はじめに
始めまして、株式会社ジール所属の@hiroaki_yoshidaです。
普段はAWSやPythonを使った開発を行っています。
開発に携わるにあたり、現場で学んだ事をアウトプットしていこうと思います。
今回の記事は前回の続きでPythonの pandas というライブラリについて書いていこうかと思っており、データ加工の手段について基本的なSQL文と比較しながら説明したいと思います。
前回の記事がまだの方はこちらから↓
データ分析ライブラリのpandasについて
実行環境
pyhonバージョン:3.7.6
pandasバージョン:1.0.1
SQLとは?
今回比較対象とされるSQLとはいったいなんぞやという方がいらっしゃるかと思いますので、簡単にご説明します。
SQL とは「 Structure Query Language 」の略です。日本語だと構造化問い合わせ言語です。
データベース(以下DB)から必要なデータを取得する際に、どういうデータが必要なのか?といった問い合わせを行うためにSQLを使います。
例えば、顧客データの中から、20歳以上の男性のデータが欲しい場合、「 20歳以上の男性 」が問合せ内容になります。
SQLはデータ加工を行う際には必ず出てくる単語ですので覚えておくといいと思います。
データ準備
今回は下記データを使って説明していこうかと思います。
detailテーブル
| id | item | shop_id | amount | date |
|---|---|---|---|---|
| 1 | ショベルカー | 2 | 2 | 2022-09-09 |
| 2 | ダンプカー | 1 | 3 | 2022-09-10 |
| 3 | ロードローラー | 3 | 4 | 2022-09-11 |
| 4 | ショベルカー | 2 | 5 | 2022-09-12 |
shop_infoテーブル
| id | shop_name | status |
|---|---|---|
| 1 | 東京支店 | 2 |
| 2 | 名古屋支店 | 1 |
| 3 | 大阪支店 | 3 |
statusテーブル
| id | status |
|---|---|
| 1 | 開店 |
| 2 | 閉店 |
| 3 | 移転中 |
| 4 | 休業中 |
SELECT
SELECT文とはデータの選択を行うために使われる構文です。
SQLの場合
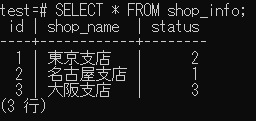
shop_infoテーブルのデータを 全列選択する場合 は下記の様に記載します。
SELECT * FROM shop_info;
↓実行結果↓
列を選択したい場合 は下記のように記載します。
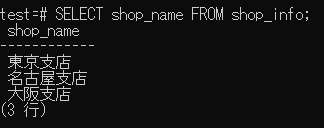
SELECT shop_name FROM shop_info; --単一列の出力の場合
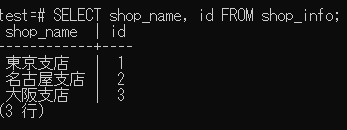
SELECT shop_name, id FROM shop_info; --複数列の出力の場合
↓実行結果↓
単一列の場合
複数列の場合
行を絞りたい場合 は下記のように記載します。
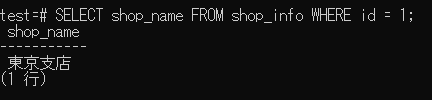
SELECT shop_name FROM shop_info WHERE id = 1; --単一行の出力の場合
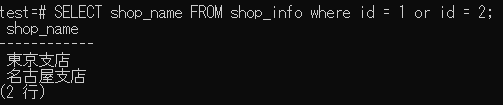
SELECT shop_name FROM shop_info where id = 1 or id = 2; --複数行の出力の場合
↓実行結果↓
単一行の出力の場合
複数行の出力の場合
pandasの場合
全列選択の場合
import pandas as pd
shop_info = pd.read_csv(r'C:\table\shop_info.csv',index_col=None)
shop_info
↓実行結果↓

列を選択したい場合 はdfの後に [ ] を付け、出力したいカラムを記載します。
複数記載する場合はリストとして記載します。
import pandas as pd
shop_info = pd.read_csv(r'C:\table\shop_info.csv',index_col=None)
shop_info['shop_name'] #単一列の出力の場合
shop_info[['shop_name','id']] #複数列の出力の場合
↓実行結果↓
単一列の場合

複数列の場合

