倒的に少ないので、Augmentationの強化は必要だとして…
4-1. val_lossが極めて小さくなったのに、可視化するとNG
ノートブック Small Dataset -Train With fast.ai library - failed sample.ipynb
epoch trn_loss val_loss accuracy
0 2.833867 29.770578 0.266667
1 5.102689 2.876118 0.4
2 4.21876 0.749274 0.8
3 3.605483 0.657577 0.866667
4 4.233637 0.674379 0.866667
5 5.409446 0.422157 0.933333
6 5.027302 0.715448 0.866667
7 4.683777 0.256084 0.933333
8 4.237247 0.007954 1.0
9 3.762359 0.00091 1.0
:
ものすごくUnderfitしていますが、可視化してみると全くGeneralizeしていませんでした。
原因の想定
lrs = np.array([1e-4]*20 + [1e-3]*20 + [1e-2] *9)
傾斜させた学習率はこのようになり、前方の層も(乱暴な20層という指定で)学習させています。成功例との差分はここで、前方の学習率を0にして、Kerasでの実装と同じように後方の層だけを学習させることで解決しました。
このことから、ImageNetで得られた表現能力が失われ、前方の層が少ないデータにOverfitし、Validation setのデータにすらval_lossがほぼ0になるような学習が、たまたま、出来たのでしょう。
実際fast.aiの講義の中でも、ImageNetに近い画像なら後方だけを学習させたほうがいい、ということも言っていました(おそらくLesson 2)。今回の画像はImageNetに近いと言えそうですが、それ以上に「データ数が少なすぎる」ため、こういう「数字上良く見えるOverfit」が起こったのではと推測しています。
4-2. 性能が上がらない
このケースのノートブックは用意していませんが、
epoch trn_loss val_loss accuracy
0 0.928827 0.952379 1.0
1 0.918847 0.947507 1.0
2 0.900165 0.938069 1.0
3 0.906743 0.938205 0.8
4 0.900881 0.946733 0.733333
5 0.902564 0.939668 0.733333
6 0.90002 0.936944 0.733333
7 0.894409 0.934365 0.733333
8 0.896848 0.93585 0.733333
:
val_lossが下がらず、数字に現れる形でOverfitしていきます。学習がうまくいきません。
原因の想定
このときのモデルは、このようにDropoutがありませんでした。(可視化の講義サンプルそのまま)
model = nn.Sequential(*children(arch(pre=True))[:-2],
nn.Conv2d(512, len(data.classes), 3, padding=1),
nn.AdaptiveAvgPool2d(1), Flatten(),
nn.LogSoftmax())
「2-3.モデルと学習器」のように、Dropoutを追加すると改善しました。
また、学習率もトライアンドエラーで調整、UnderfitとOverfitを避けて、うまく学習できる値を探しました…
このことから、モデルの汎化能力が足りなかったのだろうと推測し、話には聞いていた「学習率の調整が難しい」件だったのかもしれません。
5. まとめ
もう一つKerasとの差分で大きいのでは、と推測するのはmixupです。これが使えれば学習方法の側面で汎化を促せて、学習を成功させられるかもしれないので試してみたいのですが、それにはfast.aiライブラリの中にもっと入っていく必要があり、今回は時間切れで諦めました。
いずれにしても、このデータセットのように数が少ない、ということが最も本質的に良くないのでしょう。
実際にクイックプロトタイピングしたいときを想定して縛りを付けましたが、どんどんテクニックを磨いていくための(良い?)練習になり、違う方向に進んでいくのを実感しました。
データは、十分に用意したいですね。
fast.aiライブラリについては、とても強力でした。使える現場なら積極的に試して見る価値があると思います。