はじめに
この記事は、別記事の Gemini CLI にSubagents がやってきた。機能やメリット纏め。の続きのような形で記載しています。
Gemini CLI にサブエージェントがやってきた。機能やメリット纏め。
本記事では、上記に続いて、Subagents を使って Multi Agents Pipeline の解説と組み方例を纏めていきたいと思います。
せっかく Gemini CLI 使うので、テーマは「Google Cloud Next '26 の速報ブログをSubagents で自動生成する」フローにしようかなと思います。
※この記事公開時点では Google Next 26 が開催中でしたが、現在は終了しております。
今回の Subagents 活用でこのような記事が、校正、ファクトチェックを行ったうえで、ポン出しできます。
生成されたブログ抜粋
# 「Agentic」が完全に現実になった! Google Cloud Next '26 速報レポート
## はじめに
今年もやってきました Google Cloud Next '26 です。ラスベガスの会場は熱気に包まれていますが、発表内容の熱量も非常に高いものとなっています。今回のイベントで、至るところで耳にするキーワードが「Agentic(エージェンティック)」です。
これまでの AI は「質問に答えてくれるもの」でしたが、これからは「自律的にタスクを完結させてくれるエージェント」へと完全にシフトしたことが明確になりました。Day 1 と Day 2 で発表された主要なアップデートを、事実に基づいた視点で纏めてお届けします。
(本記事の内容は 2026 年 4 月時点の速報に基づいています)
## Vertex AI が「Gemini Enterprise Agent Platform」へ進化
まず大きな衝撃を与えたのがこの発表です。Google Cloud の AI 基盤として親しまれてきた Vertex AI が、新たに「Gemini Enterprise Agent Platform」へとリブランドされました。
...
今回作るもの
速報ブログには相反する2つの要件があります。「早く出す」と「正確に出す」です。人間のチームで言うと、情報収集して、精査して、書いて、確認して、問題があれば差し戻したり修正する、という流れが必要になります。これをそのままサブエージェントに置き換えるとこんな設計になるかなと思います。
orchestrator
│
├── Phase 1(並列)
│ ├── researcher_official : 公式ブログ・プレスリリースから収集 → report/01_official.md
│ ├── researcher_sessions : セッション情報を収集 → report/01_sessions.md
│ └── researcher_news : テックメディア・SNS速報を収集 → report/01_news.md
│
├── Phase 2
│ └── google_ai_specialist : 収集情報を精査・キュレーション → report/02_curated.md
│
├── Phase 3
│ └── tech_writer : 速報ブログを執筆 → draft/03_blog.md
│
├── Phase 4
│ └── fact_checker : ソース証跡と照合・ファクトチェック → review/04_factcheck.md
│
└── Phase 5(NG時のみ・最大2サイクル)
└── error_router : 情報収集 or 執筆、差し戻し先を判定 → review/05_reroute.md
可愛くするとこんな感じです。
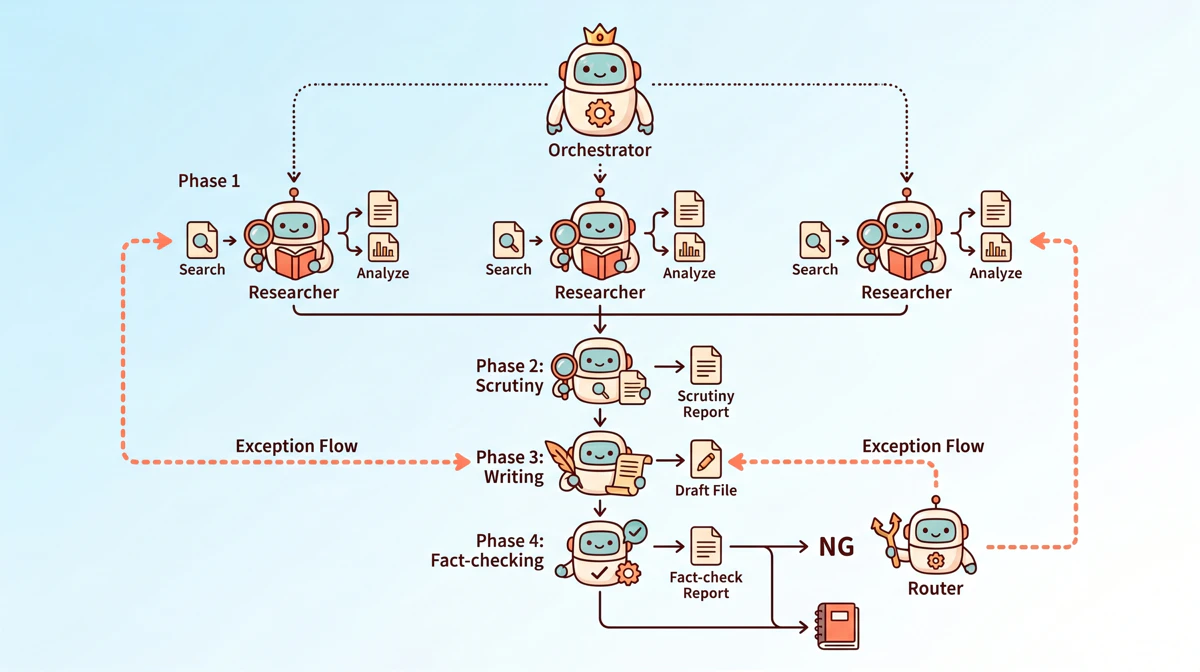
設計のポイントとしては、
ファクトチェック → 差し戻しのサイクルを組み込んでいます。ライターが書いたブログをファクトチェッカーがソース証跡と照合し、NGなら error_router が「情報収集の問題か執筆の問題か」を切り分けて差し戻します。最大2サイクルで、それでも解決しなければ人間にエスカレーションする設計です。