行を絞りたい場合 も同じくdfの後に [] を付けなかに条件を記載していくような形になります。
複数記載する場合は 「and」 や 「or」 ではなく 「&」 と 「|」 を使います。
import pandas as pd
shop_info = pd.read_csv(r'C:\table\shop_info.csv',index_col=None)
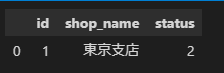
shop_info[shop_info['id'] == 1] #単一条件の場合
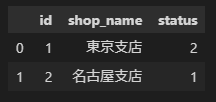
shop_info[(shop_info['id'] == 1) | (shop_info['id'] == 2)] #複数条件の場合
↓実行結果↓
単一条件の場合
複数条件の場合
上記の記述を利用すると、DBから欲しいデータを抽出することができます。
続いては結合です。
JOIN
JOINとは読んで字のごとく、結合を意味しています。
JOINを使う事でテーブルとテーブルを結合させることができます。
ここではよく使うLEFT JOIN・RIGHT JOIN・INNER JOIN・FULL OUTER JOINの書き方の違いを紹介します
SQLの場合
LEFT JOINの場合
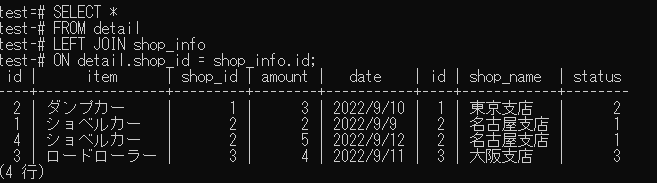
SELECT *
FROM detail
LEFT JOIN shop_info
ON detail.shop_id = shop_info.id;
↓実行結果↓
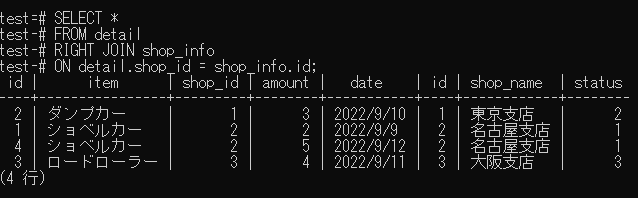
RIGHT JOINの場合
SELECT *
FROM detail
RIGHT JOIN shop_info
ON detail.shop_id = shop_info.id;
↓実行結果↓
INNER JOINの場合
INNER JOINの動きが分かるようにdetailテーブルとshop_infoに新たに1レコード追加します。
detailテーブル
| id | item | shop_id | amount | date |
|---|---|---|---|---|
| 1 | ショベルカー | 2 | 2 | 2022-09-09 |
| 2 | ダンプカー | 1 | 3 | 2022-09-10 |
| 3 | ロードローラー | 3 | 4 | 2022-09-11 |
| 4 | ショベルカー | 2 | 5 | 2022-09-12 |
| 5 | ショベルカー | 5 | 5 | 2022-09-15 |
shop_infoテーブル
| id | shop_name | status |
|---|---|---|
| 1 | 東京支店 | 2 |
| 2 | 名古屋支店 | 1 |
| 3 | 大阪支店 | 3 |
| 4 | 石川支店 | 2 |
この状態で下記クエリを実行します。
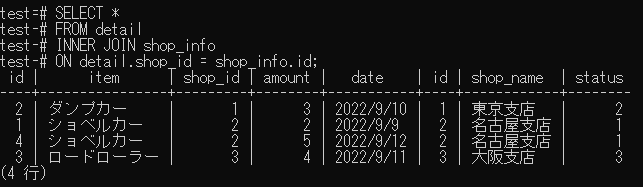
SELECT *
FROM detail
INNER JOIN shop_info
ON detail.shop_id = shop_info.id;
↓実行結果↓
FULL OUTER JOINの場合
こちらでも先ほどとINNER JOINで利用したテーブルを利用します。
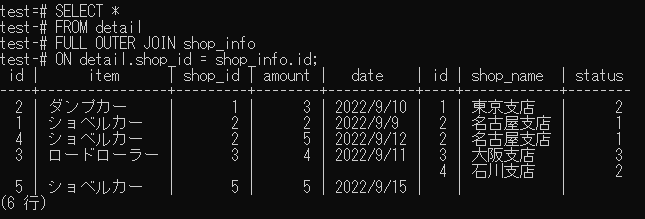
SELECT *
FROM detail
FULL OUTER JOIN shop_info
ON detail.shop_id = shop_info.id;
↓実行結果↓
pandasの場合
pandasではjoinする場合、 marge という関数を使います。
渡す引数としては下記になります。
pd.merge(左テーブル, 右テーブル, left_on='左テーブルの結合キー', right_on='右テーブルの結合キー', how='結合方法')
もしキー項目が同じ名称な場合は下記のように書くこともできます。
pd.merge(左テーブル, 右テーブル, on='結合キー', how='結合方法')
それでは各結合についてみていきます。
LEFT JOINの場合
import pandas as pd
detail = pd.read_csv(r'C:\table\detail.csv',index_col=None)
shop_info = pd.read_csv(r'C:\table\shop_info.csv',index_col=None)
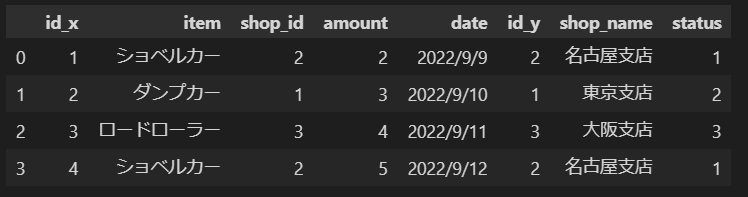
left_join_df = pd.merge(detail, shop_info, left_on='shop_id', right_on='id', how='left')
left_join_df
↓実行結果↓
RIGHT JOINの場合
import pandas as pd
detail = pd.read_csv(r'C:\table\detail.csv',index_col=None)
shop_info = pd.read_csv(r'C:\table\shop_info.csv',index_col=None)
right_join_df = pd.merge(detail, shop_info, left_on='shop_id', right_on='id', how='right')
right_join_df
↓実行結果↓
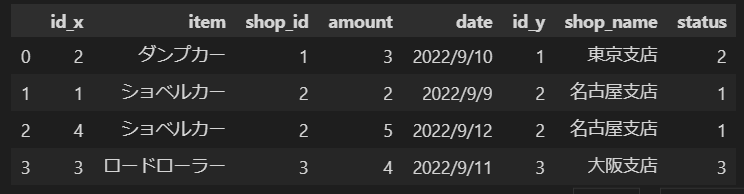
INNER JOINの場合
import pandas as pd
ddetail = pd.read_csv(r'C:\table\detail.csv',index_col=None)
shop_info = pd.read_csv(r'C:\table\shop_info.csv',index_col=None)
#DataFrameに追加する行を作っています
detail_addd = pd.DataFrame([[5,'ショベルカー',5,5,'2022/9/15']],columns=['id','item','shop_id','amount','date'])
sho_info_add = pd.DataFrame([[4,'石川',2]],columns=['id','shop_name','status'])
#行を追加しています
detail = pd.concat([detail,detail_addd])
shop_info = pd.concat([shop_info,sho_info_add])
inner_join_df = pd.merge(detail, shop_info, left_on='shop_id', right_on='id', how='inner')
inner_join_df
↓実行結果↓
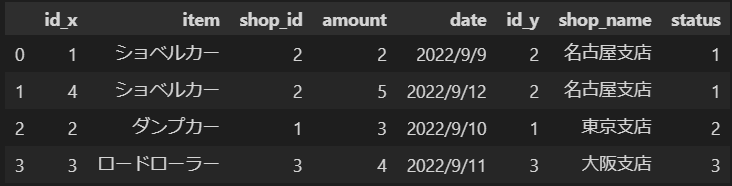
FULL OUTER JOINの場合
import pandas as pd
detail = pd.read_csv(r'C:\table\detail.csv',index_col=None)
shop_info = pd.read_csv(r'C:\table\shop_info.csv',index_col=None)
#DataFrameに追加する行を作っています
detail_addd = pd.DataFrame([[5,'ショベルカー',5,5,'2022/9/15']],columns=['id','item','shop_id','amount','date'])
sho_info_add = pd.DataFrame([[4,'石川',2]],columns=['id','shop_name','status'])
#行を追加しています
detail = pd.concat([detail,detail_addd])
shop_info = pd.concat([shop_info,sho_info_add])
outer_join_df = pd.merge(detail, shop_info, left_on='shop_id', right_on='id', how='outer')
outer_join_df
↓実行結果↓

まとめ
以上が基本的なSQLとpandasの書き方の違いになります。
pandasを使うメリットとしてはPythonの他のライブラリを利用するなどで、より複雑なデータ加工や分析ができるようになる 事です。
pandasの利用例としては、AWSサービスであるS3上のファイルを一次加工するのに利用することもできますし、ライブラリを組み合わせればDBへそのままDataFrameをinsertすることもできます。
もちろんDBのデータをDataFlameへ格納することもできます。
SQLを使わずPandasだけで処理を作成することもできてしまいます。
とても奥が深いライブラリなので、是非みなさんもpandasを活用してみてください。