初のAdvent calendarは最近触ってみたPrometheusという監視ツールの構築について書きます
みなさん、Webサイトの死活監視はされていますでしょうか?
「自分で構築できるの?」「SaaSと契約するほど大きなシステムじゃないんだけど・・・」「サーバを1から立てるのは辛い」などなど、私もハードルが高い機能の1つだと思っていました
が、DockerとPrometheusを組み合わせることで意外と簡単に外形監視の仕組みを作ることができるので、書いていこうと思います
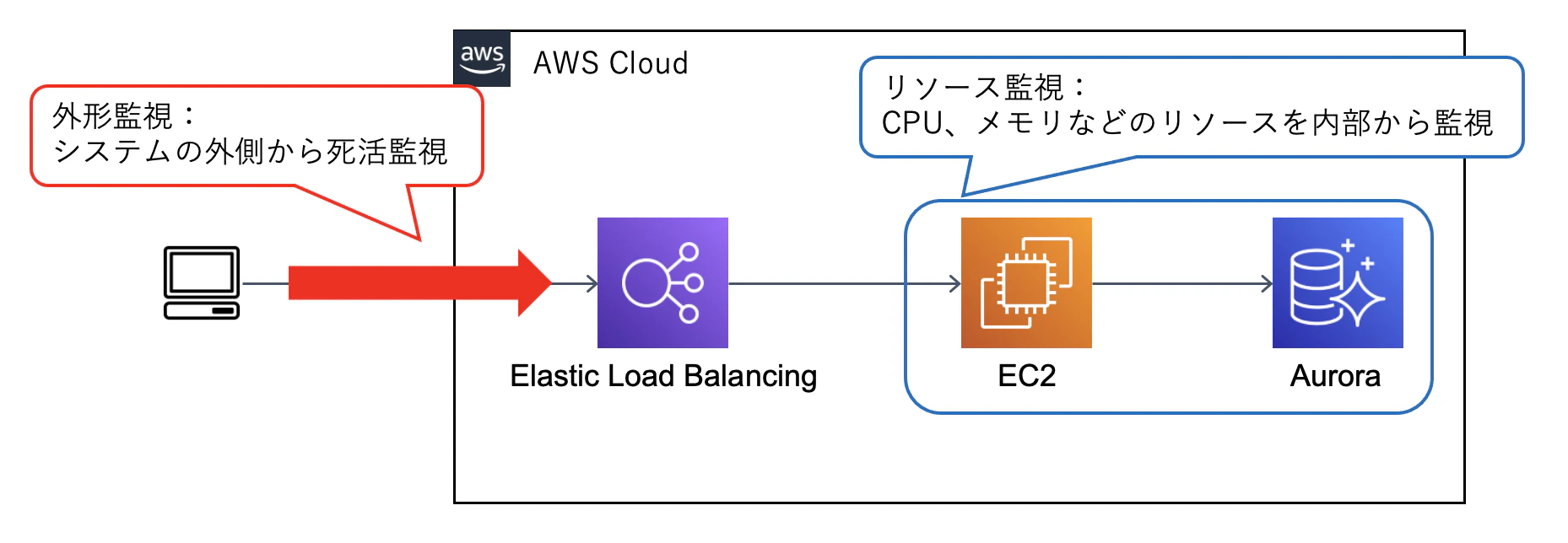
外形(URL)監視とは何か?
