はじめに
始めまして、株式会社ジール所属の@hiroaki_yoshidaです。
普段はAWSやPythonを使った開発を行っています。
開発に携わるにあたり、現場で学んだ事をアウトプットしていこうと思います。
今回はPythonの pandas というライブラリについて書いています。
データ分析基盤ではETL処理などで利用されています。
pandasについて
pandasとはPythonのデータ分析ライブラリの1つです。
データ分析ライブラリとしてはほかには numpy や matplotlib などがあります。
今回は比較的よく使うpandasを扱います。
pandasの基本知識
ここではpandasを利用するにあたって抑えておきたい単語について解説します。
1.Series
pandasで扱われるデータ構造の一つで、単一列で構成された表になります。
※インデックが付与されている為2列になっています。インデックスについてはのちほど説明します。

2.DataFrame
pandasで扱われるデータ構造の一つで、複数列で構成された表になります。
Seriesをまとめたものになります。
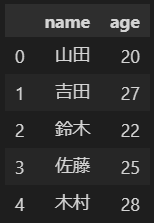
3.index
行ラベルの事、SeriesやDataFrameに付与することができます。
インデックスを利用して行データにアクセスすることも可能です。
インデックスは自動的に付与されますが、不要であればオプションで付与しないこともできます。
また、任意のカラムをインデックスとすることも可能です。
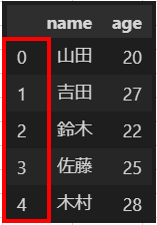
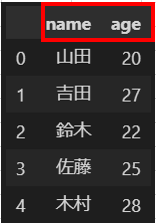
4.columns
列に対して付与することのできるラベルです。
columnsを利用してDataFrameのカラム情報を取得することができます。
pandasを利用するには
まず、利用にあたってpandas のインストールをしなくてはいけません。
インストールする際は下記pipコマンドを利用してインストールをおこなってください。
pip install pandas
実際にコーディングする際はimport文を書くのですが、pandasは多くの場合に別名であるpdとしてインポートします。
import pandas as pd
毎回モジュールを利用する際にpandasって書くよりもpdの方が楽ですよね!
簡単なサンプルコード
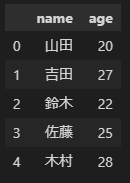
下記は基本知識で表示していたDataFrameの作成をしているコードです。
#pandasをimportする文です。例の如くpdにリネームしています。
import pandas as pd
#DataFrameにするための元データを作成してdataという変数に入れています。
data = [["山田",20],["吉田",27],["鈴木",22],["佐藤",25],["木村",28]]
#作ったdataという変数を用いてDataFrameを作成しています。
#その際にカラム名をcolumns = []で指定しています。
#作成したDataFrameはdfという変数に格納します。
df = pd.DataFrame(data,columns=["name","age"])
#DataFrameの中身を確認しています。
df
Jupyter notebookでは下記の様に表示されます。
まとめ
今回はデータを手作業で作成し、dataという変数へ格納し、さらにその変数を利用してDataFrameを作成しました。
実はpandasではCSVやparquetなど様々な種類のファイルを読み取ることでDataFrameを作成することができます。
扱えるフォーマットファイルについては下記URLが参考になるかと思います。
https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html?highlight=format%20file
次回はpandasを使ったデータ加工についてSQLとの書き方の比較の記事を作成予定です。
株式会社ジールでは、「ITリテラシーがない」「初期費用がかけられない」「親切・丁寧な支援がほしい」「ノーコード・ローコードがよい」「運用・保守の手間をかけられない」などのお客様の声を受けて、オールインワン型データ活用プラットフォーム「ZEUSCloud」を月額利用料にてご提供しております。
ご興味がある方は是非下記のリンクをご覧ください: