え、何したの?
運用中のサービスに対するデータのモニタリング体制を構築して欲しいという実務課題を解決しました。
具体的には、、、
- 運用中のWebサービスのデータ分析環境が整っておらず、KPIモニタリングを行えていない。
- SQLでデータを分析する際にも本番DBに接続するしかない。
- 運用中のWebサービスのKPIモニタリング体制の整備
- 開発期間 42日間
- 運用費用は月5,000円以内 などなど
今回の実務経験は、応募者の中からクライアント様が選考を行い、最終的に絞り込んだ人数の中で同じ課題に取り組み、それぞれのソリューションからベストなものを選定していただくという採用方式でした。
で、何作ったの?
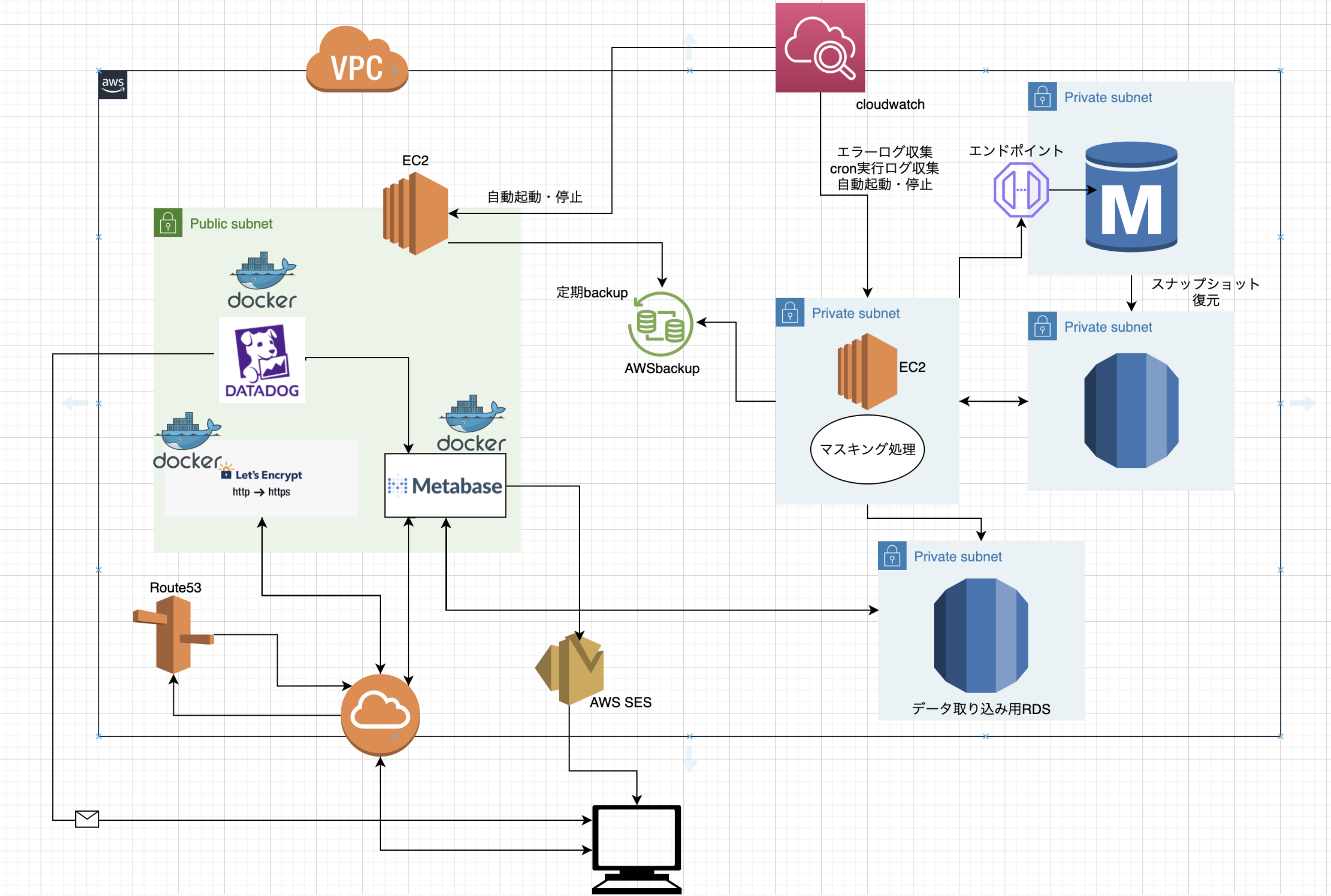
最終システム構成図
BIツールのトップ画面
BIツールのダッシュボード
実現した内容
- OSSのBIツールをAWSのEC2上に構築し分析DBと接続することで、KPIモニタリングの日次自動分析およびSQLによる探索的分析を行えるようにした
- 分析DBは本番のシステムに影響が出ないよう、本番DBのデータを日次同期した形で別途設置
- 分析DBはアルバイトの人等が触ることも考慮し、個人情報をマスキング処理
- BIツールに障害が発生した際にはメールで通知
- BIツールのバージョンアップやサーバー不具合時に再構築などに対応できるよう手順書を作成
使用した技術
- AWS(EC2、RDS、Rute53、AWSbackup、cloudwatch)
- cron
- シェルスクリプト
- SQL
- BIツール(Metabase)
- Docker
誰が作ったの?
