グラフDBを使ってpackage by featureを進める
アーキテクチャをインタラクティブに可視化するにはグラフDBが強力
ソフトウェアのアーキテクチャはグラフ構造です。
ファイルAの中身がファイルBで使われていて、ファイルBがファイルCから使われていればA=>B=>Cと依存グラフが描けます。
Graphvizなどを使って静的なグラフを画像に書き出すことはできますが、リファクタリングでファイル構造変更などアーキテクチャの変更を検討する際にインタラクティブにグラフをいじれるとより理解が深まりやすいです。
グラフデータベースのNeo4jではグラフDBのSQL相当のCypherをサポートしており、可視化ツールも同梱されているためこういったケースに向いているように感じたので今回見て行きます。
データは下記記事のRedmineのモデルグラフ、モデルのクラスタリング結果を使用してpackage by featureのアークテクチャを検討します。
Neo4jのインストール
brew install neo4j
brew services start neo4j
source venv/bin/activate
pip install neo4j
http://localhost:7474 にGUIが立ち上がります。
id: neo4j, password: neo4jでログイン後パスワード変更を要求されるので対応します。
モデル関係のインポート
pythonでcsv経由でneo4jにデータをインポートします。
neo4jは事前にスキーマを定義する必要がないです。
READ側のクエリーは無向グラフとしても扱えるのですが、作成時は有効グラフなのでfrom_modelとto_modelは常にhasの関係がtoに向くように反転させます。
from_model,to_model,association_type
Doorkeeper::AccessToken,Doorkeeper::Application,belongs_to
Doorkeeper::AccessGrant,Doorkeeper::Application,belongs_to
WorkflowRule,Role,belongs_to
WorkflowRule,Tracker,belongs_to
WorkflowRule,IssueStatus,belongs_to
後略
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Load model associations from a CSV into Neo4j.
Nodes: (:Model {name})
Relationships (directed from from_model -> to_model):
:BELONGS_TO | :HAS_ONE | :HAS_MANY | :HAS_AND_BELONGS_TO_MANY
Each relationship keeps the original association_type as a property too.
Usage:
export NEO4J_URI="neo4j://localhost:7687"
export NEO4J_USER="neo4j"
export NEO4J_PASSWORD="password"
python load_associations.py path/to/associations.csv
"""
import os
import sys
import csv
import argparse
from typing import List, Dict
from neo4j import GraphDatabase
from neo4j.exceptions import ServiceUnavailable
REL_MAP = {
"belongs_to": "BELONGS_TO",
"has_one": "HAS_ONE",
"has_many": "HAS_MANY",
"has_and_belongs_to_many": "HAS_AND_BELONGS_TO_MANY",
}
def parse_csv(path: str) -> List[Dict[str, str]]:
rows = []
with open(path, "r", encoding="utf-8-sig", newline="") as f:
reader = csv.DictReader(f)
for i, row in enumerate(reader, start=1):
fm = row["from_model"].strip()
tm = row["to_model"].strip()
at = row["association_type"].strip()
key = at.lower()
if key not in REL_MAP:
raise ValueError(f"Unknown association_type at line {i}: {at}")
if key == "belongs_to":
rows.append({
"from_model": tm,
"to_model": fm,
"association_type": "has",
"rel_type": "HAS",
})
else:
rows.append({
"from_model": fm,
"to_model": tm,
# "association_type": at,
"association_type": "has",
# "rel_type": REL_MAP[key],
"rel_type": "HAS",
})
return rows
def ensure_constraints(tx):
# Unique model names
tx.run("CREATE CONSTRAINT model_name_unique IF NOT EXISTS "
"FOR (m:Model) REQUIRE m.name IS UNIQUE")
def load_chunk_by_type(tx, rows: List[Dict[str, str]], rel_type: str):
"""
Insert a chunk of rows having the same relationship type.
