GCPでkaggle用の環境を作るのに苦労した
こんにちは、Qiita初投稿のhiromuです。
最近、KaggleのJigsaw Unintended Bias in Toxicityc Classificationに参加し、3位入賞を果たすことができました。
その際に、必要に駆られてGCPを使ったのですが、意外とつまずくポイントが多かったです。
なので、自分へのメモ用もかねてこの記事を書いています。
Compute Engineのデプロイまで
@lain21さんの記事の「GCEインスタンスの作成」がとても丁寧でわかりやすいです。
ただ、コメント欄で紹介されているように、事前にGPUの割り当てを行なっておく必要があります。
やり方は以下の通りです。
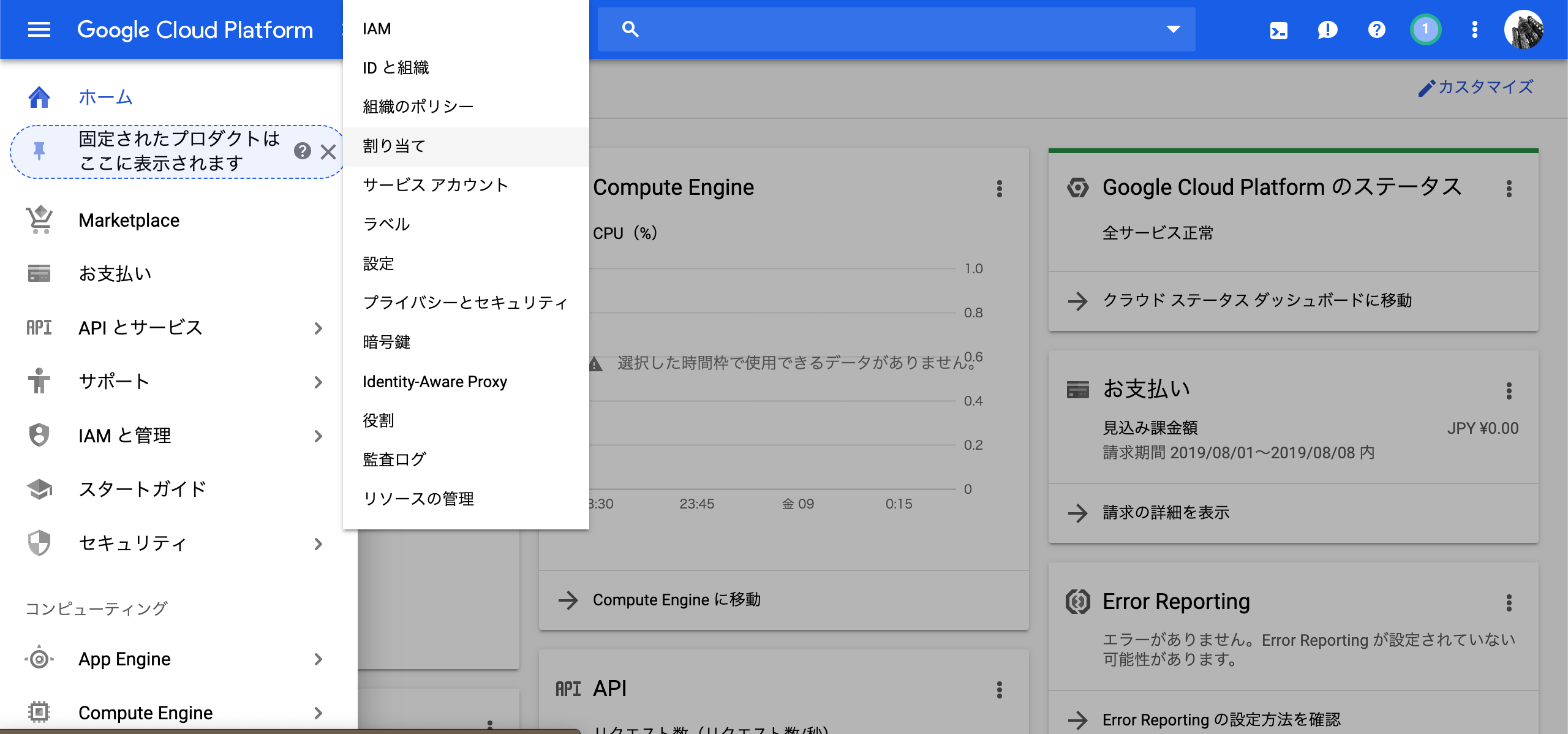
1.コンソールのIAMと管理->割り当てをクリック
2.指標のチェックボックスでGPUs(all regions)にチェックをつける
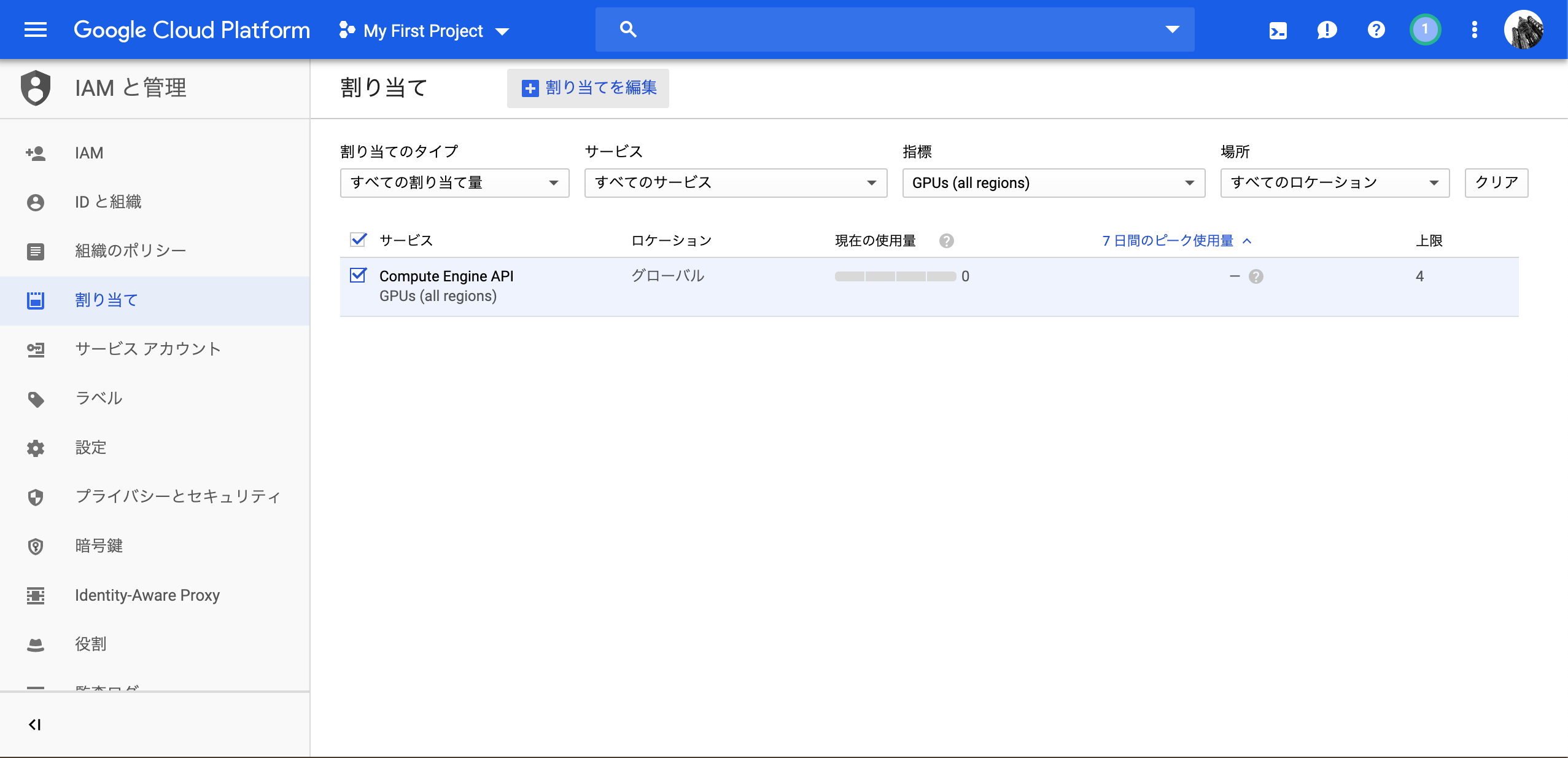
3.横の四角にチェックをつけ、割り当てを編集をクリック
4.必要な情報を入力し、送信
5.承認されるまで少し時間がかかるので、気長に待ちましょう
記事の通り進んでいくと、ここでCloud SDKインストールするのですが、僕はここでつまずいてしまったので別の方法を後で紹介します。
Dockerは取っつきづらいので手打ちで解決
僕は、Docker fileなんじゃそれ状態だったので紹介されているfileの中身を手打ちすることにしました。
ここから実際に環境を構築していきます。
GCEをデプロイしたら、VMインスタンスに作ったインスタンスが表示されるはずです。
そこで、接続という文字の下にあるSSHを押してみましょう。
ターミナルのようなものが立ち上がるはずです。
まずは、以下のコマンドを打ってみてください。
sudo apt-get upgrade