- エンジニア未経験の文系大学出身の公務員 33歳
- 独学で学んだVBAによる業務改善がきっかけで、プログラミングと出会い、エンジニアを目指す
- 新卒後、VBAと出会う(32歳)まで仕事やプライベートでプログラミングに触れたことがない素人
- 体育会系のノリが好きで、パソコンとは縁もゆかりもない1児の父親
*プログラミング学習歴 *
プログラミングスクールを6ヶ月間オンライン通学(Ruby,Git,HTML,CSS,JavaScript等)
どこから作ったの?
はじめから自分で考えて作りました。具体的には、、、
- クライアントに対するヒアリング、ソリューション定義、提案書作成
- タスクばらし・ガントチャート作成
- 開発
- 監視体制の構築(ログ出力、アラート発信)
- 検証・テスト
- 運用
- 見積もり、クライアントへのプレゼン
クライアントから必要事項を聴取し、要件を満たすBIツールの選定から開発、実装まで全ての工程を行い、ソリューションを提案して、実際に採用していただきました。
なんでこんなことしたの?
エンジニアになりたいと思っているからです。
プログラミングスクールを卒業してから、約1ヶ月間転職活動を行うも、そこで自分に足りないものが何なのかが見えてきました。
それは、自走力があるのか否か証明できるものがないということでした。
スクールで学んだことしかできない(言われたことしかできない)人間ではなく、自走して課題を解決できる人間であることを少しでも証明したいと思ったため、今回の実務案件に挑戦させていただきました。
結果、どうなったの?
ありがたいことに、選考で選ばれた5名の候補者の中から私が提案したソリューションを採用していただきました。
課題解決への道
今回のソリューション提案までに、自分自身が意識したこと、苦労したこと等を各フェーズでピックアップしながら説明していきます。
クライアントからの聴取〜要件定義
クライアントが抱えている問題点を洗い出すため、ヒアリングを行いました。
この時に私が意識したことは、
- 機能要件と非機能要件を明確に区別すること
- 実際に運用するユーザーは誰で、どのレベルに合わせたものを作るべきなのかの確認
- 何が必要で、何が不要なのか
- 課題解決に向けて、問題をなるべく細分化してクライアントの真意を汲み取ること
これらの点を意識しながら、次のような要件定義を行いました。
要件定義
機能要件
- データベースに直接アクセスできる
- SQLを自由に叩ける
- モニタリング指標の各項目が数字として表示される
- モニタリング指標の各項目がグラフ化して見ることができる
- モニタリング指標の各項目を自由に変更できる
- ユーザー管理機能(アクセス権限の設定)
非機能要件
- 個人情報は閲覧できない
- 読み込み専用にする
- 本番DBに負荷がかからない
- インターフェイスはデザイン崩れしない
- 画面は3秒以内に表示できるようにする
- 指定されたユーザーのみ、ユーザー管理を自由に行えるようにする
- 死活監視:モニタリングサービスが落ちたら検知できる
- エラー監視:エラーが発生したら検知できる
これらの要件定義をもとにまずは、必要なBIツールの選定から行うことにしました。
BIツールの選定
データ分析基盤については、
- 実際に自分で開発する
- 既存のツールを使用する
という2つの選択肢があったのですが、開発期間とクライアントが求めている要件、そして自分のスキル面を考慮し、「既存のツールを使用する」という選択をしました。また、ツールを選定する上で、優先すべき事項として
- クライアントが求めている機能要件と非機能要件を満たしていること
- 無料であること
- 非エンジニアが操作しても分かりやすいこと
という基準をもとに、ツールの選定を行い、Metabaseを選定することにしました。
主な理由は
-
クライアントが求めている機能要件を全て満たしている
-
SQLアドホック分析可能、直感的なデータ分析
qiita記事(記事は少し古いですが) -
mysqlデータソースに対応
metabase公式 -
導入価格無料
metabase公式
といった感じです。
比較検討したBIツールと不採用理由は、以下のとおりです。
**Microsoft Power Bi Desktop **
mac向きではない、ユーザーごとの月額費用がかかる
google データポータル
SQLを使用したアドホック分析ができない
**Kibana **
利用者ごとのダッシュボードを分けることができない
ユーザ管理機能が不十分
以下は費用が高額で、今回のソリューションから外しました。
**Tableau(タブロー) **
Domo(ドーモ)
**Looker(ルッカー) **
ツールの選定で学んだことと反省点
ツールの選定において、ネット上に溢れている記事や公式ドキュメントばかり眺めてしまい、実際に自分で触って、使ってみて、本当にクライアントの要件を満たすのか確認したのが、ツールを選定した後になってしまいました。