"""
query = f"""
UNWIND $rows AS row
MERGE (a:Model {{name: row.from_model}})
MERGE (b:Model {{name: row.to_model}})
MERGE (a)-[r:{rel_type}]->(b)
ON CREATE SET r.association_type = row.association_type
ON MATCH SET r.association_type = coalesce(r.association_type, row.association_type)
"""
tx.run(query, rows=rows)
def chunked(iterable, size):
buf = []
for it in iterable:
buf.append(it)
if len(buf) >= size:
yield buf
buf = []
if buf:
yield buf
def main():
parser = argparse.ArgumentParser()
parser.add_argument("csv_path", help="Path to associations CSV")
parser.add_argument("--uri", default=os.getenv("NEO4J_URI", "neo4j://localhost:7687"))
parser.add_argument("--user", default=os.getenv("NEO4J_USER", "neo4j"))
parser.add_argument("--password", default=os.getenv("NEO4J_PASSWORD", "neo4j"))
parser.add_argument("--batch", type=int, default=1000, help="Batch size per write")
args = parser.parse_args()
rows = parse_csv(args.csv_path)
# Group rows per relationship type to allow typed relationships in Cypher
grouped: Dict[str, List[Dict[str, str]]] = {}
for r in rows:
grouped.setdefault(r["rel_type"], []).append(r)
driver = GraphDatabase.driver(args.uri, auth=(args.user, args.password))
try:
with driver.session() as session:
session.execute_write(ensure_constraints)
total = 0
for rel_type, rel_rows in grouped.items():
for ch in chunked(rel_rows, args.batch):
session.execute_write(load_chunk_by_type, ch, rel_type)
total += len(ch)
print(f"Done. Inserted/merged {len({k: len(v) for k,v in grouped.items()})} relationship groups, {total} rows.")
except ServiceUnavailable as e:
print("Neo4j service unavailable. Check URI/credentials or that Neo4j is running.", file=sys.stderr)
raise e
finally:
driver.close()
if __name__ == "__main__":
main()
pythonスクリプトを実行しGUI上でCypherクエリーを投げるとグラフを描画できます。
export NEO4J_URI="neo4j://localhost:7687"
export NEO4J_USER="neo4j"
export NEO4J_PASSWORD="password"
python neo4j_import.py model_relations.csv
MATCH (n) RETURN n
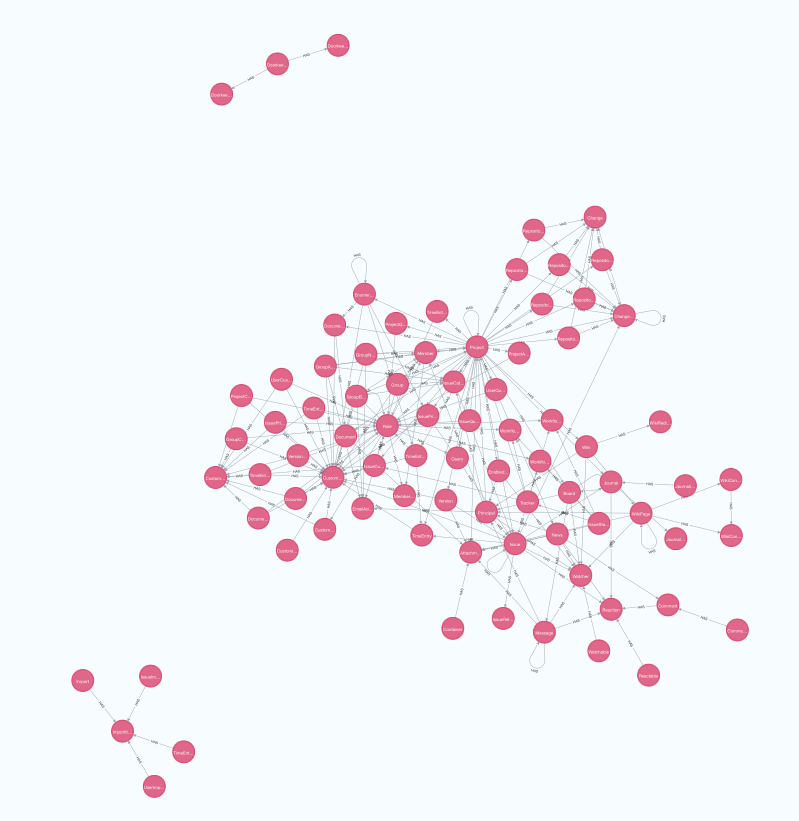
ちょっとうじゃうじゃいすぎですが、他と関係が独立している部分はわかりやすく描画されています。

Feature to Modelを追加
モデルをグルーピングして同一Featureにまとめると良いだろうという仮定があるのでFeature to Modelもインポートします。
feature,model
Feature_1,Doorkeeper::AccessGrant
Feature_1,Doorkeeper::AccessToken
Feature_1,Doorkeeper::Application
Feature_2,IssueStatus
Feature_2,Tracker
後略
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Import feature->model pairs from a CSV into Neo4j.