外形監視とは、WebサイトやAPIサーバが正常に動いているか?をHTTPアクセスで確認する監視方法です
「レスポンスが正常か?」「規定の秒数以内にレスポンスが返却されるか?」などを確認します
良いところとしては、ユーザと同じ方法でアクセスするため、ネットワークを含めてシステムまたはAPI全体の正常/異常を確認することが可能です
サーバのリソース(CPUやメモリなど)を内部から監視する方法と組み合わせて使うことが多いと思います
AWSのサービスを使っていますが、簡単に説明した図になります
背景
- Webシステムに対して外形監視をしたい
- SaaSもあるがシステムが大規模じゃない場合はオーバースペックだと感じた(大規模ならお金かけて使った方が良いのかもしれないけれど)
- 柔軟な選択ができるよう環境(開発端末・クラウドなど)に関係なく構築できるようにしたい
今回やること
- 監視ツールであるPrometheusを使って外形監視をする
- OSに寄らずに環境構築できるDocker+Prometheusで構築する
- 開発端末で起動する
- 異常を検知した場合、Slackに通知する
説明しないこと
ここでは書かないので、調べてみてください...
- ターミナルの操作方法
- Docker, docker-composeについて
環境
今回はMacでやりますが、Dockerを使っているので、windowsでもlinuxでも起動できます
- Mac : 10.15.5
- Docker : 19.03.8
- docker-compose : 1.25.5
使用したDockerイメージ
- prom/prometheus : 2.19.1
- prom/blackbox-exporter : 0.17.0
- prom/alertmanager : 0.21.0
フォルダ・ファイル構成
━ docker-compose.yml
┣ prometheus
┃ ┗ alert_roles.yml
┃ ┗ prometheus.yml
┣ blackbox_exporter
┃ ┗ config.yml
┗ alertmanager
┗ config.yml
docker-compose.ymlの作成
- prometheus:本体のイメージ
- blackbox_exporter:URL監視してくれるexporter(外部ライブラリ的なもの)
- alertmanager:アラートが発生した時にメッセージ通知をしてくれるexporter(今回はslack通知で使用する)
- 各々のポート番号とconfigファイルを設定していきます
version: '3'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
volumes:
- ./prometheus:/etc/prometheus
command: "--config.file=/etc/prometheus/prometheus.yaml"
ports:
- 9090:9090
restart: always
blackbox_exporter:
image: prom/blackbox-exporter:latest
volumes:
- ./blackbox_exporter/config.yml:/etc/blackbox_exporter/config.yml
alertmanager:
image: prom/alertmanager
container_name: alertmanager
volumes:
- ./alertmanager:/etc/alertmanager
command: "--config.file=/etc/alertmanager/config.yaml"
ports:
- 9093:9093
restart: always
blackbox_exporter
URL監視の設定をyml形式で記載していきます
modules:には確認したいプロトコルごとに設定を作っていきます(tcp、pop3、sshもデフォルトで用意されています)
今回はPOSTメソッドの設定としてhttp_post_2xx:を追加しています
headers:にはHTTPヘッダを設定することができます
設定できる内容についてはblackbox_exporterのConfigurationを参照してください
modules:
http_2xx:
prober: http
http:
http_post_2xx:
prober: http
http:
method: POST
headers:
xxx: yyyy
prometheus
prometheus本体で外形監視の設定を記載します
評価内容は``alert_roles.yml''に定義しています
global:
# prometheusがexporter等に情報を取りに行く間隔(今回はblackbox_exporter)
scrape_interval: 15s
# ruleの評価を行う間隔(今回はrule_filesで指定されているalert_roles.ymlが評価内容)
evaluation_interval: 15s
external_labels:
monitor: 'codelab-monitor'
rule_files:
- /etc/prometheus/alert_roles.yml
alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- alertmanager:9093
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets:
- prometheus:9090
# 1つの監視条件をjobという単位で扱う
- job_name: 'blackbox_http'
metrics_path: /probe
# blackbox_exporterのconfig.ymlで定義しているmoduleを指定
params:
module: [http_post_2xx]
static_configs:
# 監視対象のURLを指定
- targets:
- '[target_url]'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackbox_exporter:9115
# alertの定義
groups:
- name: blackbox_exporter
rules:
- alert: http_success
# 評価するメトリクスと条件
# probe_successの条件を"blackbox_http"のjobに適用しています
expr: probe_success{job='blackbox_http'} != 1
# 評価NGとするまでの継続時間(10秒間alert状態の場合NG)
for: 10s
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }}: http request not return 200"
description: "{{ $labels.instance }} http request not return 200 for more than 10 seconds."
