Prometheusとは、オープンソースのメトリクスベースのモニタリングツールです。
特にweb系で商用の利用者も増えていて、RedHat Openshiftでも利用されているなど、期待の高さを感じます。Prometheusではさまざまな環境の可視化ができますが、VMware環境についての可視化については日本語の情報が検索できなかったため、vCenter環境を可視化するためのメモ書きとなります。
Prometheusとは
CNCF(オープンソース技術を支援するクラウド・ネイティブ・コンピューティング・ファウンデーション) にてホストされていたProjectですが、2018年8月に、k8sに次いで、Graduation Stageに入ったプロジェクトとなりました。
Graduationとは、コミュニティの広がり、コードコントリビューションの活性度、プロジェクトとしての組織力などで、成熟度が一定の段階に達した認められたものです。すなわち、CNCFがクラウドネイティブアプリケーションを開発する企業にとって、最も適したオープンソースの監視ツールのひとつに成長したと認定したものとなります。
入門Prometheusという書籍があるためこちらは非常に参考になりますが、この書籍の監修をした須田さんのスライドでも概要の紹介をしています。
個人的におもしろいなと思った項目を以下に羅列しておきますが、共通する特徴として感じるのは、メトリクスによるモニタリングにフォーカスして、よりシンプルに、よりスケールする、という思想で作られているということです。餅は餅屋ですね。
- モニタリングツールには、ログ、トレース、プロファイリング、メトリクスという4つのカテゴリーができるが、システムレベルの状況確認にはメトリクスの確認が必要になるとして、メトリクスにフォーカスしている。メトリクスによりシステムのパフォーマンスがわかる。
- プロファイルングとは、たとえばtcpdumpのような限られた時間で一部のコンテキストを残すという考えかた。
- トレーシングとは、イベントの一部だけを見るというサンプリングによって影響を確認。
- ロギングとは、イベントひとつひとつのコンテキストの一部を記録する。例えばデバッグログがあり、システムとしてはELKスタックなど。
- メトリクスとは、コンテキストを無視し、様々なタイプのイベントの集計を時系列で管理する。コンテキストの情報を排除することで、必要なデータ量と処理が合理的になる。
- パフォーマンスが高く、容易に実行可能。1秒に何百万ものサンプルを取り込むことができる。
- データモデルと高度なクエリ(PromQL)に対応し、ラベルに基づく集計をサポート。
- クラウドネイティブ環境のような対象が消えたり増えたりする環境では、静的な設定で対応することはむずかしいが、サービスディスカバリによりモニター対象を柔軟に見つけ、対応することができる。
- プルベースのシステムとなり、設定に基づいていつ何を監視するのかをきめる。
- データをローカルのカスタムデータベースに格納する。分散システムは信頼性を確保するのがむずかしいため、クラスタリングは行わない。結果、信頼性が上がり、実行が簡単になっている。 また、クラスタリングを使わないことで、コストも安価となる(1/5)
- 長期記憶ストレージは、リモート書き出し/書き込みのAPIがあるため、他のシステムにその役割を担わせる。
- Alertmanagerによりアラートを通知することができる。アラートの嵐にならないように関連するアラートをグルーピングしてまとめたり、チームごとに通知出力を設定したりできる。
- 各データセンタにひとつのPrometheusを配置することで信頼性の高い単純なシステムをつくることがえきるが、例えばグローバルレイテンシのような場合は、各データセンターのprometheusで集計されたメトリクスをプルするグローバルPrometheusを置くこともできる。
- 運用のモニタリング用に設計されているため、100%正確というよりも利用できることが重要としている。よって、例えばスクレイプが過負荷で失敗したときに、負荷が下がったとしてデータを再度取り戻すというと再び過負荷になるため、そのようなことは行わない。
- ダッシュボードはGrafanaを使うことが推奨。
Exporter および VMware Exporterとは
Prometheusはk8sやAmazon EKSのようなクラウド・ネイティブのメトリクスを取得できるのはもちろんですが、ほかにもさまざまな監視データを取得することができます。
Prometheusのアーキテクチャとして、Prometheusサーバーが監視対象にアクセスしてデータを収集するPull型アーキテクチャになっています。このデータ収集を行う対象として、exporterというのを利用し、監視対象ごとにこのexporterを用意することになります。
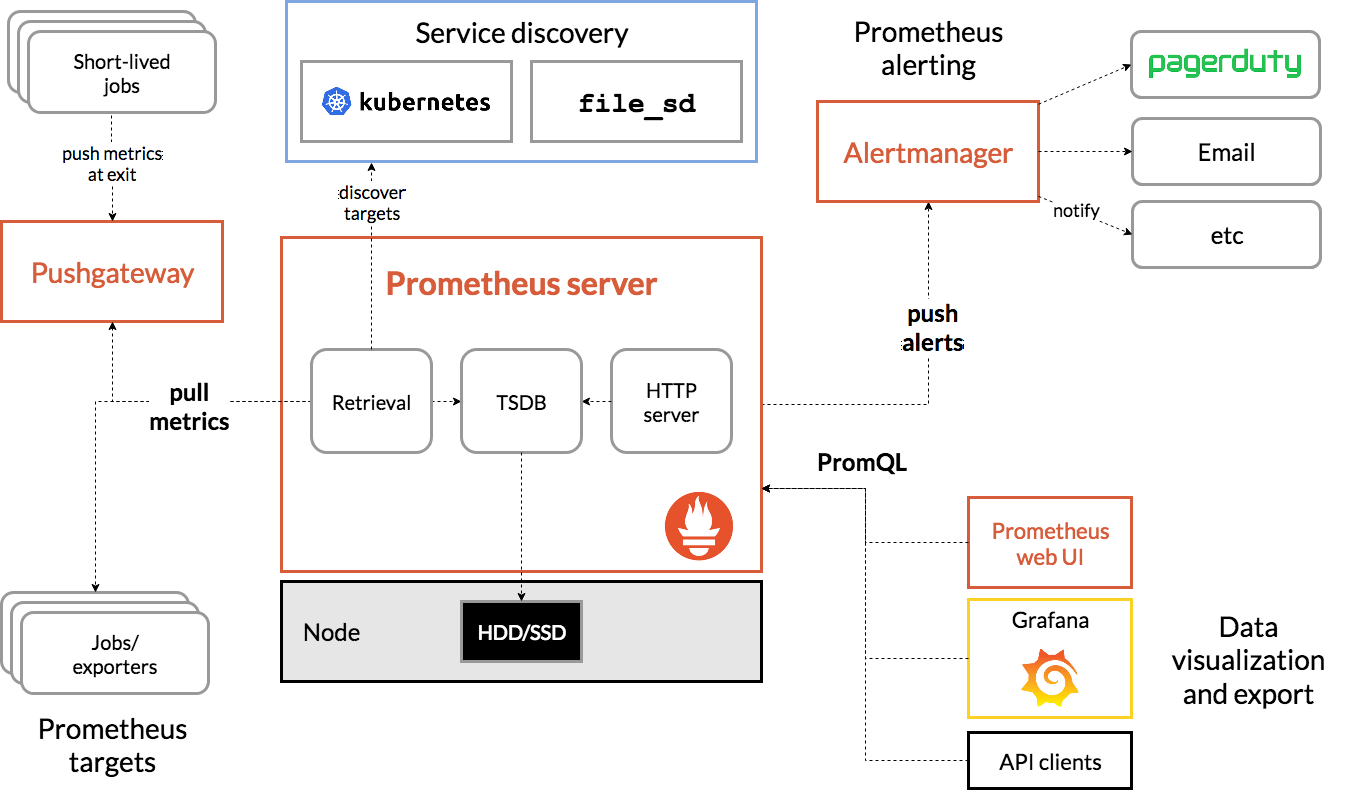
exporterの種類は、Prometheusプロジェクトが公式に開発に参加している公式のものもあれば、サードパーティによって開発されているものもあります。
共にPrometheusのドキュメントから確認することができて、IPMI exporterのようなハードウェアや、MemcachedのようなDB、HAProxy exporterやSNMP exporterでルータやスイッチなどネットワーク機器のメトリクスも収集することができたりと、さまざまなexporterが存在します。また、自らexporterを開発するということもできます。
ただし、現時点でVMwareのESXiやvCenter関連のexporterはこの一覧では確認することが出来ません。
すこし調べると、サイトによっては、vcenter exportersはどれもメンテナンスされておらず、telegrafが推奨というコメントもあります。
VMwareの見解としてどのようなものなのかわからないですが、Prometheusによりヘテロな環境の可視化をしたり、シンプルなメトリック管理をする場合は、vCenterも可視化対象としたい場合もあるのではとも思っています。
もし、公式のexporterがあるなどVMware社の見解をご存知であればおしえていただけるとありがたいです。
今回は、githubにあがっていた、こちらのvmware_exporterを使ってみました。
こちらは、Pythonベースのもので、https://github.com/rverchere/vmware_exporterからfolkしたものですが、元々のvmware_exporterはもうメンテナンスはしておらず、Pryor氏が現在はメンテナーとなっています。
vCenterからは、pyVmomiを利用し、vSphere API から情報をとってきているようです。
githubにあがっていただけのため他にもexporterがあるかもしれないですし、どのexporterが最適なのかまだわかりませんが、とりえあえずは、これを利用することで、vCenterからベーシックな仮想マシン、ホスト、データストアの基本的なメトリックスなどの情報が取得できるようになります。
Prometheusのインストール
Prometheus自体のインストールはいくつかの方法があります。
- OSのパッケージマネージャ経由でインストール
- Docker経由で実行
- Prometheusが公式にビルドして配布しているバイナリを利用
- 自分でソースコードからビルド
Prometheus自体のインストール検索すると色々でてくると思いますので、そちら参照ください。
例えば、
公式ガイドのFirst Step
Prometheus+GrafanaでKubernetesクラスターを監視する
さくらのナレッジ:「Prometheus」入門
私は、コンテナイメージと、CentOSに直接バイナリをDLしてインストールする方法を試してみましたが、コンテナはもちろん、バイナリの場合も非常に容易で、解凍して起動するだけで、9090のポートでアクセスできるようになります。
ただ、PrometheusのGUIは簡易なもののため、GUIは、Grafanaを利用することが推奨されています。
こちらも検索すると色々情報があります。
公式ガイド
Prometheus+GrafanaでKubernetesクラスターを監視する
ざっくり記載すると
# wget https://dl.grafana.com/oss/release/grafana-7.2.0-1.x86_64.rpm
# yum install grafana-7.2.0-1.x86_64.rpm
# systemctl start grafana-server
# systemctl status grafana-server -l
これで起動することで、
http://x.x.x.x:3000/login でアクセス可能となります。
デフォルトのusername/passwordは、admin/adminです。
そして、GUIで"Add data source"からPrometheusを追加することで可視化対象とすることができます。
こちらも非常に簡単ですね。
VMware exporterのインストール
Pythonでインストールする方法とコンテナを利用する方法があります。
コンテナを利用する場合は、
{VSPHERE_HOST}, {VSPHERE_USERNAME},{VSPHERE_PASSWORD}のパラメーターを渡してコンテナを起動するだけです。
docker run -it --rm -p 9272:9272 -e VSPHERE_USER=${VSPHERE_USERNAME} -e VSPHERE_PASSWORD=${VSPHERE_PASSWORD} -e VSPHERE_HOST=${VSPHERE_HOST} -e VSPHERE_IGNORE_SSL=True -e VSPHERE_SPECS_SIZE=2000 --name vmware_exporter pryorda/vmware_exporter
または、
直接インストールする場合は、pipを使えるようにしてから
でインストールをします。
設定対象をconfig.ymlに記載しますが、ここで各ホストから取得する対象を制限できます。
今回はシンプルに何も制限せず、とりあえずvCenterから取得するために以下のようにconfig.ymlを記載してます。
default:
vsphere_host: "x.x.x.x"
vsphere_user: "xxxx"
vsphere_password: "xxxx"
ignore_ssl: True
specs_size: 5000
fetch_custom_attributes: True
fetch_tags: True
fetch_alarms: True
collect_only:
vms: True
vmguests: True
datastores: True
hosts: True
snapshots: True
これで、起動することで、
$ vmware_exporter -c config.yml &
http://x.x.x.x:9272/metrics
で可視化対象のメトリックが見れるようになります。
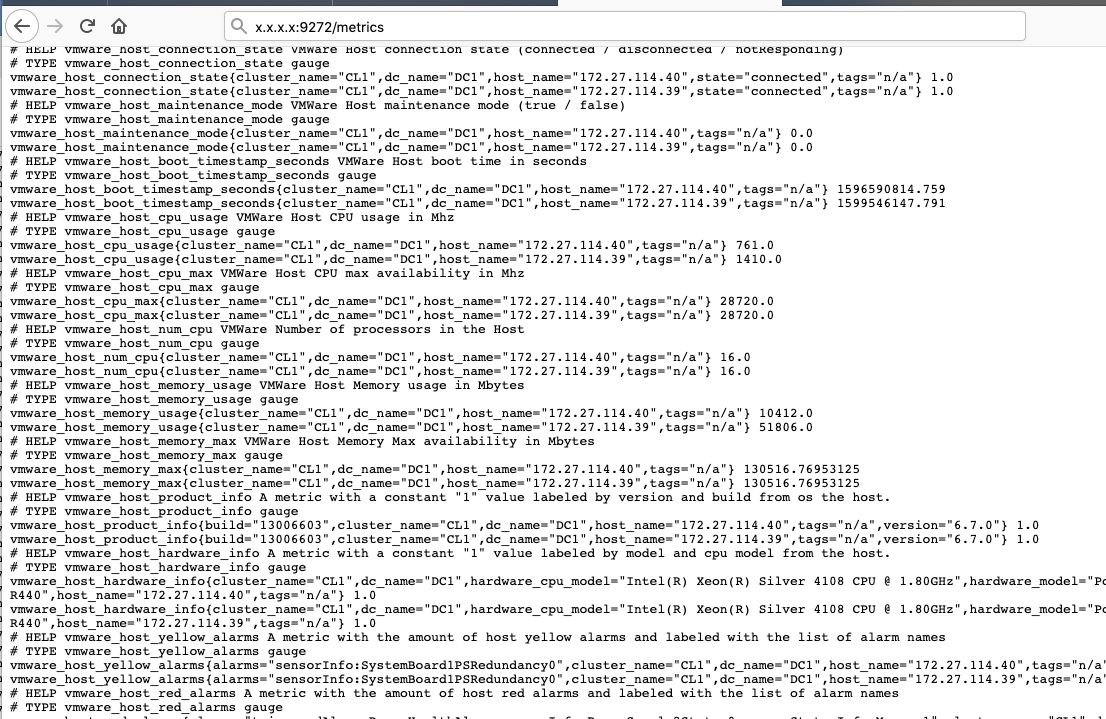
exporterとして可視化できることが確認できたため、これをPrometheusの監視対象とするため、targetでexporterを追加します。
/usr/local/prometheus-server
- job_name: 'vcenter'