CSV columns:
feature,model
Schema created/used:
(:Feature {name: <feature>})
(:Model {name: <model>}) # 既存スキーマがあれば再利用
(:Feature)-[:INCLUDES]->(:Model)
- 冪等: MERGE を使うので同じCSVを何度流しても重複しません
- 速度: バッチ書き込み(--batch オプション)対応
- 事前に Model ノードが無くても自動で作成されます
Usage:
export NEO4J_URI="neo4j://localhost:7687"
export NEO4J_USER="neo4j"
export NEO4J_PASSWORD="password"
python import_feature_model.py path/to/feature_model.csv
Options:
--rel-type INCLUDES # リレーションタイプ名を変更したい場合
--batch 1000 # バッチサイズ
"""
import os
import csv
import argparse
from typing import List, Dict, Tuple, Iterable
from neo4j import GraphDatabase
from neo4j.exceptions import ServiceUnavailable
def parse_csv(csv_path: str) -> List[Dict[str, str]]:
rows: List[Dict[str, str]] = []
with open(csv_path, "r", encoding="utf-8-sig", newline="") as f:
reader = csv.DictReader(f)
# ヘッダは feature,model を想定
for i, row in enumerate(reader, start=2):
feat = (row.get("feature") or "").strip()
model = (row.get("model") or "").strip()
if not feat or not model:
# 空行や欠損はスキップ
continue
rows.append({"feature": feat, "model": model})
return rows
def dedup(rows: Iterable[Dict[str, str]]) -> List[Dict[str, str]]:
seen: set[Tuple[str, str]] = set()
out: List[Dict[str, str]] = []
for r in rows:
key = (r["feature"], r["model"])
if key in seen:
continue
seen.add(key)
out.append(r)
return out
def ensure_constraints(tx):
# 一意制約(存在しなければ作成)
tx.run("CREATE CONSTRAINT feature_name_unique IF NOT EXISTS "
"FOR (f:Feature) REQUIRE f.name IS UNIQUE")
tx.run("CREATE CONSTRAINT model_name_unique IF NOT EXISTS "
"FOR (m:Model) REQUIRE m.name IS UNIQUE")
def write_batch(tx, batch_rows: List[Dict[str, str]], rel_type: str):
query = f"""
UNWIND $rows AS row
MERGE (f:Feature {{name: row.feature}})
MERGE (m:Model {{name: row.model}})
MERGE (f)-[r:{rel_type}]->(m)
RETURN count(r) as created_or_merged
"""
tx.run(query, rows=batch_rows)
def chunked(items: List[Dict[str, str]], size: int):
for i in range(0, len(items), size):
yield items[i:i+size]
def main():
parser = argparse.ArgumentParser()
parser.add_argument("csv_path", help="Path to feature_model.csv (feature,model)")
parser.add_argument("--uri", default=os.getenv("NEO4J_URI", "neo4j://localhost:7687"))
parser.add_argument("--user", default=os.getenv("NEO4J_USER", "neo4j"))
parser.add_argument("--password", default=os.getenv("NEO4J_PASSWORD", "neo4j"))
parser.add_argument("--rel-type", default="INCLUDES",
help="Relationship type name (default: INCLUDES)")
parser.add_argument("--batch", type=int, default=1000, help="Write batch size")
args = parser.parse_args()
rows = dedup(parse_csv(args.csv_path))
if not rows:
print("No rows to import. Check the CSV content/headers (feature,model).")
return
driver = GraphDatabase.driver(args.uri, auth=(args.user, args.password))
try:
with driver.session() as session:
# 制約作成(存在すればスキップされる)
session.execute_write(ensure_constraints)
total = 0
for ch in chunked(rows, args.batch):
session.execute_write(write_batch, ch, args.rel_type)
total += len(ch)
print(f"Done. Upserted {total} (Feature)-[:{args.rel_type}]->(Model) pairs.")
except ServiceUnavailable as e:
print("Neo4j service unavailable. Check URI/credentials or that Neo4j is running.")
raise e
finally:
driver.close()
if __name__ == "__main__":
main()
実行するとModelとは別にFeatureもインポートされます。
python import_feature_model.py feature_model.csv

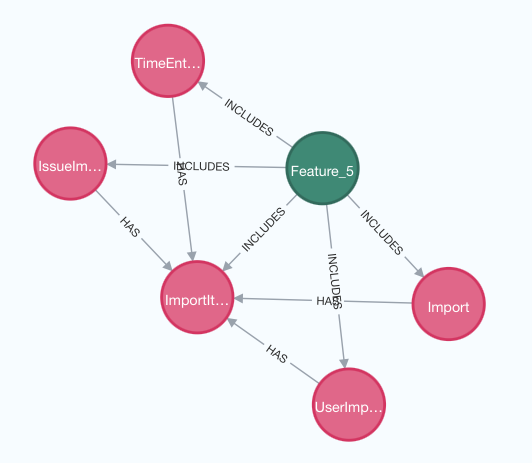
ごちゃごちゃしているので同一Featureに属しているModel同士のRelationは削除して可視化します。
MATCH (m1:Model)-[r:HAS]->(m2:Model)
WHERE EXISTS {
MATCH (f:Feature)-[:INCLUDES]->(m1)
MATCH (f)-[:INCLUDES]->(m2)
}
DELETE r;

少し見やすくなりましたね。
辺が集中しているモデルへの辺を削る

データをふむふむしているとRoleへの辺が集中していることがわかります。モデルのクラスタリングでは事前にuser軸を消していますが、Redmineはuser => role => 各モデルの部分があったので不十分であったということですね。
package by featureを決める上でRoleはユーザーよりの概念でノイズになるのでRoleへの辺は消します。
Roleを消した上でモデルのグルーピングを再度仮定。
Detected communities (Louvain):
Community 1: Doorkeeper::AccessGrant, Doorkeeper::AccessToken, Doorkeeper::Application
Community 2: Attachment, Container, Issue, IssueRelation, IssueStatus, Journal, JournalDetail, Journalized, Tracker, Version, WorkflowPermission, WorkflowRule, WorkflowTransition
Community 3: Board, Comment, Commented, EnabledModule, Message, News, Principal, Reactable, Reaction, Watchable, Watcher, Wiki, WikiContent, WikiContentVersion, WikiPage, WikiRedirect