sudo apt install git wget make nano vim gcc build-essential tmux htop```
3行目の部分はお好みで。emacsを入れるのもありです。
# Anacondaのインストール
[Anaconda](https://www.anaconda.com/distribution/)からLinuxバージョンのpython3.7をダウンロードします。
```wget https://repo.anaconda.com/archive/Anaconda3-2019.07-Linux-x86_64.sh
bash Anaconda3-2019.07-Linux-x86_64.sh
source ~/.bashrc```
これは、2019年8月8日時点で最新のバージョンをダウンロードするコマンドです。
AnacondaのダウンロードボタンのURLをwgetの後ろにつければいつでも最新版をダウンロードできます。
# Jupyter Notebookを使えるようにする
ここが、最大のつまづきポイントでした。
Cloud SDKなしで実行する際に、とても参考になる@tk_01さんの[記事](https://qiita.com/tk_01/items/307716a680460f8dbe17)を置いておきます。
vimを使ってconfigファイルに書き込む作業は、臆することなく下までスクロールして数行を書き足すだけなので安心してください。
# 必要なライブラリを入れる
ここは、参加するコンペによって変わってくると思います。
[Jigsaw Unintended Bias in Toxicityc Classification](https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification)の場合は、以下のようにしました。
・PyTorch
```conda install pytorch torchvision cudatoolkit=10.0 -c pytorch```