static_configs:
- targets: ['localhost:9272']
これでPrometheusのGUIでStatus > Targets をみるとvcenterのexporterが"UP"となっていれば監視対象となっていることがわかります。
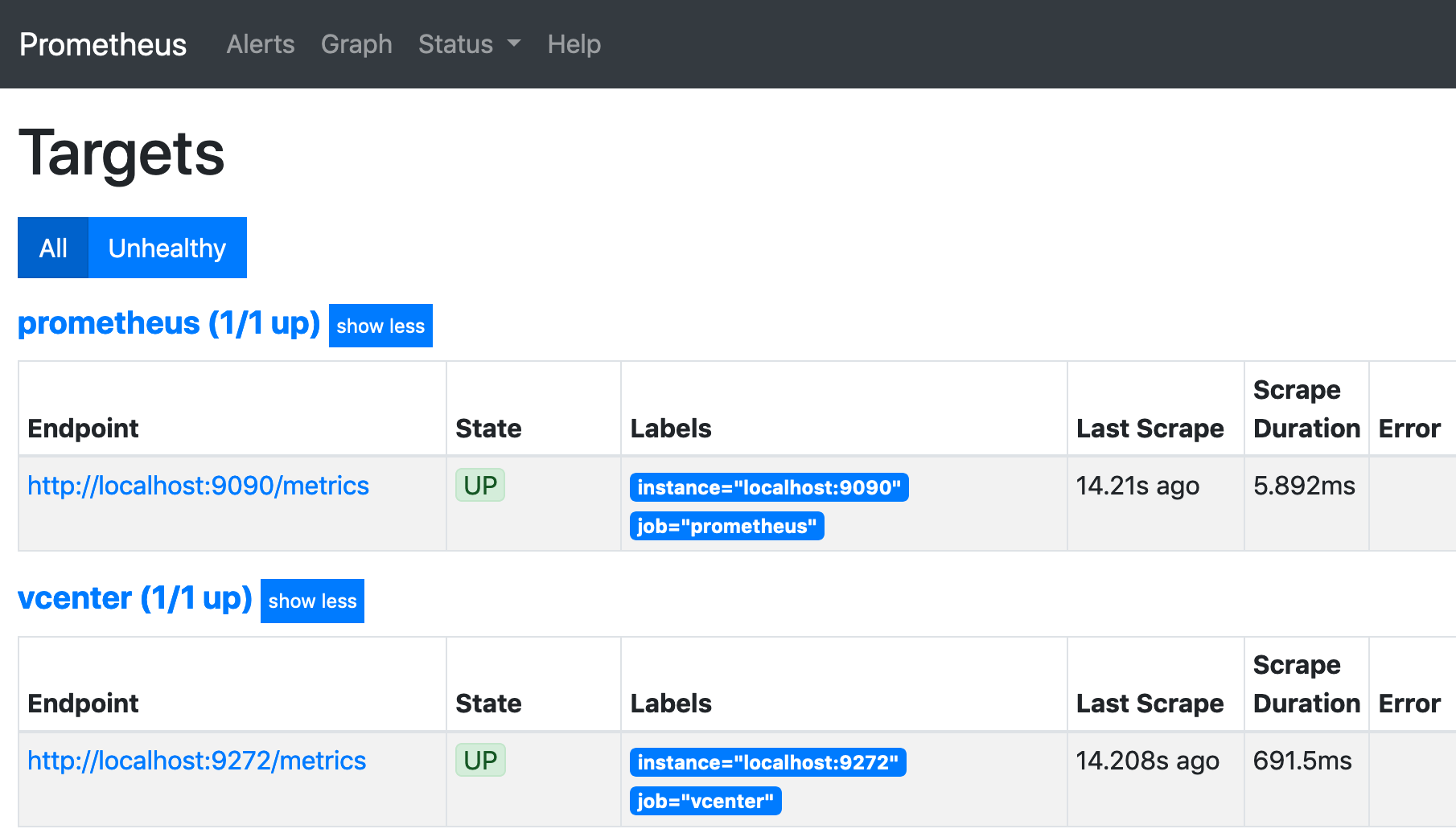
あとは、PrometheusまたはGrafanaのGUIでメトリックを確認することができます。
取得メトリックはhttp://x.x.x.x:9272/metrics から確認できますし、概要はこちらで記載されています。
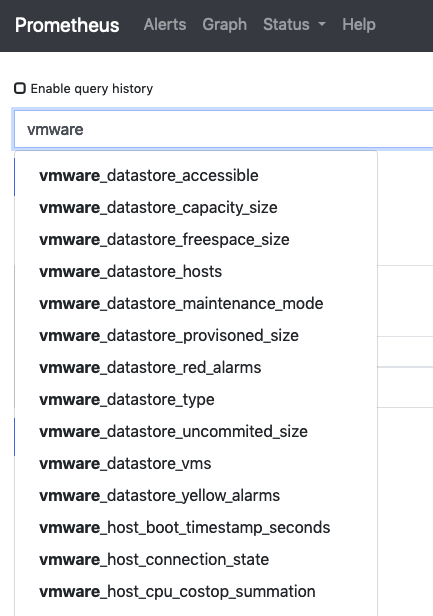
たとえばPrometheus GUIのGraphで"vmware"とするといろいろなメトリックの候補がでてくるのがわかります。
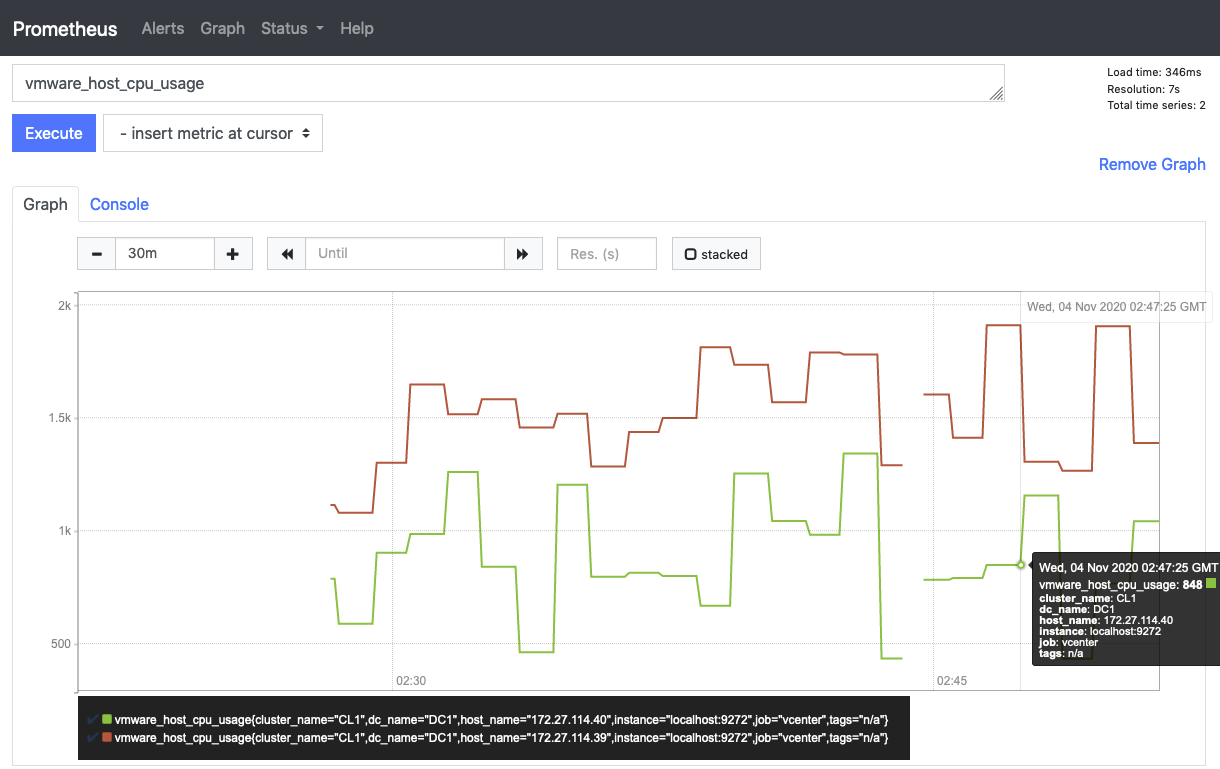
このなかで、例えば、VMware Host CPU usage in MHzを示している、vmware_host_cpu_usageを取得するとそのメトリックが取得できます。
GraphanaのGUIでもDashboardでそれぞれのMetricsで監視対象のメトリックを指定するだけで監視対象となります。
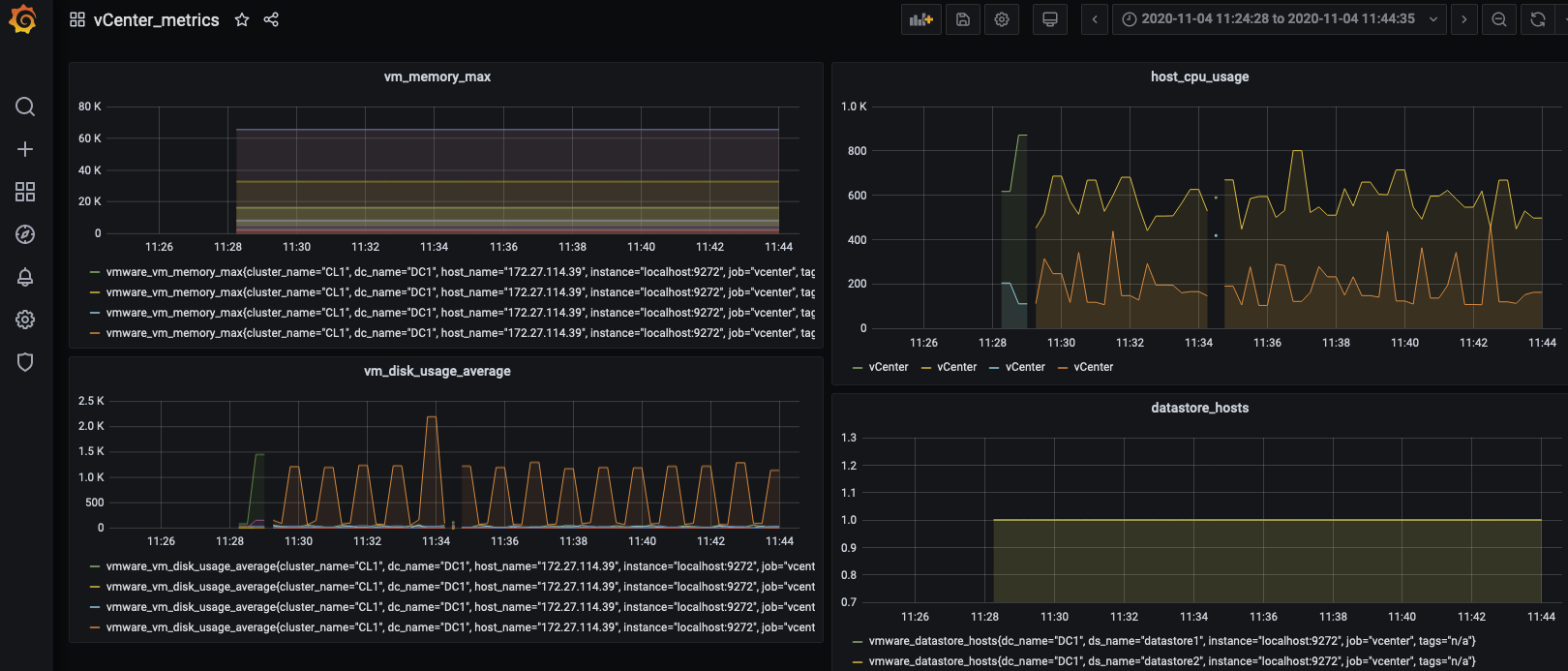
このように非常に容易にVMware ESX環境のメトリックもPrometheusで取得できることがわかりました。あとは通常のPrometheusの機能を利用することでアラートなどを定義することもできます。
参考
Prometheus公式ドキュメント(英語)
書籍:入門Prometheus
Prometheus+GrafanaでKubernetesクラスターを監視する
Github:vmware_exporter