Community 4: Change, Changeset, IssueQuery, Project, ProjectAdminQuery, ProjectQuery, Query, Repository, Repository::Bazaar, Repository::Cvs, Repository::Filesystem, Repository::Git, Repository::Mercurial, Repository::Subversion, TimeEntryQuery, UserQuery
Community 5: Import, ImportItem, IssueImport, TimeEntryImport, UserImport
Community 6: EmailAddress, Group, GroupAnonymous, GroupBuiltin, GroupNonMember, IssueCategory, Member, MemberRole
Community 7: CustomField, CustomFieldEnumeration, CustomValue, Customized, Document, DocumentCategory, DocumentCategoryCustomField, DocumentCustomField, Enumeration, GroupCustomField, IssueCustomField, IssuePriority, IssuePriorityCustomField, ProjectCustomField, TimeEntry, TimeEntryActivity, TimeEntryActivityCustomField, TimeEntryCustomField, UserCustomField, VersionCustomField
可視化するとこんな感じ。

だいぶ辺が減って見やすくなりましたが、Projectが集積モデルで区分けが難しくなっています。

ユーザー軸ではなく機能軸側なので本来は削る側ではないのですが、ここはProjectはグローバルの概念として各Featureに入れない方が全体の見通しが良くなるだろうと仮定して辺を削除します。
MATCH (m:Model {name:'Project'})-[r:HAS]-(:Model)
DELETE r;

かなりシンプルになりましたね。
FeatureへのリクエストはFeature APIを通すようにする
ソフトウェアを機能軸で分離する時、理想は機能ごとの関係がゼロになることです。残念ながら現状は機能Aに属するモデルが機能Bに属するモデルと関係を持ってしまっています。
理想は理想としてあるものの、現実のアプリケーションとして必要なら無くすことはできません。影響範囲を最小化するためにはこのFeatureを跨いだModelの関係はFeature APIとしてセミPublic化します。
ここでいうAPIはWeb APIなどのPublicなAPIではなくアプリケーション内部のFeature同士のやり取りをするAPIです。Featureを跨いだModelの関係は直接呼んでしまうと内部APIのCallになり自由度が高すぎるため制御ができません。