[公式ホームページ](https://pytorch.org/)から簡単にコマンド生成できます。
・Apex
GPUのメモリ使用量を下げたり、計算時間を短くしてくれる優れものです。
```git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./```
・Bert (PyTorch ver)
コンペ時から改良がなされ、コマンドが変わっていますが、pipインストールだけですぐ使えます。
[pytorch-transformers](https://github.com/huggingface/pytorch-transformers)
```pip install pytorch-transformers```
・その他
実際に回したいコードを回して、エラーが出たらその都度入れていきましょう。
# コンペに使うデータの読み込み方
これは、ベストな方法ではないと思いますが、簡単にできます。
1. Kaggleから使いたいデータセットをダウンロードします。
2. GCPのStorageにアップロードします。
3. インスタンスのターミナルで次のコマンドを打ち込むだけです。
```mkdir input
gsutil -m cp -r gs://バケット名/フォルダ名/ファイル名 input/```
上のコマンドは一例なのでデータの構造によって若干異なると思います。
tkm2261さんの[詳しい解説](https://www.youtube.com/watch?v=3o1gj08WR4o&t=32s)がYouTubeにあるのでぜひ参考にしてください。
# 終わりに
多分、上記の流れで基本的な計算環境は整うはずです。
僕自身もGCPはなかなか使い方がわからず、敬遠しがちでした。
なので、この記事を読んでやってみようと思ってくれる方がいたらとても嬉しいです。
何かわからないところや間違っているところがあったら、ぜひ教えてください!