alertmanager
alertmaneagerは通知を行います
今回はslackへの通知を設定しています
slackのwebhookは公式を参照ください
global:
# slackのwebhookURLを指定
slack_api_url: '[slack webhook url]'
smtp_smarthost: 'localhost:25'
smtp_require_tls: false
smtp_from: 'Alertmanager'
route:
receiver: 'test-route'
# グループ化の設定(アラート名)
group_by: '[alertname]'
# alertグループの通知の送信を最初に待機する時間
group_wait: 10s
# alertグループでの最小送信間隔(新しいアラート送信まで待機する時間)
group_interval: 5m
# 通知を再度送信するまで待機する時間
repeat_interval: 1h
receivers:
- name: 'test-route'
# slackのチャンネル名
slack_configs:
- channel: '#general'
# email(※slackには表示されなかった)
email_configs:
- to: "zzz@gmail.com"
dockerコンテナ起動
dockerコンテナを起動します
今回は複数コンテナを一度で上げるのにdocker-composeを使用します
$ docker-compose build
# "-d"オプションをつけることで、バックグラウンドで実行します
# オプションがないとターミナルを閉じた時にコンテナが停止してしまいます
$ docker-compose up -d
# コンテナの起動を確認
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ab4455256cff prom/prometheus "/bin/prometheus --c…" 5 days ago Up 5 days 0.0.0.0:9090->9090/tcp prometheus
830bf6475888 prom/alertmanager "/bin/alertmanager -…" 5 days ago Up 5 days 0.0.0.0:9093->9093/tcp alertmanager