Model a => Model bと関係がある時に、Model a => Feautre_B_API => Model bと必ずインターフェースを通すと自由度を制限できますし、Feature APIへのcallはモック化することで各Featureのテストを独立に実行できるメリットがあります。
Featureを跨いだモデルのRelationを削除し代わりにFeature APIを通すようにします。現実的にはModel a has_one/many Model b、Model b belongs_to Model aの時に、aからbを呼ぶこともbからaを呼ぶこともあるのですが、ここではaからb, hasの関係のcallのみあるとして可視化します。
// 一意制約(初回だけ作成されます)
CREATE CONSTRAINT feature_api_name_unique IF NOT EXISTS
FOR (n:Feature_API) REQUIRE n.name IS UNIQUE;
// ノード作成(存在しなければ作成、あれば再利用)
UNWIND ['Feature_2_API','Feature_3_API','Feature_4_API','Feature_6_API','Feature_7_API'] AS nm
MERGE (:Feature_API {name: nm});
UNWIND ['Feature_2','Feature_3','Feature_4','Feature_6','Feature_7'] AS featName
WITH featName, featName + '_API' AS apiName
MATCH (f:Feature {name: featName})
MERGE (api:Feature_API {name: apiName})
WITH f, api
MATCH (f)-[:INCLUDES]->(b:Model)
MATCH (a:Model)-[h:HAS]->(b)
WHERE a <> b
WITH DISTINCT a, api, b, h
MERGE (a)-[:CALL]->(api)
MERGE (api)-[:CALL]->(b)
WITH DISTINCT h
DELETE h;
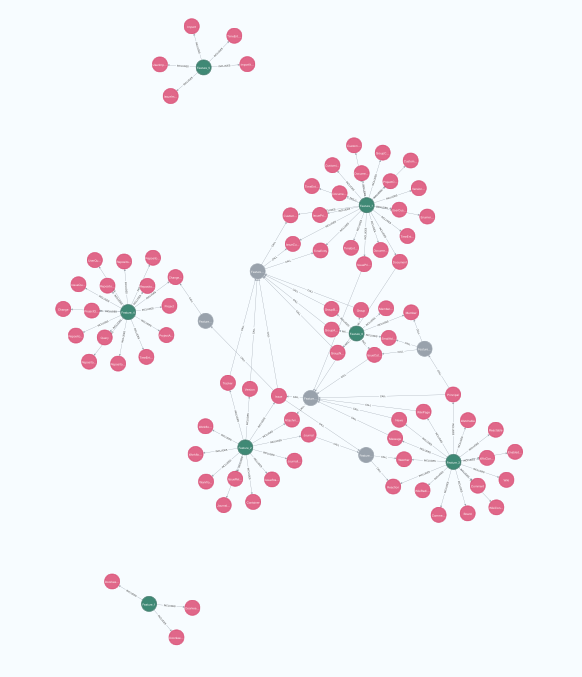
だいぶ綺麗になりましたね。
最後に: 可視化結果をベースにアーキテクチャを見直す
これで可視化としては以上です。これをベースに色々と構成を悩み続けるのが実際の運用なのかなと。
Feature APIへの辺の総数がより最小になる構成を見つけられればfeatureの独立性が上がりアーキテクチャとしてはより良くなります。
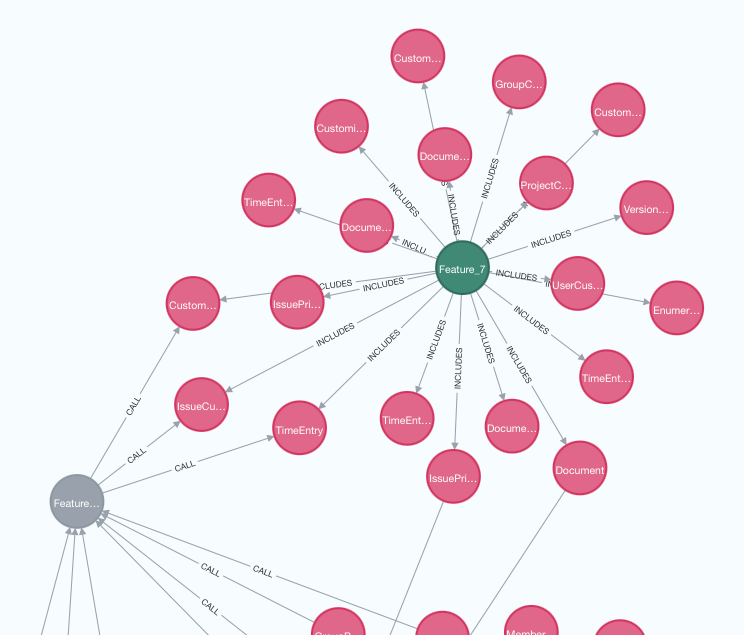
例えばFeature 7はFeature APIへのcallが多すぎます。CustomValueはProjectと同様にグローバルの概念であると割り切った方が全体のコードの見通しが良くなるだろうとするのも一つの案ですね。
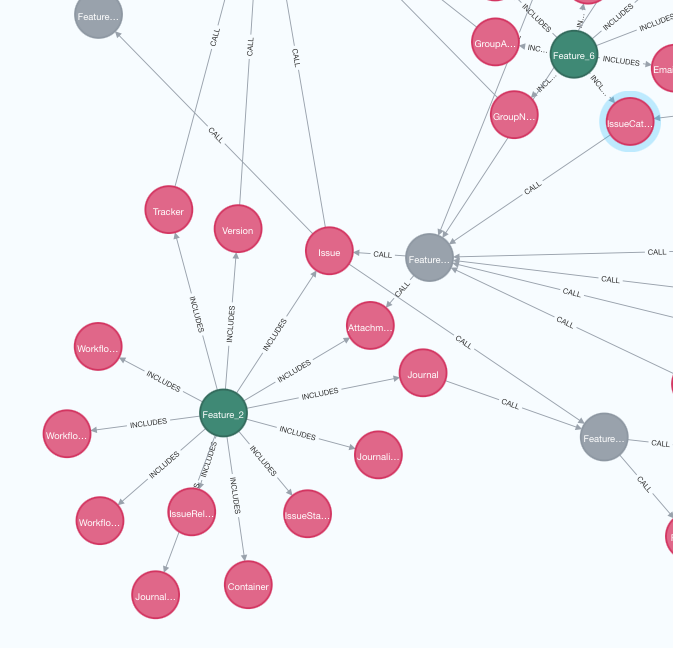
例えばFeature 2のAPI callを見ていくとIssueとIssue Categoryが別Featureに属していることがわかります。この2つのモデルを同一FeatureにするとFeature APIへの辺の数が減ることもあれば増えることもあるかもしれません。
そういったことを悩み続けるのがアーキテクトとしての仕事の醍醐味ですかね。