今回はきちんと要件を満たしたものになったのですが、これは非常に大きな失敗だと感じました。
ここで、失敗すると、ソリューション根本的な基盤が崩れ、1からやり直しになってしまう恐れがあるので、初歩的なことなのですが、ツール選定はきちんと検証しないといけないと感じました。
ガントチャートの作成
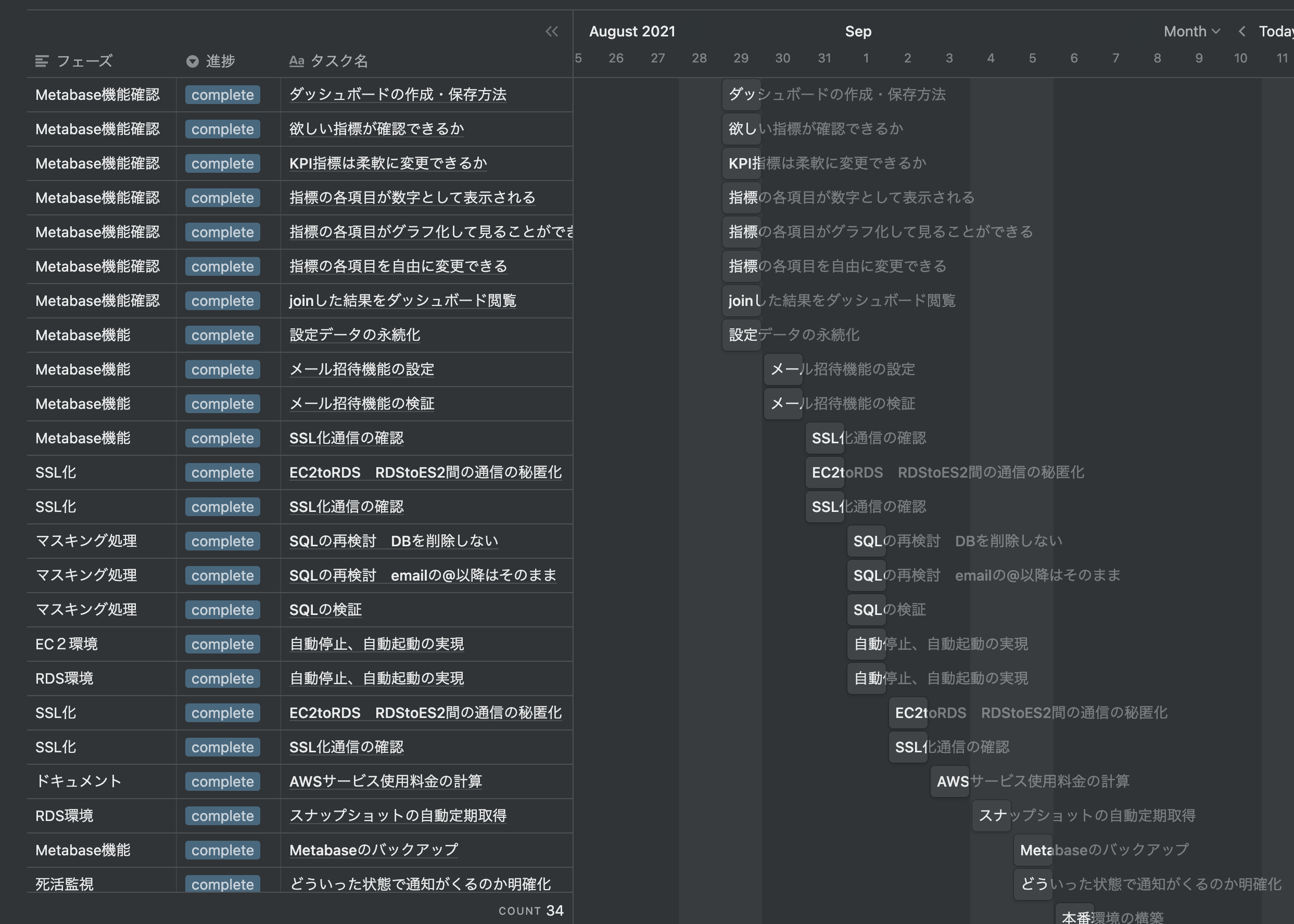
必要なタスクを定義し、ガントチャートも作りました。
下の図はガントチャートの一部ですが、実際に開発を進めると、なかなか計画どおりにいきませんでした。
途中で悪戦苦闘を繰り返して、ガントチャートの作り直しや工程の変更を加えました。
タスク管理で学んだこと
自分のスケジュール感のなさが露呈し、何度も計画を作り直す作業を行ってしまいました。
優先事項が何なのか、そのために必要な調査期間や実装期間の見積もりが甘く、経験値のなさが露呈し、せっかく作成したガントチャートの修正を繰り返すことが多かったです。
逆に、ここでしっかりとした計画を練り、きちんとしたタスクを構築できれば、ほぼ勝ったも同然じゃないかと思ってしまうくらい、大事なフェーズだと実体験を通じて学ぶことができました。
バッファも考慮して(2日くらいは余裕をもたせる)余裕を持ったガントチャートを作成しないといけないと反省しています。
この作業はどれくらいかかるのかを予測する能力・計画力もエンジニアには必要な能力だと感じることができました。
マスキング処理と日次更新
今回の開発で一番注力したのが、本番データに負荷をかけないで、個人情報のマスキングを行い、情報の保護をはかるマスキング処理です。
クライアントが一番気にしていたことが次の3点
-
本番環境に負荷をかけないこと
-
個人情報を保護すること
-
パブリックアクセスできる環境に本番データの生データを晒さないこと
であり、この要件を突破するのに私を始め、候補者の方々は苦戦しました。
結果、どうしたのかというと、、、
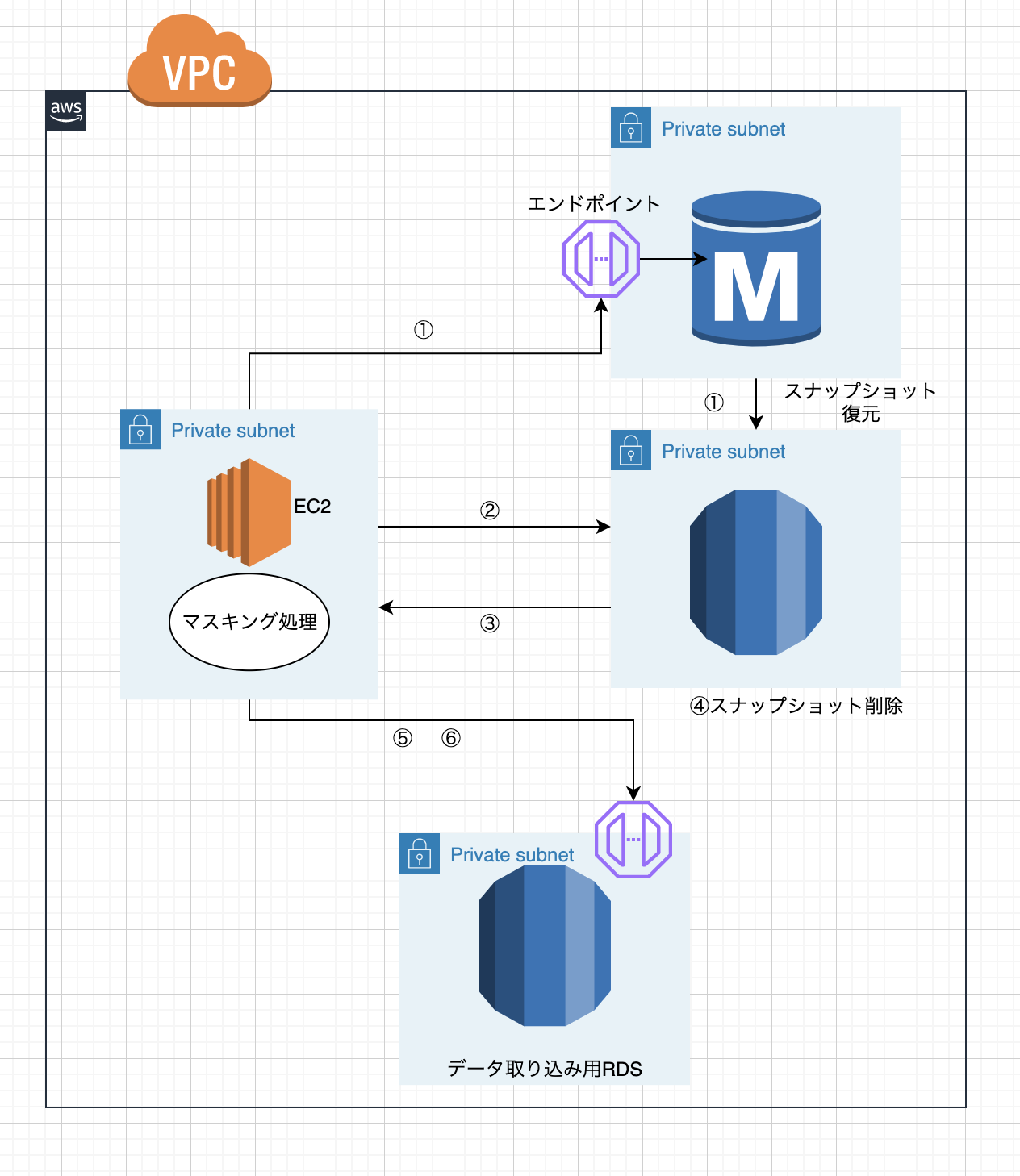
私が考えたマスキング手法と日次更新は次のような流れです。上記の図も参考にしてください。
① 本番RDSから自動スナップショット(最新のもの)の復元をAWSCLIを使って行う
② 復元したRDSに対して、マスキング用のSQLを流し、必要な個人情報のマスキングを行う
③ マスキングを行ったRDSからダンプファイルを取得する
④ 復元したスナップショットは削除する
⑤ データ取り込み用RDSの各テーブルにtruncateを実行して、テーブル内データをクリアにする
⑥ クリアにしたRDSに取得済みのダンプファイルを流し込む
少し補足します。
ダンプデータというのは、DBデータのフルコピーのようなもので、ここではRDSのデータをまるっとコピーしたものです。
⑤のダンプデータを流す前に、各テーブルにtruncateを実行する理由は日次で本番データからマスキングしたデータをBIツールと連携したRDSに更新させる際、そのまま取得したダンプデータを流すと、以前のデータがRDSに入っているためダンプデータが流せなくなるので、一度各テーブルをクリアにする必要があったためです。
マスキング処理と日次更新実現までの格闘
私のAWSに関する知識は入門レベルで、今回の案件をこなすまで、S3を使ったことがある程度のレベルでした。
最初は、何をしたらいいのか訳が分からず、適当にネット検索で色々課題解決方法探しました。
その結果、AWSGlueを使用したマスキング方法があると分かり、glueを使った突破方法を模索しました。
しかし、難易度が高く自分の技術力では、実現できそうにありませんでした。この間、1週間の時を費やし、納期も近づいてくる中で、かなり焦りました。
心が折れそうになったのですが、「絶対やり抜いてやる!」と心に誓い、一度紙に書いて思考を整理することにしました。
汚いですが、その時のメモの一部です。
紙に図などを書いて、思考を整理することで、課題を細分化して考えることができました。
すぐに結論を導き出そうとしていたことも悪いアプローチだったと思います。
マスキング処理と日次更新、大きな課題を2つに分けて一つづ突破方法を考えました。
日次更新について
マスキング処理と日次更新を分けて考え、まずは簡単そうだったので、日次更新から考えました。行いたい作業を日本語で整理すると、
- データを日々更新する作業、本番データからデータをまるっとコピーしてデータ取り込み用RDSに放り込む、この時に、すでに古いデータが入っているので、これを削除する
- 本番データをコピーする
- コピーデータを移行する
- コピーデータを移行する前に既存の古いデータを削除する
- この作業を定期実行する
この4つの大きな流れで日次更新は実現できそうでした。
マスキング処理について
マスキング処理については、行いたい作業を箇条書きにして一つ一つ課題を整理しました。
- 個人情報のマスキング処理
- どんな処理で行うか?
- どうやって実行するか?
- どのタイミングで、実行するか?
このような感じで、細かく課題を箇条書きにしていき、一つ一つについての突破方法を調べていきました。
そして、最終的には細分化した2つの課題を一つにまとめていったのです。
課題を細かくすることで、一つ一つのハードルが下がり、目標が明確になりました。
公式ドキュメントを中心にAWSサポートや技術ブログを参考に実装方法を探しました。
また、本番環境に負荷をかけない方法については、自分の知見が足りず、他の人からアドバイスをもらい、スナップショットを復元する作業がベストだと教えてもらいました。
復元した新しいRDSに対してマスキング処理を行い、ダンプデータを取得して、データ取り込み用RDSに渡す、その流れをAWSCLIを使って構築することで、処理を自動化できるという結論に至り、実装に向けて自分が何を勉強しないといけないのかが明確になりました。
実装に必要な学習で特に意識したことは、2点
- オプションも含めてきちんと意味を理解することを意識し、自分が分からないコードは使わない
- 納期を意識して、学習する内容を絞る
この点を意識して、実際に作成したコードは次のとおりです。(ソリューション提案時のもので、実際の導入コードとは若干異なっています。仕組みは同じです。)
# !/bin/bash -l
# 自動バックアップしている最新のスナップショット名を取得
SNAPSHOT_NAME=`/usr/local/bin/aws rds describe-db-snapshots --query "reverse(sort_by(DBSnapshots[?DBInstanceIdentifier=='xxxxxxxxxx'],&SnapshotCreateTime))[0].DBSnapshotIdentifier"`
# ダブルクォーテーションを削除
SNAPSHOT_NAME=`echo $SNAPSHOT_NAME | sed "s/\"//g"`
# スナップショットの復元 マスキング用RDSの作成
/usr/local/bin/aws rds --no-cli-pager restore-db-instance-from-db-snapshot \
--db-snapshot-identifier $SNAPSHOT_NAME \
--db-instance-identifier "xxxxxxxxxx" \
--availability-zone "ap-northeast-1a" \
--db-subnet-group-name "xxxxxxxxxxxx" \
--vpc-security-group-ids "xxxxxxxxxxxx" \
--db-parameter-group-name "aws-metabase-mysql57" \
--db-instance-class db.t3.micro \
--no-multi-az \
# RDSが作成するまで待機
/usr/local/bin/aws rds wait db-instance-available --db-instance-identifier "xxxxxxxxxxxxxxx"
# マスキング処理からxxxxxxxxxxxxxへのエクスポート
mysql --defaults-extra-file=/etc/xxxxxxxxxx.conf \
-h xxxxxxxxxxxxxxxxx.xxxxxxxxx.ap-northeast-1.rds.amazonaws.com -uroot \
dokugaku_engineer < ~/sql/masking_dayly_query.sql
sleep 5
mysqldump --defaults-extra-file=/etc/xxxxxxxxxx.conf \
-h xxxxxxxxxxxxxxxxx.xxxxxxxxx.ap-northeast-1.rds.amazonaws.com -uroot \
--set-gtid-purged=OFF dokugaku_engineer > ~/dump/dokugaku_dump.spl
sleep 5
mysql --defaults-extra-file=/etc/xxxxxxxxxxxxx.conf \
-h xxxxxxxxxxxxxxxxx.xxxxxxxxx.ap-northeast-1.rds.amazonaws.com -uroot \
-e'CREATE DATABASE IF NOT EXISTS xxxxxxxxxxxx;'
sleep 2
mysql --defaults-extra-file=/etc/xxxxxxxxxxxx.conf \
-h xxxxxxxxxxxxxxxxx.xxxxxxxxx.ap-northeast-1.rds.amazonaws.com -uroot \
dokugaku_engineer < ~/sql/truncate_dayly_query.sql
sleep 2
mysql --defaults-extra-file=/etc/xxxxxxxx.conf \
-h xxxxxxxxxxxxxxxxx.xxxxxxxxx.ap-northeast-1.rds.amazonaws.com -uroot \
dokugaku_engineer < ~/dump/dokugaku_dump.spl
sleep 5
# DBの削除
/usr/local/bin/aws rds delete-db-instance \
--db-instance-identifier "xxxxxxxxxxxxxxxxx" \
--skip-final-snapshot
このシェルスクリプトに書いたコードをcronを使用して定期実行させ、マスキング処理とデータの日次更新を実現させました。
マスキング処理用のSQLとtruncate処理をするSQLは別ファイルで作成し、ファイルを読み込ませています。
日次で流し込む本番データをマスキングするためのSQL
use dokugaku_engineer;
-- usernameのマスキング処理 `new_dummy_id`で記載
update users set username= replace(username, username, concat('masking_dummy_',id));
-- emailのマスキング処理 `new_dummy_email_id`で記載
update users set email= replace(email, left(email,instr(email,'@')- 1), concat('masking_dummy_email_',id));
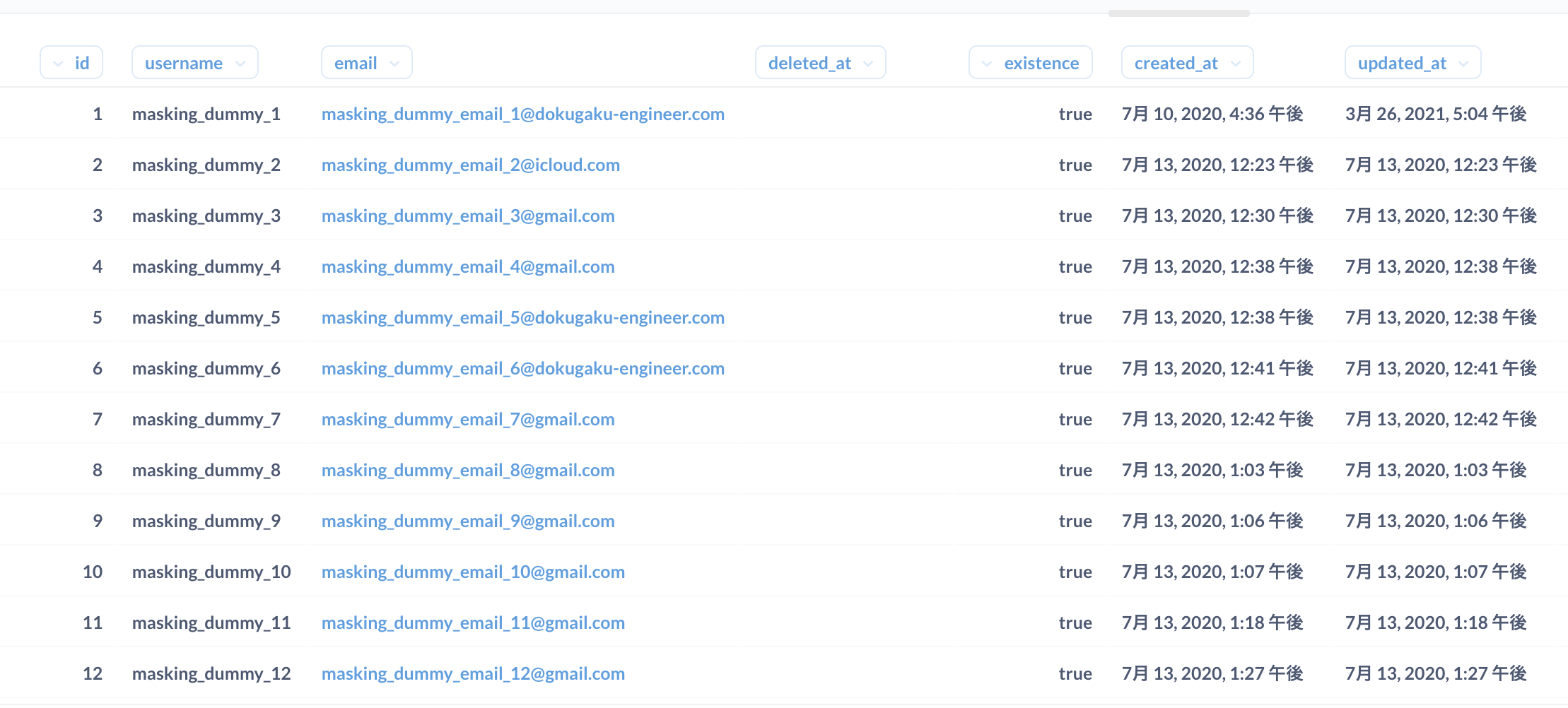
マスキングするユーザ名とemailについては、一意の値にしないといけなかったので、レコードに結びついているidカラムの値をマスキング文字列と結合させて、一意の値を実現させています。
これまで私は、RubyOnRailsを使ってデータベースを扱ったことしかなく、今回SQLを扱ったのは初めてであり、SQLの学習の必要性を感じるきっかけになりました。
ダンプファイルを流す前に以下のようなSQLを流してBIツールと連携しているRDSの既存データをクリアにしてます。
use dokugaku_engineer;
set FOREIGN_KEY_CHECKS = 0;
truncate table categories;
truncate table category_posts;
truncate table courses;
truncate table courses_olds;
truncate table learning_histories;
truncate table lectures;
truncate table lectures_olds;
truncate table lessons;
truncate table lessons_olds;
truncate table migrations;
truncate table parts;
truncate table parts_olds;
truncate table posts;
truncate table subscriptions;
truncate table taking_courses;
truncate table users;
set FOREIGN_KEY_CHECKS = 1;
マスキング化されたデータの中身
マスキング処理・日次更新で学んだこと
今回の案件で一番苦労したフェーズだったのですが、全体の実装イメージがついて、机上では実現可能だと考えていた処理も、実際に実装していくと、環境の違いや、パスの設定、オプションの設定等細かいところでエラーが発生し、なかなか実現させることに苦労してしまい、作業計画がのびのびになっていきました。
未知の領域に挑戦する際は、必ず余裕を持ったスケジュールを設定し、実際に個別の処理はうまくいくけど、全体を通して実行してみると、うまくいかなくなることがあることを念頭においた開発を行うことが大切であると学ぶことができました。
また、心が折れそうになっても、そこで諦めずに、やり抜くマインドもしっかり持っておかないといけないなと身の引き締まる思いでした。
さらに、課題を解決するためのアプローチの仕方についてもしっかり検討することが大切だと感じました。
というのも、候補者の中には、私よりも全然技術レベルが高い方がおり、Rubyを使った複雑なコードを記載して、マスキングを実装している方がいたのですが、私の簡単なコードで、要件を満たすことができ、より簡単にアプローチができる手法があるなら、無駄なことはしないで簡単な方を使うというエンジニアの考え方についても学ぶことができました。
シンプルに実現ができるものがあるのなら、よりシンプルなソリューションを選定し、課題解決に向けたアプローチを行うことが大切であると学ぶことができました。
セキュリティに対する考慮
先程のマスキング処理の項目で、クライアントが一番気にしていた個人情報の保護についてはEC2上で処理を実行させていました。
私は、そのEC2をプライベートサブネットに配置し、よりセキュリティを高めるシステム構成にしました。
個人情報の漏洩というのは、とてもリスクが大きく、何よりも優先しないといけないことだと思ったからです。
その分、コストが上がり、システムの導入に手間(プライベートサブネットに設置したEC2に多段でSSH接続して環境構築する手間)がかかることになりましたが、クライアントはセキュリティ重視の設計に納得していただけました。
閉域網でのEC2への接続方法や他のAWSリソースへの接続方法などは、今回とても勉強になったので別途記事を作成してみようと思います。
セキュリティ対策の重要性、プロなら責任を持つというマインドも大切にしていきたいと感じました。
監視体制の構築・運用に対する考慮
監視体制についても、初めて挑戦させていただきましたが、マスキング処理を行うEC2のcron実行ログとマスキング処理が記載されたシェルスクリプトのエラー出力をcloudwatchで確認できるようにし、BIツールが入ったDockerコンテナが停止した場合、アラートを発生させて、メールでユーザーに通知する仕組みを構築することができました。
また、運用がしやすいように、SSL化、BIツールはDockerを採用し、システム導入がしやすくすることも考慮するとともに、EC2のバックアップを定期でとることで、システムがダウンした際や、分析データが消えてしまっても直ちに復旧できる体制を構築しました。
監視体制・運用管理で学んだこと
納期の問題と実力不足で、エラー監視についてはメール通知まで実装させることができず、十分な実装ができませんでした。
今後の自分の課題として、監視体制の構築についても勉強し、より運用効率を上げるコードの書き方や導入方法が実現できるようにしていきたいです。
最後に
ここまでご覧いただき、ありがとうございました。
私ははっきり言って、技術レベルは大したレベルではありません。このソリューションについても、もっと良質なものがあると思います。
また、今回挑戦した案件はモダンな技術はほとんど使っておらず、枯れた技術と既存のツール、更にはAWSの知識があれば実装することができるもので、技術力を証明できるものではないと思います。
私は今回実務を通じて自分がカリキュラム通りの言われたことしかできないという人間ではなく、クライアントの課題を自走して解決まで持っていけるということを少しでも証明したいと思いました。
これまで情報系の学校を卒業したわけでもなく、パソコンとは無縁の人間だった私は、この歳になり、現職の業務改善のためにと思ってVBAと出会い、業務効率化の面白さとそれによって得られる達成感や感動を本業にしたいと思い、遅咲きながらエンジニアを目指しています。
スクール卒業後に転職活動を行ったのですが、自分に足りないものが分かり、この案件に挑戦することにしました。
「自走力がある方」というのはよくエンジニアの募集要項で目にします。
その力を私は持っていますよと少しでも証明するために、今回、実務案件に挑戦させていただき、幸運にも実際にソリューションを採用していただくことができました。
私に挑戦の場をくれたクライアント様に心から感謝するとともに、一緒に同じ課題に挑戦した仲間たちにもとても感謝しています。
今回の経験を踏まえて、自分に改めて足りていないもの、学習しなければならないこと、エンジニアという職業がコードを書くだけの職業ではないこと、技術以外に必要となるスキル、エンジニアになるってどんなことなのか等、本当に多くのことを学ばせていただきました。
そして、実務をわずかながら経験させていただき、エンジニアの面白さを感じることができ、この職でこれから挑戦したいなと再認識することができました。
これからその夢を実現できるよう学習を継続するとともに、今後の転職活動に力を入れたいと思います。ご覧いただきありがとうございました。