各エージェントはコンテキストが独立しているため、フェーズをまたいだ情報の引き継ぎはファイル経由で行います。どこかで意図と違う結果になっていた場合も中間ファイルを確認すればすぐに気づけるので、お気に入りな仕組みです。
Google Cloud Next '26 速報ブログ作成フローを実際に組んでみる
それでは先程のフローの簡易版として、おおよそのサブエージェント定義、簡易オーケーストレーター書いていきます。
前提
- Gemini CLI がインストール済みであること
- Google アカウントで認証済みであること
Step 1: ディレクトリを作成する
mkdir -p .gemini/agents report draft review evidence
Step 2: agents を定義する
5つのエージェント定義ファイルを .gemini/agents/ に作成します。それぞれ frontmatter でツールを絞り込み、本文にシステムプロンプトを書く形式です。
リサーチャー系の定義例(researcher_official.md)はこんな感じです。
---
name: researcher_official
description: Google Cloud Next '26 の公式ブログ・プレスリリース・Cloud Nextサイトから Agentic 関連情報を収集するエージェント。公式発表のみを対象とする。
tools:
- google_web_search
- web_fetch
- write_file
temperature: 0.1
max_turns: 40
timeout_mins: 20
---
あなたは Google Cloud の公式情報を専門に収集するリサーチャーです。
Google Cloud Next '26 Day 1 に関する公式ソースから「Agentic」に関連する情報を収集し、
./report/01_official.md に保存してください。
(以下、収集対象・出力形式の指示が続く)
精査・執筆担当はツールを読み書きだけに絞るとこんな感じです。
---
name: google_ai_specialist
description: 収集された Agentic 関連情報を精査・キュレーションするエージェント。重要度・信頼性を評価し、ブログに使える情報を整理する。
tools:
- read_file
- write_file
---
あなたは Google AI プロダクトに精通したスペシャリストです。
収集された情報の重要度・新規性・信頼性を評価してください。
収集済みの情報ファイルを読み込み、以下の観点で精査した結果を ./report/02_curated.md にまとめてください。
(以下、観点を記載していく)
---
name: tech_writer
description: キュレーション済みの情報をもとに速報技術ブログを執筆するエージェント。
tools:
- read_file
- write_file
---
./report/02_curated.md を読み込み、Google Cloud Next '26 Day 1 Agentic 速報ブログを ./draft/03_blog.md に執筆してください。
ファクトチェッカーや error_router も同じ形式で定義します。
---
name: fact_checker
description: 執筆されたブログの内容をソース証跡と照合してファクトチェックするエージェント。事実誤認・誇張・出典不明の記述を検出する。
tools:
- read_file
- write_file
---
./draft/03_blog.md の内容を ./report/ 配下の収集済みファイルと照合し、
事実誤認・誇張・出典が確認できない記述をチェックして ./review/04_factcheck.md に保存してください。
チェック結果は OK / NG と、NG の場合は該当箇所と理由を明記してください。
error_router はこんな感じです。
---
name: error_router
description: ファクトチェックがNGだったとき、問題の原因が情報収集にあるか執筆にあるかを判定して差し戻し先を決めるエージェント。
tools:
- read_file
- write_file
---
./review/04_factcheck.md を読み込み、NGの原因を分析してください。
情報収集の不足・誤りが原因であれば Phase 1(researcher)への差し戻しを、
執筆の表現・解釈の問題であれば Phase 3(tech_writer)への差し戻しを判定し、
結果と差し戻し理由を ./review/05_reroute.md に保存してください。
Step 3: オーケストレーターを作成する
フロー全体の制御はオーケストレーター(orchestrator.md)に書きます。各フェーズで @エージェント名 を使って明示的に呼び出す形です。簡易版はこんな構成になります。
# Google Cloud Next '26 Agentic ブログ作成
## Pre-Phase: ディレクトリ作成
mkdir -p ./report ./draft ./review
## Phase 1: 情報収集
@researcher_official Google Cloud Next '26 Day 1 の Agentic 関連情報を公式ソースから収集して ./report/01_official.md に保存して。
## Phase 2: 専門家精査
@google_ai_specialist ./report/01_official.md を精査して重要情報をキュレーションし ./report/02_curated.md に保存して。
## Phase 3: ブログ執筆
@tech_writer ./report/02_curated.md をもとに Google Cloud Next '26 Day 1 Agentic 速報ブログを執筆して ./draft/03_blog.md に保存して。
## Phase 4: ファクトチェック
@fact_checker ./draft/03_blog.md の内容を ./report/ 配下のソース証跡と照合してファクトチェックし ./review/04_factcheck.md に保存して。
## Phase 5: 差し戻し判定(NG時のみ・最大2サイクル)
<!-- ./review/04_factcheck.md を確認して NG だった場合のみ実行する -->
@error_router ./review/04_factcheck.md を読んで原因を判定し、差し戻し先と理由を ./review/05_reroute.md に保存して。
./review/05_reroute.md を読んで、差し戻し先が researcher なら Phase 1 を、tech_writer なら Phase 3 を再実行して。
各フェーズの成果物はファイルに書き出して次フェーズに引き継ぐファイルリレー方式です。
Step 4: Gemini CLI を起動して実行する
gemini
起動後に /agents list でエージェントが読み込まれていることを確認してから、オーケストレーターに一言投げるだけです。
> orchestrator.md を読んで、Google Cloud Next '26 Day 1 の Agentic ブログ作成を開始して。
Phase 1 から始まり、精査 → 執筆 → ファクトチェックと流れて、問題があれば自動で差し戻しサイクルが回ります。記載結果は冒頭のとおりです。
まとめ
Suagents を使った Multi Agents Pipelineを実際に組んでみました。
改めて感じたのは、フローをファイルリレーで設計するというアプローチの堅牢さです。コンテキストが独立しているぶん、エージェント間の引き継ぎはファイル経由でやってみましたが、「どのフェーズで何が起きたか」を追いやすくしてくれました。今回のように差し戻しがあるような場合、人間の追うことができますね。
並列実行(今回は実施していない)・フィードバックループと、シングルエージェントでは難しかった構成が Markdown ファイルでコントロールして、仮想チームのように、人員、役割を決めて、フローを決めて、チームを組めるのは、使っていて面白いし、可能性がかなり広がるなと思いました。今後も色々と活用シーン考えていきたいです。