b6fcd4f26f57 prom/blackbox-exporter:latest "/bin/blackbox_expor…" 5 days ago Up 5 days 9115/tcp prometheus_sample_blackbox_exporter_1
Prometheusのダッシュボードを確認
http://localhost:9090にアクセスする
実際の運用ではhttps、ポートフォワーディングなどに対応しますが、今回は開発端末なのでそのままにします
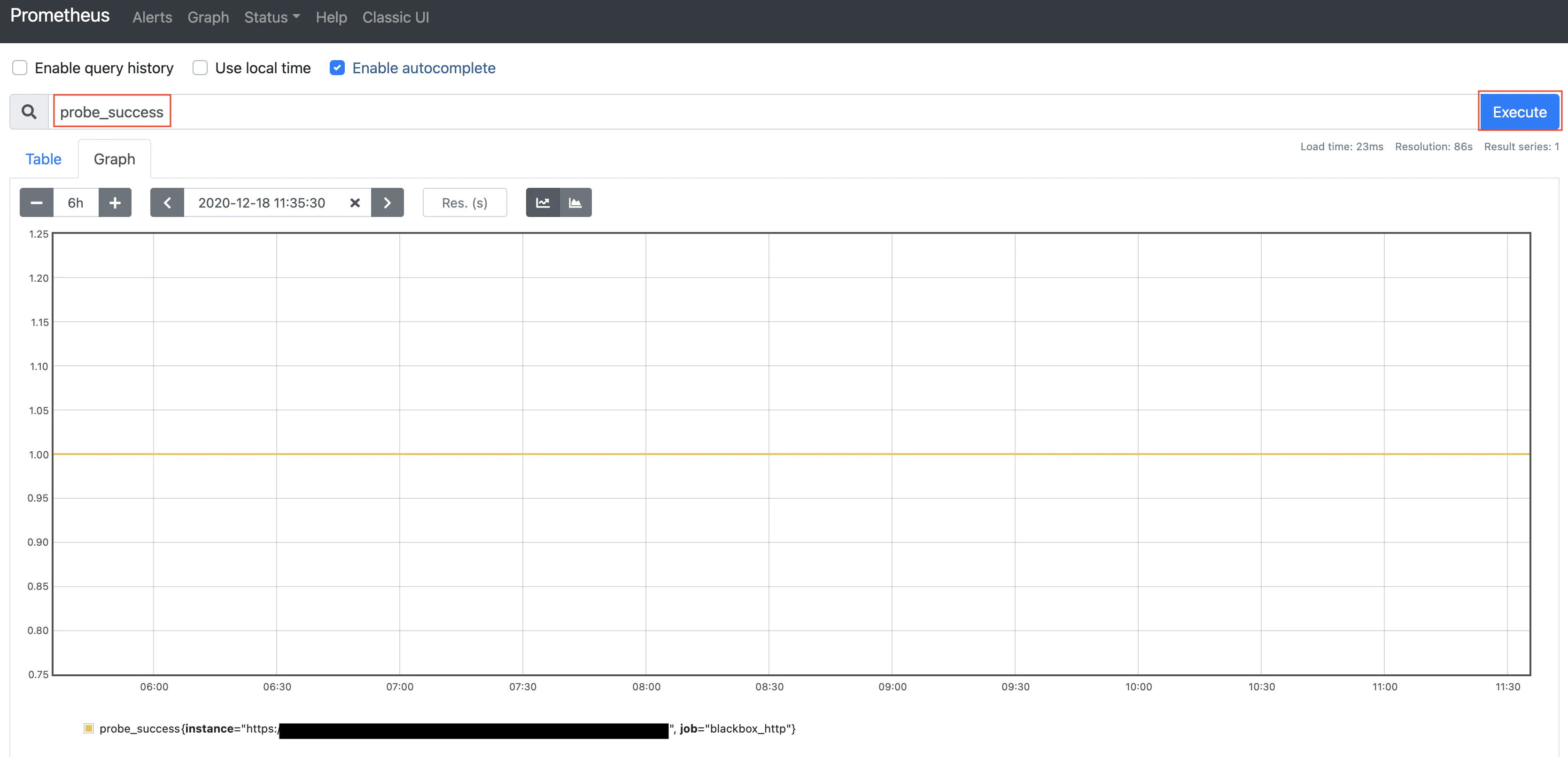
alert_roles.ymlで指定した評価メトリクスを入力し、executeをクリックすると評価結果をグラフで表示できます
今回はhttpリクエストが成功(200 OK)を評価していて、1.0であれば正常となります
メニューからAlertを選択するとアラート(通知)の状態を確認することができます
状況が色分けされていて、一目でどの評価がエラーとなっているか確認ができます

slack通知を確認する
監視対象のURLを存在しないURLに変更して、httpレスポンスが500系を返却するようにしてAlertの確認をします
httpリクエストが異常を返却するとAlertメニューの状況が赤く変化します

そして、slackにエラー発生していることが通知されます

今回はSlackというチャットサービスでしたが、チャットの通知に反応する習慣がない人などから「Slackに通知すると気づきにくい!もっと早く確実に気づきたい」という要望があれば、SaaSの電話コールサービスと繋げることでAlert発生時に電話をコールすることも可能です
通知することが大事ではなく、人間が認識する方法・可能性を考慮した設計にすることが大事だと思っています
おまけ
Prometheusの見た目は正直質素・・・だと思います(必要な機能は揃っているので十分な内容です)が、
「デザインがイケてるダッシュボードにしたい!」という方は、Grafanaと連携させるとかっこよくなると思います
Prometheusと同様にDockerイメージがあるので、docker-compose.ymlに追加することでGrafanaが起動します
興味がある方はぜひチャレンジしてみてはいかがでしょうか
(画像は公式のデモになります)
「監視を構築するのはかなり辛いなぁ・・・」という方は、
簡単に構築して設定をコード管理できるDocker+Prometheusで監視機能を構築してクリスマスを迎えてはいかがでしょうか?